欢迎访问我的另一个博客: https://xingzhu.top/
注意:前置知识:
HTTP: https://xingzhu.top/archives/web-fu-wu-qi
Linux 多线程: https://xingzhu.top/archives/duo-xian-cheng
源码放
github上了,欢迎star: https://github.com/xingzhuz/webServer
思路
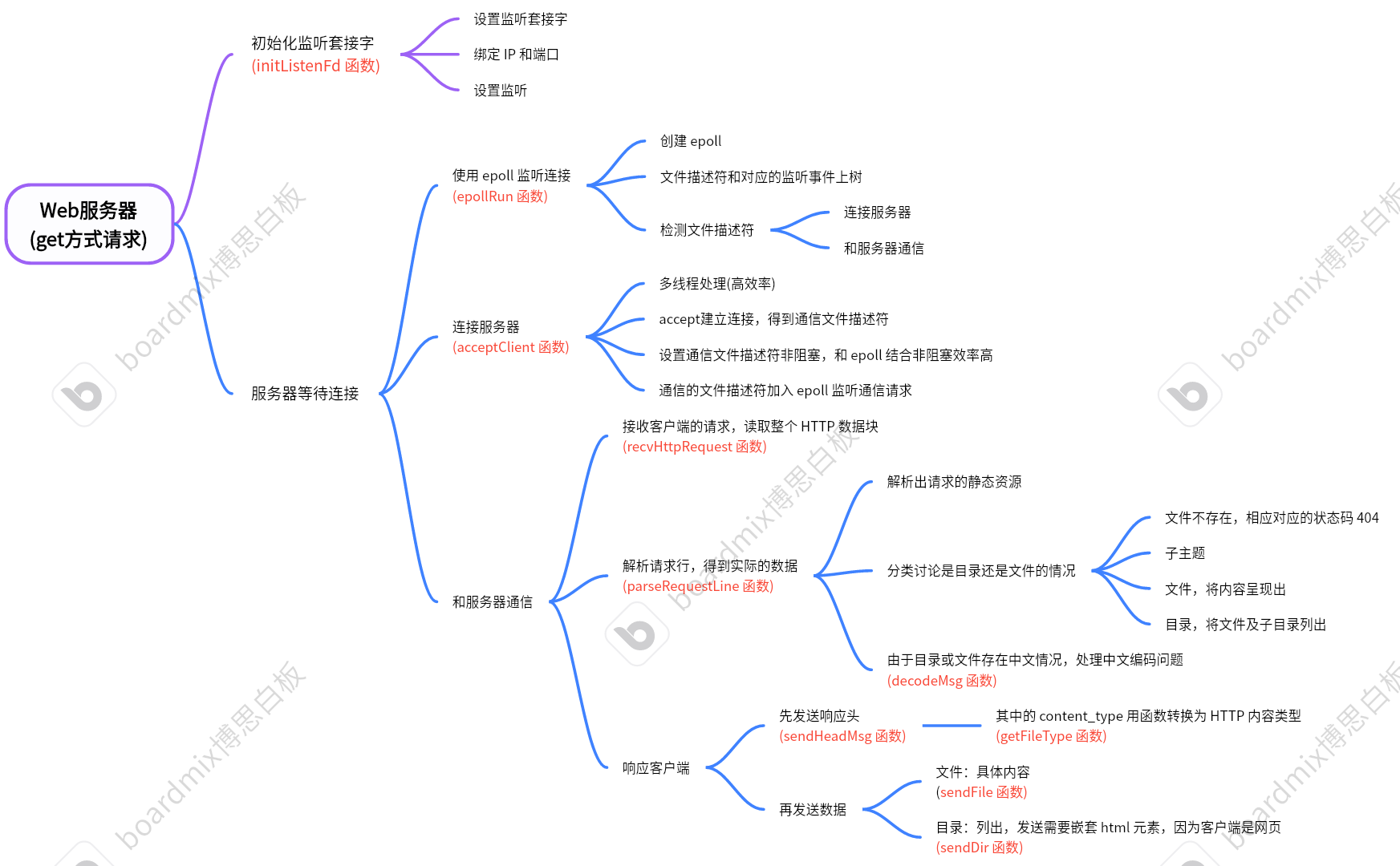
实现代码
server.h
#pragma once
#include <arpa/inet.h>
#include <sys/epoll.h>
#include <stdio.h>
#include <fcntl.h>
#include <errno.h>
#include <sys/stat.h>
#include <assert.h>
#include <sys/sendfile.h>
#include <dirent.h>
#include <string.h>
#include <strings.h>
#include <unistd.h>
#include <stdlib.h>
#include <ctype.h>
#include <pthread.h>
// 子线程执行动作函数的参数结构体
struct FdInfo
{
int fd;
int epfd;
pthread_t tid;
};
// 初始化监听的套接字
int initListenFd(unsigned short port);
// 启动 epoll
int epollRun(int lfd);
// 和客户端建立连接
// int acceptClient(int lfd, int epfd);
void *acceptClient(void *arg);
// 接收http请求
// int recvHttpRequest(int cfd, int epfd);
void *recvHttpRequest(void *arg);
// 解析请求行
int parseRequestLine(const char *line, int cfd);
// 发送文件
int sendFile(const char *fileName, int cfd);
// 发送响应头(状态行+响应头)
int sendHeadMsg(int cfd, int status, const char *descr, const char *type, int length);
// 根据文件名字或者后缀获取 HTTP 格式响应的数据类型
const char *getFileType(const char *name);
// 发送目录
int sendDir(const char *dirName, int cfd);
// 将字符转换为整形数
int hexToDec(char c);
// 解码
// to 存储解码之后的数据,传出参数,from为被解码的数据,传入参数
void decodeMsg(char *to, char *from);
main.c
#include "server.h"
int main(int argc, char *argv[])
{
if (argc < 3)
{
printf("./a.out port path\n");
return -1;
}
unsigned short port = atoi(argv[1]);
// 切换服务器的工作路径
chdir(argv[2]);
// 初始化用于监听的套接字
int lfd = initListenFd(port);
// 启动服务器程序
epollRun(lfd);
return 0;
}
initListenFd
// 初始化监听的套接字
int initListenFd(unsigned short port)
{
// 1.创建监听的fd
int lfd = socket(AF_INET, SOCK_STREAM, 0);
if (lfd == -1)
{
perror("socket");
return -1;
}
// 2. 设置端口复用
int opt = 1;
int ret = setsockopt(lfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof opt);
if (ret == -1)
{
perror("setsocket");
return -1;
}
// 3. 绑定
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = INADDR_ANY;
ret = bind(lfd, (struct sockaddr *)&addr, sizeof addr);
if (ret == -1)
{
perror("bind");
return -1;
}
// 4. 设置监听
ret = listen(lfd, 128);
if (ret == -1)
{
perror("listen");
return -1;
}
// 返回 fd
return lfd;
}
- 这些步骤都是基础的
Socket网络通信部分,不再赘述 - 解释端口复用:因为存在服务器端主动断开连接的情况,如果是服务器端主动断开连接,主动断开的一方存在一个等待时长,也就是在这个等待时长内,端口还是没有被释放,时长结束后才会释放
- 如果不想等待这个时长或者由于这个时长而换端口,就需要设置这个端口复用,设置后即使即使是在等待时长时间段内,仍可使用该端口
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
- sockfd: 套接字的文件描述符,通常是通过
socket()函数创建的 - level: 选项所在的协议层,通常为
SOL_SOCKET,表示通用的套接字选项。也可以是特定协议的层,例如IPPROTO_TCP - optname: 需要设置的选项的名称。可以是多种选项,如:
SO_REUSEADDR: 允许重用本地地址SO_KEEPALIVE: 启用 TCP 的保活机制SO_BROADCAST: 允许发送广播消息
- optval: 指向要设置的选项值的指针。这个值的类型取决于选项的类型
- optlen:
optval所指向的值的大小,通常使用sizeof()来获取
epollRun
int epollRun(int lfd)
{
// 1. 创建 epoll 实例
int epfd = epoll_create(1); // 1 这个参数已被弃用,随便写一个大于 0 的数即可
if (epfd == -1)
{
perror("epoll_create");
return -1;
}
// 2. lfd 上树
struct epoll_event ev;
ev.data.fd = lfd; // data 是一个联合体,只能使用一个成员,这里使用 fd
ev.events = EPOLLIN; // 委托内核需要检测的事件: 检测连接请求,对于服务器而言就是读事件 EPOLLIN
// 参数: epoll id, 操作的动作, 操作的文件描述符, 事件结构体
// 可以做三件事,增加、修改、删除
int ret = epoll_ctl(epfd, EPOLL_CTL_ADD, lfd, &ev);
if (ret == -1)
{
perror("epoll_ctl");
return -1;
}
// 3. 检测
struct epoll_event evs[1024];
int size = sizeof(evs) / sizeof(struct epoll_event);
while (1)
{
// 检测添加到 epoll 树上的文件描述符事件是否被激活,也就是是否有事件到达
// 第四个参数是阻塞时长,如果为 -1 就是一直阻塞
int num = epoll_wait(epfd, evs, size, -1);
for (int i = 0; i < num; i++)
{
struct FdInfo *info = (struct FdInfo *)malloc(sizeof(struct FdInfo));
int fd = evs[i].data.fd;
info->epfd = epfd;
info->fd = fd;
if (fd == lfd)
{
// 如果是监听的文件描述符,建立新连接 accept
// 注意这里的 accept 是不会阻塞的,因为 epoll 已经检测了,只有触发了,才会在 evs 数组中
// 这里创建多线程处理,效率更高
pthread_create(&info->tid, NULL, acceptClient, info);
}
else
{
// 响应客户端请求,接收客户端请求
pthread_create(&info->tid, NULL, recvHttpRequest, info);
}
}
}
}
epoll是 IO 多路转接 / 复用中的一个实现,可以大大提高效率,IO 多路转接/复用可以实现一个线程就监视多个文件描述符,其实现机制是在内核去中监视的,也就是可以大大减小开销,不用手动创建线程阻塞等待连接了,内核区监视是否有连接请求- 而
epoll是实现方式中效率较高的,是基于红黑树实现的,搜索起来快速
acceptClient
void *acceptClient(void *arg)
{
struct FdInfo *info = (struct FdInfo *)arg;
// 1. 建立连接
// 第二三个参数都是客户端相关信息,不需要知道,直接指定为 NULL
int cfd = accept(info->fd, NULL, NULL);
if (cfd == -1)
{
perror("accept");
return NULL;
}
// 2. 设置非阻塞
int flag = fcntl(cfd, F_GETFL); // 第二个参数表示得到当前文件描述符属性
flag |= O_NONBLOCK; // 将非阻塞属性 O_NONBLOCK 追加进去
fcntl(cfd, F_SETFL, flag); // 重新设置文件描述符的属性,即 flag
// 3. cfd 添加到 epoll 中
struct epoll_event ev;
ev.data.fd = cfd;
// 这个加的属性 EPOLLET 表示设置这个通信的文件描述符对应的处理事件为边沿触发模式
ev.events = EPOLLIN | EPOLLET;
int ret = epoll_ctl(info->epfd, EPOLL_CTL_ADD, cfd, &ev);
if (ret == -1)
{
perror("epoll_ctl");
return NULL;
}
printf("acceptClient threadId: %ld\n", info->tid);
free(info);
return 0;
}
epoll工作模式中,边缘非阻塞模式效率最高,因此采用这个,所以设置了文件描述符为非阻塞模式(默认为阻塞)- 这里的连接和接收数据用多线程处理效率更高,即使之前已经实现了多个客户端和多个服务器端通信
recvHttpRequest
void *recvHttpRequest(void *arg)
{
struct FdInfo *info = (struct FdInfo *)arg;
int len = 0, total = 0;
char tmp[1024] = {0};
char buf[4096] = {0};
while ((len = recv(info->fd, tmp, sizeof tmp, 0)) > 0)
{
if (total + len < sizeof buf)
{
memcpy(buf + total, tmp, len);
}
total += len;
}
// 判断数据是否被接收完毕
if (len == -1 && errno == EAGAIN)
{
// 解析请求行
char *pt = strstr(buf, "\r\n");
int reLen = pt - buf;
buf[reLen] = '\0';
parseRequestLine(buf, info->fd);
}
else if (len == 0)
{
// 客户端断开了连接
// 删除在 epoll 树上的文件描述符,因为不需要检测这个文件描述符了
epoll_ctl(info->epfd, EPOLL_CTL_DEL, info->fd, NULL);
close(info->fd);
}
else
perror("recv");
printf("resvMsg threadId: %ld\n", info->tid);
free(info);
return NULL;
}
- 上述
total是偏移量,因为memcpy是从起始位置开始复制 - 虽然
buf只有 4096 字节,存在读不完所有的请求数据,但是这也是没问题的,有用的数据 4096 已经够了,因为请求行最重要,只需要知道客户端向服务器请求的静态资源是什么,即便后面没读完,也不影响 - 由于这个套接字是非阻塞,所以当数据读完后,不阻塞,但是返回 -1,但是读取数据失败也是返回 -1,这就无法判断是否是读取完数据了,此时再用到
errno == EAGAIN就能判断成功 - 如果套接字是阻塞的,当读取完数据后,会一直阻塞,所以书写逻辑需要更改,内部判断是否读取完毕,然后
break循环
parseRequestLine
// 解析请求行
int parseRequestLine(const char *line, int cfd)
{
// 解析请求行 get /xxx/1.jpg http/1.1
char method[12];
char path[1024];
sscanf(line, "%[^ ] %[^ ]", method, path);
if (strcasecmp(method, "get") != 0) // 这个比较忽略大小写
{
// 这里只处理 get 请求
return -1;
}
// 处理中文编码问题
decodeMsg(path, path);
// 处理客户端请求的静态资源(目录或者文件)
char *file = NULL;
if (strcmp(path, "/") == 0)
{
// 说明只有当前资源目录
file = "./";
}
else
{
// 说明目录中存在当前资源目录中的子目录
// 去掉 '/' 就能是相对路径了,就成功了,或者在开头加个 '.' 也行
file = path + 1;
}
// printf("%s\n", file);
// 获取文件属性
struct stat st;
int ret = stat(file, &st);
if (ret == -1)
{
// 文件不存在 -- 回复 404
// 最后一个参数设置为 -1,让浏览器自己计算长度
sendHeadMsg(cfd, 404, "Not Found", getFileType(".html"), -1);
sendFile("404.html", cfd); // 这个 html 需要当前资源目录下的 html文件(自己部署)
return 0;
}
// 判断文件类型
if (S_ISDIR(st.st_mode))
{
// 把这个目录中的内容发送给客户端
sendHeadMsg(cfd, 200, "OK", getFileType(".html"), -1);
sendDir(file, cfd);
}
else
{
// 把文件的内容发送给客户端
sendHeadMsg(cfd, 200, "OK", getFileType(file), st.st_size);
sendFile(file, cfd);
}
}
sendFile
// 发送的数据部分
int sendFile(const char *fileName, int cfd)
{
// 1.打开文件
int fd = open(fileName, O_RDONLY);
// 断言判断文件是否打开成功,如果打开失败,程序直接挂在这里,或者抛出异常
assert(fd > 0);
#if 0
while (1)
{
char buf[1024];
int len = read(fd, buf, sizeof buf);
if (len > 0)
{
send(cfd, buf, len, 0);
usleep(10); // 这非常重要
}
else if (len == 0) // 文件内容读取完毕
break;
else
perror("read");
}
#else
off_t offset = 0;
int size = lseek(fd, 0, SEEK_END);
lseek(fd, 0, SEEK_SET);
while (offset < size)
{
int ret = sendfile(cfd, fd, &offset, size - offset);
printf("ret value: %d\n", ret);
if (ret == -1 && errno != EAGAIN)
{
perror("sendfile");
}
}
#endif
return 0;
}
- 上述是发送文件的两种方式
- 第一种方式的
usleep(10)很重要,发送数据很快,但是客户端读数据不一定这么快,客户端需要读取数据,然后进行解析,然后呈现出,这都需要耗时间的,不休眠一会儿,会存在接收数据不一致的问题(我遭受过...) - 第二种方式使用库函数
sendfile,通过这个函数发送,比手写的发送文件代码效率高,因为会减少拷贝次数,第四个参数是发送的大小,size - offset的原因是offset这个参数是传入传出参数,会偏移到发送的位置,由于多次发送,前面发送了数据之后,就不是size了,就需要减去发送的字节数,也就是传出的偏移量offset - 注意
lseek函数计算文件大小,会移动文件的指针,且sendfile也是有内部也是有缓存大小的,因此需要循环读取发送 if判断是因为文件描述符改为了非阻塞模式,会一直读取数据,如果数据读完,也会返回-1,所以就需要再加个判断
sendHeadMsg
// 发送响应头
int sendHeadMsg(int cfd, int status, const char *descr, const char *type, int length)
{
// 状态行
char buf[4096] = {0};
sprintf(buf, "http/1.1 %d %s\r\n", status, descr);
// 响应头
sprintf(buf + strlen(buf), "content-type: %s\r\n", type);
sprintf(buf + strlen(buf), "content-length: %d\r\n\r\n", length); // 注意两个\r\n
send(cfd, buf, strlen(buf), 0);
return 0;
}
getFileType
// 根据文件名字或者后缀获取 HTTP 格式响应的数据类型
const char *getFileType(const char *name)
{
// a.jpg a.mp4 a.html
// 自右向左查找 '.' 字符,如不存在返回 NULL
const char *dot = strrchr(name, '.');
if (dot == NULL)
return "text/plain;charset=utf-8"; // 纯文本
if (strcmp(dot, ".html") == 0 || strcmp(dot, ".htm") == 0)
return "text/html; charset=utf-8";
if (strcmp(dot, ".jpg") == 0 || strcmp(dot, ".jpeg") == 0)
return "image/jpeg";
if (strcmp(dot, ".gif") == 0)
return "image/gif";
if (strcmp(dot, ".png") == 0)
return "image/png";
if (strcmp(dot, ".css") == 0)
return "text/css";
if (strcmp(dot, ".au") == 0)
return "audio/basic";
if (strcmp(dot, ".wav") == 0)
return "audio/wav";
if (strcmp(dot, ".mp3"))
return "audio/mp3";
// 还有一些未写
return "text/plain; charset = utf-8";
}
sendDir
下述拼接是这样的
<html>
<head>
<title>test</title>
</head>
<body>
<table> <!--- 开头拼接到这 --->
<tr> <!--- 中间部分的拼接 --->
<td></td>
<td></td>
</tr>
<tr>
<td></td>
<td></td>
</tr>
</table> <!--- 尾巴从这开始拼接 -->
</body>
</html>
// 发送目录
int sendDir(const char *dirName, int cfd)
{
char buf[8192] = {0};
sprintf(buf,
"<html>"
"<head>"
"<title>%s</title>"
"<style>"
"body { font-family: Arial, sans-serif; margin: 20px; background-color: #f4f4f4; }"
"h1 { color: #2c3e50; text-align: center; }"
"table { width: 100%%; border-collapse: collapse; margin-top: 20px; }"
"th, td { border: 1px solid #ddd; padding: 12px; text-align: left; }"
"th { background-color: #3498db; color: white; }"
"tr:hover { background-color: #e7f3ff; }"
"a { text-decoration: none; color: #3498db; transition: color 0.3s; }"
"a:hover { color: #2980b9; text-decoration: underline; }"
"</style>"
"</head>"
"<body><h1>%s</h1><table><tr><th>名称</th><th>大小 (字节)</th></tr>",
dirName, dirName);
struct dirent **namelist;
// 第三个参数是回调函数,表示遍历时过滤的规则, 第四个参数是排序的方式
int num = scandir(dirName, &namelist, NULL, alphasort);
// 虽然 namelist 定义时没有分配地址,但是在函数调用后就分配了地址,所以后续要释放内存
for (int i = 0; i < num; i++)
{
// 取出文件名,namelist 指向的是一个指针数组
char *name = namelist[i]->d_name;
struct stat st;
char subPath[1024] = {0};
sprintf(subPath, "%s/%s", dirName, name);
stat(subPath, &st);
if (S_ISDIR(st.st_mode))
{
sprintf(buf + strlen(buf),
"<tr><td><a href=\"%s/\">%s</a></td><td>%ld</td></tr>",
name, name, st.st_size);
}
else
{
sprintf(buf + strlen(buf),
"<tr><td><a href=\"%s\">%s</a></td><td>%ld</td></tr>",
name, name, st.st_size);
}
send(cfd, buf, strlen(buf), 0);
memset(buf, 0, sizeof buf);
free(namelist[i]);
}
sprintf(buf, "</table></body></html>");
send(cfd, buf, strlen(buf), 0);
free(namelist);
return 0;
}
- 拼接
html网页元素,是因为需要一个网页形式发送给浏览器 - 可以拼一份,发一份,因为底层使用的
TCP协议 - 注意上述
a标签那儿\"%s/\"需要\转义,因为前面已经有"了,所以需要用\转义,%s后面加/是因为可能需要点击进入这个子目录,所以必须要这个/
注意: 中文乱码问题
- HTTP 协议中,不支持特殊字符 (如中文),会自动转义为
utf-8编码,也就是如果当前文件名为中文,那么linux会将这个特殊字符转换为utf-8编码 - 如
/Linux%E5%86%85%E6%A0%B8.jpg原本是/Linux内核.jpg,这样之后发送信息时就打不开了,报错Not Found,因为本地文件名是带有中文,但是经过代码处理后,程序读出的文件名没有中文,就找不到了 - 因此需要转换一下
decodeMsg
// 将字符转换为整形数
int hexToDec(char c)
{
if (c >= '0' && c <= '9')
return c - '0';
if (c >= 'a' && c <= 'f')
return c - 'a' + 10;
if (c >= 'A' && c <= 'F')
return c - 'A' + 10;
return 0;
}
// 解码
// to 存储解码之后的数据,传出参数,from被解码的数据,传入参数
void decodeMsg(char *to, char *from)
{
for (; *from != '\0';)
{
// isxdigit -> 判断字符是不是16进制格式,取值在 0-f
if (from[0] == '%' && isxdigit(from[1]) && isxdigit(from[2]))
{
// 将 16进制的数 -> 十进制 将这个数值赋值给了字符 int -> char
*to = hexToDec(from[1]) * 16 + hexToDec(from[2]);
// 跳过 '%' 和后面的两个字符
to++;
from += 3; // 修改为3
}
else
{
// 字符拷贝,赋值
*to = *from;
to++;
from++;
}
}
*to = '\0'; // 添加字符串结束符
}
- 这个没必要理解,直接网上搜索即可,这里让 GPT 润色修改成功的
404.html
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>404 页面未找到</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f4f4f4;
margin: 0;
padding: 0;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
text-align: center;
}
.container {
background-color: #fff;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0, 0, 0, 0.1);
padding: 40px;
max-width: 400px;
width: 100%;
}
h1 {
font-size: 72px;
color: #e74c3c;
margin: 0;
}
h2 {
color: #333;
margin: 20px 0;
}
p {
color: #666;
margin-bottom: 20px;
}
a {
text-decoration: none;
background-color: #3498db;
color: #fff;
padding: 10px 20px;
border-radius: 5px;
transition: background-color 0.3s;
}
a:hover {
background-color: #2980b9;
}
</style>
</head>
<body>
<div class="container">
<h1>404</h1>
<h2>页面未找到</h2>
<p>抱歉,我们找不到您请求的页面。</p>
<a href="/">返回首页</a>
</div>
</body>
</html>
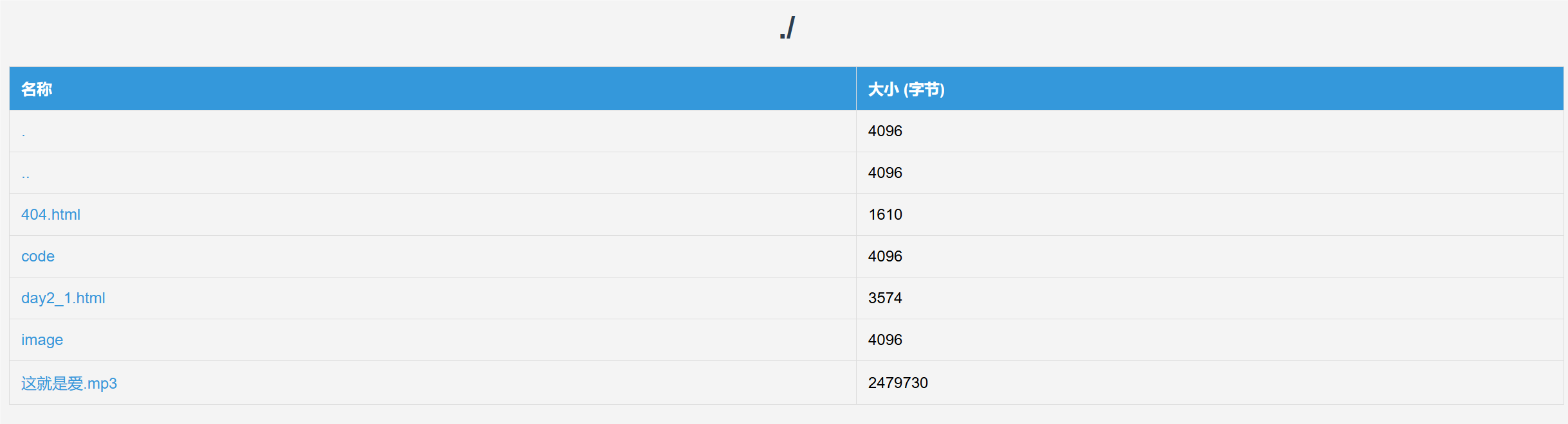
效果展示
# 编译
gcc *.c -o server
./server
- 刚登上服务器页面
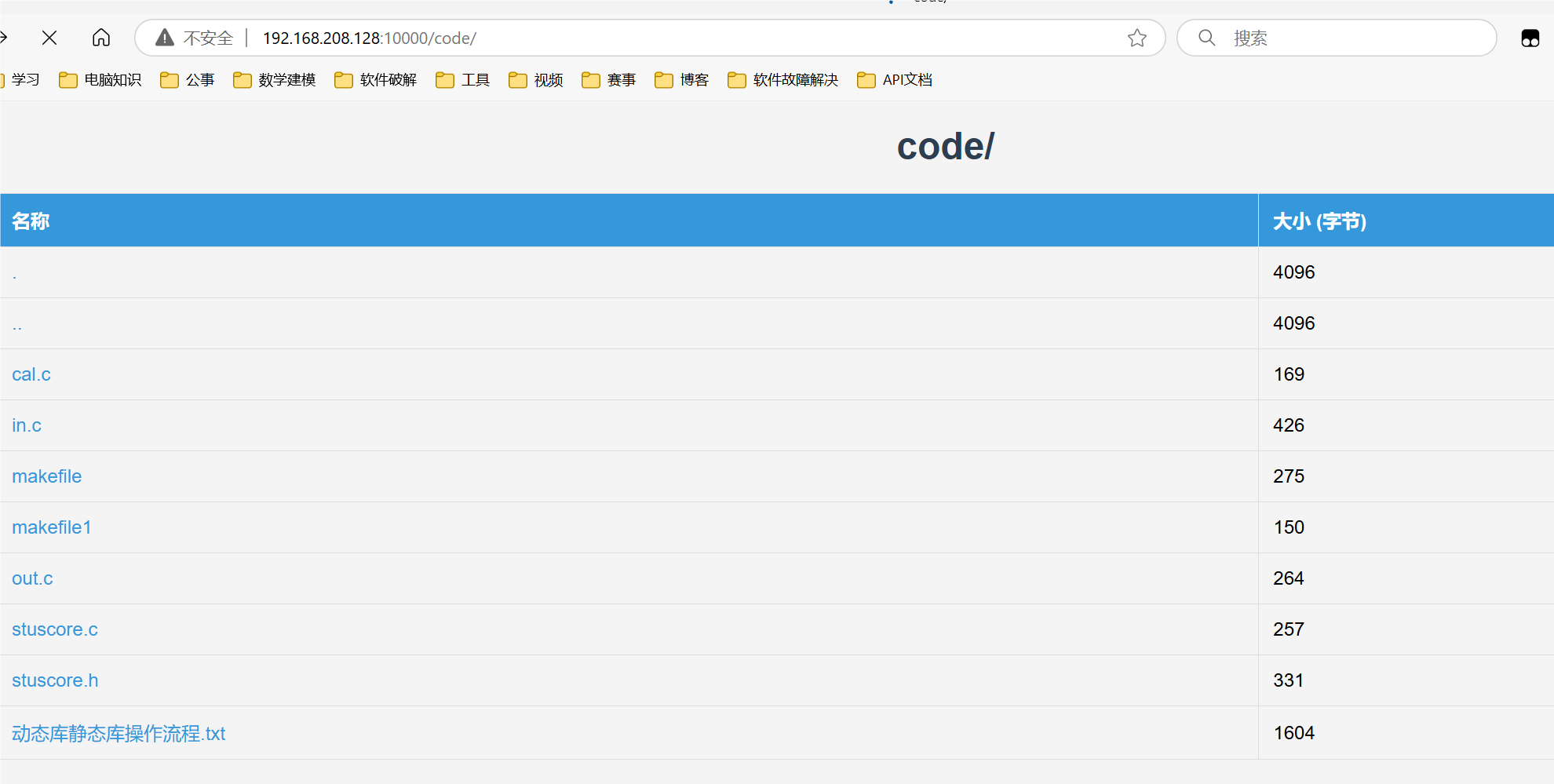
- 点击
code文件目录中的cal.c代码文件
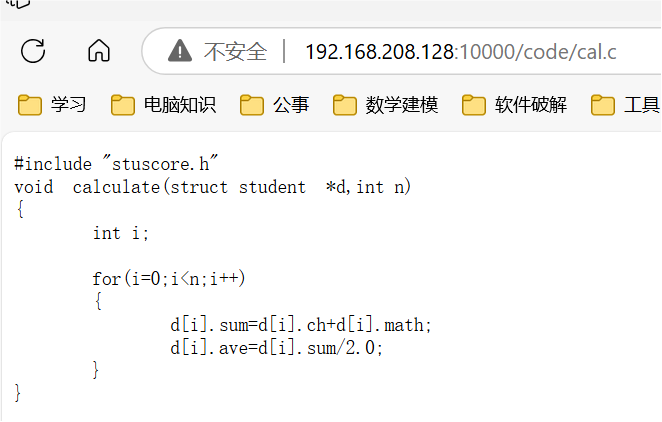
- 点击
html目录中的一个html文件

- 点击
Image目录中的一个图片
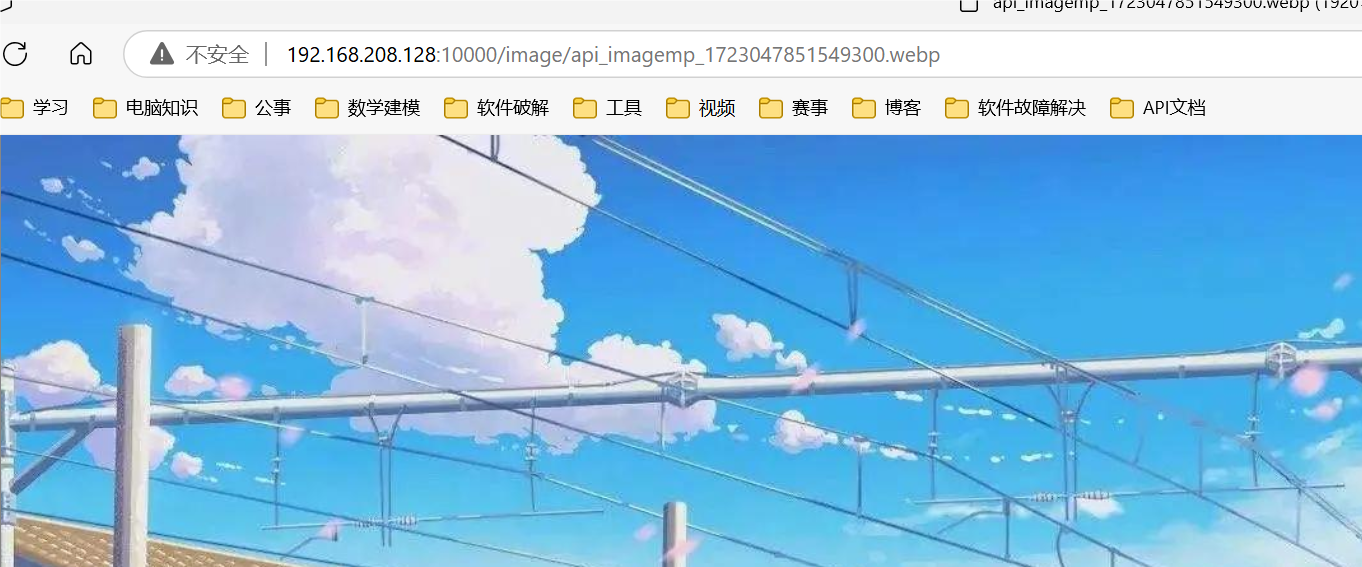
- 点击
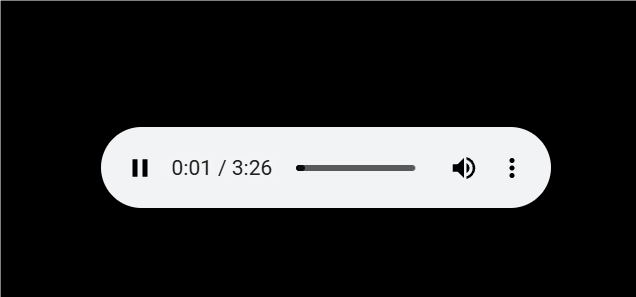
mp3文件,开始播放
- 如果是一个不存在的文件
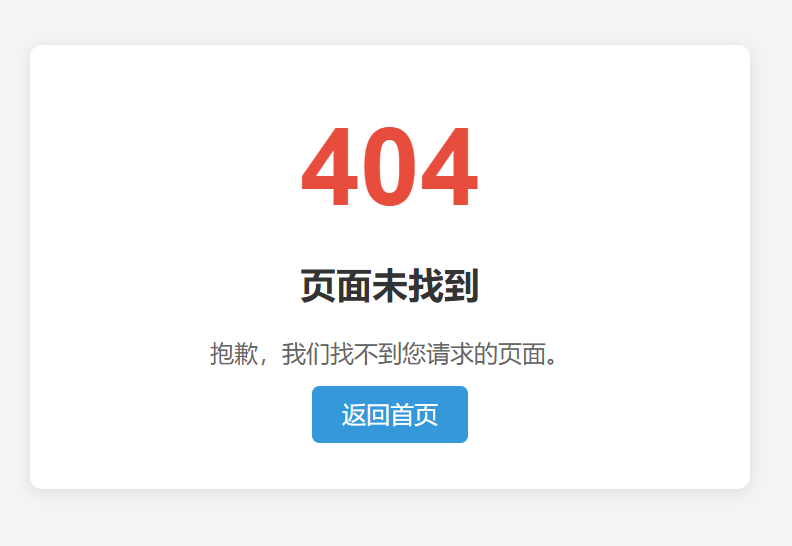
标签:Web,return,epoll,int,cfd,char,Linux,buf From: https://www.cnblogs.com/xingzhuz/p/18440510说明:参考学习:https://subingwen.cn/