随着最大的人工智能研究会议(NeurIPS 2022)即将到来,我们进入了2022年的最后阶段。让我们回顾一下人工智能世界最近发生了什么。
在介绍推荐论文之前,先说一个很有意思的项目:
img-to-music:想象图像听起来是什么样的模型! https://huggingface.co/spaces/fffiloni/img-to-music。有兴趣的可以看看。
下面我们开始介绍10篇推荐的论文。这里将涵盖强化学习(RL)、扩散模型、自动驾驶、语言模型等主题。
1、Scaling Instruction-Finetuned Language Models
https://arxiv.org/abs/2210.11416
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay et al.
一年前Google 的 FLAN¹ 展示了如何通过将带标签的 NLP 示例重新表述为自然语言指令并将它们包含在预训练语料库中来提高语言模型 (LM) 的通用性。这篇论文则扩大该技术应用。
OpenAI 著名的 GPT系列的模型的一个成功关键是使用未标记数据进行训练。但这并不意味着自回归 LM 不能使用标记数据进行训练:注释可以注入到模型的训练中而无需任何架构更改。这里的关键思想是:不是让分类头为输入输出标签,而是将带标签的例子重新表述为用自然语言编写的指令。例如,可以将带有标签的情感分类示例转换为具有以下模板的语句:
文本:The film had a terrific plot and magnific acting. 标签[POSITIVE]
改为:
The film [is good because it] had a terrific plot and magnific acting.
这里有一个问题,就是要将零样本性能与 GPT-3 等完全自监督模型进行比较,必须确保评估中使用的任务不包含在训练集中!(也就是数据泄露的问题)
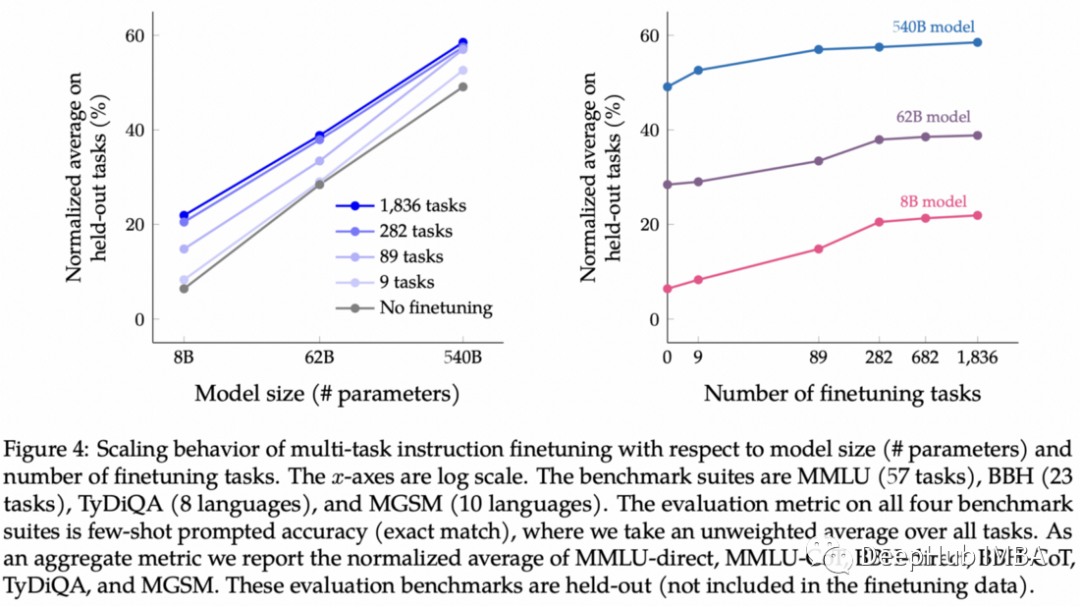
最初的 FLAN 论文在 137B 参数模型上,使用了有来自几十个 NLP 任务的 30k 额外指令展示了这种技术的强大功能。 在本文中,他们通过将 (1) 任务数量扩展到 1836,(2) 模型大小扩展到 540B 参数,以及 (3) 添加思维链提示来进入下一个级别。
结果表明,添加指令会提高性能,尤其是对于较小的模型,但模型规模仍然是最大的因素。
完整的模型在谷歌的Research Github Repository上公开发布:
https://avoid.overfit.cn/post/25ce9e587880476486c151a2920d37e6
标签:11,10,https,标签,模型,论文,2022 From: https://www.cnblogs.com/deephub/p/16914632.html