https://zhuanlan.zhihu.com/p/501473091
我的Linux系统背景:
- 系统和驱动都已安装。
- 系统是centos 8。查看自己操作系统的版本信息:
cat /etc/issue或者是cat /etc/lsb-release - 用
nvidia-smi可以看到显卡驱动和可支持的最高cuda版本,我的是11.4。驱动版本是470.57.02。
首先,检查是否安装了CUDA:ls -l /usr/local | grep cuda
如果已经安装了就不需要再次安装,当然有一种说法是不安装CUDA也可行,在虚拟环境中安装pytorch的时候会自动装一个不完整的CUDA,足够跑深度学习了。但是如果需要cuda编程等操作就需要安装完整版的CUDA,也就是后面我要介绍的安装过程。
其实我也试过不安装CUDA直接安装pytorch,确实是可用的,只不过用deepspeed的时候会报错找不到CUDA HOME,所以还是安装完整版CUDA吧~
1.安装cuda
根据机器的显卡驱动可以查看可安装的cuda版本
参考:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
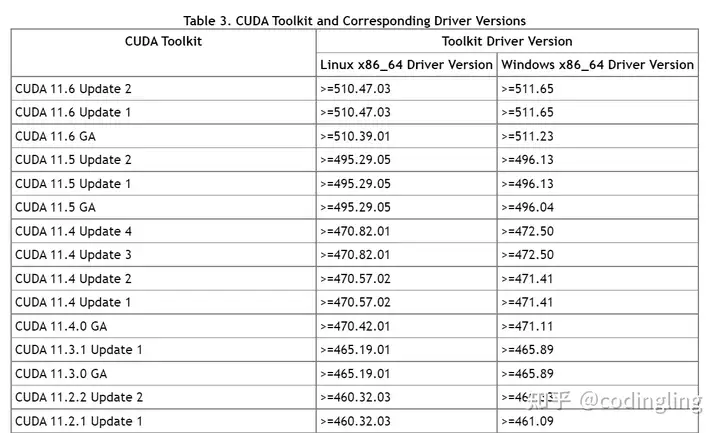
我选择安装的是CUDA 11.3.1,不同版本下载安装链接,根据自己的系统选择下图的选项,installer type选择runfile(local),然后根据给出的命令安装CUDA:
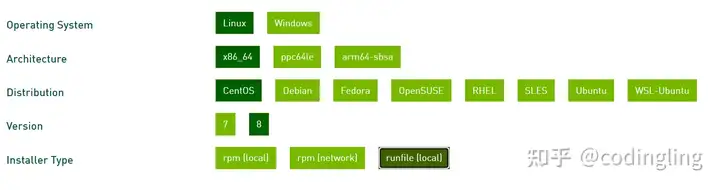
比如我安装CUDA 11.3.1的命令是:
wget https://developer.download.nvidia.com/compute/cuda/11.3.1/local_installers/cuda_11.3.1_465.19.01_linux.run
sudo sh cuda_11.3.1_465.19.01_linux.run
傻瓜式操作输入yes,accept等即可。安装的时候注意选择不安装驱动,因为机器本身已经有驱动,所以这一步需要用空格取消对Driver的选中(事实上我遇到的情况是,如果不取消选中,安装会fail)。其他选项中除了CUDA Toolkit是必选,其他都是可选项目。我这里其他都选择了。最后选择Install。类似于下图
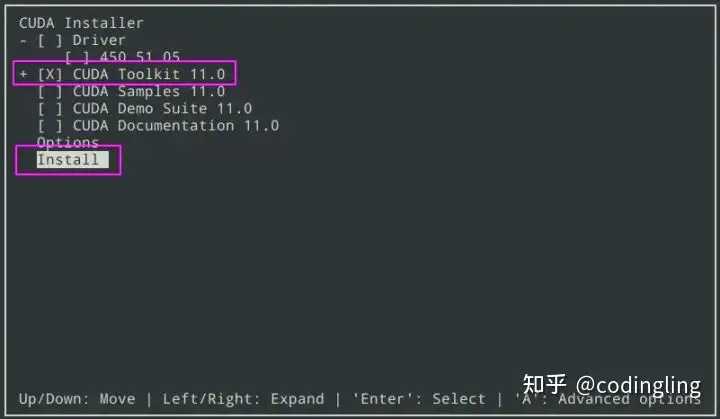
如果这个过程中出现提示existing package manager installation of the driver found,那么需要先退出安装,删除cuda toolkit和driver
To remove CUDA Toolkit:
$ sudo dnf remove "cuda*" "*cublas*" "*cufft*" "*curand*" \
"*cusolver*" "*cusparse*" "*npp*" "*nvjpeg*" "nsight*"
To remove NVIDIA Drivers:
$ sudo dnf remove nvidia-driver
To reset the module stream:
$ sudo dnf module reset nvidia-driver
然后装CUDA,再装驱动:sudo dnf module install nvidia-driver
如果没有出现这个问题就不需要管驱动啦~
检查cuda是否安装成功:nvcc -V
如果没有这个命令的话,需要配置。
vim ~/.bashrc
在文件末尾添加(这里的/usr/local/cuda-11.3替换成你的cuda安装路径,一般都在/usr/local路径下)
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.3/lib64
export PATH=$PATH:/usr/local/cuda-11.3/bin
# export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.3
export CUDA_HOME=/usr/local/cuda-11.3
然后source ~/.bashrc
上述环境变量中,我看很多教程都是按照第三行配置的CUDA_HOME,但是后续我在使用deepspeed的时候会报错找不到/usr/local/cuda-11.3:/usr/local/cuda-11.3/bin/nvcc,按照第四行配置CUDA_HOME就不会有这个问题。
再执行nvcc -V就会显示出你刚刚安装的CUDA版本
2.安装cuDNN
cuDNN是NVIDIA专门针对深度神经网络(Deep Neural Networks)中的基础操作而设计基于GPU的加速库。不安装的话不会报错,但是训练的速度会慢很多。
去英伟达官网下载cuda 11.3对应的cuDNN安装包(需要注册),具体安装哪个版本呢,可以参考这个链接和你的CUDA版本选择。
我选择安装的是8.2.0版本,cuDNN Library for Linux(x86_64)这个版本(图中的第二个链接),下载后的文件是cudnn-11.3-linux-x64-v8.2.0.53.tgz
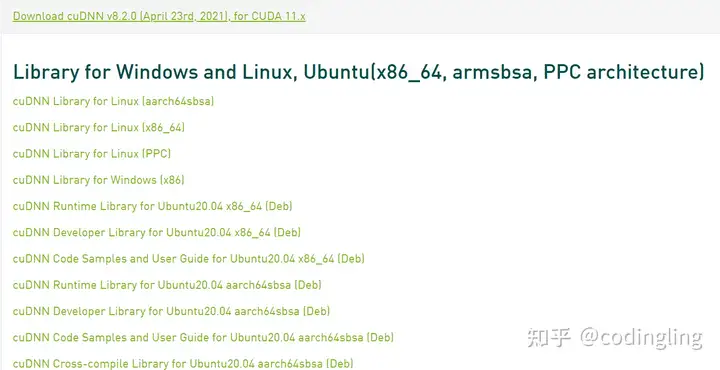
下载完成后解压得到cuda目录,cuda目录下面有include和lib64两个子目录。将cuda/include/cudnn.h文件复制到usr/local/cuda-11.3/include文件夹,将cuda/lib64/下所有以libcudnn开头的文件复制到/usr/local/cuda-11.3/lib64文件夹中,并添加读取权限
tar -xvf cudnn-11.3-linux-x64-v8.2.0.53.tgz #解压
sudo cp cuda/include/cudnn.h /usr/local/cuda-xx.x/include # 填写对应的版本的cuda路径
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-xx.x/lib64 # 填写对应的版本的cuda路径
sudo chmod a+r /usr/local/cuda-xx.xx/include/cudnn.h /usr/local/cuda-xx.xx/lib64/libcudnn*
3.测试是否成功
安装miniconda,创建环境,安装pytorch。conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch。
进入环境,执行
import torch
torch.cuda.is_available()
返回True就说明没问题了。
然后此处我一直是False,报错信息是Error 802: system not yet initialized 。
搜索这个报错信息,找到教程,可以用来验证CUDA是否安装成功。
教程里用的是ubuntu系统。centos系统的操作过程如下(注意下面的教程操作完成后,显卡驱动会更新)
# 需要先安装git:sudo yum install -y git
# 其实安装cuda的时候如果选了samples也可以直接用那个
git clone https://github.com/NVIDIA/cuda-samples.git
# 这个路径如果不存在,就自己找找bandwidthTest在哪个路径,因为项目可能有更新
cd cuda-samples/Samples/1-Utilities/bandwidthTest
make
./bandwidthTest
注意如果make报错说没有g++,需要安装**yum install gcc-c++**
执行./bandwidthTest后报错:
> ./bandwidthTest
[CUDA Bandwidth Test] - Starting...
Running on...
cudaGetDeviceProperties returned 802
-> system not yet initialized
CUDA error at bandwidthTest.cu:256 code=802(cudaErrorSystemNotReady) "cudaSetDevice(currentDevice)"
需要安装Data Center GPU manager。安装教程
# Set up the CUDA network repository meta-data, GPG key
sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
# Install DCGM
sudo dnf clean expire-cache \
&& sudo dnf install -y datacenter-gpu-manager
# Set up the DCGM service
sudo systemctl --now enable nvidia-dcgm
然后
# terminate the host engine,这里可能会报错unable to terminate xxx,忽略
sudo nv-hostengine -t
# and start the fabricmanager
sudo service nvidia-fabricmanager start
如果报错了:
> sudo service nvidia-fabricmanager start
Failed to start nvidia-fabricmanager.service: Unit nvidia-fabricmanager.service not found.
sudo dnf install cuda-drivers-fabricmanager
sudo service nvidia-fabricmanager start
start的时候报错Job for nvidia-fabricmanager.service failed because the control process exited with error code.
systemctl status nvidia-fabricmanager.service也看不出个所以然,用nvidia-smi发现报错Failed to initialize NVML: Driver/library version mismatch说明驱动不匹配。
查看驱动版本cat /proc/driver/nvidia/version,还是之前的。
重启服务器,再次查看驱动,发现驱动升级了。
nvidia-smi也可以用,显示的CUDA版本是11.6,跟nvcc看到的版本不一样。不过这并不冲突,nvcc看到的CUDA版本不会大于nvdia-smi看到的版本,安装pytorch的时候也是根据nvcc的CUDA版本安装的。
至于两者为什么不一样,可以查看这篇文章:【CUDA】nvcc和nvidia-smi显示的版本不一致?。
再次执行sudo service nvidia-fabricmanager start不报错
按照之前的教程,验证cuda是否安装成功
cd cuda-samples/Samples/1-Utilities/bandwidthTest
./bandwidthTest
没有报错!进一步验证torch.cuda.is_available()返回True。大功告成!
参考资料
理清GPU、CUDA、CUDA Toolkit、cuDNN关系以及下载安装
https://lizhihao999.cn/posts/脱坑记录/linux多版本cuda安装及切换/
发布于 2022-04-19 23:11 标签:Linux,sudo,11.3,cuda,nvidia,安装,CUDA From: https://www.cnblogs.com/wcxia1985/p/17761200.html