多进程模型
基于最原始的阻塞网络 I/O, 如果服务器要支持多个客户端,其中比较传统的方式,就是使用多进程模型,也就是为每个客户端分配一个进程来处理请求。
服务器的主进程负责监听客户的连接,一旦与客户端连接完成,accept() 函数就会返回一个「已连接 Socket」,这时就通过 fork() 函数创建一个子进程,实际上就把父进程所有相关的东西都复制一份,包括文件描述符、内存地址空间、程序计数器、执行的代码等。
这两个进程刚复制完的时候,几乎一模一样。不过,会根据返回值来区分是父进程还是子进程,如果返回值是 0,则是子进程;如果返回值是其他的整数,就是父进程。
正因为子进程会复制父进程的文件描述符,于是就可以直接使用「已连接 Socket 」和客户端通信了,
可以发现,子进程不需要关心「监听 Socket」,只需要关心「已连接 Socket」;父进程则相反,将客户服务交给子进程来处理,因此父进程不需要关心「已连接 Socket」,只需要关心「监听 Socket」。
下面这张图描述了从连接请求到连接建立,父进程创建生子进程为客户服务。
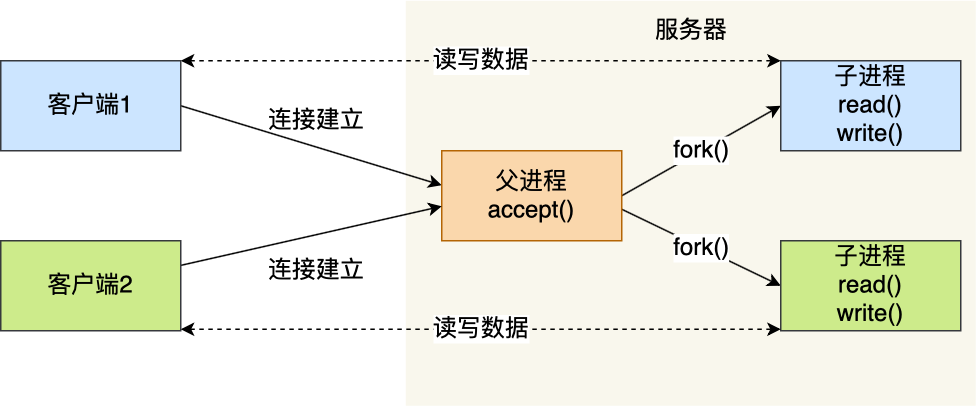
另外,当「子进程」退出时,实际上内核里还会保留该进程的一些信息,也是会占用内存的,如果不做好“回收”工作,就会变成僵尸进程,随着僵尸进程越多,会慢慢耗尽我们的系统资源。
因此,父进程要“善后”好自己的孩子,怎么善后呢?那么有两种方式可以在子进程退出后回收资源,分别是调用 wait() 和 waitpid() 函数。
这种用多个进程来应付多个客户端的方式,在应对 100 个客户端还是可行的,但是当客户端数量高达一万时,肯定扛不住的,因为每产生一个进程,必会占据一定的系统资源,而且进程间上下文切换的“包袱”是很重的,性能会大打折扣。
进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
标签:Socket,模型,监听,进程,返回值,连接,客户端 From: https://www.cnblogs.com/sunupo/p/18309835