关键词:react react-scheduler scheduler 时间切片 任务调度 workLoop
背景
本文所有关于 React 源码的讨论,基于 React v17.0.2 版本。
文章背景
工作中一直有在用 React 相关的技术栈,但却一直没有花时间好好思考一下其底层的运行逻辑,碰巧身边的小伙伴们也有类似的打算,所以决定组团卷一波,对 React 本身探个究竟。
本文是基于众多的源码分析文章,加入自己的理解,然后输出的一篇知识梳理。如果你也感兴趣,建议多看看参考资料中的诸多引用文章,相信你也会有不一样的收获。
本文不会详细说明 React 中 react-reconciler 、 react-dom 、fiber 、dom diff、lane 等知识,仅针对 scheduler 这一细节进行剖析。
知识点背景
在我尝试理解 React 中 Scheduler 模块的过程中,发现有很多概念理解起来比较绕,也是在不断问自己为什么的过程中,发现如果自顶向下的先有一些基本的认知,再深入理解 Scheduler 在 React 中所做的事情,就变得容易很多。
浏览器的 EventLoop 简单说明
此处默认你已经知道了 EventLoop 及浏览器渲染的相关知识
一个 frame 渲染(帧渲染)的过程,按 60fps来计算,大概有16.6ms,在这个过程中浏览器要做很多东西,包括 “执行 JS -> 空闲 -> 绘制(16ms)”,在执行 JS 的过程中,即是浏览器的 JS 线程执行 eventloop 的过程,里面包括了 marco task 和 mirco task 的执行,其中执行多少个 macro task 的数量是由浏览器决定的,而这个数量并没有明确的限制。
因为 whatwg 规范标准中只是建议浏览器尽可能保证 60fps 的渲染体验,因此,不同的浏览器的实现也并没有明确说明。同时需要注意,并不是每一帧都会执行绘制操作。如果某一个 macro task 及其后执行 mirco task 时间太长,都会延后浏览器的绘制操作,也就是我们常见的掉帧、卡顿。
React 的 Scheduler 的简单说明
React 为了解决 15 版本存在的问题:组件的更新是递归执行,所以更新一旦开始,中途就无法中断。当层级很深时,递归更新时间超过了16ms,用户交互就会卡顿。
React 引入了 Fiber 的架构,同时配合 Schedduler 的任务调度器,在 Concurrent 模式下可以将 React 的组件更新任务变成可中断、恢复的执行,就减少了组件更新所造成的页面卡顿。
目录
- 常见问题
- Scheduler 是什么,作用是什么
- 实际生产中我们的 React 库有用到 Scheduler 调度吗
- 为什么用 MessageChannel ,而不用 setTimeout ?
- 为什么不用 Generator、Webworkers 来做任务调度
- 核心逻辑解析
- 概念说明
- 核心流程图
- 如何实现的任务切片
- 如何实现任务的中断
- 如何实现任务的恢复
- 个人的一点理解
- Demo 示例
- 利用 Scheduler 任务调度的示例
- 不用 Scheduler 任务调度的示例
- 设置切片时间为 0ms 时 的情景
- 实现一个 Scheduler 核心逻辑——判断单个任务的完成状态
- 拓展
- Scheduler 的开源计划
- Scheduler 为浏览器提供规范
- React 18 的离屏渲染
- Vue 和 React 的两种方案的选择
常见问题
Scheduler 是什么,作用是什么
Scheduler是一个独立的包,不仅仅在React中可以使用。
Scheduler 是一个任务调度器,它会根据任务的优先级对任务进行调用执行。
在有多个任务的情况下,它会先执行优先级高的任务。如果一个任务执行的时间过长,Scheduler 会中断当前任务,让出线程的执行权,避免造成用户操作时界面的卡顿。在下一次恢复未完成的任务的执行。
Scheduler 是 React 团队开发的一个用于事务调度的包,内置于 React 项目中。其团队的愿景是孵化完成后,使这个包独立于 React,成为一个能有更广泛使用的工具。
实际生产中我们的 React 库有用到 Scheduler 调度吗
这个问题,其实是我个人想说明的一个点
因为在我看的很多文章中,大家都在不断强调 Scheduler 的各种好处,各种原理,以至于我最开始也以为只要引入了 React 16-17 的版本,就能体会到这样的“优化”效果。但是当我开启源码调试时,就产生了困惑,因为完全没有按照套路来输出我辛辛苦苦打的 console.log 。
直到我使用 Concurrent 模式才体会到 Scheduler 的任务调度核心逻辑。这个模式直到 React 17 都没有暴露稳定的 API,只是提供了一个非稳定版的 unstable_createRoot 方法。
结论:Scheduler 的逻辑有被 React 使用,但是其核心的切片、任务中断、任务恢复并没有在稳定版中采用,你可以理解现在的 React 在执行 Fiber 任务时,还是一撸到底。
为什么用 MessageChannel ,而不首选 setTimeout
如果当前环境不支持 MessageChannel 时,会默认使用 setTimeout
- MessageChannel 的作用
- 生成浏览器 Eventloops 中的一个宏任务,实现将主线程还给浏览器,以便浏览器更新页面
- 浏览器更新页面后能够继续执行未完成的 Scheduler 中的任务
- tips:不用微任务迭代原因是,微任务将在页面更新前全部执行完,达不到将主线程还给浏览器的目的
- 选择 MessageChannel 的原因是因为 setTimeout(fn,0) 所创建的宏任务,会有至少 4ms 的执行时差,setInterval 同理
- 代码示例:MessageChannel 总会在 setTimeout 任务之前执行,且执行消耗的时间总会小于 setTimeout
// setTimeout 的执行示例
var date1 = Date.now()
console.log('setTimeout 执行的时间戳1:',date1)
setTimeout(()=>{
var date2 = Date.now()
console.log('setTimeout 执行的时间戳2:',date2)
console.log('setTimeout 时差:',date2 - date1)
},0)
// messageChannel 的执行示例
var channel = new MessageChannel()
var port1 = channel.port1;
var port2 = channel.port2;
port1.onmessage = ()=>{
var cTime2 = Date.now()
console.log('messageChannel 执行的时间戳2:',cTime2)
console.log('messageChannel 时差:', cTime2-cTime1)
}
var cTime1 = Date.now()
console.log('messageChannel 执行的时间戳1:',cTime1)
port2.postMessage(null)
React v16.10.0 之后完全使用 postMessage
- 不选择 requestIdelCallback 的原因
从 React 的 issues 及之前版本(在 15.6 的源码中能搜到)中可以看到,requestIdelCallback 方法也被 React 尝试过,只是后来因为兼容性、不同机器及浏览器执行效率的问题又被 requestAnimationFrame + setTimeout 的 polyfill 方法替代了
- 不选择 requestAnimationFrame 的原因
参考React实战视频讲解:进入学习
在 React 16.10.0 之前还是使用的 requestAnimationFrame + setTimeout 的方法,配合动态帧计算的逻辑来处理任务,后来也因为这样的效果并不理想,所以 React 团队才决定彻底放弃此方法
requestAnimationFrame 还有个特点,就是当页面处理未激活的状态下,requestAnimationFrame 会停止执行;当页面后面再转为激活时,requestAnimationFrame 又会接着上次的地方继续执行。
为什么不用 Generator、Webworkers 来做任务调度
针对 Generator ,其实 React 团队为此做过一些努力
- Generator 不能在栈中间让出。比如你想在嵌套的函数调用中间让出, 首先你需要将这些函数都包装成 Generator,另外这种栈中间的让出处理起来也比较麻烦,难以理解。除了语法开销,现有的生成器实现开销比较大,所以不如不用。
- Generator 是有状态的, 很难在中间恢复这些状态。
针对 Webworkers , React 团队同样做过一些分析和讨论
关于在 React 中引入 Webworkers 的讨论,我这里仅贴一下在 issues 中看到的部分,因为没有深入去研究来龙去脉,暂不做翻译
- How do you start a worker?
For now I can see the following solutions for this problem:
- separate file that includes only what is necessary for the worker, which would require extra build steps
- create a worker on the fly (blob), which will not work in every browser and I expect would have performance penalties. Also resolving dependencies here for the worker is going to be painful - if not impossible without extra build steps.
- start the entire build in multiple workers, still this would still require the usage of a build tool
So yeah, for now I don't see this working without a build tool. My preference would go to the first one.
- How do you determine the root to render into?
I would expect the "main" React to always start in the main thread, and components leaving stubs in this thread to which they can write when they want to. Of course writing to the DOM still needs to be done via the normal React reconciliation mechanism.
It should be possible to have a single worker which is used for multiple components, which makes it a bit more challenging. Probably an extra id needs to be given to communicate to the right component.
- How do we unit test the system?
If you would be testing a render function, it would initially only show the webworker stubs - and testing the result of a webworker would be something different. Something like a callback for a webworker result could work here (waitFor(webworkerId) comes to mind).
If there are other options here or I'm missing something, I would definitely like to hear it!
核心逻辑解析
概念说明
为了方便后续的理解,先对源码中常见的概念或代码块做一个解读
-
Concurrent 模式:
- 将渲染工作分解为多个部分,对任务进行暂停和恢复操作以避免阻塞浏览器。这意味着 React 可以在提交之前多次调用渲染阶段生命周期的方法,或者在不提交的情况下调用它们(默认情况下未启用)
- 整个 Scheduler 的任务调度、时间切片、任务中断及恢复都是依赖于 Concurent 模式及 Fiber 数据结构。
-
Scheduler task
- task 对象
// 一个 scheduler 的任务 var newTask = { id: taskIdCounter++, // 任务id,在 react 中是一个全局变量,每次新增 task 会自增+1 callback: callback, // 在调度过程中被执行的回调函数 priorityLevel: priorityLevel, // 通过 Scheduler 和 React Lanes 优先级融合过的任务优先级 startTime: startTime, // 任务开始时间 expirationTime: expirationTime, // 任务过期时间 sortIndex: -1 // 排序索引, 全等于过期时间. 保证过期时间越小, 越紧急的任务排在最前面 };-
task 执行的本质
- 执行逻辑在 scheduler 包中的 workLoop 方法中,代码如下:
function workLoop(hasTimeRemaining, initialTime) { // ... 其他逻辑 while (currentTask !== null && !(enableSchedulerDebugging )) { // ... 其他逻辑 if (typeof callback === 'function') { // ... 其他逻辑 // 此处即执行 callback var continuationCallback = callback(didUserCallbackTimeout); // ... 其他逻辑 } } // ... 其他逻辑 }- task 执行的方法实质
newTask中的callback是由unstable_scheduleCallback(priorityLevel, callback, options)传入unstable_scheduleCallback方法中的callback是在scheduleCallback(reactPriorityLevel, callback, options)方法中传入scheduleCallback方法中的callback是在ensureRootIsScheduled中的newCallbackNode = scheduleCallback(schedulerPriorityLevel, performConcurrentWorkOnRoot.bind(null, root));设置- 因此可以看到
newTask本质执行的方法是performConcurrentWorkOnRoot,即构建 Fiber 树的任务函数
-
timerQueue 与 taskQueue
-
timerQueue:依据任务的过期时间(expirationTime)排序,过期时间越早,说明越紧急,过期时间小的排在前面。过期时间根据任务优先级计算得出,优先级越高,过期时间越早。
-
taskQueue:依据任务的开始时间(startTime)排序,开始时间越早,说明会越早开始,开始时间小的排在前面。任务进来的时候,开始时间默认是当前时间,如果进入调度的时候传了延迟时间,开始时间则是当前时间与延迟时间的和。
-
两者的联系
- 在创建新的 task 时,如果发现这个任务的执行时间并不紧急,则会将其先放入 timerQueue 队列
- 优先执行的 task 在 taskQueue 队列中
- 在不同的执行阶段会通过
advanceTimers方法,从 timerQueue 中将快过期的任务让如到 taskQueue 队列
function advanceTimers(currentTime) { // Check for tasks that are no longer delayed and add them to the queue. var timer = peek(timerQueue); while (timer !== null) { if (timer.callback === null) { // Timer was cancelled. pop(timerQueue); } else if (timer.startTime <= currentTime) { // Timer fired. Transfer to the task queue. pop(timerQueue); timer.sortIndex = timer.expirationTime; push(taskQueue, timer); } else { // Remaining timers are pending. return; } timer = peek(timerQueue); } }
-
-
Scheduler 与 React 的联系
- 说明:因为 Scheduler 本质可以和 React 分离,在 Scheduler 中也有其自己的任务优先级定义,而 React 中也利用 Lanes 的优先级模型,所以 React 在使用 Scheduler 的任务调度时,需要有一个任务优先级的转换过程
- 源码示例:
function scheduleCallback(reactPriorityLevel, callback, options) { // 将 React 的任务优先级转换为 Scheduler 的任务优先级 var priorityLevel = reactPriorityToSchedulerPriority(reactPriorityLevel); return Scheduler_scheduleCallback(priorityLevel, callback, options); }
核心逻辑解析
仍然推荐大家看一下 7kms 大佬的 React 核心流程图,每深入一个模块,再回过头来看这张图都会有不一样的理解。

核心流程图
- 使用了 Scheduler 任务调度的流程图(Conurrent模式)

- 没有使用 Scheduler 任务的调度的流程图(默认模式,Legacry 模式)

- 从源码可以看到,区别非常简单,就是循环中多了有一个
!shouldYield()的判断,用于做时间切片
// concurrent 模式
function workLoopConcurrent() {
// Perform work until Scheduler asks us to yield
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}
// legacy 模式
function workLoopSync() {
// Already timed out, so perform work without checking if we need to yield.
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
如何实现的任务切片
-
判断条件
- 定义了 yieldInterval 变量,默认写死的是 5ms
- 导出了条件方法 unstable_shouldYield
- 代码部分
var yieldInterval = 5; var deadline = 0; // TODO: Make this configurable { // `isInputPending` is not available. Since we have no way of knowing if // there's pending input, always yield at the end of the frame. exports.unstable_shouldYield = function () { return exports.unstable_now() >= deadline; }; // Since we yield every frame regardless, `requestPaint` has no effect.requestPaint = function () {};}
- 核心逻辑
- 在 react-reconciler 中的 workLoopConcurrent 中应用如下
```javascript
// shouldYield() 方法即 unstable_shouldYield 本身
function workLoopConcurrent() {
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}
-
在 react-scheduler 中的 workLoop 中应用如下
function workLoop(hasTimeRemaining, initialTime) { var currentTime = initialTime; advanceTimers(currentTime); currentTask = peek(taskQueue); // unstable_shouldYield 用于判断是否要中断 while (currentTask !== null && !(enableSchedulerDebugging )) { if (currentTask.expirationTime > currentTime && (!hasTimeRemaining || exports.unstable_shouldYield())) { // This currentTask hasn't expired, and we've reached the deadline. break; } // 省略其他代码 }
- 说明:
- 在理解切片的过程中,我一直思考错了方向,总想着是先把任务按时间切好之后,再顺次执行,以此达到切片的效果
- 其实是另一种实现,举个例子:比如我们切萝卜,并不是先标记好每一段在哪才下手,而是达到一定长度就下手,最终实现了按将萝卜切成相似的一段一段
- 有了这层思考之后,理解切片,其实就是到时间点就停止,到时间点就停止,以此循环,最终看到的结果便是按一定时间段切割的效果
##### 如何实现任务的中断
在理解了上述任务的切片之后,再理解任务的中断就变得非常容易,任务的中断即在 reconciler 和 scheduler 中两个 workLoop 循环的 break
在任务中断的同时,还有两处需要注意的逻辑,即 react 是如何保存中断那一时刻的任务,以便后续恢复
- 在 scheduler 中,在每次执行 workLoop 中的循环时,是在执行 performConcurrentWorkOnRoot 方法
```javascript
function workLoop(hasTimeRemaining, initialTime) {
var currentTime = initialTime;
advanceTimers(currentTime);
currentTask = peek(taskQueue);
// 针对 taskQueue 方法进行循环遍历
while (currentTask !== null && !(enableSchedulerDebugging )) {
if (currentTask.expirationTime > currentTime && (!hasTimeRemaining || exports.unstable_shouldYield())) {
// This currentTask hasn't expired, and we've reached the deadline.
break;
}
// 从当前的 task 中获取执行的方法
var callback = currentTask.callback;
// 如果执行的方法存在,则继续
if (typeof callback === 'function') {
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
var didUserCallbackTimeout = currentTask.expirationTime <= currentTime;
// 此时,执行 callback,即 performConcurrentWorkOnRoot 方法
// 在执行 performConcurrentWorkOnRoot 方法的过程中,如果 reconciler 中的 workLoop 中断了
// 会返回 performConcurrentWorkOnRoot 自身方法,也就是 continuationCallback 会被放到当前 task 的 callback
// 此时 workLoop 的 while 循环中断,但是由于当前 task 并没有从队列中出来,
// 所以下一次执行 workLoop 时,仍然会执行本次存储的 continuationCallback
var continuationCallback = callback(didUserCallbackTimeout);
currentTime = exports.unstable_now();
if (typeof continuationCallback === 'function') {
currentTask.callback = continuationCallback;
} else {
if (currentTask === peek(taskQueue)) {
pop(taskQueue);
}
}
advanceTimers(currentTime);
} // 执行的方法不存在,则将当前任务从 taskQueue 移除
else {
pop(taskQueue);
}
// 获取队列中下一个方法
currentTask = peek(taskQueue);
} // Return whether there's additional work
if (currentTask !== null) {
return true;
} else {
var firstTimer = peek(timerQueue);
if (firstTimer !== null) {
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
return false;
}
}
- reconciler 中的 performConcurrentWorkOnRoot 方法,会在执行时,通过逻辑判断,返回不同的值,当返回的值为其自身时,可以视作是一种中断前的状态保存
function performConcurrentWorkOnRoot(){
// 其他逻辑
// 当 fiber 链表的 callbackNode 在执行时,并没有发生改变
// 则说明当前任务和之前是相同的任务,即上一次执行的任务还可以继续
// 便将其自身返回,用于 scheduler 中的 continuationCallback
if (root.callbackNode === originalCallbackNode) {
// The task node scheduled for this root is the same one that's
// currently executed. Need to return a continuation.
return performConcurrentWorkOnRoot.bind(null, root);
}
// 其他逻辑
}
如何实现任务的恢复
其实到这里,可以发现,在了解了上述的任务切片和任务中断之后,任务恢复的逻辑就很容易理解了。
换一个角度思考,即如果在 reconciler 中的 workLoopConcurrent 被中断了,则会返回一个 performConcurrentWorkOnRoot 方法,在 scheduler 中的 workLoop 发现 continuationCallback 返回的值为一个方法,则会存下当前中断的回调,且不让当前执行的任务出栈,也就意味着当前的 task 没有执行完,下一次循环时可以继续执行,而执行的方法便是 continuationCallback 。
以此,实现了任务的恢复。
个人的一点理解
要理解 scheduler ,要从浏览器的 eventloop 开始理解,就会发现,这其实是3个 loop 循环的配合
- 一个比较泛的流程示例,仅给大家提供一些思考方向

在 React 中宏观来看,针对浏览器、Scheduler 、Reconciler 其实是有3层 Loop。浏览器级别的 eventLoop,Scheduler 级别的 workLoop,Reconciler 级别 workLoopConcurrent 。
- 浏览器的 eventLoop 与 Scheduler 的关系
- 每次 eventLoop 会执行宏任务的队列的宏任务,而 React 中的 Scheduler 就是用宏任务 messageChannel 触发的。
- 当 eventLoop 开始执行跟 Scheduler 有关的宏任务时,Scheduler 会启动一次 workloop,就是在遍历执行 Scheduler 中已存在的 taskQueue 队列的每个 task。
- Scheduler 与 Reconciler 的关系
- Scheduler中的 workLoop 中每执行一次 task,是通过调用 Reconciler 中的 performConcurrentWorkOnRoot 方法,即每一个 task 可以理解为是一个 performConcurrentWorkOnRoot 方法的调用。
- performConcurrentWorkOnRoot 方法每次调用,其本质是在执行 workLoopConcurrent 方法,这个方法是在循环 performUnitOfWork 这个构建 Fiber 树中每个 Fiber 的方法。
因此可以梳理出来,3个大循环,从最开始的 eventLoop 的单个宏任务执行,会逐步触发 Scheduler 和 Reconciler 的任务循环执行。
任务的中断与恢复,实现中断与恢复的逻辑分了2个部分,第一个是 Scheduler 中正在执行的 workloop 的任务中断,第二个是 Reconciler 中正在执行的 workLoopConcurrent 的任务中断
- Reconciler 中的任务中断与恢复:在 workLoopConcurrent 的 while 循环中,通过 shouldYield() 方法来判断当前构建 fiber 树的执行过程是否超时,如果超时,则中断当前的 while 循环。由于每次 while 执行的 fiber 构建方法,即 performUnitOfWork 是按照每个 fiberNode 来遍历的,也就是说每完成一次 fiberNode 的 beginWork + completeWork 树的构建过程,会设置下一次 nextNode 的值 ,可以理解为中断时已经保留了下一次要构建的 fiberNode 指针,以至于不会下一次不知道从哪里继续。
- Scheduler 中的任务中断与恢复:当执行任务时间超时后,如果 Reconciler 中的 performConcurrentWorkOnRoot 方法没有执行完成,会返回其自身。在 Scheduler 中,发现当前任务还有下一个任务没有执行完,则不会将当前任务从 taskQueue 中取出,同时会把 reconciler 中返回的待执行的回调函数继续赋值给当前任务,于是下一次继续启动 Scheduler 的任务时,也就连接上了。同时退出这次中断的任务前,会通过 messageChannel 向 eventLoop 的宏任务队列放入一个新的宏任务。
- 所以任务的恢复,其实就是从下一次 eventLoop 开始执行 Scheduler 相关的宏任务,而执行的宏任务也是 Reconciler 中断前赋值的 fiberNode,也就实现了整体的任务恢复。
Demo 示例
示例仅采取了一些关键代码的示例。
tips:如何调试 React 源码,大家可以查看参考资料中的《React 技术揭秘》中的调试代码环节
不用 Scheduler 任务调度的示例
-
代码示例
- 创建 React 项目后的 index.js 代码
import React from 'react'; import ReactDOM from 'react-dom'; import './index.css'; import App from './App'; // React 默认的渲染模式,即 legacy 模式 // 此模式会使用到 Scheduler 的方法,但并不会做时间切片、任务中断、恢复的相关逻辑 ReactDOM.render( <React.StrictMode> <App /> </React.StrictMode>, document.getElementById('root') );- App.js 代码示例
import List from './scheduler-demo/list' function App() { return ( <div className="App"> <List /> </div> ); } export default App;- list.js 代码示例
import React from 'react' export default function List () { return <ul> {Array(3000).fill(0).map((_, i) => <li>{i}</li>)} </ul> }
- 效果示例
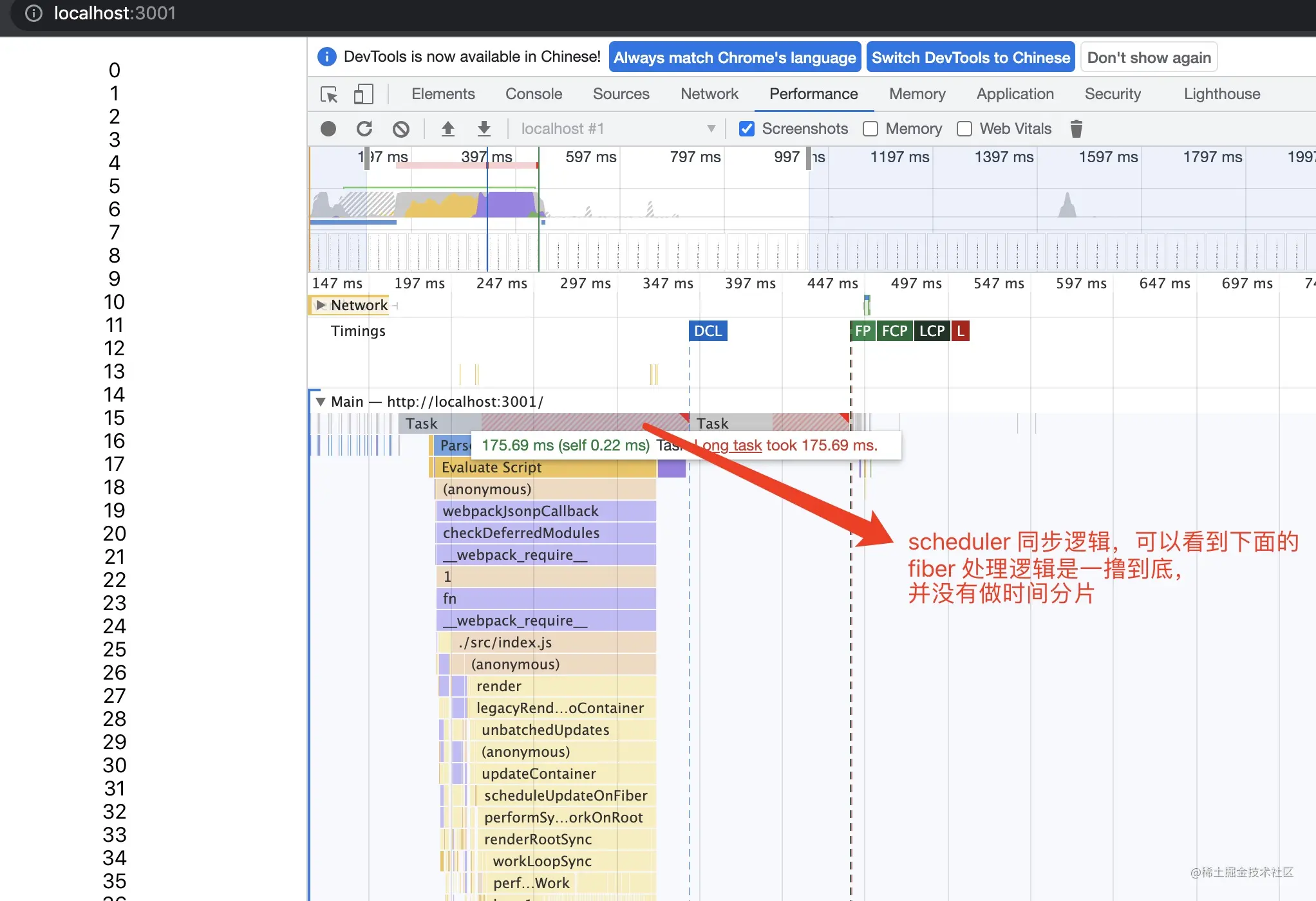
- 结果说明
- 可以从图中示例看到,在没有任务调度的情况下,如果我们存在大量的 DOM 计算,则会将一次计算 DOM 相关的计算进行到底,之后统一输出渲染,可以看到渲染 3000 个 `<li>` 节点,大约耗时 180ms
- 主要关注 React 的逻辑处理,即 `scheduleUpdateOnFiber` 的入口函数
- 可以看到主流程的逻辑,基本都带有 `xxxSync` 的同步命名,也基本说明了在 `legacy` 模式下执行的是同步处理逻辑
##### 利用 Scheduler 任务调度的示例
- 代码示例
- 创建 React 项目后的 index.js 代码
```javascript
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
// React 的 concurrent 渲染模式
// 此模式会使用到 Scheduler 的方法,并且会做时间切片、任务中断、恢复的相关逻辑
ReactDOM.unstable_createRoot(document.getElementById('root')).render( <React.StrictMode>
<App />
</React.StrictMode>);
-
App.js 代码示例、list.js 代码示例不需要调整

- 结果说明
- 可以从图中示例看到,在有任务调度的情况下,会将 DOM 计算的过程切割成一段一段 5ms 左右的宏任务
- 主要关注 React 的逻辑处理,可以看到调用了很多带有
xxxConcurrent的 concurrent 模式特有的方法 - 需要注意并不是每个任务都是完全按照 5ms 这个值进行切割的,会或多或少的类似 5.1 ms、5.2 ms 的切片,这是因为在做切割逻辑时,也会有 js 执行的时间损耗。
- 同时如果某个任务执行过程比较久,也会占用较为大的时间,比如在出现较为稳定的 5ms 切片任务前的第一个任务,大约耗时了 24 ms ,也是因为当前的执行逻辑还并未走进切片逻辑,是其他的 React 执行所耗时。
设置切片时间为 0ms 时 的情景
-
代码示例
- index.js、App.js、list.js 的文件不需要调整,同 concurrent 模式
- 修改引入的 React 源码,主要设置 yieldInterval 的赋值逻辑,示例如下:
// 在 scheduler 相关的源码中 var isMessageLoopRunning = false; var scheduledHostCallback = null; var taskTimeoutID = -1; // Scheduler periodically yields in case there is other work on the main // thread, like user events. By default, it yields multiple times per frame. // It does not attempt to align with frame boundaries, since most tasks don't // need to be frame aligned; for those that do, use requestAnimationFrame. var yieldInterval = 0; // 将此处的值由原来的 5 改为 0 var deadline = 0; // TODO: Make this configurable -
效果示例


- 结果说明
- 从效果示例中可以看到,当切片时间由 5ms 变为 0ms 后,渲染时长变的很长,大约是 5s 之后才将 DOM 渲染出来
- 从 Performance 中可以看出,任务根据 0ms 一段切割成了 n 个宏任务片段,并且很难找到(其实还是有)concurrent 模式下的 React 方法执行
- 所以可以得出一个结论,在 concurrent 模式下,将切片时间由 5ms 变为 0ms 后,Scheduler 还是会切割任务,由于 js 执行本身也是有时间损耗的,所以每一次的 task 执行完全依赖于浏览器内部对于这些产生的宏任务的处理,已经脱离了 Scheduler 本身能控制的范围。即只要用了 concurrent 模式,都会有任务切割、中断、回复,但是产生的效果如何,完全依赖于代码逻辑以及浏览器执行底层的处理。
- 从 Scheduler 的角度出发,大家可以根据情况去设置这个时间切片的节点,还是不建议改为 0 (演示除外)
实现一个 Scheduler 核心逻辑
- 示例代码
const result = 3
let currentResult = 0
function calculate() {
currentResult++
if (currentResult < result) {
return calculate
}
return null
}
// 存放任务的队列
const taskQueue = []
// 存放模拟时间片的定时器
let interval
// 调度入口----------------------------------------
const scheduleCallback = (task, priority) => {
// 创建一个专属于调度器的任务
const taskItem = {
callback: task,
priority
}
// 向队列中添加任务
taskQueue.push(taskItem)
// 优先级影响到任务在队列中的排序,将优先级最高的任务排在最前面
taskQueue.sort((a, b) => (a.priority - b.priority))
// 开始执行任务,调度开始
requestHostCallback(workLoop)
}
// 开始调度-----------------------------------------
const requestHostCallback = cb => {
interval = setInterval(cb, 1000)
}
// 执行任务-----------------------------------------
const workLoop = () => {
// 从队列中取出任务
const currentTask = taskQueue[0]
// 获取真正的任务函数,即calculate
const taskCallback = currentTask.callback
// 判断任务函数否是函数,若是,执行它,将返回值更新到currentTask的callback中
// 所以,taskCallback是上一阶段执行的返回值,若它是函数类型,则说明上一次执行返回了函数
// 类型,说明任务尚未完成,本次继续执行这个函数,否则说明任务完成。
if (typeof taskCallback === 'function') {
currentTask.callback = taskCallback()
console.log('正在执行任务,当前的currentResult 是', currentResult);
} else {
// 任务完成。将当前的这个任务从taskQueue中移除,并清除定时器
console.log('任务完成,最终的 currentResult 是', currentResult);
taskQueue.shift()
clearInterval(interval)
}
}
// 把calculate加入调度,也就意味着调度开始
scheduleCallback(calculate, 1)
- 效果示例
// 输出结果
// 正在执行任务,当前的currentResult 是 1
// 正在执行任务,当前的currentResult 是 2
// 正在执行任务,当前的currentResult 是 3
// 任务完成,最终的 currentResult 是 3
- 结果说明
- 本示例主要展示的是
如何判断单个任务的完成状态 - 本示例展示 Scheduler 中如何对任务中断后如何进行恢复
typeof taskCallback === function - 本示例主要展示了任务完成的逻辑处理
- 本示例并未加入切片的逻辑,其实要加入也并不复杂,即在
workLoop加入循环的判断条件即可,参考 Scheduler 源码
- 本示例主要展示的是
拓展
Scheduler 的开源计划
从 Scheduler 源码的 README.md 中可以看到,React 团队是希望它变得更通用,不仅仅服务于 React,只是现阶段更多是用于 React 中。
- npm 地址:www.npmjs.com/package/sch…
- README.md 原文:
This is a package for cooperative scheduling in a browser environment. It is currently used internally by React, but we plan to make it more generic.
The public API for this package is not yet finalized.
Scheduler 为浏览器提供规范
调度系统的限制:
- 调度系统只能有一个,如果同时存在两个调度系统,就无法保证调度的正确性。
- 调度系统能力有限,只能在浏览器提供的能力范围内进行调度,而无法影响比如 HTML 渲染、内存回收周期。
为了解决这个问题,Chrome 正在与 React、Polymer、Ember、Google Maps、Web Standars Community 共同创建一个浏览器调度规范,提供浏览器级别 API,可以让调度控制更底层的渲染时机,也保证调度器的唯一性。
React 18 的离屏渲染
React 的离屏渲染是在 React 18 中的一个新 API,作用可以先视作 keep-alive 的实现
之所以在这里提一下离屏渲染,是因为这也是一种提升用户体验,减少用户卡顿的优化体验。如果说 Scheduler 任务调度器是为了能够让一个任务不至于将用户页面卡死,那么离屏渲染则是能够让用户在看到页面时就不需要再等待。
-
React 18 中提出的新 API
- 原文如下,防止变味不做硬翻
The main motivation for the new Offscreen API (and the effects changes described in this post) is to allow React to preserve state like this by hiding components instead of unmounting them. To do this React will call the same lifecycle hooks as it does when unmounting– but it will also preserve the state of both React components and DOM elements.
-
离屏渲染的拓展(此处的说明已与 React 无关):
- 概念:指的是 GPU 在当前屏幕缓冲区以外新开辟一个缓冲区(离屏缓存区)进行渲染操作。等所有数据都在离屏渲染区完成渲染后才会提交到帧缓存区,然后再被显示。
- 应用场景:Android、IOS、Electron
- 个人理解:需要利用 GPU 做辅助渲染,方便 CPU 在使用时直接显示。假如某一天浏览器(比如在 React)中要实现类似的功能,那么必然需要借助 Canvas 3D 模式 + WebGL 才有可能触发 GPU 的计算和渲染,那时前端能做的事情将更加炫酷,当然这个和现在的图形图像方向并非一件事。
Vue 和 React 优化方案的选择
JavaScript 是单线程运行的,它要负责页面的 JS 解析和执行、绘制、事件处理、静态资源加载和处理。
Javascript 引擎是单线程运行的。 严格来说,Javascript 引擎和页面渲染引擎在同一个渲染线程,GUI 渲染和 Javascript执行 两者是互斥的. 另外异步 I/O 操作底层实际上可能是多线程的在驱动。
它只是一个 JavaScript ,同时只能做一件事情,这个和 DOS 的单任务操作系统一样的,事情只能一件一件的干。要是前面有一个任务长期霸占 CPU,后面什么事情都干不了,浏览器会呈现卡死的状态,这样的用户体验就会非常差。
对于“前端框架”来说,解决这种问题有三个方向:
- 优化每个任务,让它有多快就多快。挤压 CPU 运算量
- 快速响应用户,让用户觉得够快,不能阻塞用户的交互
- 尝试 Worker 多线程
Vue 选择的是第1种,因为对于 Vue 来说,使用模板让它有了很多优化的空间,配合响应式机制可以让 Vue 可以精确地进行节点更新;而 React 选择了第2种 。对于 Worker 多线程渲染方案也有人尝试,要保证状态和视图的一致性相当麻烦。
个人理解:
- Vue 通过 Object.defineProperty/Proxy 等方式,控制每次执行的点,每次只需要更新需要的部分。因为每次可以只更新部分
- React 则是通过 Fiber、Scheduler 的结合,控制每次执行的量,每次尽可能不影响浏览器主流程的情况下尽可能多的执行任务,因为每次都会走一遍 Fiber 的遍历
杂谈
- React-Scheduler 的源码中,也使用了数据结构和算法,timerQueue、taskQueue 就使用了小顶堆排序的数据结构及算法,感兴趣的同学可以去深入了解
- 如果你要抓浏览器的 performance ,最好在无痕模式,因为这样的话可以避免一些插件的干扰
- 在 React 的 issues 中搜索 requestIdleCallback、requestAnimateCallback、MessageChannel 可以看到很多关于这3个问题的渐进式迭代过程,以及相关的讨论和原因
- 在探索 React 相关的问题中,有一个感受就是,在 React 不断迭代的过程中,其团队会在源码中尝试各种想法,但是并不影响其最终发版的文档版本。比如从 15.6 版本中就出现了 Fiber,但是并未向外暴露,当我们去看最终稳定版时,并没有相关源码。所以当我们看到很多概念,在源码中并没有找到时,或者当你发现一些稳定版没有的内容时,不要急于否定。因为开发版和稳定版往往是通过最终发包的不同做了区分。我们可以多去 issues 中探寻一些痕迹,会帮助我们理解 React 团队的整个思考过程
- 学习方法建议:看文章一定要多看几篇,尤其是要优先看官方文档、源代码,之后再配合一些成体系的文章、以及单篇的精讲(比如本文),单篇的精讲也要多找一些,兼听则明。因为不同的作者在其研究相关知识点的过程中,除了一些共识点外,也会流露出一些他们思考的方式及思考的维度。而恰恰是这些值得发散的点,往往能帮助我们理解核心的细节。切记:不要背文章,也不用仅相信一篇文章(包括本文)。