
大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
村上春树有本著名的小说名叫《当我谈跑步时我谈些什么》,讲述了一个人怎么样通过跑步去悟道出人生的很多哲理与感悟。而读书的价值,就是让我们可以将别人参悟出的道理化为己用,将别人走过的路化为充实自己的养料。
在上一篇文章《手写本地缓存实战1——各个击破,按需应对实际使用场景》中,我们领略了实际项目中一些零散的缓存场景的实现方式,并对缓存实现中的LRU淘汰策略、TTL过期清理机制实现方案进行了探讨。作为《深入理解缓存原理与实战设计》系列专栏的第四篇文章,我们将在上一篇的基础之上进行升华,一起思考如何构建一个完整且通用的本地缓存框架,并在过程中体会缓存实现的关键点与架构设计的思路。
有的小伙伴可能会有疑问,现在有很多成熟的开源库,比如JAVA项目的Guava cache、Caffeine Cache、Spring Cache等(这些在我们的系列文章中,后面都会逐个介绍),它们都提供了相对完善、开箱即用的本地缓存能力,为什么这里还要去自己手写本地缓存呢?这不是重复造轮子吗?
是也?非也!在编码的进阶之路上,“会用”永远都只是让自己停留在入门级别。正所谓知其然更要知其所以然,通过一起探讨手写缓存的实现与设计关键点,来切身的体会蕴藏在缓存架构中的设计哲学。只有真正的掌握其原理,才能在使用中更好的去发挥其最大价值。

缓存框架定调
在一个项目系统中需要缓存数据的场景会非常多,而且需要缓存的数据类型也不尽相同。如果每个使用到缓存的地方,我们都单独的去实现一套缓存,那开发小伙伴们的工作量又要上升了,且后续各业务逻辑独立的缓存部分代码的维护也是一个可预见的头疼问题。
作为应对之法,我们的本地缓存必须往一个更高层级进行演进,使得项目中不同的缓存场景都可以通用 —— 也即将其抽象封装为一个通用的本地缓存框架。既然定位为业务通用的本地缓存框架,那至少从规范或者能力层面,具备一些框架该有的样子:
-
泛型化设计,不同业务维度可以通用
-
标准化接口,满足大部分场景的使用诉求
-
轻量级集成,对业务逻辑不要有太强侵入性
-
多策略可选,允许选择不同实现策略甚至是缓存存储机制,打破众口难调的困局
下面,我们以上述几个点要求作为出发点,一起来勾勒一个符合上述诉求的本地缓存框架的模样。
缓存框架实现
缓存容器接口设计
在前一篇文章中,我们有介绍过项目中常见的缓存使用场景。基于提及的几种具体应用场景,我们可以归纳出业务对本地缓存的API接口层的一些共性诉求。如下表所示:
| 接口名称 | 含义说明 |
|---|---|
| get | 根据key查询对应的值 |
| put | 将对应的记录添加到缓存中 |
| remove | 将指定的缓存记录删除 |
| containsKey | 判断缓存中是否有指定的值 |
| clear | 清空缓存 |
| getAll | 传入多个key,然后批量查询各个key对应的值,批量返回,提升调用方的使用效率 |
| putAll | 一次性批量将多个键值对添加到缓存中,提升调用方的使用效率 |
| putIfAbsent | 如果不存在的情况下则添加到缓存中,如果存在则不做操作 |
| putIfPresent | 如果key已存在的情况下则去更新key对应的值,如果不存在则不做操作 |
为了满足一些场景对数据过期的支持,还需要提供或者重载一些接口用于设定过期时间:
| 接口名称 | 含义说明 |
|---|---|
| expireAfter | 用于指定某个记录的过期时间长度 |
| put | 重载方法,增加过期时间的参数设定 |
| putAll | 重载方法,增加过期时间的参数设定 |
基于上述提供的各个API方法,我们可以确定缓存的具体接口类定义:
/**
* 缓存容器接口
*
* @author 架构悟道
* @since 2022/10/15
*/
public interface ICache<K, V> {
V get(K key);
void put(K key, V value);
void put(K key, V value, int timeIntvl, TimeUnit timeUnit);
V remove(K key);
boolean containsKey(K key);
void clear();
boolean containsValue(V value);
Map<K, V> getAll(Set<K> keys);
void putAll(Map<K, V> map);
void putAll(Map<K, V> map, int timeIntvl, TimeUnit timeUnit);
boolean putIfAbsent(K key, V value);
boolean putIfPresent(K key, V value);
void expireAfter(K key, int timeIntvl, TimeUnit timeUnit);
}
此外,为了方便框架层面对缓存数据的管理与维护,我们也可以定义一套统一的管理API接口:
| 接口名称 | 含义说明 |
|---|---|
| removeIfExpired | 如果给定的key过期则直接删除 |
| clearAllExpiredCaches | 清除当前容器中已经过期的所有缓存记录 |
同样地,我们可以基于上述接口说明,敲定接口定义如下:
public interface ICacheClear<K> {
void removeIfExpired(K key);
void clearAllExpiredCaches();
}
至此,我们已完成了缓存的操作与管理维护接口的定义,下面我们看下如何对缓存进行维护管理。
缓存管理能力构建
在一个项目中,我们会涉及到多种不同业务维度的数据缓存,而不同业务缓存对应的数据存管要求也各不相同。
比如对于一个公司行政管理系统而言,其涉及到如下数据的缓存:
- 部门信息
部门信息量比较少,且部门组织架构相对固定,所以需要全量存储,数据不允许过期。
- 员工信息
员工信息总体体量也不大,但是员工信息可能会变更,如员工可能会修改签名、头像或者更换部门等。这些操作对实时性的要求并不高,所以需要设置每条记录缓存30分钟,超时则从缓存中删除,后续使用到之后重新查询DB并写入缓存中。
从上面的示例场景中,可以提炼出缓存框架需要关注到的两个管理能力诉求:
-
需要支持托管多个缓存容器,分别存储不同的数据,比如部门信息和员工信息,需要存储在两个独立的缓存容器中,需要支持获取各自独立的缓存容器进行操作。
-
需要支持选择多种不同能力的缓存容器,比如常规的容器、支持数据过期的缓存容器等。
-
需要能够支持对缓存容器的管理,以及缓存基础维护能力的支持,比如销毁缓存容器、比如清理容器内的过期数据。
基于上述诉求,我们敲定管理接口类如下:
| 接口名称 | 含义说明 |
|---|---|
| createCache | 创建一个新的缓存容器 |
| getCache | 获取指定的缓存容器 |
| destoryCache | 销毁指定的缓存容器 |
| destoryAllCache | 销毁所有的缓存容器 |
| getAllCacheNames | 获取所有的缓存容器名称 |
对应地,可以完成接口类的定义:
public interface ICacheManager {
<K, V> ICache<K, V> getCache(String key, Class<K> keyType, Class<V> valueType);
void createCache(String key, CacheType cacheType);
void destoryCache(String key);
void destoryAllCache();
Set<String> getAllCacheNames();
}
在上一节关于缓存容器的接口划定描述中,我们敲定了两大类的接口,一类是提供给业务调用的,另一类是给框架管理使用的。为了简化实现,我们的缓存容器可以同时实现这两类接口,对应UML图如下:
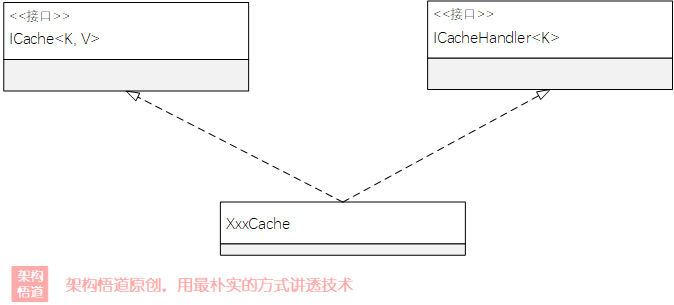
为了能让业务自行选择使用的容器类型,可以通过专门的容器工厂来创建,根据传入的缓存容器类型,创建对应的缓存容器实例:
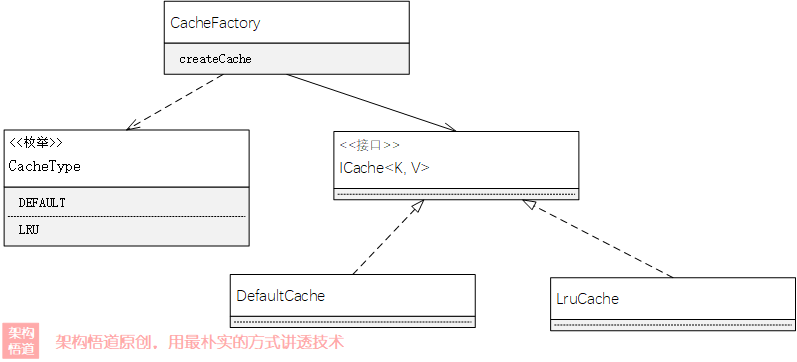
这样,在CacheManager管理层面,我们可以很轻松的完成创建缓存容器或者获取缓存容器的接口实现:
@Override
public void createCache(String key, CacheType cacheType) {
ICache cache = CacheFactory.createCache(cacheType);
caches.put(key, cache);
}
@Override
public <K, V> ICache<K, V> getCache(String cacheCollectionKey, Class<K> keyType, Class<V>valueType) {
try {
return (ICache<K, V>) caches.get(cacheCollectionKey);
} catch (Exception e) {
throw new RuntimeException("failed to get cache", e);
}
}
过期清理
作为缓存,经常会需要设定一个缓存有效期,这个有效期可以基于Entry维度进行实现,并且需要支持到期后自动删除此条数据。在前一篇文章《本地缓存实现的时候需要考虑什么——按需应对实际使用场景》中我们有详细探讨过几种不同的过期数据清理机制,这里我们直接套用结论,采用惰性删除与定期清理结合的策略来实现。
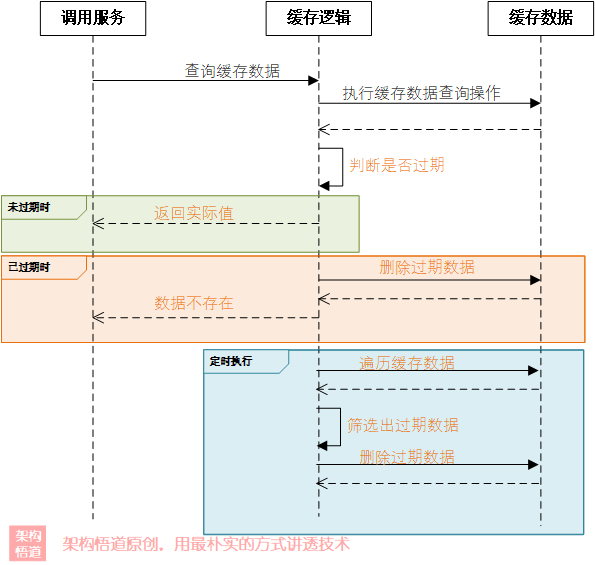
我们对实际缓存数据值套个外壳,用于存储一些管理类的属性,比如过期时间等。然后我们的容器类实现ICacheClear接口,并在对外提供的业务操作接口中进行惰性删除的实现逻辑。
比如对于默认的缓存容器而言,其ICacheClear的实现逻辑可能如下:
@Override
public synchronized void removeIfExpired(K key) {
Optional.ofNullable(data.get(key)).map(CacheItem::hasExpired).ifPresent(expired -> {
if (expired) {
data.remove(key);
}
});
}
@Override
public synchronized void clearAllExpiredCaches() {
List<K> expiredKeys = data.entrySet().stream()
.filter(cacheItemEntry -> cacheItemEntry.getValue().hasExpired())
.map(Map.Entry::getKey)
.collect(Collectors.toList());
for (K key : expiredKeys) {
data.remove(key);
}
}
这样呢,按照惰性删除的策略,在各个业务接口中,需要先调用removeIfExpired方法移除已过期的数据:
@Override
public Optional<V> get(K key) {
removeIfExpired(key);
return Optional.ofNullable(data.get(key)).map(CacheItem::getValue);
}
而在框架管理层面,作为兜底,需要提供定时机制,来清理各个容器中的过期数据:
public class CacheManager implements ICacheManager {
private Map<String, ICache> caches = new ConcurrentHashMap<>();
private List<ICacheHandler> handlers = Collections.synchronizedList(new ArrayList<>());
public CacheManager() {
new Timer().schedule(new TimerTask() {
@Override
public void run() {
System.out.println("start clean expired data timely");
handlers.forEach(ICacheHandler::clearAllExpiredCaches);
}
}, 60000L, 1000L * 60 * 60 * 24);
}
// 省略其它方法
}
这样呢,对缓存的数据过期能力的支撑便完成了。
构建不同能力的缓存容器
作为缓存框架,势必需要面临不同的业务各不相同的诉求。在框架搭建层面,我们整体框架的设计实现遵循着里式替换的原则,且借助泛型进行构建。这样,我们就可以实现给定的接口类,提供不同的缓存容器来满足业务的场景需要。
比如我们需要提供两种类型的容器:
-
普通的键值对容器
-
支持设定最大容量且使用LRU策略淘汰的键值对容器
可以直接创建两个不同的容器类,然后分别实现接口方法即可。对应UML示意如下:
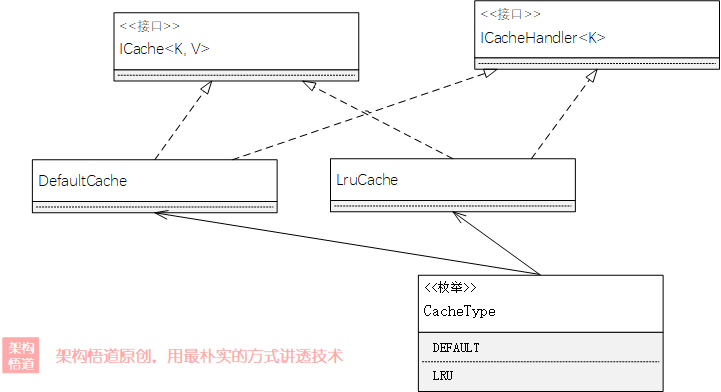
最后,需要将我们创建的不同的容器类型在CacheType中注册下,这样调用方便可以通过指定不同的CacheType来选择使用不同的缓存容器。
@AllArgsConstructor
@Getter
public enum CacheType {
DEFAULT(DefaultCache.class),
LRU(LruCache.class);
private Class<? extends ICache> classType;
}
缓存框架使用初体验
至此呢,我们的本地缓存框架就算是搭建完成了。在业务中有需要使用缓存的场景直接使用CacheManager中的createCache方法创建出对应缓存容器,然后调用缓存容器的接口进行缓存的操作即可。
我们来调用一下,看看使用体验与功能如何。比如我们现在需要为用户信息创建一个独立的缓存,然后往里面写入一个用户记录并设定1s后过期:
public static void main(String[] args) {
manager.createCache("userData", CacheType.LRU);
ICache<String, User> userDataCache = manager.getCache("userData", String.class, User.class);
userDataCache.put("user1", new User("user1"));
userDataCache.expireAfter("user1", 1, TimeUnit.SECONDS);
userDataCache.get("user1").ifPresent(value -> System.out.println("找到用户:" + value));
try {
Thread.sleep(2000L);
} catch (Exception e) {
}
boolean present = userDataCache.get("user1").isPresent();
if (!present) {
System.out.println("用户不存在");
}
}
执行之后,输出结果为:
找到用户:User(userName=user1)
用户不存在
可以发现,完全符合我们的预期,且过期数据清理机也已生效。同样地,如果需要为其它数据创建独立的缓存存储,也参考上面的逻辑,创建自己独立的缓存容器即可。
扩展探讨
分布式场景下本地缓存漂移现象应对策略
在本系列的开篇文章《聊一聊作为高并发系统基石之一的缓存,会用很简单,用好才是技术活》中,我们有提到过一个本地缓存在分布式场景下存在的一个缓存漂移问题:
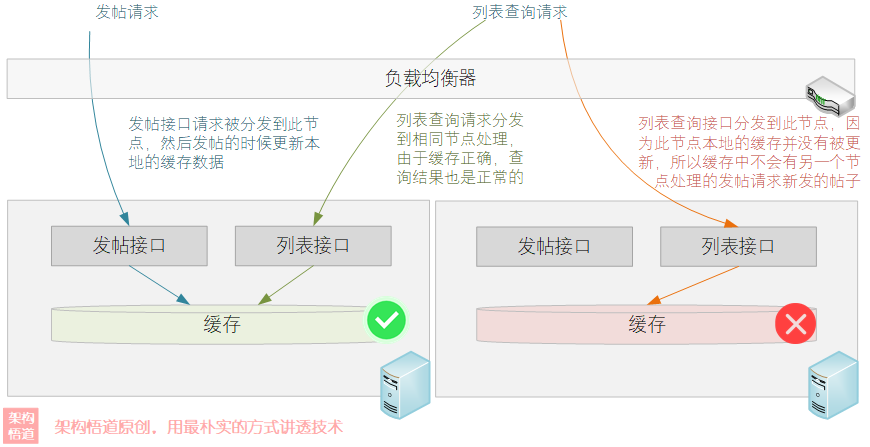
解决缓存漂移问题,一个简单的方案就是借助集中式缓存来解决(比如Redis)。但是在一些简单的小型分布式节点中,不太值得引入太多额外公共组件服务的时候,也可以考虑对本地缓存进行增强,提供一些同步更新各节点缓存的机制。
下面介绍两个两个实现思路。
- 组网广播
在一些小型组网中,当某一个节点执行缓存更新操作的时候,都同时广播一个事件通知给其余节点,各个节点都进行节点自身缓存数据的更新。
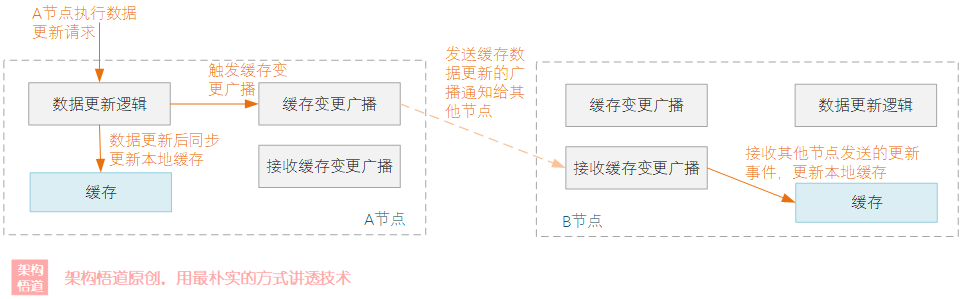
- 定时轮询式
一般的系统中,都会有个数据库节点(比如MySQL),我们可以借助数据库作为一个中间辅助,每次更新之后,都将缓存的更新信息写入一个独立的表中,然后各个缓存节点都定时从DB中拉取增量更新的记录,然后更新到本地缓存中。
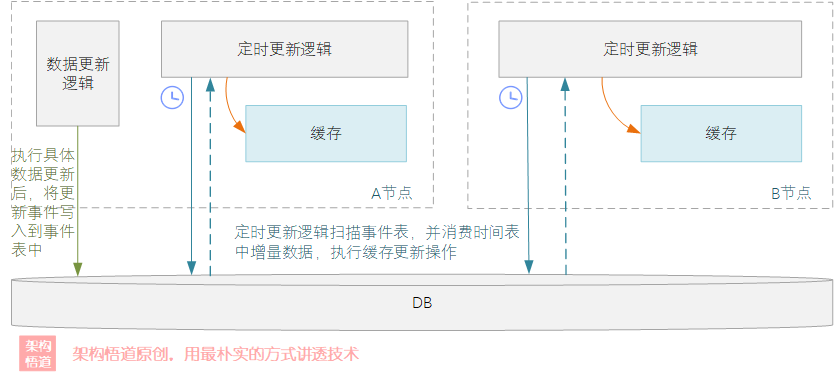
值得注意的是,上面这些思路仅适用于写操作不是很频繁、并且对实时一致性要求不是特别严苛的场景 —— 当然,在实际项目中,真正这么搞的情况比较少。因为本地缓存设计存在的初衷就是用来应对单进程内的缓存独立缓存使用,而这种涉及到多节点之间缓存数据一致保证的场景,本就不是本地缓存的擅长领域。所以在分布式场景下,往往都会直接选择使用集中式缓存。
当然啦,上面我们提到的两种本地缓存同步的机制,都是相对简单的一种实现。一些比较主流的本地缓存框架,也有提供一些集群化数据同步的机制,比如Ehcache就提供了高达5种不同的集群化策略,以达到各个本地缓存节点数据保持一致的效果:
-
RMI组播方式 -
JMS消息方式 -
Cache Server模式 -
JGroup方式 -
Terracotta方式
后续文章中我们会一起探讨下Ehcache的相关内容,这里先卖个关子,到时候我们细聊。
小结回顾
好啦,关于手写本地通用缓存框架的内容,我们就聊这么多。通过本篇内容,我们完成了对前面文章中提过的一些缓存设计理论原则的实践,并一步步的阐述了缓存的设计与实现关键点,更展示了如何让一个缓存模块从简单的能用变为好用、通用。
当然,本篇内容主要是为了通过手写缓存的模式,来让大家更切身的体会缓存实现中的关键点与架构设计思路,并能在后续的使用中更正确的去使用。在实际项目中,除非一些特殊定制诉求需要手动实现缓存机制外,我们倒也不必自己费时劳神地去手写缓存框架,直接采用现有的开源方案即可。比如JAVA类的项目,目前有很多开源库(比如Guava cache、Caffeine Cache、Spring Cache等)都提供了相对完善、开箱即用的本地缓存能力,可以直接使用,在后面的系列文章中,我们将逐个剖析。
那么,关于缓存模块的设计与实现,你是否也曾手动编写过呢?你是如何解决这些问题的呢?你关于这些问题你是否有更好的理解与应对策略呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
标签:容器,缓存,本地,void,接口,key,手写 From: https://www.cnblogs.com/softwarearch/p/16870925.html