原文:https://www.modb.pro/db/182864
引入此问题的原因,是因为在单节点的ES部署策略中,如果在设置某个ES索引的replica不为零,你会发现。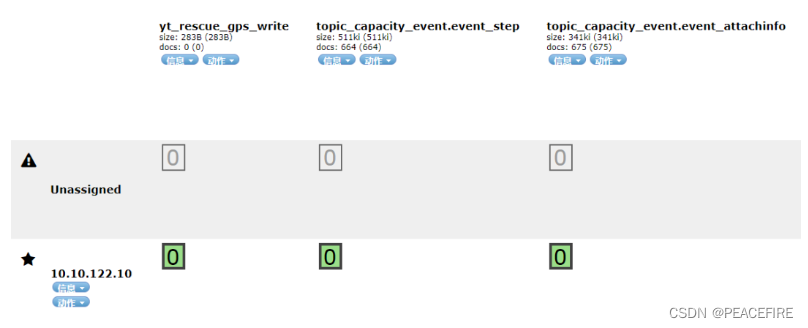
存在Unassigned的状态出现。一般开发者在遇到这种情况的时候,有没有考虑过为什么会有这样的情况出现呢?
分析问题
首先可以用相关命令查看哪一些索引处于unassigned状态,见下:
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason| grep UNASSIGNED
- 1
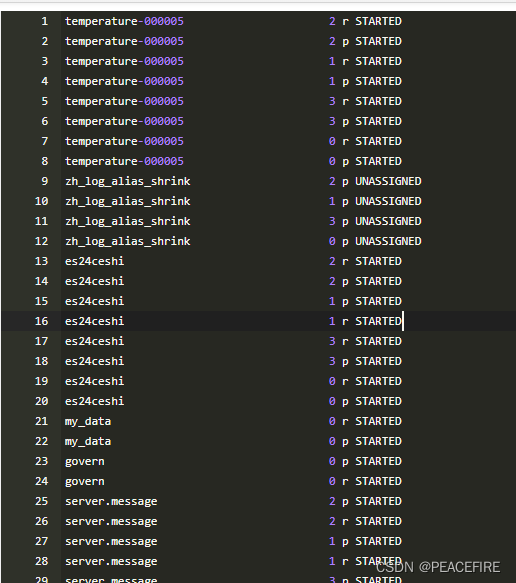
集群中的某些分片仍未分配的有用详细信息:每行都列出了索引的名称、分片编号、它是主分片 § 还是副本 ® 分片,以及未分配的原因。很容易就能看出有unassigned的分片。
查看分片分配不下去的原因
GET /_cluster/allocation/explain?pretty
- 1
结果为:
{
"index": "add-000004",
"shard": 3,
"primary": true,
"current_state": "unassigned",
"unassigned_info": {
"reason": "CLUSTER_RECOVERED",
"at": "2021-10-26T10:21:10.943Z",
"last_allocation_status": "no_valid_shard_copy"
},
"can_allocate": "no_valid_shard_copy",
"allocate_explanation": "cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster",
"node_allocation_decisions": [
{
"node_id": "0WHacVilSN2dUyyirft9Eg",
"node_name": "10.10.120.134",
"transport_address": "10.10.120.134:9333",
"node_attributes": {
"ml.machine_memory": "16728154112",
"rack": "rack-1",
"ml.max_open_jobs": "20",
"xpack.installed": "true"
},
"node_decision": "no",
"store": {
"found": false
}
},
{
"node_id": "jFmvlDdgT_OQ1BY0I6DXsg",
"node_name": "10.10.120.132",
"transport_address": "10.10.120.132:9333",
"node_attributes": {
"ml.machine_memory": "33672540160",
"rack": "rack-1",
"ml.max_open_jobs": "20",
"xpack.installed": "true"
},
"node_decision": "no",
"store": {
"found": false
}
},
{
"node_id": "xamy3maMQQqeiFLZqw_vXQ",
"node_name": "10.10.120.133",
"transport_address": "10.10.120.133:9333",
"node_attributes": {
"ml.machine_memory": "16728154112",
"rack": "rack-1",
"ml.max_open_jobs": "20",
"xpack.installed": "true"
},
"node_decision": "no",
"store": {
"found": false
}
}
]
}
很容易就能看出问题cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster
总结可能有以下几种原因导致
分片太多,节点不够
上面所述的情况就是此种原因的结果。当节点加入或者离开集群,主节点会自动重新分配分片,确保分片的多个副本不会分配给同一个节点。这个其实很好理解,如果一个主分片和它的一个副本分片在一个集群中同时分配到同一个节点中,如果此节点挂掉,整个index的数据都会loss,此时副本的意义就不存在了。
为了避免这个问题,集群中的每个索引初始化时每个主分片的副本数+1要少于或等于节点数:N >= R+1;
Shard默认延迟分配
在某个节点与master失去联系后,集群不会立刻重新allocation,而是会延迟一段时间确定此节点是否会重新加入集群。如果重新加入,则此节点会保持现有的分片数据,不会触发新的分片分配。
当然通过修改delayed_timeout,默认等待时间可以全局设置也可以在索引级别进行修改:
PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "10m"
}
}
通过_all 索引名,我们可以为所有的索引使用这个参数,默认时间修改成了10分钟
如果不想等待可以设置:delayed_timeout: 0
注意:延迟分配不会阻止副本被提拔为主分片。集群还是会进行必要的提拔来让集群回到 yellow
状态。缺失副本的重建是唯一被延迟的过程。
如果节点在超时之后再回来,且集群还没有完成分片的移动,会发生什么事情呢?在这种情形下, Elasticsearch 会检查该机器磁盘上的分片数据和当前集群中的活跃主分片的数据是不是一样 — 如果两者匹配, 说明没有进来新的文档,包括删除和修改 — 那么 master 将会取消正在进行的再平衡并恢复该机器磁盘上的数据。
之所以这样做是因为本地磁盘的恢复永远要比网络间传输要快,并且我们保证了他们的分片数据是一样的,这个过程可以说是双赢。
如果分片已经产生了分歧(比如:节点离线之后又索引了新的文档),那么恢复进程会继续按照正常流程进行。重新加入的节点会删除本地的、过时的数据,然后重新获取一份新的。
重启分片分配
一般情况下分配分配功能是默认开启的,不存在这种情况。但是某些时候可能禁用了分片分配(例如:滚动重启)
Disable shard allocation. This prevents Elasticsearch from rebalancing
missing shards until you tell it otherwise. If you know the
maintenance window will be short, this is a good idea. You can disable
allocation as follows:https://www.elastic.co/guide/en/elasticsearch/guide/current/_rolling_restarts.html
需要启动分片分配
put /_cluster/settings
{
"transient" : {
"cluster.routing.allocation.enable" : "all"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
低磁盘水印
如果磁盘使用率超过85%,一旦一个节点磁盘达到这个水平,意味着 Elasticsearch 不会将分片分配给磁盘使用率超过 85% 的节点。它还可以设置为绝对字节值(如500mb),以防止 Elasticsearch 在可用空间少于指定量时分配分片。此设置对新创建索引的主分片没有影响,但会阻止分配它们的副本。
如果节点够大eg 10TB ,可以安全的增加低磁盘水印到90%
put /_cluster/setttings
{
"transient": {
"cluster.routing.allocation.disk.watermark.low": "90%"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
磁盘使用率超过90%:ES会尝试将对应节点中的分片迁移到其他磁盘使用率比较低的数据节点中。
ES中cluster.routing.allocation.disk.watermark.flood_stage 洪水阶段水印控制,默认为95%。如果当磁盘使用率超过这个值后,查询settings会发现index.blocks.read_only_allow_delete = true ,强制每个索引只允许读或者删除。此设置防止节点耗尽磁盘空间的最后手段。
恢复写入命令
PUT /_cluster/settings
{
"persistent" : {
"cluster.blocks.read_only" : false
}
}
- 1
- 2
- 3
- 4
- 5
- 6
多个ES版本
滚动升级过程中,主节点不会将主分片的副本分配给旧版本的节点。所以如果是此原因,升级旧版本的节点可以解决此问题。
分片数据不存在集群中
如果出现只有主分片未分配。它可能是在没有任何副本的节点上创建(加速初始化索引过程中,关掉副本创建和同步的方案),并且该节点在数据可以复制之前和集群断了联系。主节点在其全局集群状态中能够检测到分片,但是无法在集群中定位分片的数据。
另一种可能,当节点在与集群恢复连接时,将磁盘分片的信息同步到主节点,后将这些分片从未分配转为已分配的过程中因为某种原因失败,导致了分配保持了未分配的状态。
在这种情况下,如何继续:尝试让原始节点恢复并重新加入集群(并执行 不是强制分配主分片),或使用Cluster Reroute API强制分配分片并使用原始数据源或备份重新索引丢失的数据。
如果决定使用后者(强制分配主分片),需要注意的是将分配一个“空”分片。如果包含原始主分片数据的节点稍后重新加入集群,则其数据将被新创建的(空)主分片覆盖,因为它将被视为数据的“较新”版本。在继续执行此操作之前,可能希望重试分配,这将允许保留存储在该分片上的数据。
如果了解其中的含义并且仍想强制分配未分配的主分片,则可以使用该allocate_empty_primary标志来实现。以下命令将索引中的主分片重新路由到特定节点:
POST /_cluster/reroute?pretty
{
"commands" : [
{
"allocate_empty_primary" : {
"index" : "test-index",
"shard" : 0,
"node" : "<NODE_NAME>",
"accept_data_loss" : "true"
}
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
需要指定"accept_data_loss" : "true"以确认已准备好丢失分片上的数据。如果不包含此参数,将看到如下错误:
{
"error" : {
"root_cause" : [
{
"type" : "remote_transport_exception",
"reason" : "[NODE_NAME][127.0.0.1:9300][cluster:admin/reroute]"
}
],
"type" : "illegal_argument_exception",
"reason" : "[allocate_empty_primary] allocating an empty primary for [test-index][0] can result in data loss. Please confirm by setting the accept_data_loss parameter to true"
},
"status" : 400
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
如果需要恢复丢失的数据,需要使用Snapshot and Restore API
Snapshot module
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-snapshots.html
从备份快照中恢复。
标签:node,节点,cluster,UNASSIGNED,集群,分片,分配,ES From: https://www.cnblogs.com/lovezhr/p/16919161.html