Docker 基础技术之 Linux namespace 详解
Docker 是“新瓶装旧酒”的产物,依赖于 Linux 内核技术 chroot 、namespace 和 cgroup。本篇先来看 namespace 技术。
Docker 和虚拟机技术一样,从操作系统级上实现了资源的隔离,它本质上是宿主机上的进程(容器进程),所以资源隔离主要就是指进程资源的隔离。实现资源隔离的核心技术就是 Linux namespace。这技术和很多语言的命名空间的设计思想是一致的(如 C++ 的 namespace)。
隔离意味着可以抽象出多个轻量级的内核(容器进程),这些进程可以充分利用宿主机的资源,宿主机有的资源容器进程都可以享有,但彼此之间是隔离的,同样,不同容器进程之间使用资源也是隔离的,这样,彼此之间进行相同的操作,都不会互相干扰,安全性得到保障。
为了支持这些特性,Linux namespace 实现了 6 项资源隔离,基本上涵盖了一个小型操作系统的运行要素,包括主机名、用户权限、文件系统、网络、进程号、进程间通信。

这 6 项资源隔离分别对应 6 种系统调用,通过传入上表中的参数,调用 clone() 函数来完成。
1 |
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg); |
clone() 函数相信大家都不陌生了,它是 fork() 函数更通用的实现方式,通过调用 clone(),并传入需要隔离资源对应的参数,就可以建立一个容器了(隔离什么我们自己控制)。
一个容器进程也可以再 clone() 出一个容器进程,这是容器的嵌套。
如果想要查看当前进程下有哪些 namespace 隔离,可以查看文件 /proc/[pid]/ns (注:该方法仅限于 3.8 版本以后的内核)。
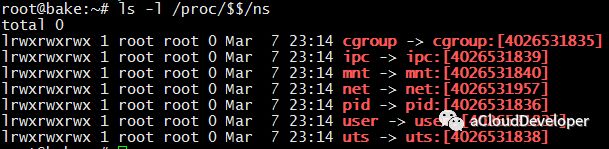
可以看到,每一项 namespace 都附带一个编号,这是唯一标识 namespace 的,如果两个进程指向的 namespace 编号相同,则表示它们同在该 namespace 下。同时也注意到,多了一个 cgroup,这个 namespace 是 4.6 版本的内核才支持的。Docker 目前对它的支持普及度还不高。所以我们暂时先不考虑它。下面通过简单的代码来实现 6 种 namespace 的隔离效果,让大家有个直观的印象。
UTS namespace
UTS namespace 提供了主机名和域名的隔离,这样每个容器就拥有独立的主机名和域名了,在网络上就可以被视为一个独立的节点,在容器中对 hostname 的命名不会对宿主机造成任何影响。
首先,先看总体的代码骨架:
1 |
#define _GNU_SOURCE |
该程序骨架调用 clone() 函数实现了子进程的创建工作,并定义子进程的执行函数,clone() 第二个参数指定了子进程运行的栈空间大小,第三个参数即为创建不同 namespace 隔离的关键。
对于 UTS namespace,传入 CLONE_NEWUTS,如下:
1 |
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS, NULL); |
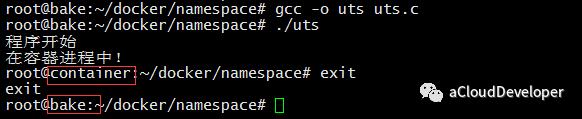
为了能够看出容器内和容器外主机名的变化,我们子进程执行函数中加入:
1 |
sethostname("container", 9);
|
最终运行可以看到效果如下:
IPC namespace
IPC namespace 实现了进程间通信的隔离,包括常见的几种进程间通信机制,如信号量,消息队列和共享内存。我们知道,要完成 IPC,需要申请一个全局唯一的标识符,即 IPC 标识符,所以 IPC 资源隔离主要完成的就是隔离 IPC 标识符。
同样,代码修改仅需要加入参数 CLONE_NEWIPC 即可,如下:
1 |
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC, NULL); |
为了看出变化,首先在宿主机上建立一个消息队列:
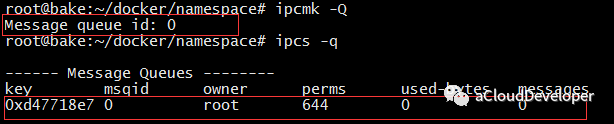
然后运行程序,进入容器查看 IPC,没有找到原先建立的 IPC 标识,达到了 IPC 隔离。
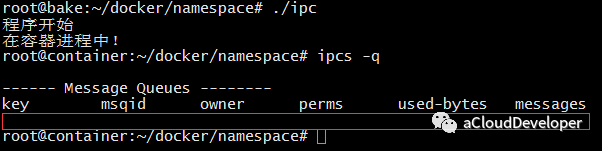
PID namespace
PID namespace 完成的是进程号的隔离,同样在 clone() 中加入 CLONE_NEWPID 参数,如:
1 |
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID, NULL); |
效果如下,echo $$ 输出 shell 的 PID 号,发生了变化。
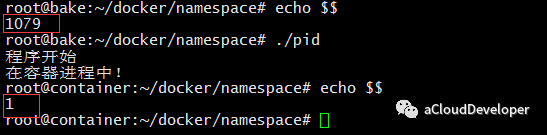
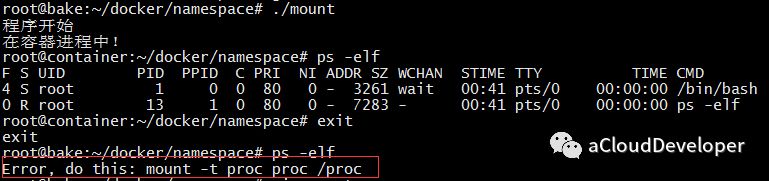
但是对于 ps/top 之类命令却没有改变:
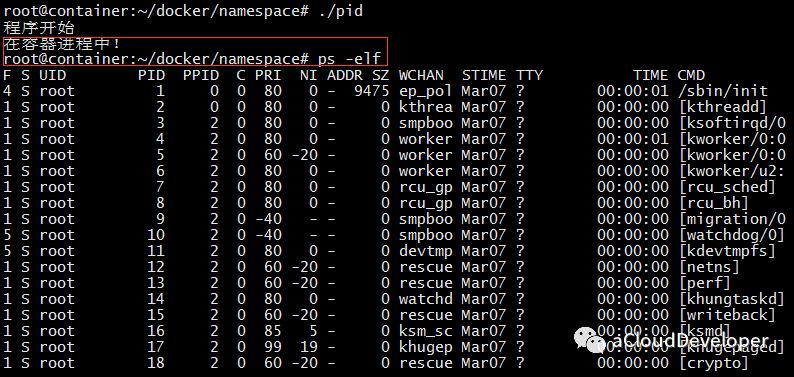
原因是 ps/top 之类的命令底层调用的是文件系统的 /proc 文件内容,由于 /proc 文件系统(procfs)还没有挂载到一个与原 /proc 不同的位置,自然在容器中显示的就是宿主机的进程。
我们可以通过在容器中重新挂载 /proc 即可实现隔离,如下:

这种方式会破坏 root namespace 中的文件系统,当退出容器时,如果 ps 会出现错误,只有再重新挂载一次 /proc 才能恢复。
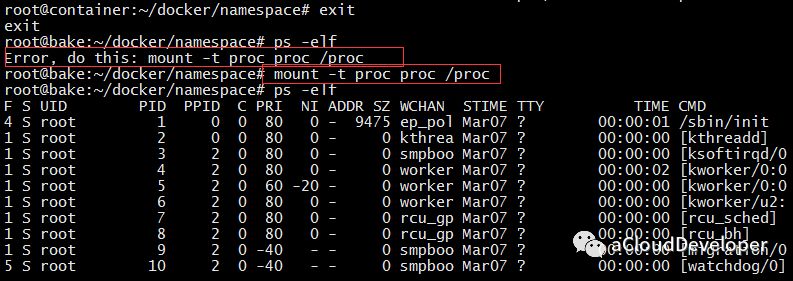
一劳永逸地解决这个问题最好的方法就是用接下来介绍的 mount namespace。
mount namespace
mount namespace 通过隔离文件系统的挂载点来达到对文件系统的隔离。我们依然在代码中加入 CLONE_NEWNS 参数:
1 |
int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNS, NULL); |
我验证的效果,当退出容器时,还是会有 mount 错误,这没道理,经多方查阅,没有找到问题的根源(有谁知道,可以留言指出)。
Network namespace
Network namespace 实现了网络资源的隔离,包括网络设备、IPv4 和 IPv6 协议栈,IP 路由表,防火墙,/proc/net 目录,/sys/class/net 目录,套接字等。
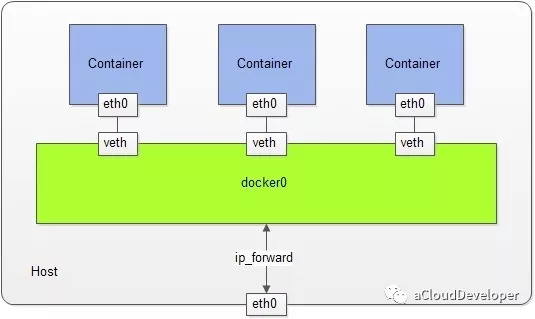
Network namespace 不同于其他 namespace 可以独立工作,要使得容器进程和宿主机或其他容器进程之间通信,需要某种“桥梁机制”来连接彼此(并没有真正的隔离),这是通过创建 veth pair (虚拟网络设备对,有两端,类似于管道,数据从一端传入能从另一端收到,反之亦然)来实现的。当建立 Network namespace 后,内核会首先建立一个 docker0 网桥,功能类似于 Bridge,用于建立各容器之间和宿主机之间的通信,具体就是分别将 veth pair 的两端分别绑定到 docker0 和新建的 namespace 中。
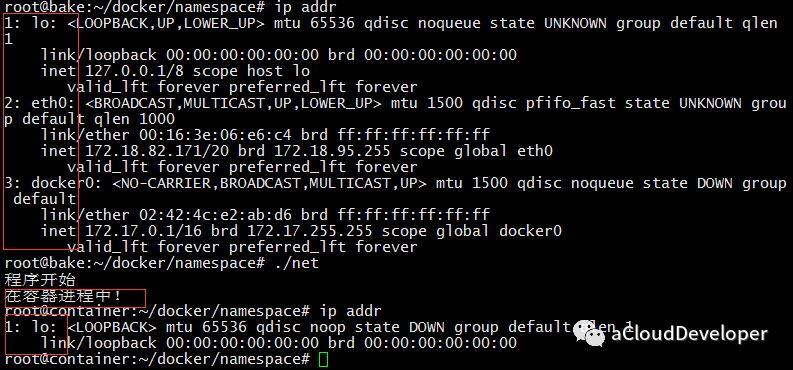
和其他 namespace 一样,Network namespace 的创建也是加入 CLONE_NEWNET 参数即可。我们可以简单验证下 IP 地址的情况,如下,IP 被隔离了。
User namespace
User namespace 主要隔离了安全相关的标识符和属性,包括用户 ID、用户组 ID、root 目录、key 以及特殊权限。简单说,就是一个普通用户的进程通过 clone() 之后在新的 user namespace 中可以拥有不同的用户和用户组,比如可能是超级用户。
同样,可以加入 CLONE_NEWUSER 参数来创建一个 User namespace。然后再子进程执行函数中加入 getuid() 和 getpid() 得到 namespace 内部的 User ID,效果如下:
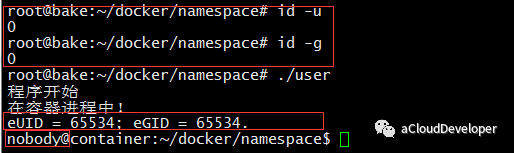
可以看到,容器内部看到的 UID 和 GID 和外部不同了,默认显示为 65534。这是因为容器找不到其真正的 UID ,所以设置上了最大的UID(其设置定义在/proc/sys/kernel/overflowuid)。另外就是用户变为了 nobody,不再是 root,达到了隔离。
总结
以上就是对 6 种 namespace 从代码上简单直观地演示其实现,当然,真正的实现比这个要复杂得多,然后这 6 种 namespace 实际上也没有完全隔离 Linux 的资源,比如 SElinux、cgroup 以及 /sys 等目录下的资源没有隔离。目前,Docker 在很多方面已经做的很好,但相比虚拟机,仍然有许多安全性问题急需解决。
参考链接:
https://ctimbai.github.io/2018/03/08/tech/cloud/container/docker/Docker_%E5%9F%BA%E7%A1%80%E6%8A%80%E6%9C%AF%E4%B9%8B_Linux_namespace_%E8%AF%A6%E8%A7%A3/
https://coolshell.cn/articles/17010.html
标签:容器,container,隔离,CLONE,namespace,288,Linux,进程 From: https://www.cnblogs.com/hechangchun/p/17166524.html