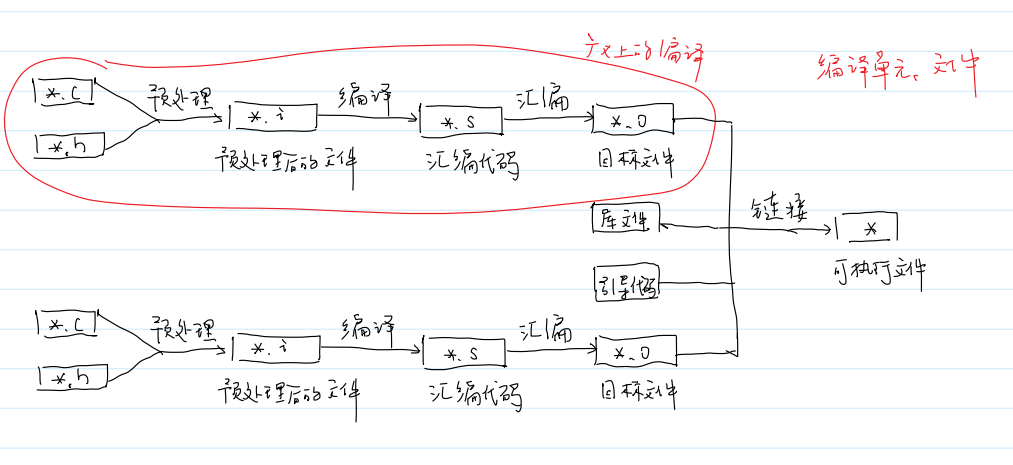
编译工具链
IDE(集成开发环境):visual studio,clion,Eclipse,xcode
SDK(software Development Kit):软件开发工具包
GCC(GNU C Compiler)
// 查看gcc版本
gcc -v
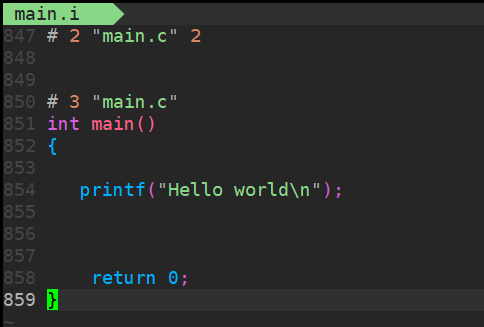
预处理(-E)
作用:执行预处理指令
常见的预处理指令
-
#include<stdio.h>
-
#define N 5
-
#define SIZE(a)(sizeof(a)/sizeof(a[0]))
-
宏开关
宏开关
// 一般很少用
#if
//...
#else
//...
#endif
// 条件编译
#ifdef
//...
#else
//..
#endif
//ex:
#include <stdio.h>
int main(void)
{
#ifdef N
printf("Hello world\n");
#else
printf("I love xjl~\n");
#endif
return 0;
}
预处理指令:

// 防御或声明,防止头文件被包含多次
#ifndef
//...
#else
//...
#endif
编译(-S)
作用:把预处理后的代码翻译成汇编代码
gcc -S main.c -o main.s
汇编基础
基本操作
push(入栈) mov(移动) call(函数调用) ret(函数返回)
pop(出栈) lea(load effective address,加载有效地址,等价于取地址&)
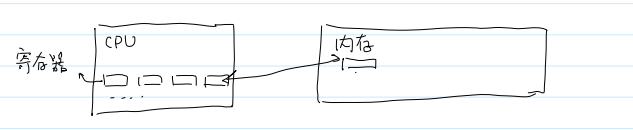
寄存器
寄存器是 CPU 内部用来存放数据的一些小型存储区域 ,用来暂时存放参与运算的数据和运算结果。在计算机领域,寄存器是CPU内部的元件,包括通用寄存器、专用寄存器和控制寄存器。寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快。
- 有16个常用寄存器
%rax、 %rbx、 %rcx、 %rdx、 %rsi、 %rdi、 %rbp、 %rsp
%r8、 %r9、 %r10、 %r11、 %r12、 %r13、 %r14、 %r15
- 寄存器大小
1、r开头的寄存器都是64位8字节的
2、e开头的寄存器是32位4字节的
3、l和h结尾的寄存器是16位2字节的
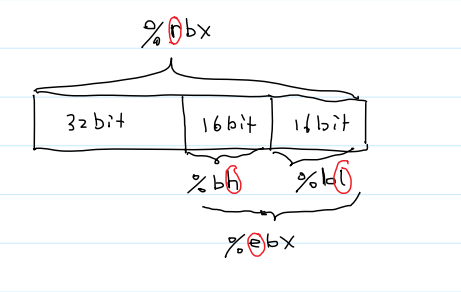
特殊的寄存器
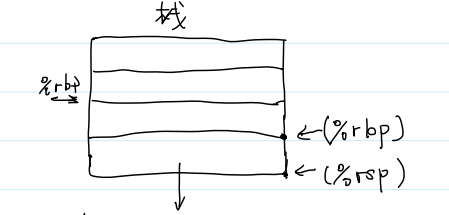
%rbp:register base pointer(栈帧的基址寄存器)
%rsp:register stack pointer(栈顶的地址)
%rdi:参数寄存器 第一个参数
%edi:参数寄存器 第一个参数(存放32bits的数据)
%rsi:参数寄存器 第二个参数
%esi:参数寄存器 第二个参数(存放32bits的数据)
%rax:返回值寄存器
%eax:返回值寄存器(存放32bits数据)
(%eax是寄存器的低32位,%rax是寄存器的整个64位;%rdi和%edi同理 )
栈帧的大小:(%rbp) - (%rsp)
数据单位
x86架构:
数据总线:16bits
地址总线:20bits
word:16bits
long word:32bits(l)
quadra word:64bits(q)
//q、l(如:pushq里的这个q)都是数据的单位
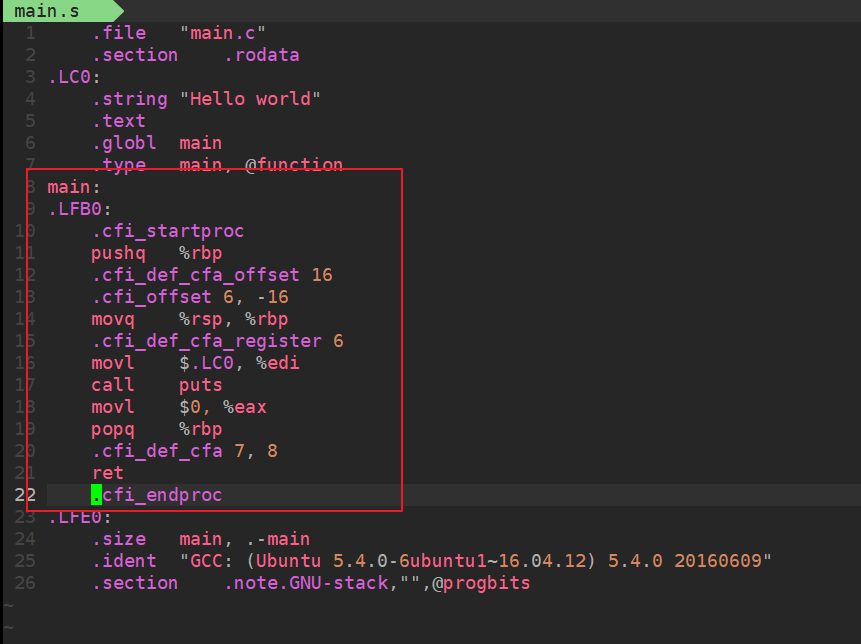
main:
.LFB0:
.cfi_startproc
pushq %rbp // 将上一个函数的基址地址入栈(保存上一函数的基址地址)
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
// 以上,push和mov操作,是函数调用的准备工作
.cfi_def_cfa_register 6
movl $.LC0, %edi // 将"Hello world"字符串字面值的地址保存到edi(参数寄存器)里面去
call puts // 编译器优化,调用puts函数,没有调用printf函数
movl $0, %eax // main函数的返回值是int型(32bits),返回0,存放到返回值寄存器中
// 到此处,函数功能执行完毕
popq %rbp
.cfi_def_cfa 7, 8
ret
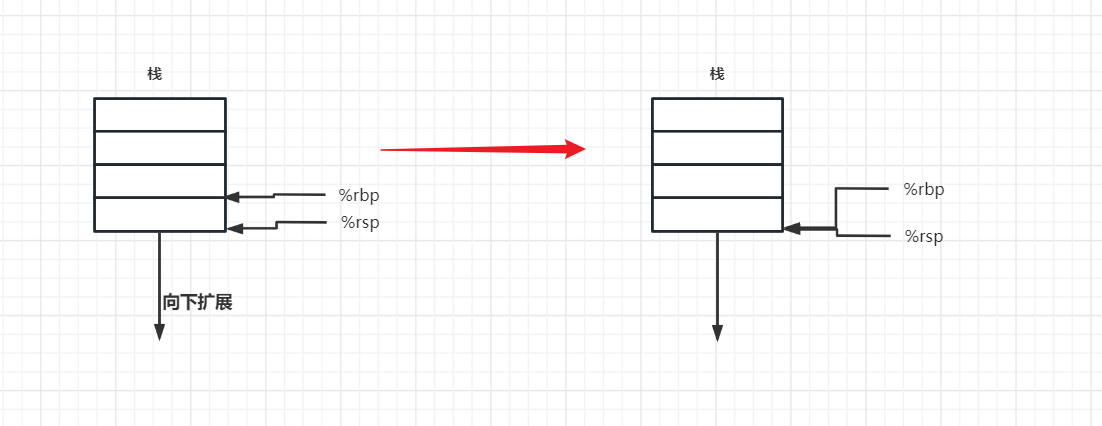
movq %rsp, %rbp // 解释如下图
#include <stdio.h>
void foo(int arr[], int a) {
int tmp = arr[0];
arr[0] = a;
a = tmp;
}
int main()
{
int j = 10;
int arr[] = {1,2,3,4,5};
arr[2] = 20;
int *p = arr + 3;
*p = 40;
int sum = 0;
for(int i = 0;i < 5;i++)
{
sum += arr[i];
}
foo(arr,j);
return 0;
}
注意:对寄存器的操作,加括号就相当于是解引用,是对寄存器里存放地址所指向的内存空间里的内容进行操作。没有加括号相当于直接对寄存器里的内容进行操作
.type foo, @function
foo:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movl %esi, -28(%rbp)
movq -24(%rbp), %rax
movl (%rax), %eax
movl %eax, -4(%rbp)
movq -24(%rbp), %rax
movl -28(%rbp), %edx
movl %edx, (%rax)
movl -4(%rbp), %eax
movl %eax, -28(%rbp)
nop
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size foo, .-foo
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $64, %rsp // 把%rsp里面的值减去 64 再赋值给%rsp,%rsp -= 64;确定栈帧的大小
// 为何以下两行不可以用一个mov完成?
// 答:现在的架构无法满足直接从一块内存向另一块内存传输数据,必须经过寄存器
movq %fs:40, %rax // %fs:40是内存中的一片空间(只读区域,不可写),段+偏移量
movq %rax, -8(%rbp) // 存放金丝雀值
xorl %eax, %eax // 用异或的方式将返回值寄存器中的内容清零(很常用的清零操作)
// 接下来 7 行都是赋值操作
movl $10, -44(%rbp) // 将基址地址 -44 字节的内存赋值为 10(int j = 10)
movl $1, -32(%rbp)
movl $2, -28(%rbp)
movl $3, -24(%rbp)
movl $4, -20(%rbp)
movl $5, -16(%rbp)
movl $20, -24(%rbp)
// 50-52行:int *p = arr + 3;
leaq -32(%rbp), %rax // 加载有效地址,-32(%rbp)是arr的地址(数组首地址),将该地址存放到%rax寄存器中
addq $12, %rax // %rax里面的值减去12再赋值给%rax
movq %rax, -40(%rbp) // 将%rax 里面的值(地址)保存到 %rbp 减40的位置
movq -40(%rbp), %rax
movl $40, (%rax) // 把40存放到%rax所指向的内存空间 即:*p = 40;
// 56-57行:int sum = 0、int i = 0
movl $0, -52(%rbp)
movl $0, -48(%rbp)
jmp .L3 // 函数内进行跳转,直接执行66行的指令(无条件跳转)
.L4:
movl -48(%rbp), %eax // 将i的值放到%eax中
cltq // 将%eax的内存扩充到64位,并将前32位清零
// -32(%rbp,%rax,4) <=> %rbp - 32 + 4 * %rax <=> arr[i];%rbp - 32即是arr(数组首地址),%rax指向的地址存放的是i的值
movl -32(%rbp,%rax,4), %eax // 将arr[i]的值赋值%eax
addl %eax, -52(%rbp) // <=> sum += arr[i]
addl $1, -48(%rbp) // <=> i++
.L3:
cmpl $4, -48(%rbp) // 比较大小指令,将4 和 i的值进行比较
jle .L4 // jle(jump less equal),有条件跳转(≤),如果满足≤4,则跳转到.L4
// 下面开始调用foo函数
movl -44(%rbp), %edx // 将j的值存放到%edx寄存器中
leaq -32(%rbp), %rax // 加载有效地址,将数组首地址加载到%rax寄存器中
movl %edx, %esi // 将%edx中的值存放到%esi寄存器(第二个参数寄存器)
movq %rax, %rdi // 将%rax中的值存放到%rsi寄存器(第二个参数寄存器)
call foo // 调用foo宏函数
movl $0, %eax // 将0存放到%eax寄存器(返回值寄存器)
movq -8(%rbp), %rcx // 把%rbp到%rbp - 8这片内存空间的值存放到%rcx这个寄存器中
// 将内存中的金丝雀值(39行)与%rcx中的值进行异或运算,来判断是否出现数组越界(如果为0说明没有变动,则未越界;否则越界)
xorq %fs:40, %rcx
je .L6 // 判断是否等于 0 ,是的话,jump到.L6,否则调用“栈检查失败”即栈溢出
call __stack_chk_fail
.L6:
leave // 做一些清理操作
.cfi_def_cfa 7, 8
ret // 函数返回
.cfi_endproc
.LFE1:
.size main, .-main
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits
再次理解 pushq %rbp :
push是入栈操作,q代表大小(64位),此时%rbp存放的还是上一个函数栈帧的基址地址,将%rbp里面的内容入栈即保存了上一函数栈帧的基址地址,如图:
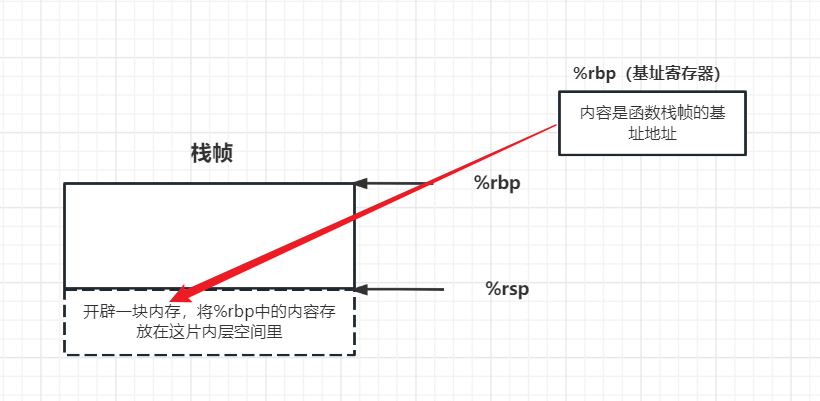
随后,还需要将栈顶指针移动到相应位置,实际上此操作是包括了两个步骤的,这两个步骤是不能被中断的,如图:
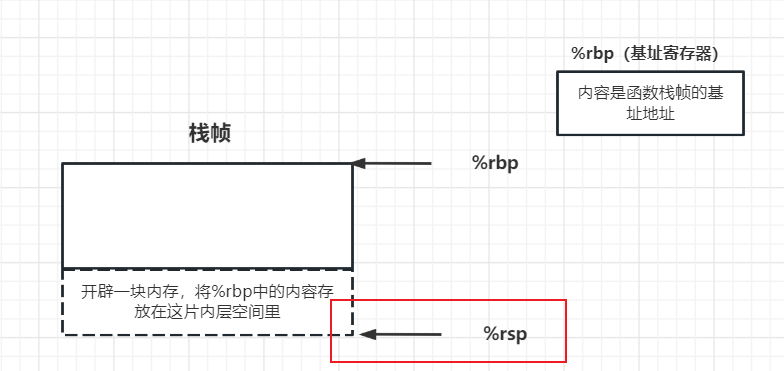
总之,push操作包含了两个步骤:
1、将基址寄存器里的值(上一函数栈帧的基址地址)入栈
2、将栈帧的栈顶指针移动到相应位置
小结
- C语言中的变量名对应汇编中的地址
- C语言中的类型对应汇编中的长度
- 函数调用都有自己独立的栈帧,并且参数都是值传递
- 循环是通过跳转实现的
汇编(-c)
作用:将汇编代码转换成目标平台的机器代码
gcc -c main.c -o main.o
链接
作用:为每一个符号(全局变量、函数名)找到对应的定义
gcc main.o -o main
总结
预处理:-E 得到 *.i 文件
编译:-S 得到 *.s 文件
汇编:-c 注意是小写c 得到 *.o 文件
链接:无
定义宏:-D
显示所有警告:-Wall
gcc main.c -o main -Wall

