通过量化可以减少大型语言模型的大小,但是量化是不准确的,因为它在过程中丢失了信息。通常较大的llm可以在精度损失很小的情况下量化到较低的精度,而较小的llm则很难精确量化。
什么时候使用一个小的LLM比量化一个大的LLM更好?
在本文中,我们将通过使用GPTQ对Mistral 7B、Llama 27b和Llama 13B进行8位、4位、3位和2位量化实验来回答这个问题。我们将使用optimum-benchmark比较它们的内存消耗,并使用LLM Evaluation Harness比较它们的准确性。
在最后我们还要介绍一个大模型的最新研究1.58 Bits,它只用 -1,0,1来保存权重,这样就不会再有浮点数,虽然不是量化的方法,但是这样保存模型的权重应该是模型极限了。
llm的核心是深度学习模型,本质上是深度神经网络。这些网络由多层神经元组成,深度堆叠在一起处理和解释大量数据。
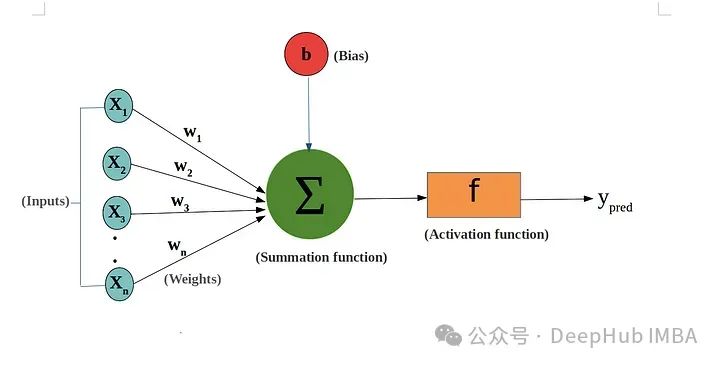
这些网络的运作取决于一种叫做“权重”的东西。这些权重在训练过程中进行训练,以类似于矩阵乘法的方式进行相乘。
https://avoid.overfit.cn/post/9a067e1d895240e9a82827edab45549f
标签:LLM,16,模型,llm,量化,bit,1.58 From: https://www.cnblogs.com/deephub/p/18065670