1. Linux描述物理内存
在linux 内存管理(一)中介绍了UMA和NUMA,Linux通过巧妙办法把UMA和NUMA的差别隐藏了起来,所谓的UMA其实就是只有一个结点的NUMA。内存的每个结点关联到系统中的一个处理器内存控制器,每个服务器处理器可以有多个内存控制器,所以每个服务器处理器可以有多个内存结点。在每个结点管理着它的本地内存范围。内存结点又细分为内存域,每个内存域管理着一部分内存范围,有着不同的使用目的。页面是内存的最小单元,所有的可用物理内存都被细分成页,页面的索引就是页框。
Linux把物理内存划分三个层次:
- Node
- To extend support for NUMA machines, kernel views each non uniform memory partition(local memory) as a node.CPU被划分为多个节点(node), 内存则被分簇, 每个CPU对应一个本地物理内存, 即一个CPU-node对应一个内存簇bank,即每个内存簇被认为是一个节点。
- Zone
- 每个物理内存节点node被划分为多个内存管理区域, 用于表示不同范围的内存, 内核可以使用不同的映射方式映射物理内存。
- Page
- 内存被细分为多个页面帧, 页面是最基本的页面分配的单位。
三种关系如下图所示:
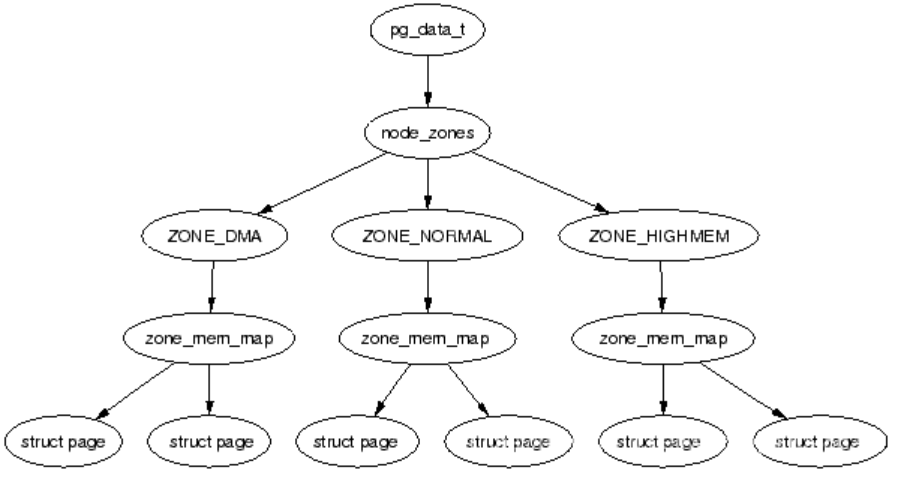
2. Node
在NUMA结构下, 每个CPU与一个本地内存直接相连, 而不同处理器之间,则通过总线进行进一步的连接,因此相对于任何一个CPU访问本地内存的速度比访问远程内存的速度要快。
Linux适用于各种不同的体系结构,而不同体系结构在内存管理方面的差别很大。因此linux内核需要用一种体系结构无关的方式来表示内存。
因此linux内核把物理内存按照CPU节点划分为不同的node,每个node作为某个cpu结点的本地内存,而作为其他CPU节点的远程内存, 而UMA结构下, 则任务系统中只存在一个内存node,这样对于UMA结构来说, 内核把内存当成只有一个内存node节点的伪NUMA。
include/linux/mmzone.h :
680 * On NUMA machines, each NUMA node would have a pg_data_t to describe
681 * it’s memory layout. On UMA machines there is a single pglist_data which
682 * describes the whole memory.
- 对于NUMA系统来讲, 整个系统的内存由一个
node_data的pg_data_t指针数组来管理, - 对于UMA系统(只有一个node),使用struct pglist_data contig_page_data ,作为系统唯一的node管理所有的内存区域。
2.1 struct pg_data_t
内存被划分为结点, 每个节点关联到系统中的一个处理器,内核中表示为pg_data_t的实例。系统中每个节点被链接到一个以NULL结尾的pgdat_list链表中。
内存中的每个节点都是由pg_data_t描述,而pg_data_t由struct pglist_data定义而来, 该数据结构定义:
在分配一个页面时,Linux采用节点局部分配的策略, 从最靠近运行中的CPU的节点分配内存, 由于进程往往是在同一个CPU上运行, 因此从当前节点得到的内存很可能被用到。
pg_data_t描述内存节点:
/*
* The pg_data_t structure is used in machines with CONFIG_DISCONTIGMEM
* (mostly NUMA machines?) to denote a higher-level memory zone than the
* zone denotes.
*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
struct bootmem_data;
typedef struct pglist_data {
/* 包含了结点中各内存域的数据结构 , 可能的区域类型用zone_type表示*/
struct zone node_zones[MAX_NR_ZONES];
/* 指点了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存 */
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones; /* 保存结点中不同内存域的数目 */
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map; /* 指向page实例数组的指针,用于描述结点的所有物理内存页,它包含了结点中所有内存域的页。 */
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#ifndef CONFIG_NO_BOOTMEM
/* 在系统启动boot期间,内存管理子系统初始化之前,
内核页需要使用内存(另外,还需要保留部分内存用于初始化内存管理子系统)
为解决这个问题,内核使用了自举内存分配器
此结构用于这个阶段的内存管理 */
struct bootmem_data *bdata;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG.
*
* Nests above zone->lock and zone->span_seqlock
* 当系统支持内存热插拨时,用于保护本结构中的与节点大小相关的字段。
* 哪调用node_start_pfn,node_present_pages,node_spanned_pages相关的代码时,需要使用该锁。
*/
spinlock_t node_size_lock;
#endif
/* /*起始页面帧号,指出该节点在全局mem_map中的偏移
系统中所有的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一) */
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages 结点中页帧的数目 */
unsigned long node_spanned_pages; /* total size of physical page range, including holes 该结点以页帧为单位计算的长度,包含内存空洞 */
int node_id; /* 全局结点ID,系统中的NUMA结点都从0开始编号 */
wait_queue_head_t kswapd_wait; /* 交换守护进程的等待队列 */
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() 指向负责该结点的交换守护进程的task_struct。 */
int kswapd_max_order; /* 定义需要释放的区域的长度 */
enum zone_type classzone_idx;
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_classzone_idx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
#endif
#ifdef CONFIG_NUMA_BALANCING
/* Lock serializing the migrate rate limiting window */
spinlock_t numabalancing_migrate_lock;
/* Rate limiting time interval */
unsigned long numabalancing_migrate_next_window;
/* Number of pages migrated during the rate limiting time interval */
unsigned long numabalancing_migrate_nr_pages;
#endif
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spinlock_t split_queue_lock;
struct list_head split_queue;
unsigned long split_queue_len;
#endif
} pg_data_t;
2.1.1. 结点的内存管理域
typedef struct pglist_data {
/* 包含了结点中各内存域的数据结构 , 可能的区域类型用zone_type表示*/
struct zone node_zones[MAX_NR_ZONES];
/* 指点了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存 */
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones; /* 保存结点中不同内存域的数目 */
} pg_data_t;
12345678
node_zones[MAX_NR_ZONES]:数组保存了节点中各个内存域的数据结构node_zonelist:指定备用节点以及其内存域的列表, 以便在当前结点没有可用空间时, 在备用节点分配内存nr_zones:存储结点中不同内存域的数目
2.1.2.结点的内存页面
typedef struct pglist_data
{
struct page *node_mem_map; /* 指向page实例数组的指针,用于描述结点的所有物理内存页,它包含了结点中所有内存域的页。 */
/* /*起始页面帧号,指出该节点在全局mem_map中的偏移
系统中所有的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一) */
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages 结点中页帧的数目 */
unsigned long node_spanned_pages; /* total size of physical page range, including holes 该结点以页帧为单位计算的长度,包含内存空洞 */
int node_id; /* 全局结点ID,系统中的NUMA结点都从0开始编号 */
} pg_data_t;
node_mem_map:是指向页面page实例数组的指针, 用于描述结点的所有物理内存页. 它包含了结点中所有内存域的页.node_start_pfn:是该NUMA结点的第一个页帧的逻辑编号. 系统中所有的节点的页帧是一次编号的, 每个页帧的编号是全局唯一的. node_start_pfn在UMA系统中总是0, 因为系统中只有一个内存结点, 因此其第一个页帧编号总是0.node_present_pages:指定了结点中页帧的数目, 而node_spanned_pages则给出了该结点以页帧为单位计算的长度. 二者的值不一定相同, 因为结点中可能有一些空洞, 并不对应真正的页帧.
2.2.结点的状态
2.2.1. 结点状态标识node_states
内核用enum node_state变量标记内存结点所有可能的状态信息。
include/linux/nodemask.h:
enum node_states {
N_POSSIBLE, /* The node could become online at some point
结点在某个时候可能变成联机*/
N_ONLINE, /* The node is online
节点是联机的*/
N_NORMAL_MEMORY, /* The node has regular memory
结点是普通内存域 */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory
结点是普通或者高端内存域*/
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
#ifdef CONFIG_MOVABLE_NODE
N_MEMORY, /* The node has memory(regular, high, movable) */
#else
N_MEMORY = N_HIGH_MEMORY,
#endif
N_CPU, /* The node has one or more cpus */
NR_NODE_STATES
};
3.zone
为什么Linux内核又把各个物理内存节点分成个不同的管理区域zone ?
因为实际的计算机体系结构有硬件的诸多限制,这限制了页框可以使用的方式。尤其是,Linux内核必须处理80x86体系结构的两种硬件约束:
- ISA总线的直接内存存储DMA处理器有一个严格的限制 : 他们只能对RAM的前16MB进行寻址。
- 在具有大容量RAM的现代32位计算机中, CPU不能直接访问所有的物理地址,因为线性地址空间太小, 内核不可能直接映射所有物理内存到线性地址空间。
因此Linux内核对不同区域的内存需要采用不同的管理方式和映射方式,因此内核将物理地址或者成用zone_t表示的不同地址区域。
3.1.内存管理区类型zone_type
include/linux/mmzone.h:
enum zone_type
{
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
ZONE_DMA类型的内存区域在物理内存的低端,主要是ISA设备只能用低端的地址做DMA操作。ZONE_NORMAL类型的内存区域直接被内核映射到线性地址空间上面的区域(line address space)。ZONE_HIGHMEM将保留给系统使用,是系统中预留的可用内存空间,不能被内核直接映射。ZONE_MOVABLE内核定义了一个伪内存域ZONE_MOVABLE, 在防止物理内存碎片的机制memory migration中需要使用该内存域. 供防止物理内存碎片的极致使用ZONE_DEVICE为支持热插拔设备而分配的Non Volatile Memory非易失性内存
3.2. struct zone结构体
struct zone {
/* Fields commonly accessed by the page allocator */
/* zone watermarks, access with *_wmark_pages(zone) macros */
/*本管理区的三个水线值:高水线(比较充足)、低水线、MIN水线。*/
unsigned long watermark[NR_WMARK];
/*
* We don't know if the memory that we're going to allocate will be freeable
* or/and it will be released eventually, so to avoid totally wasting several
* GB of ram we must reserve some of the lower zone memory (otherwise we risk
* to run OOM on the lower zones despite there's tons of freeable ram
* on the higher zones). This array is recalculated at runtime if the
* sysctl_lowmem_reserve_ratio sysctl changes.
*/
/**
* 当高端内存、normal内存区域中无法分配到内存时,需要从normal、DMA区域中分配内存。
* 为了避免DMA区域被消耗光,需要额外保留一些内存供驱动使用。
* 该字段就是指从上级内存区退到回内存区时,需要额外保留的内存数量。
*/
unsigned long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
/*所属的NUMA节点。*/
int node;
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
/*当可回收的页超过此值时,将进行页面回收。*/
unsigned long min_unmapped_pages;
/*当管理区中,用于slab的可回收页大于此值时,将回收slab中的缓存页。*/
unsigned long min_slab_pages;
/*
* 每CPU的页面缓存。
* 当分配单个页面时,首先从该缓存中分配页面。这样可以:
*避免使用全局的锁
* 避免同一个页面反复被不同的CPU分配,引起缓存行的失效。
* 避免将管理区中的大块分割成碎片。
*/
struct per_cpu_pageset *pageset[NR_CPUS];
#else
struct per_cpu_pageset pageset[NR_CPUS];
#endif
/*
* free areas of different sizes
*/
/*该锁用于保护伙伴系统数据结构。即保护free_area相关数据。*/
spinlock_t lock;
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
/*用于保护spanned/present_pages等变量。这些变量几乎不会发生变化,除非发生了内存热插拨操作。
这几个变量并不被lock字段保护。并且主要用于读,因此使用读写锁。*/
seqlock_t span_seqlock;
#endif
/*伙伴系统的主要变量。这个数组定义了11个队列,每个队列中的元素都是大小为2^n的页面*/
struct free_area free_area[MAX_ORDER];
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
/*本管理区里的页面标志数组*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/*填充的未用字段,确保后面的字段是缓存行对齐的*/
ZONE_PADDING(_pad1_)
/* Fields commonly accessed by the page reclaim scanner */
/*
* lru相关的字段用于内存回收。这个字段用于保护这几个回收相关的字段。
* lru用于确定哪些字段是活跃的,哪些不是活跃的,并据此确定应当被写回到磁盘以释放内存。
*/
spinlock_t lru_lock;
/* 匿名活动页、匿名不活动页、文件活动页、文件不活动页链表头*/
struct zone_lru {
struct list_head list;
} lru[NR_LRU_LISTS];
/*页面回收状态*/
struct zone_reclaim_stat reclaim_stat;
/*自从最后一次回收页面以来,扫过的页面数*/
unsigned long pages_scanned; /* since last reclaim */
unsigned long flags; /* zone flags, see below */
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
/*
* prev_priority holds the scanning priority for this zone. It is
* defined as the scanning priority at which we achieved our reclaim
* target at the previous try_to_free_pages() or balance_pgdat()
* invokation.
*
* We use prev_priority as a measure of how much stress page reclaim is
* under - it drives the swappiness decision: whether to unmap mapped
* pages.
*
* Access to both this field is quite racy even on uniprocessor. But
* it is expected to average out OK.
*/
int prev_priority;
/*
* The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
* this zone's LRU. Maintained by the pageout code.
*/
unsigned int inactive_ratio;
/*为cache对齐*/
ZONE_PADDING(_pad2_)
/* Rarely used or read-mostly fields */
/*
* wait_table -- the array holding the hash table
* wait_table_hash_nr_entries -- the size of the hash table array
* wait_table_bits -- wait_table_size == (1 << wait_table_bits)
*
* The purpose of all these is to keep track of the people
* waiting for a page to become available and make them
* runnable again when possible. The trouble is that this
* consumes a lot of space, especially when so few things
* wait on pages at a given time. So instead of using
* per-page waitqueues, we use a waitqueue hash table.
*
* The bucket discipline is to sleep on the same queue when
* colliding and wake all in that wait queue when removing.
* When something wakes, it must check to be sure its page is
* truly available, a la thundering herd. The cost of a
* collision is great, but given the expected load of the
* table, they should be so rare as to be outweighed by the
* benefits from the saved space.
*
* __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the
* primary users of these fields, and in mm/page_alloc.c
* free_area_init_core() performs the initialization of them.
*/
wait_queue_head_t * wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
/*
* Discontig memory support fields.
*/
/*管理区属于的节点*/
struct pglist_data *zone_pgdat;
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
/*管理区的页面在mem_map中的偏移*/
unsigned long zone_start_pfn;
/*
* zone_start_pfn, spanned_pages and present_pages are all
* protected by span_seqlock. It is a seqlock because it has
* to be read outside of zone->lock, and it is done in the main
* allocator path. But, it is written quite infrequently.
*
* The lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*/
unsigned long spanned_pages; /* total size, including holes */
unsigned long present_pages; /* amount of memory (excluding holes) */
/*
* rarely used fields:
*/
const char *name;
} ____cacheline_internodealigned_in_smp;
如上所示,包含如下结构体数组:
struct free_area free_area[MAX_ORDER];
#define MAX_ORDER 11
include/linux/mmzone.h:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
- free_list 是用于连接空闲页的链表. 页链表包含大小相同的连续内存区
- nr_free 指定了当前内存区中空闲页块的数目
阶是描述了内存分配的数量单位。内存块的长度是2^0,order , 其中order的范围从0到MAX_ORDER。zone->free_area[MAX_ORDER]数组中阶作为各个元素的索引, 用于指定对应链表中的连续内存区包含多少个页帧。
- 数组中第0个元素的阶为0, 它的free_list链表域指向具有包含区为单页(2^0 = 1)的内存页面链表
- 数组中第1个元素的free_list域管理的内存区为两页(2^1 = 2)
- 第3个管理的内存区为4页,依次类推
- 直到 2^MAXORDER-1个页面大小的块

4.page
页框是系统内存的最小单位。对内存中的每个页都会创建struct page实例。内核需要注意保持该结构尽可能小。因为即便在中等程度内存配置下,系统的内存同样会分解为大量的页。例如当页长度为4KB,主内存384MB时大约需要100000页。
include/linux/mm_types.h:
struct page {
unsigned long flags;
atomic_t _count;
union {
atomic_t _mapcount;
struct { /* SLUB */
u16 inuse;
u16 objects;
};
};
union {
struct {
unsigned long private;
struct address_space *mapping;
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
/* 如果属于伙伴系统,并且不是伙伴系统中的第一个页
则指向第一个页*/
struct page *first_page; /* Compound tail pages */
};
union {/*如果是文件映射,那么表示本页面在文件中的位置(偏移)*/
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
#ifdef CONFIG_KMEMCHECK
void *shadow;
#endif
};
因为内核会为每一个物理页帧创建一个struct page的结构体,因此要保证page结构体足够的小,否则仅struct page就要占用大量的内存。出于节省内存的考虑,struct page中使用了大量的联合体union。下面仅对常用的一些的字段做说明:
- flags:描述page的状态和其他信息;
PG_locked:page被锁定,说明有使用者正在操作该page。
PG_error:状态标志,表示涉及该page的IO操作发生了错误。
PG_referenced:表示page刚刚被访问过。
PG_active:page处于inactive LRU链表。PG_active和PG_referenced一起控制该page的活跃程度,这在内存回收时将会非常有用。
PG_uptodate:表示page的数据已经与后备存储器是同步的,是最新的。
PG_dirty:与后备存储器中的数据相比,该page的内容已经被修改。
PG_lru:表示该page处于LRU链表上。
PG_slab:该page属于slab分配器。
PG_reserved:设置该标志,防止该page被交换到swap。
PG_private:如果page中的private成员非空,则需要设置该标志。参考6)对private的解释。
PG_writeback:page中的数据正在被回写到后备存储器。
PG_swapcache:表示该page处于swap cache中。
PG_mappedtodisk:表示page中的数据在后备存储器中有对应。
PG_reclaim:表示该page要被回收。当PFRA决定要回收某个page后,需要设置该标志。
PG_swapbacked:该page的后备存储器是swap。
PG_unevictable:该page被锁住,不能交换,并会出现在LRU_UNEVICTABLE链表中,它包括的几种page:ramdisk或ramfs使用的页、
shm_locked、mlock锁定的页。
PG_mlocked:该page在vma中被锁定,一般是通过系统调用mlock()锁定了一段内存。
-
count
引用计数,表示内核中引用该page的次数,如果要操作该page,引用计数会+1,操作完成-1。当该值为0时,表示没有引用该page的位置,所以该page可以被解除映射,这往往在内存回收时是有用的。 -
mapcount
被页表映射的次数,也就是说该page同时被多少个进程共享。初始值为-1,如果只被一个进程的页表映射了,该值为0 。如果该page处于伙伴系统中,该值为PAGE_BUDDY_MAPCOUNT_VALUE(-128),内核通过判断该值是否为PAGE_BUDDY_MAPCOUNT_VALUE来确定该page是否属于伙伴系统。Note:注意区分count和mapcount,mapcount表示的是映射次数,而count表示的是使用次数;被映射了不一定在使用,但要使用必须先映射。
- mapping :有三种含义
- 如果mapping = 0,说明该page属于交换缓存(swap cache);当需要使用地址空间时会指定交换分区的地址空间swapper_space。
- 如果mapping != 0,bit[0] = 0,说明该page属于页缓存或文件映射,mapping指向文件的地址空间address_space。
- 如果mapping != 0,bit[0] != 0,说明该page为匿名映射,mapping指向struct anon_vma对象。
通过mapping恢复anon_vma的方法:anon_vma = (struct anon_vma *)(mapping - PAGE_MAPPING_ANON)。
- mapping :有三种含义
-
index:在映射的虚拟空间(vma_area)内的偏移;一个文件可能只映射一部分,假设映射了1M的空间,index指的是在1M空间内的偏移,而不是在整个文件内的偏移。
-
private:私有数据指针,由应用场景确定其具体的含义:
- 如果设置了PG_private标志,表示buffer_heads;
- 如果设置了PG_swapcache标志,private存储了该page在交换分区中对应的位置信息swp_entry_t。
- 如果_mapcount = PAGE_BUDDY_MAPCOUNT_VALUE,说明该page位于伙伴系统,private存储该伙伴的阶。
-
lru:链表头,主要有3个用途:
- page处于伙伴系统中时,用于链接相同阶的伙伴(只使用伙伴中的第一个page的lru即可达到目的)。
- page属于slab时,page->lru.next指向page驻留的的缓存的管理结构,page->lru.prec指向保存该page的slab的管理结构。
- page被用户态使用或被当做页缓存使用时,用于将该page连入zone中相应的lru链表,供内存回收时使用。
数据结构:
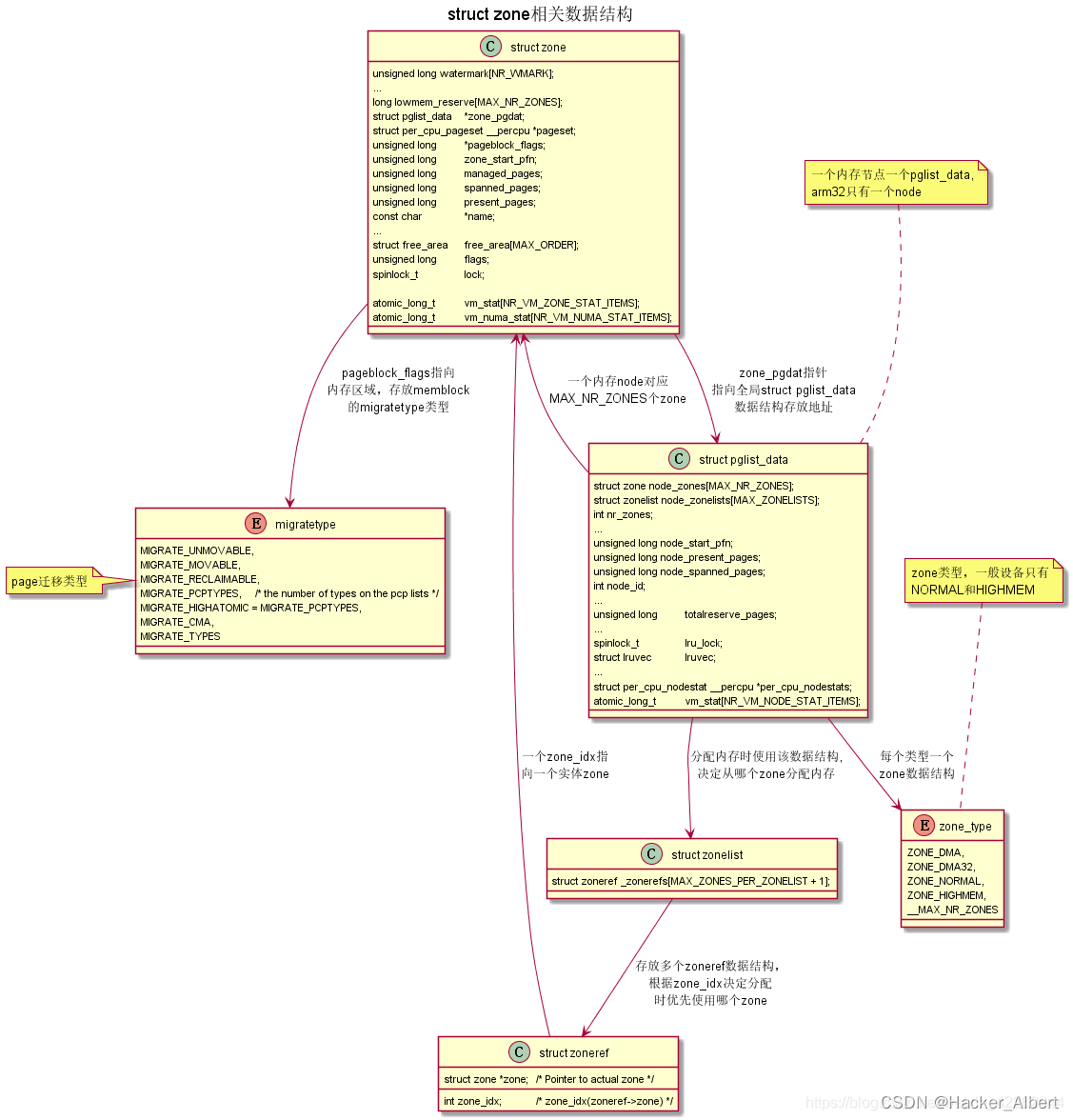
原文链接 :https://blog.csdn.net/weixin_41028621/article/details/100600020
标签:node,结点,struct,zone,内存,page From: https://www.cnblogs.com/dongxb/p/17922480.html