Linux性能分析工具Perf
介绍
Perf全名是Performance Event,是在Linux 2.6.31以后内建的系统效能分析工具,依靠perf,应用程式可以利用PMU (Performance Monitoring Unit), tracepoint和核心内部的特殊计数器(counter)来进行统计,另外还能同时分析运行中的核心程式码,从而更全面了解应用程式中的效能瓶颈。
perf基本原理是对目标进行取样,纪录特定的条件下所侦测的事件是否发生以及发生的次数。例如根据tick中断进行取样,即在tick中断内触发取样点,在取样点里判断行程(process)当时的context。假如一个行程90%的时间都花费在函式foo()上,那么90%的取样点都应该落在函式foo()的上下文中。
Perf 可取样的事件非常多,可以分析:
- Hardware event,如cpu-cycles、instructions 、cache-misses、branch-misses
- Software event,如page-faults、context-switches
- Tracepoint event
知道了cpu-cycles、instructions 我们可以了解Instruction per cycle 是多少,进而判断程式码有没有好好利用CPU,cache-misses 可以晓得是否有善用Locality of reference ,branch-misses 多了是否导致严重的pipeline hazard ?另外Perf 还可以对函式进行采样,了解效能卡在哪边。
perf的基本原理
Perf 是内置于 Linux 内核源码树中的性能剖析(profiling)工具。它基于事件 采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性 能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位。
我们先通过一个例子来看看 perf 究竟能干什么。程序[code1]是一个简单的 计算 pi 的计算密集型程序。很显然,[code1]的热点在函数 do_pi()中
#include <stdio.h>
#include <math.h>
#include <sys/types.h>
#include <linux/unistd.h>
int do_pi(){
double mypi,h,sum,x;
long long n,i;
n = 5000000;
h = 1.0 / n;
sum=0.0;
for (i = 1; i <= n; i+=1 ) { x = h * (i ‐ 0.5); sum += 4.0 / (1.0 + pow(x,2));
}
mypi = h * sum;
return 0;
}
int main()
{
printf("pid: %d\n", getpid());
sleep(8);
do_pi();
return 0;
}
运行[code1]后,根据程序显示的 pid 在命令行中执行:
$perf top ‐p $pid
该命令利用默认的性能事件”cycles”对[code1]进行热点分析。”cycles”是处理 器周期事件。这条命令能够分析出消耗处理器周期最多的代码,在处理器频率稳 定的前提下,我们可以认为 perf 给出热点代码的就是消耗时间最多的代码段。 执行上述命令后,Perf 会给出如下结果:

从图 上可以看到,在[code1]执行期间,函数 do_pi()消耗了 99.54%的 CPU 周期,是消耗处理器周期最多的热点代码。这跟我们预想的一样。
那么 perf 是怎么做到的呢?首先,perf 会通过系统调用 sys_perf_event_open 在内核中注册一个监测“cycles”事件的性能计数器。内核根据 perf 提供的信息在 PMU 上初始化一个硬件性能计数器(PMC: Performance Monitoring Counter)。PMC 随着 CPU 周期的增加而自动累加。在 PMC 溢出时,PMU 触发一个 PMI (Performance Monitoring Interrupt)中断。内核在 PMI 中断的处理函数中保存 PMC 的计数值,触发中断时的指令地址(Register IP:Instruction Pointer),当前 时间戳以及当前进程的 PID,TID,comm 等信息。我们把这些信息统称为一个采 样(sample)。内核会将收集到的 sample 放入用于跟用户空间通信的 Ring Buffer。 用户空间里的 perf 分析程序采用 mmap 机制从 ring buffer 中读入采样,并对其解 析。perf 根据 pid,comm 等信息可以找到对应的进程。根据 IP 与 ELF 文件中的 符号表可以查到触发 PMI 中断的指令所在的函数。为了能够使 perf 读到函数名, 我们的目标程序必须具备符号表。如果读者在 perf 的分析结果中只看到一串地 址,而没有对应的函数名时,通常是由于在编译时利用 strip 删除了 ELF 文件中 的符号表。建议读者在性能分析阶段,保留程序中的 symbol table,debug info 等信息。 根据上述的 perf 采样原理可以得知,perf 假设两次采样之间,即两次相邻 的 PMI 中断之间系统执行的是同一个进程的同一个函数。这种假设会带来一定 的误差,当读者感觉 perf 给出的结果不准时,不妨提高采样频率,perf 会给出更 加精确的结果
perf的功能概述
Perf 是一个包含 22 种子工具的工具集,功能很全面。表 1 给出了各个子 工具的功能描述。
| 1 | annotate | 根据数据文件,注解被采样到的函数,显示指令级别的 热点。 |
|---|---|---|
| 2 | archive | 根据数据文件中记录的 build‐id,将所有被采样到的 ELF 文件打成压缩包。利用此压缩包,可以在任何机器上分 析数据文件中记录的采样数据 |
| 3 | bench | Perf 中内置的 benchmark,目前包括两套针对调度器和 内存管理子系统的 benchmark。 |
| 4 | buildid‐cache | 管理 perf 的 buildid 缓存。每个 ELF 文件都有一个独一 无二的 buildid。Buildid 被 perf 用来关联性能数据与 ELF文件。 |
| 5 | buildid‐list | 列出数据文件中记录的所有 buildid。 |
| 6 | diff | 对比两个数据文件的差异。能够给出每个符号(函数) 在热点分析上的具体差异。 |
| 7 | evlist | 列出数据文件中的所有性能事件。 |
| 8 | inject | 该工具读取 perf record 工具记录的事件流,并将其定向 到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。 |
| 9 | kmem | 针对内存子系统的分析工具。 |
| 10 | kvm | 此工具可以用来追踪、测试运行于 KVM 虚拟机上的 Guest OS。 |
| 11 | list | 列出当前系统支持的所有性能事件。包括硬件性能事 件、软件性能事件以及检查点。 |
| 12 | lock | 分析内核中的加锁信息。包括锁的争用情况,等待延迟 等。 |
| 13 | record | 收集采样信息,并将其记录在数据文件中。随后可通过 其它工具对数据文件进行分析。 |
| 14 | report | 读取 perf record 创建的数据文件,并给出热点分析结果。 |
| 15 | sched | 针对调度器子系统的分析工具。 |
| 16 | script | 执行 perl 或 python 写的功能扩展脚本、生成脚本框架、 读取数据文件中的数据信息等。 |
| 17 | stat | 剖析某个特定进程的性能概况,包括 CPI、Cache 丢失 率等。 |
| 18 | test | Perf 对当前软硬件平台的测试工具。可以用此工具测试 当前的软硬件平台(主要是处理器型号和内部版本)是 否能支持 perf 的所有功能。 |
| 19 | timechart | 生成一幅描述处理器与各进程状态变化的矢量图。 |
| 20 | top | 类似于 Linux 的 top 命令,对系统性能进行实时分析。 |
| 21 | trace | strace inspired tool. |
| 22 | probe | 用于定义动态检查点。 |
某些需要特定内核支持的命令可能无法使用。如果想获得每个子命令的具体选项列表,只需输入命令名紧随其后 - h :
perf stat -h
usage: perf stat [<options>] [<command>]
-e, --event <event> event selector. use 'perf list' to list available events
-i, --no-inherit child tasks do not inherit counters
-p, --pid <n> stat events on existing process id
-t, --tid <n> stat events on existing thread id
-a, --all-cpus system-wide collection from all CPUs
-c, --scale scale/normalize counters
-v, --verbose be more verbose (show counter open errors, etc)
-r, --repeat <n> repeat command and print average + stddev (max: 100)
-n, --null null run - dont start any counters
-B, --big-num print large numbers with thousands' separators
perf list工具和性能事件
Perf工具支持一系列的可测量事件。这个工具和底层内核接口可以测量来自不同来源的事件。 例如,一些事件是纯粹的内核计数,在这种情况下的事件被称为软事件 ,例如:context-switches、minor-faults。
另一个事件来源是处理器本身和它的性能监视单元(PMU)。它提供了一个事件列表来测量微体系结构的事件,如周期数、失效的指令、一级缓存未命中等等。 这些事件被称为PMU硬件事件或简称为硬件事件。 它们因处理器类型和型号而异。
perf_events接口还提供了一组通用的的硬件事件名称。在每个处理器,这些事件被映射到一个CPU的真实事件,如果真实事件不存在则事件不能使用。可能会让人混淆,这些事件也被称为硬件事件或硬件缓存事件 。
最后,还有由内核ftrace基础实现的tracepoint事件。但只有2.6.3x和更新版本的内核才提供这些功能。
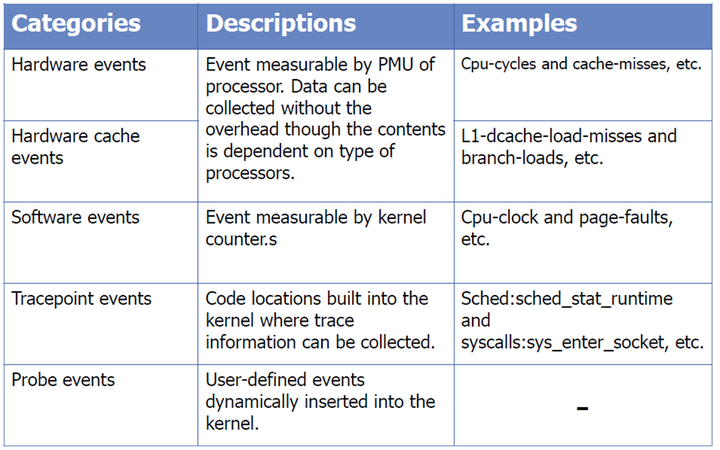
可以通过命令获得可支持的事件列表:
perf list
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
cache-references [Hardware event]
cache-misses [Hardware event]
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cpu-clock [Software event]
task-clock [Software event]
page-faults OR faults [Software event]
minor-faults [Software event]
major-faults [Software event]
context-switches OR cs [Software event]
cpu-migrations OR migrations [Software event]
alignment-faults [Software event]
emulation-faults [Software event]
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
L1-dcache-prefetches [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-icache-loads [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
L1-icache-prefetches [Hardware cache event]
L1-icache-prefetch-misses [Hardware cache event]
LLC-loads [Hardware cache event]
LLC-load-misses [Hardware cache event]
LLC-stores [Hardware cache event]
LLC-store-misses [Hardware cache event]
LLC-prefetch-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-prefetches [Hardware cache event]
dTLB-prefetch-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
iTLB-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
branch-load-misses [Hardware cache event]
rNNN (see 'perf list --help' on how to encode it) [Raw hardware event descriptor]
mem:<addr>[:access] [Hardware breakpoint]
kvmmmu:kvm_mmu_pagetable_walk [Tracepoint event]
[...]
sched:sched_stat_runtime [Tracepoint event]
sched:sched_pi_setprio [Tracepoint event]
syscalls:sys_enter_socket [Tracepoint event]
syscalls:sys_exit_socket [Tracepoint event]
[...]
一个事件可以有子事件(或掩码)。 在某些处理器上的某些事件,可以组合掩码,并在其中一个子事件发生时进行测量。最后,一个事件还可以有修饰符,也就是说,通过过滤器可以改变事件被计数的时间或方式。
软件事件实现方法
- OS为每个软件事件定义一个计数器(可以理解为一个内存变量)
- 这样定义的计数器实际上是无限的(OS可以自己随意定义,只要存储空间足够)
- 每个软件事件和计数器就是一一对应关系
- 每个软件事件发生时OS简单对分配的计数器累加

硬件事件实现方法
需要硬件性能计数器(PMC)支持