Kafka RecordAccumulator 三 高并发写入数据

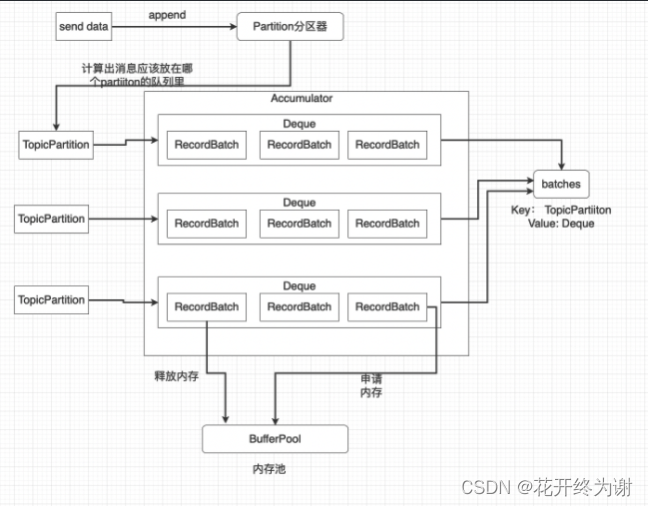
首先我们客户端会通过多线程的方式来发送消息(一般业务需求可能会通过业务系统或者大数据流计算系统如Spark Streaming或者Flink将业务数据发送出去,进而让下游系统消费使用),那这里业务日志可能数据量巨大,会开多线程进行发送数据,这里就会涉及两个问题:
-
线程安全
-
高并发,高吞吐
最简单的方式就是将Append这个方法全局加锁,变成 synchronized append(xxxxx), 但是这样子就会导致锁对整个函数方法的内容加锁,锁了太多内容了,那怎么办呢,就执行分段加锁。
分段加锁:
其大致的样子如下:
append(
xxxxx
synchronized(dp) {
xxxx
}
xxxx
synchronized(dp) {
xxxx
}
)
分析第一次数据发送的执行流程
-
因为数据是第一次发送进来,那么实际上它对应的分区的对列还没创建出来
Deque<RecordBatch> dq = getOrCreateDeque(tp);首先这段代码是线程安全的,因为内部用的是之前分析的CopyOnWriteMap这种读写分离高性能读的线程安全的数据结构, 然后会第一次创建出这个这个分区的一个空对列
-
第一次尝试发送数据
synchronized (dq) { //线程一进来了 //线程二进来了 if (closed) throw new IllegalStateException("Cannot send after the producer is closed."); /** * 步骤二: * 尝试往队列里面的批次里添加数据 * * 一开始添加数据肯定是失败的,我们目前只是以后了队列 * 数据是需要存储在批次对象里面(这个批次对象是需要分配内存的) * 我们目前还没有分配内存,所以如果按场景驱动的方式, * 代码第一次运行到这儿其实是不成功的。 */ RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq); //线程一 进来的时候, //第一次进来的时候appendResult的值就为null if (appendResult != null) return appendResult; }//释放锁加锁确保这段代码线程安全, 重点分析下tryAppend方法
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, Deque<RecordBatch> deque) { //首先要获取到队列里面一个批次 RecordBatch last = deque.peekLast(); //第一次进来是没有批次的,所以last肯定为null //线程二进来的时候,这个last不为空 if (last != null) { //线程二就插入数据就ok了 FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds()); if (future == null) last.records.close(); else //返回值就不为null了 return new RecordAppendResult(future, deque.size() > 1 || last.records.isFull(), false); } return null; }
因为是第一次进来,那么当前分区还只有一个空对列。因此从这个空对列的队尾获取批次一定是空的,所以last是空的,就直接返回了。
-
因为第一次上面代码返回的是空,所以下面代码继续,这里就需要执行申请内存空间
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value)); log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition()); ByteBuffer buffer = free.allocate(size, maxTimeToBlock); -
第一次申请内存后,执行创建批次,写数据的内容。这里面加锁
synchronized (dq) { if (closed) throw new IllegalStateException("Cannot send after the producer is closed."); /** * 步骤五: * 尝试把数据写入到批次里面。 * 代码第一次执行到这儿的时候 依然还是失败的(appendResult==null) * 目前虽然已经分配了内存 * 但是还没有创建批次,那我们向往批次里面写数据 * 还是不能写的。 * */ RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq); //失败的意思就是appendResult 还是会等于null if (appendResult != null) { //释放内存 //线程二到这儿,其实他自己已经把数据写到批次了。所以 //他的内存就没有什么用了,就把内存个释放了(还给内存池了。) free.deallocate(buffer); return appendResult; } /** * 步骤六: * 根据内存大小封装批次 * * * 线程一到这儿 会根据内存封装出来一个批次。 */ MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize); RecordBatch batch = new RecordBatch(tp, records, time.milliseconds()); //尝试往这个批次里面写数据,到这个时候 我们的代码会执行成功。 //线程一,就往批次里面写数据,这个时候就写成功了。 FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds())); /** * 步骤七: * 把这个批次放入到这个队列的队尾 * * * 线程一把批次添加到队尾 */ dq.addLast(batch); incomplete.add(batch); return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true); }//释放锁
一开始还是执行RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
执行这里还是空,因为批次对象还没创建出来,所以返回的是null,所以它后面开始执行创建批次对象了:
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
那么一旦批次对象创建出来了后,在执行写数据,那么就OK了,第一次数据就可以写进去了。
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds())); 再把批次对象放到队尾,方便后面这个分区数据再次写进来的时候直接从队尾取出这个批次对象,塞数据用。
分析多线程发送数据时,如何确保高并发高性能
假设我们有三个线程,并且在假设正好每个线程发送的数据 正好都是同一个分区
-
获取对列
Deque<RecordBatch> dq = getOrCreateDeque(tp);
假设线程1创建出了对列,并写入到batches里面,另外两个线程就可以直接获取到该对垒对象了。
-
尝试首次写数据
synchronized (dq) { //线程一进来了 //线程二进来了 if (closed) throw new IllegalStateException("Cannot send after the producer is closed."); /** * 步骤二: * 尝试往队列里面的批次里添加数据 * * 一开始添加数据肯定是失败的,我们目前只是以后了队列 * 数据是需要存储在批次对象里面(这个批次对象是需要分配内存的) * 我们目前还没有分配内存,所以如果按场景驱动的方式, * 代码第一次运行到这儿其实是不成功的。 */ RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq); //线程一 进来的时候, //第一次进来的时候appendResult的值就为null if (appendResult != null) return appendResult; }//释放锁假设线程1 执行这段代码,因为第一次所以返回空,释放锁,正好被线程2抢到,然后线程2也是第一次进来,所以返回还是空,释放锁,然后线程3抢到锁,也是第一次进来,所以返回还是空。
-
每个申请都会执行申请内存
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value)); log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition()); /** * 步骤四: * 根据批次的大小去分配内存 * * * 线程一,线程二,线程三,执行到这儿都会申请内存 * 假设每个线程 都申请了 16k的内存。 * * 线程1 16k * 线程2 16k * 线程3 16k * */ ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
获取size这个不加锁,后面申请内存部分会加锁。假设线程1线抢到锁,然后申请了16K的内存释放锁,然后线程2抢到锁,申请16K内存释放锁,再然后线程3抢到锁,申请了16K内存,释放锁。这样每个线程多申请了各自的内存.
-
执行创建批次对象,写数据
synchronized (dq) { //假设线程一 进来了。 //线程二进来了 // Need to check if producer is closed again after grabbing the dequeue lock. if (closed) throw new IllegalStateException("Cannot send after the producer is closed."); /** * 步骤五: * 尝试把数据写入到批次里面。 * 代码第一次执行到这儿的时候 依然还是失败的(appendResult==null) * 目前虽然已经分配了内存 * 但是还没有创建批次,那我们向往批次里面写数据 * 还是不能写的。 * * 线程二进来执行这段代码的时候,是成功的。 */ RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq); //失败的意思就是appendResult 还是会等于null if (appendResult != null) { //释放内存 //线程二到这儿,其实他自己已经把数据写到批次了。所以 //他的内存就没有什么用了,就把内存个释放了(还给内存池了。) free.deallocate(buffer); return appendResult; } /** * 步骤六: * 根据内存大小封装批次 * * * 线程一到这儿 会根据内存封装出来一个批次。 */ MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize); RecordBatch batch = new RecordBatch(tp, records, time.milliseconds()); //尝试往这个批次里面写数据,到这个时候 我们的代码会执行成功。 //线程一,就往批次里面写数据,这个时候就写成功了。 FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds())); /** * 步骤七: * 把这个批次放入到这个队列的队尾 * * * 线程一把批次添加到队尾 */ dq.addLast(batch); incomplete.add(batch); return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true); }//释放锁
假设线程1先获取到锁,所以线程1会在整个锁的生命周期内做完所有的事情,并且把该分区的批次对象放到对列的尾巴,这时候线程1执行完之后,释放锁,假设此时线程2获取到锁,开始执行代码,首先第一步线程2尝试append数据:
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, Deque<RecordBatch> deque) {
//首先要获取到队列里面一个批次
RecordBatch last = deque.peekLast();
//第一次进来是没有批次的,所以last肯定为null
//线程二进来的时候,这个last不为空
if (last != null) {
//线程二就插入数据就ok了
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future == null)
last.records.close();
else
//返回值就不为null了
return new RecordAppendResult(future, deque.size() > 1 || last.records.isFull(), false);
}
//返回结果就是一个null值
return null;
}
此时因为线程1已经在对列尾部添加了批次对象,所以线程2直接从队尾取已经不是空了,所以执行last.append真正开始加数据进去了
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, long now) {
if (!this.records.hasRoomFor(key, value)) {
return null;
} else {
//TODO 往批次里面去写数据
long checksum = this.records.append(offsetCounter++, timestamp, key, value);
this.maxRecordSize = Math.max(this.maxRecordSize, Record.recordSize(key, value));
this.lastAppendTime = now;
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length);
if (callback != null)
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
加完之后返回RecordAppendResult对象,代表已经成功加到批次里。
然后就是很重要的地方加成功到批次里了,就可以释放申请的内存了
if (appendResult != null) {
//释放内存
//线程二到这儿,其实他自己已经把数据写到批次了。所以
//他的内存就没有什么用了,就把内存个释放了(还给内存池了。)
free.deallocate(buffer);
return appendResult;
}
经过这一系列的做法就可以高效支撑多个并发的数据写入
标签:RecordAccumulator,批次,写入,value,Kafka,线程,内存,appendResult,null From: https://www.cnblogs.com/kason-seu/p/16883765.html