一、前言
本文主要是以context_switch为起点,分析了整个进程切换过程中的基本操作和基本的代码框架,很多细节,例如tlb的操作,cache的操作,锁的操作等等会在其他专门的文档中描述。进程切换包括体系结构相关的代码和系统结构无关的代码。第二、三、四分别描述了context_switch的代码脉络,后面的章节是以ARM64为例子,讲述了具体进程地址空间的切换过程和硬件上下文的切换过程。
二、context_switch代码分析
在kernel/sched/core.c中有一个context_switch函数,该函数用来完成具体的进程切换,代码如下(本文主要描述进程切换的基本逻辑,因此部分代码会有删节):
static inline struct rq * context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)------------------(1)
{
struct mm_struct *mm, *oldmm;
mm = next->mm;
oldmm = prev->active_mm;-------------------(2)
if (!mm) {---------------------------(3)
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);-----------------(4)
} else
switch_mm(oldmm, mm, next); ---------------(5)
if (!prev->mm) {------------------------(6)
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
switch_to(prev, next, prev);------------------(7)
barrier();
return finish_task_switch(prev);
}
(1)一旦调度器算法确定了pre task和next task,那么就可以调用context_switch函数实际执行进行切换的工作了,这里我们先看看参数传递情况:
- rq:在多核系统中,进程切换总是发生在各个cpu core上,参数rq指向本次切换发生的那个cpu对应的run queue
- prev:将要被剥夺执行权利的那个进程
- next:被选择在该cpu上执行的那个进程
(2)next是马上就要被切入的进程(后面简称B进程),prev是马上就要被剥夺执行权利的进程(后面简称A进程)。mm变量指向B进程的地址空间描述符,oldmm变量指向A进程的当前正在使用的地址空间描述符(active_mm)。对于normal进程,其任务描述符(task_struct)的mm和active_mm相同,都是指向其进程地址空间。对于内核线程而言,其task_struct的mm成员为NULL(内核线程没有进程地址空间),但是,内核线程被调度执行的时候,总是需要一个进程地址空间,而active_mm就是指向它借用的那个进程地址空间。
(3)mm为空的话,说明B进程是内核线程,这时候,只能借用A进程当前正在使用的那个地址空间(prev->active_mm)。注意:这里不能借用A进程的地址空间(prev->mm),因为A进程也可能是一个内核线程,不拥有自己的地址空间描述符。
(4)如果要切入的B进程是内核线程,那么调用体系结构相关的代码enter_lazy_tlb,标识该cpu进入lazy tlb mode。那么什么是lazy tlb mode呢?如果要切入的进程实际上是内核线程,那么我们也暂时不需要flush TLB,因为内核线程不会访问usersapce,所以那些无效的TLB entry也不会影响内核线程的执行。在这种情况下,为了性能,我们会进入lazy tlb mode。进程切换中和TLB相关的内容我们会单独在一篇文章中描述,这里就不再赘述了。
(5)如果要切入的B进程是内核线程,那么由于是借用当前正在使用的地址空间,因此没有必要调用switch_mm进行地址空间切换,只有要切入的B进程是一个普通进程的情况下(有自己的地址空间)才会调用switch_mm,真正执行地址空间切换。
如果切入的是普通进程,那么这时候进程的地址空间已经切换了,也就是说在A--->B进程的过程中,进程本身尚未切换,而进程的地址空间已经切换到了B进程了。这样会不会造成问题呢?还好,呵呵,这时候代码执行在kernel space,A和B进程的kernel space都是一样一样的啊,即便是切了进程地址空间,不过内核空间实际上保持不变的。
(6)如果切出的A进程是内核线程,那么其借用的那个地址空间(active_mm)已经不需要继续使用了(内核线程A被挂起了,根本不需要地址空间了)。除此之外,我们这里还设定了run queue上一次使用的mm struct(rq->prev_mm)为oldmm。为何要这么做?先等一等,下面我们会统一描述。
(7)一次进程切换,表面上看起来涉及两个进程,实际上涉及到了三个进程。switch_to是一个有魔力的符号,和一般的调用函数不同,当A进程在CPUa调用它切换到B进程的时候,switch_to一去不回,直到在某个cpu上(我们称之CPUx)完成从X进程(就是last进程)到A进程切换的时候,switch_to返回到A进程的现场。这一点我们会在下一节详细描述。switch_to完成了具体prev到next进程的切换,当switch_to返回的时候,说明A进程再次被调度执行了。
三、switch_to为什么需要三个参数呢?
switch_to定义如下:
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
一个switch_to将代码分成两段:
AAA
switch_to(prev, next, prev);
BBB
一次进程切换,涉及到了三个进程,prev和next是大家都熟悉的参数了,对于进程A(下图中的右半图片),如果它想要切换到B进程,那么:
prev=A
next=B
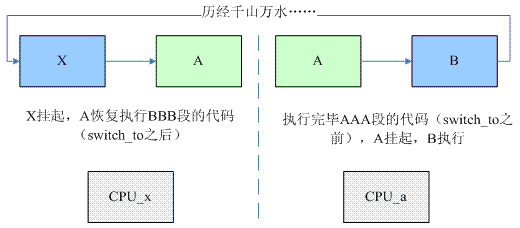
这时候,在A进程中调用 switch_to 完成A到B进程的切换。但是,当经历万水千山,A进程又被重新调度的时候,我们又来到了switch_to返回的这一点(下图中的左半图片),这时候,我们是从哪一个进程切换到A呢?谁知道呢(在A进程调用switch_to 的时候是不知道的)?在A进程调用switch_to之后,cpu就执行B进程了,后续B进程切到哪个进程呢?随后又经历了怎样的进程切换过程呢?当然,这一切对于A进程来说它并不关心,它唯一关心的是当切换回A进程的时候,该cpu上(也不一定是A调用switch_to切换到B进程的那个CPU)执行的上一个task是谁?这就是第三个参数的含义(实际上这个参数的名字就是last,也基本说明了其含义)。也就是说,在AAA点上,prev是A进程,对应的run queue是CPUa的run queue,而在BBB点上,A进程恢复执行,last是X进程,对应的run queue是CPUx的run queue。
四、在内核线程切换过程中,内存描述符的处理
我们上面已经说过:如果切入内核线程,那么其实进程地址空间实际上并没有切换,该内核线程只是借用了切出进程使用的那个地址空间(active_mm)。对于内核中的实体,我们都会使用引用计数来根据一个数据对象,从而确保在没有任何引用的情况下释放该数据对象实体,对于内存描述符亦然。因此,在context_switch中有代码如下:
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);-----增加引用计数
enter_lazy_tlb(oldmm, next);
}
既然是借用别人的内存描述符(地址空间),那么调用atomic_inc是合理的,反正马上就切入B进程了,在A进程中提前增加引用计数也OK的。话说有借有还,那么在内核线程被切出的时候,就是归还内存描述符的时候了。
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;---在rq->prev_mm上保存了上一次使用的mm struct
}
借助其他进程内存描述符的东风,内核线程B欢快的运行,然而,快乐总是短暂的,也许是B自愿的,也许是强迫的,调度器最终会剥夺B的执行,切入C进程。也就是说,B内核线程调用switch_to(执行了AAA段代码),自己挂起,C粉墨登场,执行BBB段的代码。具体的代码在finish_task_switch,如下:
static struct rq *finish_task_switch(struct task_struct *prev)
{
struct rq *rq = this_rq();
struct mm_struct *mm = rq->prev_mm;――――――――――――――――(1)
rq->prev_mm = NULL;
if (mm)
mmdrop(mm);――――――――――――――――――――――――(2)
}
(1)我们假设B是内核线程,在进程A调用context_switch切换到B线程的时候,借用的地址空间被保存在CPU对应的run queue中。在B切换到C之后,通过rq->prev_mm就可以得到借用的内存描述符。
(2)已经完成B到C的切换后,借用的地址空间可以返还了。因此在C进程中调用mmdrop来完成这一动作。很神奇,在A进程中为内核线程B借用地址空间,但却在C进程中释放它。
五、ARM64的进程地址空间切换
对于ARM64这个cpu arch,每一个cpu core都有两个寄存器来指示当前运行在该CPU core上的进程(线程)实体的地址空间。这两个寄存器分别是ttbr0_el1(用户地址空间)和ttbr1_el1(内核地址空间)。由于所有的进程共享内核地址空间,因此所谓地址空间切换也就是切换ttbr0_el1而已。地址空间听起来很抽象,实际上就是内存中的若干Translation table而已,每一个进程都有自己独立的一组用于翻译用户空间虚拟地址的Translation table,这些信息保存在内存描述符中,具体位于struct mm_struct中的pgd成员中。以pgd为起点,可以遍历该内存描述符的所有用户地址空间的Translation table。具体代码如下:
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)----------------(1)
{
unsigned int cpu = smp_processor_id();
if (prev == next)--------------------(2)
return;
if (next == &init_mm) {-----------------(3)
cpu_set_reserved_ttbr0();
return;
}
check_and_switch_context(next, cpu);
}
(1)prev是要切出的地址空间,next是要切入的地址空间,tsk是将要切入的进程。
(2)要切出的地址空间和要切入的地址空间是一个地址空间的话,那么切换地址空间也就没有什么意义了。
(3)在ARM64中,地址空间的切换主要是切换ttbr0_el1,对于swapper进程的地址空间,其用户空间没有任何的mapping,而如果要切入的地址空间就是swapper进程的地址空间的时候,将(设定ttbr0_el1指向empty_zero_page)。
(4)check_and_switch_context中有很多TLB、ASID相关的操作,我们将会在另外的文档中给出细致描述,这里就简单略过,实际上,最终该函数会调用arch/arm64/mm/proc.S文件中的cpu_do_switch_mm将要切入进程的L0 Translation table物理地址(保存在内存描述符的pgd成员)写入ttbr0_el1。
六、ARM64的的进程切换
由于存在MMU,内存中可以有多个task,并且由调度器依次调度到cpu core上实际执行。系统有多少个cpu core就可以有多少个进程(线程)同时执行。即便是对于一个特定的cpu core,调度器可以可以不断的将控制权从一个task切换到另外一个task上。实际的context switch的动作也不复杂:就是将当前的上下文保存在内存中,然后从内存中恢复另外一个task的上下文。对于ARM64而言,context包括:
(1)通用寄存器
(2)浮点寄存器
(3)地址空间寄存器(ttbr0_el1和ttbr1_el1),上一节已经描述
(4)其他寄存器(ASID、thread process ID register等)
__switch_to代码(位于arch/arm64/kernel/process.c)如下:
struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *next)
{
struct task_struct *last;
fpsimd_thread_switch(next);--------------(1)
tls_thread_switch(next);----------------(2)
hw_breakpoint_thread_switch(next);--和硬件跟踪相关
contextidr_thread_switch(next); --和硬件跟踪相关
dsb(ish);
last = cpu_switch_to(prev, next); ------------(3)
return last;
}
(1)fp是float-point的意思,和浮点运算相关。simd是Single Instruction Multiple Data的意思,和多媒体以及信号处理相关。fpsimd_thread_switch其实就是把当前FPSIMD的状态保存到了内存中(task.thread.fpsimd_state),从要切入的next进程描述符中获取FPSIMD状态,并加载到CPU上。
(2)概念同上,不过是处理tls(thread local storage)的切换。这里硬件寄存器涉及tpidr_el0和tpidrro_el0,涉及的内存是task.thread.tp_value。具体的应用场景是和线程库相关,具体大家可以自行学习了。
(3)具体的切换发生在arch/arm64/kernel/entry.S文件中的cpu_switch_to,代码如下:
ENTRY(cpu_switch_to) -------------------(1)
mov x10, #THREAD_CPU_CONTEXT ----------(2)
add x8, x0, x10 --------------------(3)
mov x9, sp
stp x19, x20, [x8], #16----------------(4)
stp x21, x22, [x8], #16
stp x23, x24, [x8], #16
stp x25, x26, [x8], #16
stp x27, x28, [x8], #16
stp x29, x9, [x8], #16
str lr, [x8] ---------A
add x8, x1, x10 -------------------(5)
ldp x19, x20, [x8], #16----------------(6)
ldp x21, x22, [x8], #16
ldp x23, x24, [x8], #16
ldp x25, x26, [x8], #16
ldp x27, x28, [x8], #16
ldp x29, x9, [x8], #16
ldr lr, [x8] -------B
mov sp, x9 -------C
ret -------------------------(7)
ENDPROC(cpu_switch_to)
(1)进入cpu_switch_to函数之前,x0,x1用做参数传递,x0是prev task,就是那个要挂起的task,x1是next task,就是马上要切入的task。cpu_switch_to和其他的普通函数没有什么不同,尽管会走遍万水千山,但是最终还是会返回调用者函数__switch_to。
在进入细节之前,先想一想这个问题:cpu_switch_to要如何保存现场?要保存那些通用寄存器呢?其实上一小段描述已经做了铺陈:尽管有点怪异,本质上cpu_switch_to仍然是一个普通函数,需要符合ARM64标准过程调用文档。在该文档中规定,x19~x28是属于callee-saved registers,也就是说,在__switch_to函数调用cpu_switch_to函数这个过程中,cpu_switch_to函数要保证x19~x28这些寄存器值是和调用cpu_switch_to函数之前一模一样的。除此之外,pc、sp、fp当然也是必须是属于现场的一部分的。
(2)得到THREAD_CPU_CONTEXT的偏移,保存在x10中
(3)x0是pre task的进程描述符,加上偏移之后就获取了访问cpu context内存的指针(x8寄存器)。所有context的切换的原理都是一样的,就是把当前cpu寄存器保存在内存中,这里的内存是在进程描述符中的 thread.cpu_context中。
(4)一旦定位到保存cpu context(各种通用寄存器)的内存,那么使用stp保存硬件现场。这里x29就是fp(frame pointer),x9保存了stack pointer,lr是返回的PC值。到A代码处,完成了pre task cpu context的保存动作。
(5)和步骤(3)类似,只不过是针对next task而言的。这时候x8指向了next task的cpu context。
(6)和步骤(4)类似,不同的是这里的操作是恢复next task的cpu context。执行到代码B处,所有的寄存器都已经恢复,除了PC和SP,其中PC保存在了lr(x30)中,而sp保存在了x9中。在代码C出恢复了sp值,这时候万事俱备,只等PC操作了。
(7)ret指令其实就是把x30(lr)寄存器的值加载到PC,至此现场完全恢复到调用cpu_switch_to那一点上了。
标签:struct,框架,mm,switch,切换,进程,prev,cpu From: https://www.cnblogs.com/linhaostudy/p/18234151