C/C++ malloc-free底层原理-动态内存管理
关于动态内存管理这块在面试中被考察频率非常高,切入的点也很多,有从操作系统虚拟内存问起的,也有从 malloc、new 等开始问起的。
但是无外乎就是两块内容:
- 虚拟内存机制:物理和虚拟地址空间、TLB 页表、内存映射
- 动态内存管理:内存管理、分配方式、内存回收、GC等等
malloc采用分离适配的方式,分配器维护着一个空闲链表的数组,每个空闲链表是和一个size class相关联的。
为了分配一个块,必须先确定请求的size class,然后对适当的空闲链表做首次适配,查找一个合适的块。如果找到,那么就分割它,并将剩余的部分插入到适当的空闲链表中。如果找不到,那么久搜索下一个更大的size class的空闲链表。直到找到一个合适的块。如果空闲链表中没有合适的块,那么就像操作系统请求额外的堆内存,从这个新的堆内存中分割出一个块,将剩余部分放置在适当的size class中。
malloc 和 free
malloc 和 free 是 C 语言中用于动态内存分配和释放内存的两个函数。它们是 C 语言标准库的一部分,用于在程序运行期间请求和释放堆内存。
那么 malloc 分配的内存究竟从何而来呢?
进程地址空间
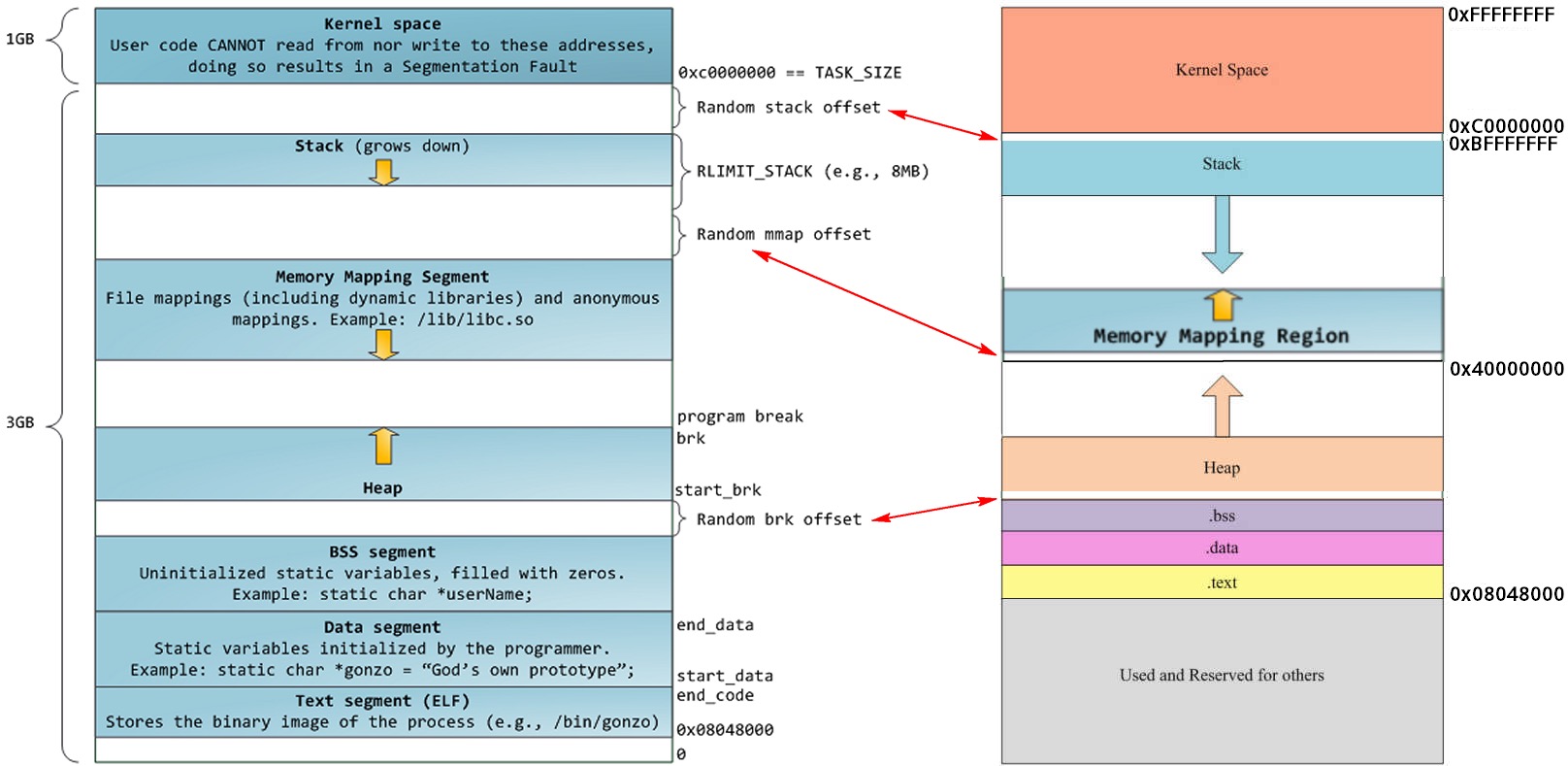
由于虚拟内存的存在,每个进程就像独占整个地址空间一样。如上图所示在一个32位系统中,可寻址的空间大小是4G,linux系统下0-3G是用户模式,3-4G是内核模式。而在用户模式下又分为代码段、数据段、.bss段、堆、栈其中代码段主要存放进程的可执行二进制代码,字符串字面值和只读变量。数据段存放已经初始化且初始值非0的全局变量和局部静态变量。bss段则存放未初始化或初始值为0的全局变量和局部静态变量。而堆段则是存放由用户动态分配内存存储的变量。栈段则主要存储局部变量、函数参数、返回地址等。
内存映射 mmap
-
内存映射段(mmap) 的作用是:内核将硬盘文件的内容直接映射到内存,任何应用程序都可通过 Linux 的
mmap()系统调用请求这种映射。 -
内存映射是一种方便高效的文件 I/O 方式, 因而被用于装载动态共享库。
-
用户也可创建匿名内存映射,该映射没有对应的文件,可用于存放程序数据。
在 Linux 中,若通过 malloc() 请求一大块内存,C 运行库将创建一个匿名内存映射,而不使用堆内存。“大块”意味着比阈值MMAP_THRESHOLD还大,缺省为 128KB,可通过 mallopt() 调整。
-
mmap 映射区向下扩展,堆向上扩展,两者相对扩展,直到耗尽虚拟地址空间中的剩余区域。
在Linux中进程由进程控制块(PCB)描述,用一个task_struct 数据结构表示,这个数据结构记录了所有进程信息,包括进程状态、进程调度信息、标示符、进程通信相关信息、进程连接信息、时间和定时器、文件系统信息、虚拟内存信息等. 和malloc密切相关的就是虚拟内存信息,定义为struct mm_struct *mm 具体描述进程的地址空间。
mm_struct结构是对整个用户空间(进程空间)的描述:
//include/linux/sched.h
struct mm_struct {
struct vm_area_struct * mmap; /* 指向虚拟区间(VMA)链表 */
rb_root_t mm_rb; /*指向red_black树*/
struct vm_area_struct * mmap_cache; /* 指向最近找到的虚拟区间*/
pgd_t * pgd; /*指向进程的页目录*/
atomic_t mm_users; /* 用户空间中的有多少用户*/
atomic_t mm_count; /* 对"struct mm_struct"有多少引用*/
int map_count; /* 虚拟区间的个数*/
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* 保护任务页表和 mm->rss */
struct list_head mmlist; /*所有活动(active)mm的链表 */
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /*命令行参数 和 环境变量的 起始地址和结束地址*/
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_address;
unsigned dumpable:1;
/* Architecture-specific MM context */
mm_context_t context;
};
其中start_brk和brk分别是堆的起始和终止地址,我们使用malloc动态分配的内存就在这之间。start_stack是进程栈的起始地址,栈的大小是在编译时期确定的,在运行时不能改变。而堆的大小由start_brk 和brk决定,但是可以使用系统调用sbrk() 或brk()增加brk的值,达到增大堆空间的效果,但是系统调用代价太大,涉及到用户态和内核态的相互转换。所以,实际中系统分配较大的堆空间,进程通过malloc()库函数在堆上进行空间动态分配,堆如果不够用malloc可以进行系统调用,增大brk的值。
malloc只知道start_brk 和brk之间连续可用的内存空间它可用任意分配,如果不够用了就向系统申请增大brk。后面一部分主要就malloc如何分配内存进行说明。
相关系统调用
brk()和sbrk()
由之前的进程地址空间结构分析可以知道,要增加一个进程实际的可用堆大小,就需要将break指针向高地址移动。Linux通过brk和sbrk系统调用操作break指针。两个系统调用的原型如下:
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
brk函数将break指针直接设置为某个地址,而sbrk将break指针从当前位置移动increment所指定的增量。brk在执行成功时返回0,否则返回-1并设置errno为ENOMEM;sbrk成功时返回break指针移动之前所指向的地址,否则返回(void *)-1。
ps: 如果将increment设置为0,则可以获得当前break的地址。
另外需要注意的是,由于Linux是按页进行内存映射的,所以如果break被设置为没有按页大小对齐,则系统实际上会在最后映射一个完整的页,从而实际已映射的内存空间比break指向的地方要大一些。但是使用break之后的地址是很危险的(尽管也许break之后确实有一小块可用内存地址)。
进程所面对的虚拟内存地址空间,只有按页映射到物理内存地址,才能真正使用。受物理存储容量限制,整个堆虚拟内存空间不可能全部映射到实际的物理内存。
因此每个进程有一个rlimit表示当前进程可用的资源上限。这个限制可以通过getrlimit系统调用得到。
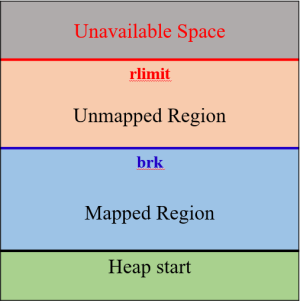
其中rlimit是一个结构体:
struct rlimit {
rlim_t rlim_cur; /* Soft limit */
rlim_t rlim_max; /* Hard limit (ceiling for rlim_cur) */
};
每种资源有软限制和硬限制,并且可以通过setrlimit对rlimit进行有条件设置。其中硬限制作为软限制的上限,非特权进程只能设置软限制,且不能超过硬限制。
mmap函数
#include <sys/mman.h>
void *mmap(void *addr, size\_t length, int prot, int flags, int fd, off\_t offset);
int munmap(void *addr, size_t length);
- mmap函数第一种用法是映射磁盘文件到内存中;而malloc使用的mmap函数的第二种用法,即匿名映射,匿名映射不映射磁盘文件,而是向映射区申请一块内存。
- munmap函数是用于释放内存,第一个参数为内存首地址,第二个参数为内存的长度。接下来看下mmap函数的参数。
当申请小内存的时,malloc使用sbrk分配内存;当申请大内存时,使用mmap函数申请内存;但是这只是分配了虚拟内存,还没有映射到物理内存,当访问申请的内存时,才会因为缺页异常,内核分配物理内存。
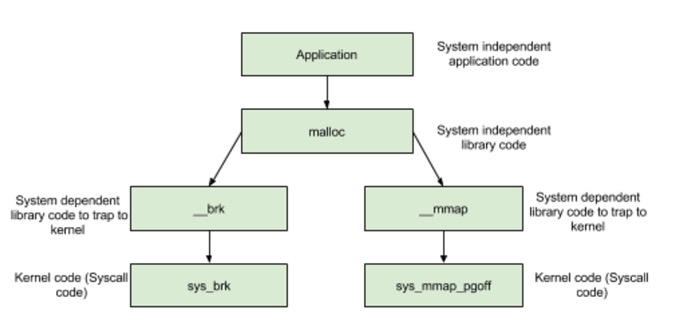
- 分配内存 < DEFAULT_MMAP_THRESHOLD,走__brk,从内存池获取,失败的话走brk系统调用。
- 分配内存 > DEFAULT_MMAP_THRESHOLD,走__mmap,直接调用mmap系统调用。
- 其中,DEFAULT_MMAP_THRESHOLD默认为128k,可通过mallopt进行设置。 重点看下小块内存(size > DEFAULT_MMAP_THRESHOLD)的分配,glibc使用的内存池如下图示。
malloc实现方案
由于brk/sbrk/mmap属于系统调用,如果每次申请内存,都调用这三个函数中的一个,那么每次都要产生系统调用开销(即cpu从用户态切换到内核态的上下文切换,这里要保存用户态数据,等会还要切换回用户态),这是非常影响性能的;
其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果低地址的内存没有被释放,高地址的内存就不能被回收。
鉴于此,malloc采用的是内存池的实现方式,malloc内存池实现方式更类似于STL分配器和memcached的内存池,先申请一大块内存,然后将内存分成不同大小的内存块,然后用户申请内存时,直接从内存池中选择一块相近的内存块即可。
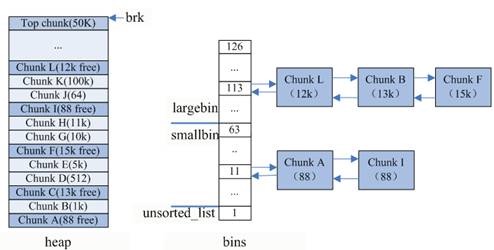
内存池保存在bins这个长128的数组中,每个元素都是一双向个链表。
- bins[0]目前没有使用
- bins[1]的链表称为unsorted_list,用于维护free释放的chunk。
- bins[2,63)的区间称为small_bins,用于维护<512字节的内存块,其中每个元素对应的链表中的chunk大小相同,均为index*8。
- bins[64,127)称为large_bins,用于维护>512字节的内存块,每个元素对应的链表中的chunk大小不同,index越大,链表中chunk的内存大小相差越大。
例如: 下标为64的chunk大小介于[512, 512+64),下标为95的chunk大小介于[2k+1,2k+512)。同一条链表上的chunk,按照从小到大的顺序排列。
- malloc将内存分成了大小不同的chunk,然后通过bins来组织起来。malloc将相似大小的chunk(图中可以看出同一链表上的chunk大小差不多)用双向链表链接起来,这样一个链表被称为一个bin。malloc一共维护了128个bin,并使用一个数组来存储这些bin。
- 数组中第一个为unsorted bin,数组编号前2到前64的bin为small bins,同一个small bin中的chunk具有相同的大小,两个相邻的small bin中的chunk大小相差8bytes。
- small bins后面的bin被称作large bins。large bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小序排列。
- large bin的每个bin相差64字节。
- malloc除了有unsorted bin,small bin,large bin三个bin之外,还有一个fast bin。
一般的情况是,程序在运行时会经常需要申请和释放一些较小的内存空间。当分配器合并了相邻的几个小的 chunk 之后,也许马上就会有另一个小块内存的请求,这样分配器又需要从大的空闲内存中切分出一块,这样无疑是比较低效的,故而,malloc 中在分配过程中引入了 fast bins,不大于 max_fast(默认值为 64B)的 chunk 被释放后,首先会被放到 fast bins中,fast bins 中的 chunk 并不改变它的使用标志 P。
这样也就无法将它们合并,当需要给用户分配的 chunk 小于或等于 max_fast 时,malloc 首先会在 fast bins 中查找相应的空闲块,然后才会去查找 bins 中的空闲 chunk。在某个特定的时候,malloc 会遍历 fast bins 中的 chunk,将相邻的空闲 chunk 进行合并,并将合并后的 chunk 加入 unsorted bin 中,然后再将 unsorted bin 里的 chunk 加入 bins 中。
unsorted bin 的队列使用 bins 数组的第一个,如果被用户释放的 chunk 大于 max_fast,或者 fast bins 中的空闲 chunk 合并后,这些 chunk 首先会被放到 unsorted bin 队列中,在进行 malloc 操作的时候,如果在 fast bins 中没有找到合适的 chunk,则malloc 会先在 unsorted bin 中查找合适的空闲 chunk,然后才查找 bins。
如果 unsorted bin 不能满足分配要求。 malloc便会将 unsorted bin 中的 chunk 加入 bins 中。然后再从 bins 中继续进行查找和分配过程。从这个过程可以看出来,unsorted bin 可以看做是 bins 的一个缓冲区,增加它只是为了加快分配的速度。(其实感觉在这里还利用了局部性原理,常用的内存块大小差不多,从unsorted bin这里取就行了,这个和TLB之类的都是异曲同工之妙啊!)
除了上述四种bins之外,malloc还有三种内存区:
- 当fast bin和bins都不能满足内存需求时,malloc会设法在top chunk中分配一块内存给用户;top chunk为在mmap区域分配一块较大的空闲内存模拟sub-heap。(比较大的时候) >top chunk是堆顶的chunk,堆顶指针brk位于top chunk的顶部。移动brk指针,即可扩充top chunk的大小。当top chunk大小超过128k(可配置)时,会触发malloc_trim操作,调用sbrk(-size)将内存归还操作系统。
- 当chunk足够大,fast bin和bins都不能满足要求,甚至top chunk都不能满足时,malloc会从mmap来直接使用内存映射来将页映射到进程空间,这样的chunk释放时,直接解除映射,归还给操作系统。(极限大的时候)
- Last remainder是另外一种特殊的chunk,就像top chunk和mmaped chunk一样,不会在任何bins中找到这种chunk。当需要分配一个small chunk,但在small bins中找不到合适的chunk,如果last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk。(这个应该是fast bins中也找不到合适的时候,用于极限小的)
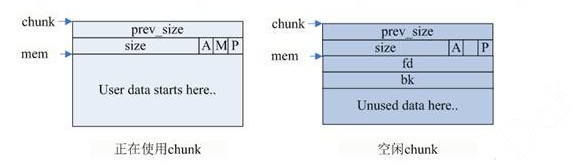
由之前的分析可知malloc利用chunk结构来管理内存块,malloc就是由不同大小的chunk链表组成的。malloc会给用户分配的空间的前后加上一些控制信息,用这样的方法来记录分配的信息,以便完成分配和释放工作。chunk指针指向chunk开始的地方,图中的mem指针才是真正返回给用户的内存指针。
- chunk 的第二个域的最低一位为P,它表示前一个块是否在使用中,P 为 0 则表示前一个 chunk 为空闲,这时chunk的第一个域 prev_size 才有效,prev_size 表示前一个 chunk 的 size,程序可以使用这个值来找到前一个 chunk 的开始地址。当 P 为 1 时,表示前一个 chunk 正在使用中,prev_size程序也就不可以得到前一个 chunk 的大小。不能对前一个 chunk 进行任何操作。malloc分配的第一个块总是将 P 设为 1,以防止程序引用到不存在的区域。(这里就很细!)
- Chunk 的第二个域的倒数第二个位为M,他表示当前 chunk 是从哪个内存区域获得的虚拟内存。M 为 1 表示该 chunk 是从 mmap 映射区域分配的,否则是从 heap 区域分配的。
- Chunk 的第二个域倒数第三个位为 A,表示该 chunk 属于主分配区或者非主分配区,如果属于非主分配区,将该位置为 1,否则置为 0。
当chunk空闲时,其M状态是不存在的,只有AP状态,原本是用户数据区的地方存储了四个指针,指针fd指向后一个空闲的chunk,而bk指向前一个空闲的chunk,malloc通过这两个指针将大小相近的chunk连成一个双向链表。
在large bin中的空闲chunk,还有两个指针,fd_nextsize和bk_nextsize,用于加快在large bin中查找最近匹配的空闲chunk。不同的chunk链表又是通过bins或者fastbins来组织的。
malloc 内存分配流程
-
如果分配内存<512字节,则通过内存大小定位到smallbins对应的index上(floor(size/8))。如果smallbins[index]为空,进入步骤3;如果smallbins[index]非空,直接返回第一个chunk;
-
如果分配内存>512字节,则定位到largebins对应的index上。如果largebins[index]为空,进入步骤3;如果largebins[index]非空,扫描链表,找到第一个大小最合适的chunk,如size=12.5K,则使用chunk B,剩下的0.5k放入unsorted_list中;遍历unsorted_list,查找合适size的chunk,如果找到则返回;否则,将这些chunk都归类放到smallbins和largebins里面。
-
index++从更大的链表中查找,直到找到合适大小的chunk为止,找到后将chunk拆分,并将剩余的加入到unsorted_list中;
-
如果还没有找到,那么使用top chunk,或者,内存<128k,使用brk;内存>128k,使用mmap获取新内存;
-
此外,调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。
虚拟内存并不是每次malloc后都增长,是与上一节说的堆顶没发生变化有关,因为可重用堆顶内剩余的空间,这样的malloc是很轻量快速的。如果虚拟内存发生变化,基本与分配内存量相当,因为虚拟内存是计算虚拟地址空间总大小。物理内存的增量很少,是因为malloc分配的内存并不就马上分配实际存储空间,只有第一次使用,如第一次memset后才会分配。
由于每个物理内存页面大小是4k,不管memset其中的1k还是5k、7k,实际占用物理内存总是4k的倍数。所以物理内存的增量总是4k的倍数。
因此,不是malloc后就马上占用实际内存,而是第一次使用时发现虚存对应的物理页面未分配,产生缺页中断,才真正分配物理页面,同时更新进程页面的映射关系。这也是Linux虚拟内存管理的核心概念之一。
内存碎片
free释放内存时,有两种情况:
chunk和top chunk相邻,则和top chunk合并,chunk和top chunk不相邻,则直接插入到unsorted_list中。
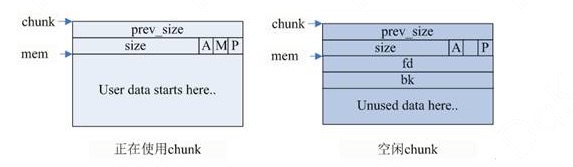
如上图示: top chunk是堆顶的chunk,堆顶指针brk位于top chunk的顶部。移动brk指针,即可扩充top chunk的大小。当top chunk大小超过128k(可配置)时,会触发malloc_trim操作,调用sbrk(-size)将内存归还操作系统。
以上图chunk分布图为例,按照glibc的内存分配策略,我们考虑下如下场景(假设brk其实地址是512k):
- malloc 40k内存,即chunkA,brk = 512k + 40k = 552k;
- malloc 50k内存,即chunkB,brk = 552k + 50k = 602k;
- malloc 60k内存,即chunkC,brk = 602k + 60k = 662k
- free chunkA。
此时,由于brk = 662k,而释放的内存是位于[512k, 552k]之间,无法通过移动brk指针,将区域内内存交还操作系统,因此,在[512k, 552k]的区域内便形成了一个内存空洞即内存碎片。 按照glibc的策略,free后的chunkA区域由于不和top chunk相邻,因此,无法和top chunk 合并,应该挂在unsorted_list链表上。
C++ malloc、new,free、delete 区别
malloc、new、free、delete 这几个总是放在一起来对比,今天来彻底的解析一下这几个函数/操作符:
整体用法:
#include <cstdlib>
int main() {
// 使用 malloc 分配内存
int *ptr = (int *)malloc(sizeof(int));
// 记得在使用完之后释放内存
free(ptr);
}
int main() {
// 使用 new 分配内存并调用构造函数
int *ptr = new int;
// 记得在使用完之后释放内存
delete ptr;
}
简单对比
- 语法不同:malloc/free是一个C语言的函数,而new/delete是C++的运算符。
- 分配内存的方式不同:malloc只分配内存,而new会分配内存并且调用对象的构造函数来初始化对象。
- 返回值不同:malloc返回一个 void 指针,需要自己强制类型转换,而new返回一个指向对象类型的指针。
- malloc 需要传入需要分配的大小,而 new 编译器会自动计算所构造对象的大小
详细解析
申请的内存所在位置
new 操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是 C++ 基于new操作符的一个抽象概念,凡是通过 new 操作符进行内存申请,该内存即为自由存储区。而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。
那么自由存储区是否能够是堆(问题等价于new是否能在堆上动态分配内存),这取决于operator new 的实现细节。自由存储区不仅可以是堆,还可以是静态存储区,这都看operator new在哪里为对象分配内存。不过大家可以基本将自由存储区等价于堆区。
特别的,new 甚至可以不为对象分配内存!placement_new的功能可以办到这一点:
new (place_address) type
place_address为一个指针,代表一块内存的地址。当使用上面这种仅以一个地址调用new操作符时,new操作符调用特殊的operator new,也就是下面这个版本:
void * operator new (size_t,void *) //不允许重定义这个版本的operator new
这个operator new不分配任何的内存,它只是简单地返回指针实参,然后 new 表达式负责在place_address指定的地址进行对象的初始化工作。
内存分配失败时返回值
new内存分配失败时,会抛出bac_alloc异常,它不会返回NULL;malloc分配内存失败时返回NULL。在使用C语言时,我们习惯在malloc分配内存后判断分配是否成功:
int *a = (int *)malloc ( sizeof (int ));
if(NULL == a) {
...
} else {
...
}
从 C 语言走入 C++ 阵营的新手可能会把这个习惯带入C++:
int * a = new int();
if(NULL == a) {
...
} else {
...
}
实际上这样做一点意义也没有,因为new根本不会返回NULL,而且程序能够执行到if语句已经说明内存分配成功了,如果失败早就抛异常了。
正确的做法应该是使用异常机制:
try {
int *a = new int();
} catch (bad_alloc) {
...
}
是否调用构造函数/析构函数
使用new操作符来分配对象内存时会经历三个步骤:
- 第一步:调用operator new 函数(对于数组是operator new[])分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
- 第二步:编译器运行相应的构造函数以构造对象,并为其传入初值。
- 第三部:对象构造完成后,返回一个指向该对象的指针。
使用delete操作符来释放对象内存时会经历两个步骤:
- 第一步:调用对象的析构函数。
- 第二步:编译器调用operator delete(或operator delete[])函数释放内存空间。
对数组的处理
C++ 提供了 new[] 与 delete[] 来专门处理数组类型:
A * ptr = new A[10];//分配10个A对象
delete [] ptr;
new 对数组的支持体现在它会分别调用构造函数函数初始化每一个数组元素,释放对象时为每个对象调用析构函数。
注意 delete[] 要与new[] 配套使用,不然会找出数组对象部分释放的现象,造成内存泄漏。
至于 malloc,它并知道你在这块内存上要放的数组还是啥别的东西,反正它就给你一块原始的内存,在给你个内存的地址就完事。所以如果要动态分配一个数组的内存,还需要我们手动自定数组的大小:
new 和 malloc 是否可以相互调用
operator new /operator delete的实现可以基于malloc,而malloc的实现不可以去调用new。下面是编写operator new /operator delete 的一种简单方式,其他版本也与之类似:
void * operator new (sieze_t size)
{
if(void * mem = malloc(size)
return mem;
else
throw bad_alloc();
}
void operator delete(void *mem) noexcept
{
free(mem);
}
能够直观地重新分配内存
使用 malloc 分配的内存后,如果在使用过程中发现内存不足,可以使用 realloc 函数进行内存重新分配实现内存的扩充。
realloc 先判断当前的指针所指内存是否有足够的连续空间,如果有,原地扩大可分配的内存地址,并且返回原来的地址指针;
如果空间不够,先按照新指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来的内存区域。
new 没有这样直观的配套设施来扩充内存。
| 特征 | new/delete | malloc/free |
|---|---|---|
| 分配内存的位置 | 自由存储区 | 堆 |
| 内存分配成功的返回值 | 完整类型指针 | void* |
| 内存分配失败的返回值 | 默认抛出异常 | 返回NULL |
| 分配内存的大小 | 由编译器根据类型计算得出 | 必须显式指定字节数 |
| 处理数组 | 有处理数组的new版本new[] | 需要用户计算数组的大小后进行内存分配 |
| 已分配内存的扩充 | 无法直观地处理 | 使用realloc简单完成 |
| 是否相互调用 | 可以,看具体的operator new/delete实现 | 不可调用new |
| 分配内存时内存不足 | 客户能够指定处理函数或重新制定分配器 | 无法通过用户代码进行处理 |
| 函数重载 | 允许 | 不允许 |
| 构造函数与析构函数 | 调用 | 不调用 |
C/C++ 内存泄露如何定位、检测以及避免
内存泄露是什么?
简单来说就是:在程序中申请了动态内存,却没有释放,如果程序长期运行下去,最终会导致没有内存可供分配。
所以不少大厂的服务有个特点,就是会定期重启服务进程,重启的目的就是让操作系统回收整个进程的资源包括内存,这样一点点的内存泄露问题即使无法定位,也不是什么大问题哈哈哈
如何检测
检测内存泄露的方法:
- 手动检查代码:仔细检查代码中的内存分配和释放,确保每次分配内存后都有相应的释放操作。比如 malloc和free、new和delete是否配对使用了。
- 使用调试器和工具:有一些工具可以帮助检测内存泄露。例如:
- Valgrind(仅限于Linux和macOS):Valgrind是一个功能强大的内存管理分析工具,可以检测内存泄露、未初始化的内存访问、数组越界等问题。使用Valgrind分析程序时,只需在命令行中输入
valgrind --leak-check=yes your_program即可。 - Visual Studio中的CRT(C Runtime)调试功能:Visual Studio提供了一些用于检测内存泄露的C Runtime库调试功能。例如,
_CrtDumpMemoryLeaks函数可以在程序结束时报告内存泄露。 - AddressSanitizer:AddressSanitizer是一个用于检测内存错误的编译器插件,适用于GCC和Clang。要启用AddressSanitizer,只需在编译时添加
-fsanitize=address选项。
- Valgrind(仅限于Linux和macOS):Valgrind是一个功能强大的内存管理分析工具,可以检测内存泄露、未初始化的内存访问、数组越界等问题。使用Valgrind分析程序时,只需在命令行中输入
如何避免内存泄露
- 使用智能指针(C++):在C++中,可以使用智能指针(如
std::unique_ptr和std::shared_ptr)来自动管理内存。这些智能指针在作用域结束时会自动释放所指向的内存,从而降低忘记释放内存或者程序异常导致内存泄露的风险。 - 异常安全:在C++中,如果程序抛出异常,需要确保在异常处理过程中正确释放已分配的内存。使用
try-catch块来捕获异常并在适当的位置释放内存。 或者使用RAII(Resource Acquisition Is Initialization)技术
C/C++ 野指针和空悬指针
野指针(Wild Pointer)和空悬指针(Dangling Pointer)都是指向无效内存的指针,但它们的成因和表现有所不同,区别如下:
野指针(Wild Pointer)
野指针是一个未被初始化或已被释放的指针。所以它的值是不确定的,可能指向任意内存地址。访问野指针可能导致未定义行为,如程序崩溃、数据损坏等。
以下是一个野指针的例子:
#include <iostream>
int main() {
int *wild_ptr; // 未初始化的指针,值不确定
std::cout << *wild_ptr << std::endl; // 访问野指针,可能导致未定义行为
return 0;
}
空悬指针(Dangling Pointer)
空悬指针是指向已经被释放(如删除、回收)的内存的指针。这种指针仍然具有以前分配的内存地址,但是这块内存可能已经被其他对象或数据占用。访问空悬指针同样会导致未定义行为。
以下是一个空悬指针的例子:
#include <iostream>
int main() {
int *ptr = new int(42);
delete ptr; // 释放内存
// 此时,ptr成为一个空悬指针,因为它指向的内存已经被释放
std::cout << *ptr << std::endl; // 访问空悬指针,可能导致未定义行为
return 0;
}
了避免野指针和空悬指针引发的问题,我们应该:
- 在使用指针前对其进行初始化,如将其初始化为
nullptr。 - 在释放指针指向的内存后,将指针设为
nullptr,避免误访问已释放的内存。 - 在使用指针前检查其有效性,确保指针指向合法内存。
delete nullptr 安全性
对一个动态存储的指针赋值nullptr,然后使用delete释放内存是否安全。我上网查阅资料有些说安全有些说不安全。 还有一个问题是,使用delete后是否要将其设置为nullptr,网上说设置为nullptr可以避免悬空指针的问题,也有的说将指针删除后设置为nullptr会伪装内存分配错误,说设置为nullptr没什么意义。
回答:
- C++ 标准里 delete 一个 nullptr 实际上没任何效果,可以理解为是安全的。
- delete 指针后是否要置空其实也有一些争论,不过总体上来说是建议 置空的,这是为了防止后续再使用这个指针去访问到了这块已经释放的内存,但是我觉得写C++的程序员应该要对 指针的生命周期掌握比较准确
至于你说的 删除后 置为 nullptr会掩盖一些错误,这个的确,如果在 delete 后立即将指针设置为 nullptr, 如果后续代码中存在对这块内存的错误使用(比如,再次 delete),这个错误就可能被掩盖,如同第一点说的, delete nullptr 是安全的。
标签:malloc,管理,chunk,内存,动态内存,new,bins,指针 From: https://www.cnblogs.com/sfbslover/p/18407369