整理了一些基础的面试题
前言
虽然这些面试题已经看了N+1遍了,但是看懂是一回事,组织语言说出来,又是一回事,像我这种嘴笨的一段时间不复习就表达不出来了,照成面试失败or压薪资!!
String、StringBuffer、StringBuilder
1、相同点
这三个类都是用来处理字符串的。
2、是否可变
- String类型的字符串对象是不可变的,⼀旦String对象创建后,包含在这个对象中的字符系列是不可以改变的,直到这个对象被销毁。
- StringBuilder和StringBuffer类型的字符串是可变的,不同的是StringBuffer类型的是线程安全的,⽽StringBuilder不是线程安全的
3、使用场景
-
使⽤String类的场景:
在字符串不经常变化的场景中可以使⽤String类,例如常量的声明、少量的变量运算。 -
使⽤StringBuffer类的场景:
在频繁进⾏字符串运算(如拼接、替换、删除等),并且运⾏在多线程环境中,则可以考虑使⽤StringBuffer,例如XML解析、HTTP参数解析和封装。 -
使⽤StringBuilder类的场景:
在频繁进⾏字符串运算(如拼接、替换、和删除等),并且运⾏在单线程的环境中,则可以考虑使⽤StringBuilder,如SQL语句的拼装、JSON封装等。 -
StringBuilder和StringBuffer的“可变”特性总结如下:
(1)append,insert,delete⽅法最根本上都是调⽤System.arraycopy()这个⽅法来达到⽬的
(2)substring(int, int)⽅法是通过重新new String(value, start, end - start)的⽅式来达到⽬的。因此,在执⾏substring操作时,StringBuilder和String基本上没什么区别。总的来说,三者在执⾏速度⽅⾯的⽐较:
StringBuilder > StringBuffer > String
方法重写和方法重载
方法重写特点:重写的关键字override
- 三同一不同:
- 方法的返回值类型相同
- 方法名相同
- 参数列表相同 - 方法的具体实现是不同的
方法重载:前提:必须是在同一个类中
- 一同三不同:
- 方法名必须一致
- 参数列表不同(参数数据类型不同、参数个数不同)
- 和访问修饰符、返回值类型无关
抽象类和接口
1、 相同点
都是用来抽取公共的特性的;都不能初始化;都没有构造器
2、定义方式
接口使用interface定义,抽象类使用abstract class定义;
3、 使用方式
一个类可以实现多个接口,但只能继承一个抽象类;
4、 属性
接口里面的属性都是常量,都是使用public static final修饰的,即便没有写也是;抽象类里面可以有普通的类变量;
5、方法
- 接口里面的方法都是抽象方法,即都没有方法体(注意从jdk8之后是可以有的,使用default修饰方法);
- 抽象类里面可以没有抽象方法,也可以有(使用abstract修饰);
- 抽象类可以有构造方法,接口中不能有构造方法;
- 抽象类中可以包含静态方法,接口中不能包含静态方法;
ArrayList、Vector、LinkedList
1、相同点
这三个类都是List的实现,都是有序可重复的集合
2、底层实现
ArrayList和Vector是基于数组的,存放在连续的内存块,LinkedList底层基于双向链表,无需连续内存;
ArrayList和Vector随机查询快(通过索引也就是下标直接访问),尾部插入、删除性能可以,其它部分插入、删除都会移动数据,因此性能会低;
LinkedList随机查询慢(需要基于指针从头一个一个查找,最坏的情况要遍历整个集合才能找到),头尾增删快,随机的话不一定因为要先找对应的数据需要遍历,所以不是绝对的快
3、线程安全性
ArrayList线程不安全,Vector线程安全(使用synchronized关键字锁定方法),然而,Vector性能较低,所以一般不怎么使用(并没有废弃),建议使用下面的方式代替Vector:
Collections.synchronizedList(new ArrayList<>())
new CopyOnWriteArrayList<>() :写入时复制
CopyOnWrite 比 Vector NB
Vector里面有synchronized锁效率低 CopyOnWrite用的lock锁
4、LinkedList线程不安全,如果需要使用线程安全的链表List,有两种处理方法:
1. 调用List<String> list = Collections.synchronizedList(new LinkedList<String>());
2. 将LinkedList全部换成ConcurrentLinkedQueue
5、大小以及增长方式
ArrayList 默认大小为0,第一次add的时候会扩容为10,之后每次以1.5倍扩容
Vector 默认就是10 每次扩容以2倍扩容
HashMap、HashTable、 LinkedHashMap 、ConcurrentHashMap
1、相同点
这三个类都是都是Map的实现,也就是说,都是双列的集合,都是存放键值对的,底层实现都是基于数组+链表的结构,也就是hash表。
2、 底层结构
除了LinkedHashMap之外,都是基于数组+链表的结构,而LinkedHashMap还在此基础上维护了一个双向链表,用来保证元素插入的顺序,所以LinkedHashMap可以保证元素的插入顺序,其他的几个则不可以
3、 null值要求
HashMap的key和值都可以为null;HashTable的键和值都不能为null;ConcurrentHashMap的键和值都不能为null;
4、容量和增长方式
HashMap : 默认大小16,负载因子0.75,当hash表的容量超过负载因子的时候开始扩容,扩容为原始容量的2倍。
HashTable:初始容量为11,负载因子为0.75。超过负载因子容量开始扩容,扩容为旧的容量*2+1。
5、 安全性及性能
HashMap是线程不安全的,所以效率高;HashTable是基于synchronized实现的线程安全的Map,效率较低;
ConCurrentHashMap线程安全,但是锁定的只是一部分代码,所以效率比HashTable高。
从concurrentHashMap的代码可以看出它引入了一个分段锁的概念,具体的可以理解为把一个大的hashmap拆分为n个小的hashtble,根据key.hashcode()来决定把key放到那个hashtable中concurrentHashMap和hashtable的主要区别是围绕着锁的力度如何,可以简单理解为大的hashtable拆分为多个小的,形成了锁分离
HashMap
1、基本数据结构
-
1.7 数组 + 链表
-
1.8 数组 + (链表 | 红黑树)
链表插入节点时,1.7 是头插法,1.8 是尾插法
-
1.7 是大于等于阈值且没有空位时才扩容,而 1.8 是大于阈值就扩容
-
1.8 在扩容计算 Node 索引时,会优化
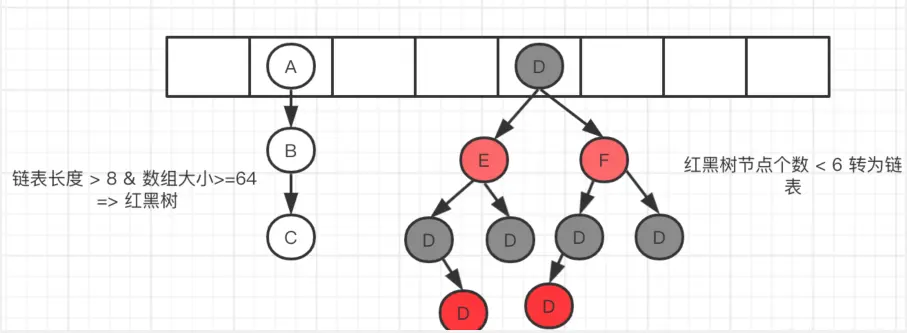
2、树化与退化
树化意义
- 红黑树用来避免 DoS 攻击,防止链表超长时性能下降,树化应当是偶然情况,是保底策略
- hash 表的查找,更新的时间复杂度是 $O(1)$,而红黑树的查找,更新的时间复杂度是 $O(log_2n )$,TreeNode 占用空间也比普通 Node 的大,如非必要,尽量还是使用链表
- hash 值如果足够随机,则在 hash 表内按泊松分布,在负载因子 0.765 的情况下,长度超过 8 的链表出现概率是 0.00000006,树化阈值选择 8 就是为了让树化几率足够小
树化规则
当链表长度超过树化阈值 8 时,先尝试扩容来减少链表长度,如果数组容量已经 >=64,才会进行树化
退化规则
- 情况1:在扩容时如果拆分树时,树元素个数 <= 6 则会退化链表
- 情况2:remove 树节点时,若 root、root.left、root.right、root.left.left 有一个为 null ,也会退化为链表
3、索引计算
索引计算方法
- 首先,计算对象的 hashCode()
- 再进行调用 HashMap 的 hash() 方法进行二次哈希
- 二次 hash() 是为了综合高位数据,让哈希分布更为均匀
- 最后 & (capacity – 1) 得到索引
数组容量为何是 2 的 n 次幂
- 计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
- 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
注意
- 二次 hash 是为了配合 容量是 2 的 n 次幂 这一设计前提,如果 hash 表的容量不是 2 的 n 次幂,则不必二次 hash
- 容量是 2 的 n 次幂 这一设计计算索引效率更好,但 hash 的分散性就不好,需要二次 hash 来作为补偿,没有采用这一设计的典型例子是 Hashtable
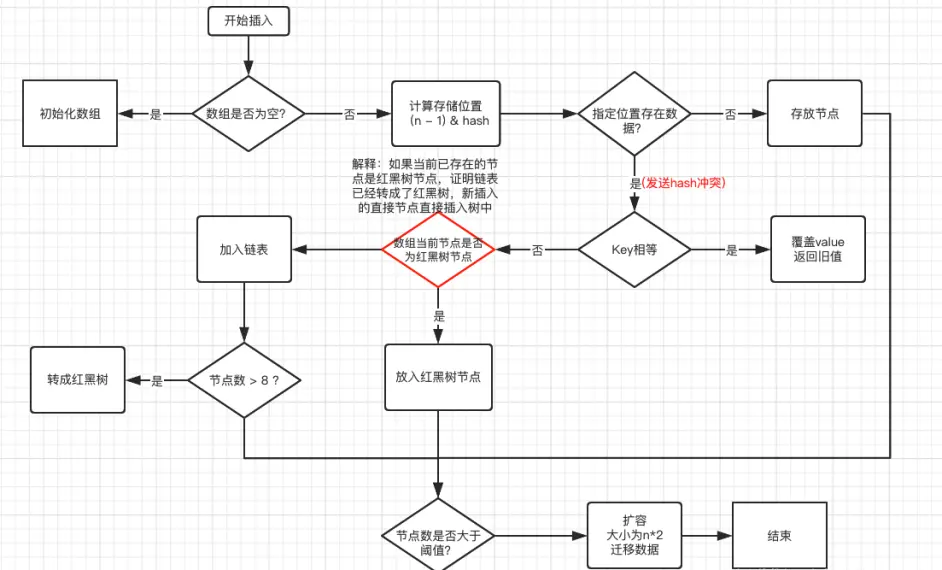
4、put 与扩容
put 流程
- HashMap 是懒惰创建数组的,首次使用才创建数组
- 计算索引(桶下标)
- 如果桶下标还没人占用,创建 Node 占位返回
- 如果桶下标已经有人占用
- 已经是 TreeNode 走红黑树的添加或更新逻辑
- 是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑-
- 返回前检查容量是否超过阈值,一旦超过进行扩容
扩容(加载)因子为何默认是 0.75f
在空间占用与查询时间之间取得较好的权衡
- 大于这个值,空间节省了,但链表就会比较长影响性能
- 小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多
JAVA有哪些数据类型
JAVA数据类型分为基本数据类型和引用数据类型
- 基本数据类型有四类八种:
- 整型:byte(1字节)、short(2字节)、int(4字节)、long(8字节)
- 浮点型:float(4字节)、double(8字节)
- 字符型:char(2字节)
- 布尔型:boolean(1位)
- 引用类型:类class、接口interface、数组[]