首先要知道 Hive 和 HBase 两者的区别,我们必须要知道两者的作用和在大数据中扮演的角色
概念
Hive
1.Hive 是 hadoop 数据仓库管理工具,严格来说,不是数据库,本身是不存储数据和处理数据的,其依赖于 HDFS 存储数据,依赖于 MapReducer 进行数据处理。
2.Hive 的优点是学习成本低,可以通过类 SQL 语句(HSQL)快速实现简单的 MR 任务,不必开发专门的 MR 程序。
3.由于 Hive 是依赖于 MapReducer 处理数据的,因此有很高的延迟性,不适用于实时数据处理(数据查询,数据插入,数据分析),适用于离线数据的批处理。
HBase
1.HBase 是一种分布式、可扩展、支持海量数据存储的 NOSQL 数据库
2.HBase 主要适用于海量数据的实时数据处理(随机读写)
3.由于 HDFS 不支持随机读写,而 HBase 正是为此而诞生的,弥补了 HDFS 的不可随机读写。
共同点
hbase 与 hive 都是架构在 hadoop 之上的。都是用 HDFS 作为底层存储。
区别
1.Hive 是建立在 Hadoop 之上为了减少 MapReduce jobs 编写工作的批处理系统,HBase 是为了支持弥补 Hadoop 对实时操作的缺陷的项目 。总的来说,hive 是适用于离线数据的批处理,hbase 是适用于实时数据的处理。
2.Hive 本身不存储和计算数据,它完全依赖于 HDFS 存储数据和 MapReduce 处理数据,Hive 中的表纯逻辑。
3.hbase 是物理表,不是逻辑表,提供一个超大的内存 hash 表,搜索引擎通过它来存储索引,方便查询操作。
4.由于 HDFS 的不可随机读写,hive 是不支持随机写操作,而 hbase 支持随机写入操作。
5.HBase 只支持简单的键查询,不支持复杂的条件查询
关系
在大数据架构中,Hive 和 HBase 是协作关系,这里就举例一种常用的协作关系,具体流程如下图:
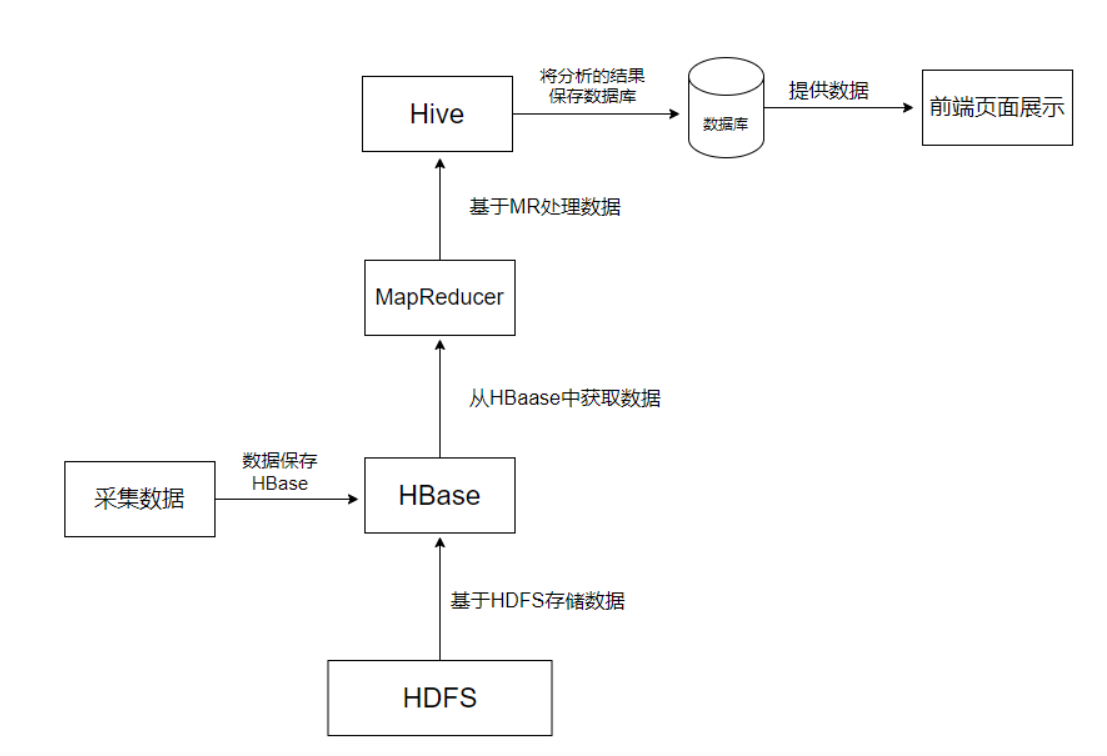
流程:
1.Hive 创建一张外部表与 HBase 表关联,因此只需对 Hive 表进行查询即可,Hive 表会自动从关联的 HBase 表中获取数据
2.采集的数据保存到 HBase 表,因为 HBase 表支持随机写操作,这个可以根据业务需求决定
3.Hive 通过 HSQ 语句创建 MR 任务去处理分析数据
3.MR 将分析的结果最终存储到常用的数据库(Mysql 数据库)
4.web 端从数据库获取数据进行可视化
标签:HDFS,存储,区别,Hive,随机,HBase,数据 From: https://www.cnblogs.com/qian-fen/p/16916249.html