NIO与内存映射文件
Java类库中的NIO包相对于IO包来说有一个新功能就是 【内存映射文件】,在业务层面的日常开发过程中并不是经常会使用,但是一旦在处理大文件时是比较理想的提高效率的手段,之前已经在基于API和开发实战角度介绍了相关的大文件读取以及NIO操作的实现,而本文主要想结合操作系统(OS)底层中相关方面的内容进行分析原理,夯实大家对IO模型及操作系统相关的底层知识体系。
下图就是Java应用程序以及操作系统OS内核的调用关系图:
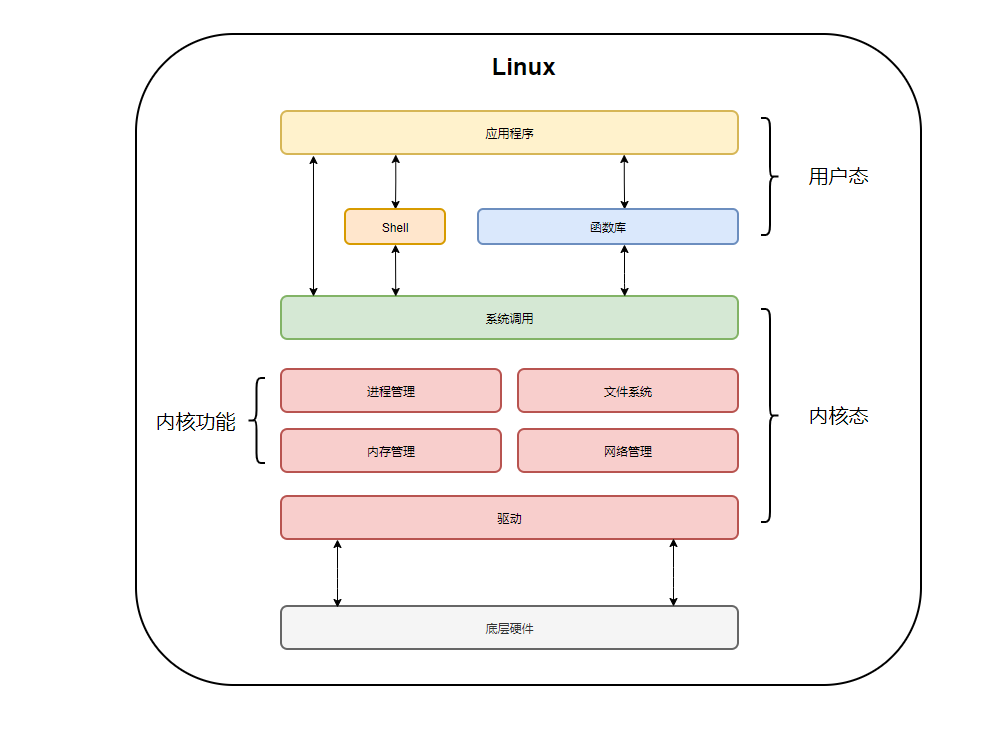
我们会针对于操作系统与应用程序之间建立的关系去分析IO处理底层机制。
传统的IO技术
在传统的文件IO操作中, 我们都是调用操作系统提供的底层标准IO系统调用函数read()、write() , 此时调用此函数的进程(Java进程) 由当前的用户态切换到内核态, 然后OS的内核代码负责将相应的文件数据读取到内核的IO缓冲区,然后再把数据从内核IO缓冲区拷贝到进程的私有地址空间中去,这样便完成了一次IO操作,如下图所示。
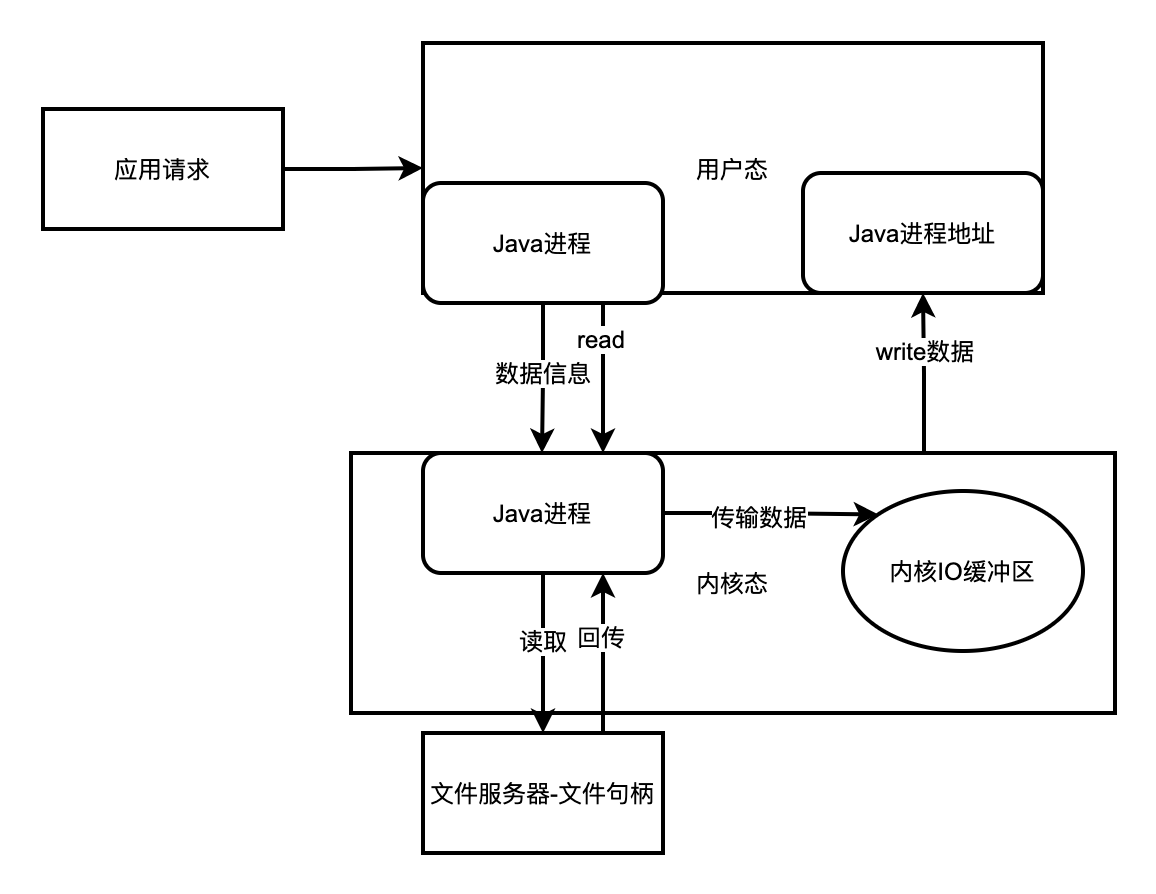
程序的局部性原理
为什么需要内核IO缓冲区
至于为什么要多此一举搞一个内核IO缓冲区把原本只需一次拷贝数据的事情搞成需要2次数据拷贝呢?
IO拷贝的预先局部拷贝
为了减少磁盘的IO操作,为了提高性能而考虑的,因为我们的程序访问一般都带有局部性,也就是所谓的局部性原理,在这里主要是指的空间局部性,即我们访问了文件的某一段数据,那么接下去很可能还会访问接下去的一段数据,由于磁盘IO操作的速度比直接访问内存慢了好几个数量级,所以OS根据局部性原理会在一次read(系统调用过程中预读更多的文件数据缓存在内核IO缓冲区中, 当继续访问的文件数据在缓冲区中时便直接拷贝数据到进程私有空间, 避免了再次的低效率磁盘IO操作。
应用程序IO操作实例
在Java中当我们采用IO包下的文件操作流,如:
FileInputStream in=new FileInputStream("/usr/text") ;
in.read();
JAVA虚拟机内部便会调用OS底层的read()系统调用完成操作, 在第二次调用read()的时候很可能就是从内核缓冲区直接返回数据了,此外还有可能需要经过native堆做一次中转,因为这些函数都被声明为native, 即本地方法, 所以可能在C语言中有做一次中转, 如win32/win64中就是通过C语言从OS读取数据, 然后再传给JVM内存 。
系统调用与应用程序
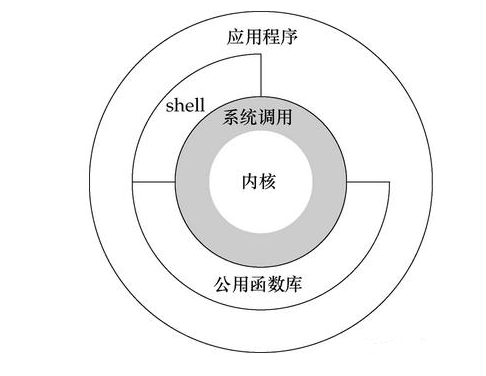
既然如此, Java-IO包中为啥还要提供一个BufferedInputStream类来作为缓冲区呢,关键在于四个字, "系统调用",当读取OS内核缓冲区数据的时候, 便发起了一次系统调用操作(通过native的C函数调用),而系统调用的代价相对来说是比较高的,涉及到进程用户态和内核态的上下文切换等一系列操作,所以我们经常采用如下的包装:
File ln put Stream in=new FileInputStream("/user/txt") ;
BufferedInputStream buf in=new BufferedInputStream(in) ;
buf in.read();
通过Buffer减少系统调用次数(经常被理解错误)
- 有了Buffer缓存,我们每一次in.read() 时候, BufferedInputStream会根据情况自动为我们预读更多的字节数据到它自己维护的一个内部字节数组缓冲区中,这样我们便可以减少系统调用次数, 从而达到其缓冲区的目的。

- 所以要明确的一点是BufferedInputStream的作用不是减少磁盘IO操作次数,因为操作系统OS已经帮我们完成了,而是通过减少系统调用次数来提高性能的。
- 同理BufferedOuputStream, BufferedReader/Writer也是一样的。在C语言的函数库中也有类似的实现, 如,fread()是C语言中的缓冲IO, 与BufferedInputStream()相同.
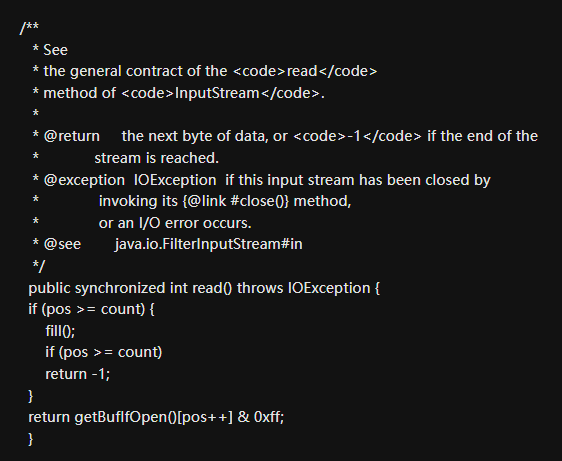
BufferedInputStream分析
从上面的源码我们可以看到,BufferedInputStream内部维护着一个字节数组byte[] buf来实现缓冲区的功能,调用的buf的in.read()方法在返回数据之前有做一个if判断, 如果buf数组的当前索引不在有效的索引范围之内, 即if条件成立, buf字段维护的缓冲区已经不够了, 这时候会调用内部的fill()方法进行填充, 而fill()会预读更多的数据到buf数组缓冲区中去, 然后再返回当前字节数据, 如果if条件不成立便直接从buf缓冲区数组返回数据了。
BufferedInputStream的buff的可见性
对于read方法中的getBufIfOpen()返回的就是buf字段的引用,源码中的buf字段声明为
protected volatile byte buf;主要是为了通过volatile关键字保证buf数组在多线程并发环
境中的内存可见性.
内存映射文件的实现
内存映射文件和之前说的标准IO操作最大的不同之处就在于它虽然最终也是要从磁盘读取数据,但是它并不需要将数据读取到OS内核缓冲区,而是直接将进程的用户私有地址空间中的一部分区域与文件对象建立起映射关系,就好像直接从内存中读、写文件一样,速度当然快了,如下图所示。
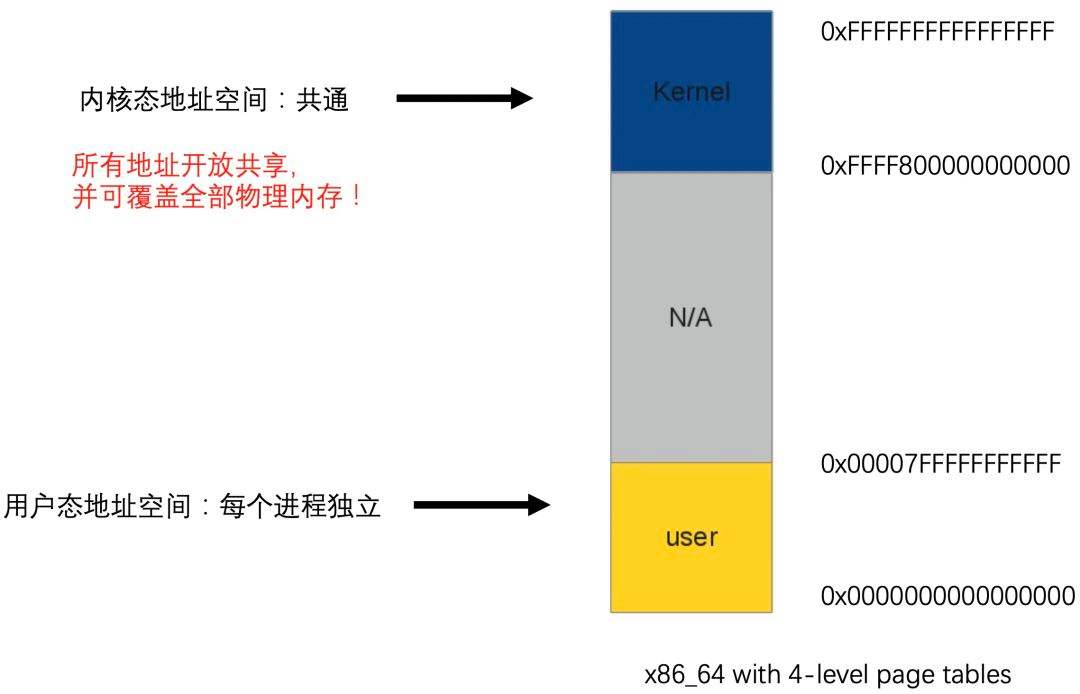
Linux中的进程虚拟存储器, 即进程的虚拟地址空间, 如果你的机子是32位,那么就有2^32=4G的虚拟地址空间,我们可以看到图中有一块区域:
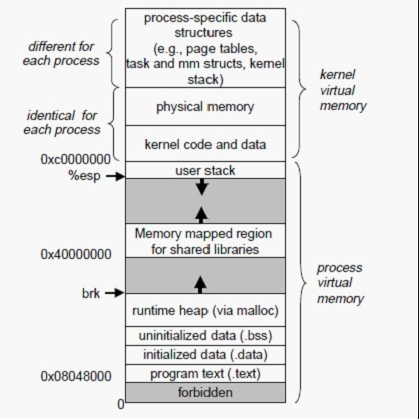
“Memory mapped region for shared libraries”
这段区域就是在内存映射文件的时候将某一段的虚拟地址和文件对象的某一部分建立起映射关系,此时并没有拷贝数据到内存中去,而是当进程代码第一次引用这段代码内的虚拟地址时,触发了缺页异常,这时候OS根据映射关系直接将文件的相关部分数据拷贝到进程的用户私有空间中去,当有操作第N页数据的时候重复这样的OS页面调度程序操作。
内存映射文件的优点
内存映射文件的效率比标准IO高的重要原因就是因为少了把数据拷贝到OS内核缓冲区这一步(可能还少了native堆中转这一步) 。
Java中提供了3种内存映射模式:只读(readonly) 、读写(read_write) 、专用(private) 。
只读(readonly) 模式
对于只读模式来说,如果程序试图进行写操作,则会抛出Readonly Buffer Exception异常。
read_write模式
NIO的read_write模式
read_write读写模式表明了通过内存映射文件的方式写或修改文件内容的话是会立刻反映到磁盘文件中去的,别的进程如果共享了同一个映射文件,那么也会立即看到变化!
标准IO的read_write模式
标准IO那样每个进程有各自的内核缓冲区, 比如Java代码中, 没有执行IO输出流的flush()或者close()操作, 那么对文件的修改不会更新到磁盘去, 除非进程运行结束。
专用模式
专用模式采用的是OS的“写时拷贝”原则,即在没有发生写操作的情况下,多个进程之间都是共享文件的同一块物理内存(进程各自的虚拟地址指向同一片物理地址),一旦某个进程进行写操作,那么将会把受影响的文件数据单独拷贝一份到进程的私有缓冲区中,不会反映到物理文件中去。
File file=new File("/usr/txt") ;
FileInputStream in=new FileInputStream(file) ;
File Channel channel=in.getChannel();
MappedByteBuffer buff=channel.map(File Channel.Map Mode.READ_ONLY, 0, channel.size 0) ;
这里创建了一个只读模式的内存映射文件区域, 接下来我就来测试下与普通NIO中的通道操作相比性能上的优势,先看如下代码:
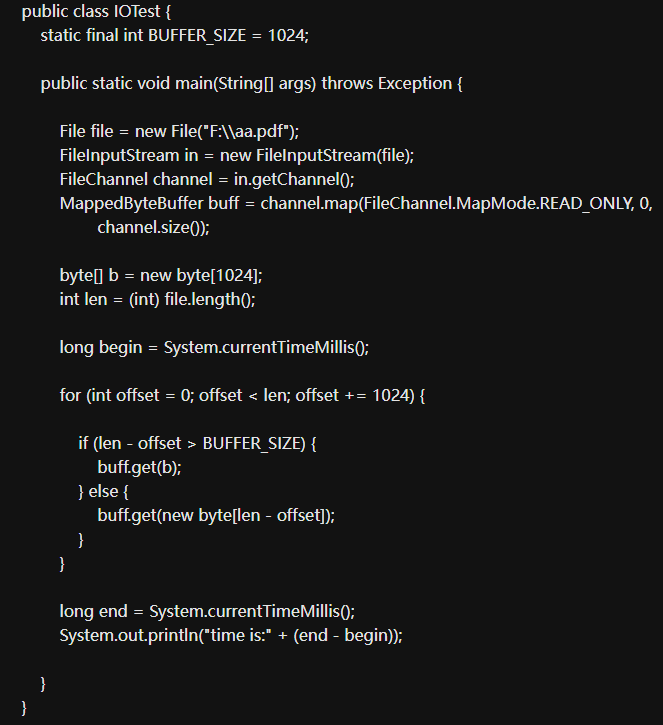
输出为63,即通过内存映射文件的方式读取86M多的文件只需要78毫秒,我现在改为普通
NIO的通道操作看下:
File file=new File("/usr/txt") ;
FileInputStream in=new FileInputStream(file) ;
File Channel channel=in.getChannel();
ByteBuffer buff=ByteBuffer.allocate(1024) ;
long begin=System.currentTimeMillis();
while(channel.read(buff) !=-1) {
buff.flip 0;
buff.clear 0;
long end=System.currentTimeMillis();
System.out.print In("time is:"+(end-begin) ) ;
输出为468毫秒,几乎是6倍的差距,文件越大,差距便越大。
内存映射的使用场景
内存映射特别适合于对大文件的操作, JAVA中的限制是最大不得超过Integer.MAXVALUE, 即2G左右, 不过我们可以通过分次映射文件(channel.map) 的不同部分来达到操作整个文件的目的。
内存映射的优势特点
内存映射属于JVM中的直接缓冲区, 还可以通过ByteBuffer.allocateDirect, 即Direct Memory的方式来创建直接缓冲区。
相比基础的IO操作来说就是少了中间缓冲区的数据拷贝开销,同时他们属于JVM堆外内存, 不受JVM堆内存大小的限制。
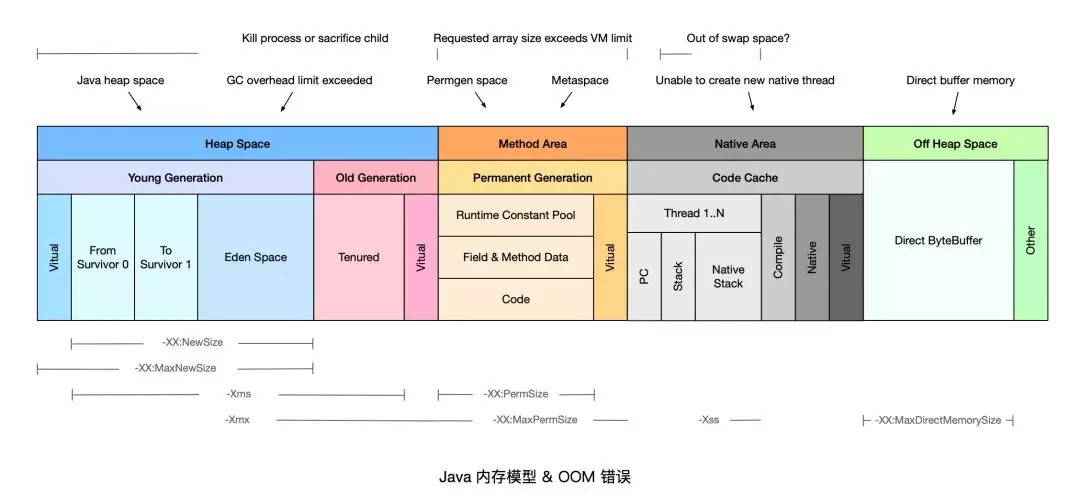
其中Direct Memory默认的大小是等同于JVM最大堆, 理论上说受限于进程的虚拟地址空间大小, 比如32位的windows上, 每个进程有4G的虚拟空间除去2G为OS内核保留外, 再减去JVM堆的最大值, 剩余的才是Direct Memory大小。
通过设置JVM参数-Xmx64M, 即JVM最大堆为64M, 然后执行以下程序可以证明Direct Memory不受JVM堆大小控制:
public static void main(String args) {
ByteBuffer.allocateDirect(1024*1024*100) ; //100MB
}
输出结果如下:
[GC1371K->1328K(61312K) , 0.0070033secs][Full GC1328K->1297K(61312K),0.0329592secs]
[GC3029K->2481K(61312K) , 0.0037401secs][Full GC2481K->2435K(61312K) , 0.0102255secs]
看到这里执行GC的次数较少, 但是触发了两次Full GC, 原因在于直接内存不受GC(新生代的Minor GC) 影响, 只有当执行老年代的Full GC时候才会顺便回收直接内存!而直接内存是通过存储在JVM堆中的Direct ByteBuffer对象来引用的, 所以当众多的Direct ByteBuffer对象从新生代被送入老年代后才触发了full gc。再看直接在JVM堆上分配内存区域的情况:
public static void main(String~args) {
for(inti=0; i<10000; i++) {
ByteBuffer.allocate(1024*100) ; //100K
}
}
ByteBuffer.allocate意味着直接在JVM堆上分配内存, 所以受新生代的Minor GC影响, 输出如下:
[GC16023K->224K(61312K) , 0.0012432secs][GC16211K->192K(77376K) , 0.0006917secs][GC32242K->176K(77376K) , 0.0010613secs][GC32225K->224K(109504K) , 0.0005539secs][GC64423K->192K(109504K) , 0.0006151secs][GC64376K->192K(171392K, 0.0004968secs][GC128646K->204K(171392K) , 0.0007423secs][GC128646K->204K(299968K) , 0.0002067secs][GC257190K->204K(299968K) , 0.0003862secs][GC257193K->204K(287680K) , 0.0001718secs][GC245103K->204K(276480K) , 0.0001994secs][GC233662K->204K(265344K) , 0.0001828secs][GC222782K->172K(255232K) , 0.0001998secs][GC212374K->172K(245120K) , 0.0002217secs]
可以看到, 由于直接在JVM堆上分配内存, 所以触发了多次GC, 且不会触及Full GC, 因为对象根本没机会进入老年代。
Direct Memory和内存映射
NIO中的Direct Memory和内存文件映射同属于直接缓冲区, 但是前者和-Xmx和-XX:MaxDirectMemorySize有关, 而后者完全没有JVM参数可以影响和控制,这让我不禁怀疑两者的直接缓冲区是否相同。
Direct Memory
Direct Memory指的是JAVA进程中的native堆, 即涉及底层平台如win 32的dII部分, 因为C语言中的malloc) 分配的内存就属于native堆, 不属于JVM堆,这也是Direct Memory能在一些场景中显著提高性能的原因, 因为它避免了在native堆和jvm堆之间数据的来回复制;
内存映射
内存映射则是没有经过native堆, 是由JAVA进程直接建立起某一段虚拟地址空间和文件对象的关联映射关系, 参见Linux虚拟存储器图中的“Memory mapped region for shared libraries”区域, 所以内存映射文件的区域并不在JVM GC的回收范围内, 因为它本身就不属于堆区, 卸载这部分区域只能通过系统调用unmap()来实现(Linux)中, 而JAVA API只提供了FileChannel.map的形式创建内存映射区域, 却没有提供对应的unmap(), 让人十分费解, 导致要卸载这部分区域比较麻烦。
Direct Memory和内存映射结合所实现的案例
通过Direct Memory来操作前面内存映射和基本通道操作的例子, 来看看直接内存操作的话,程序的性能如何:
File file=new File("/usr/txt") ;
FileInputStream in=new FilelnputStream(file) ;
FileChannel channel=in.getChannel 0;
ByteBuffer buff=ByteBuffer.allocateDirect(1024) ;
long begin=System.currentTimeMillis(;
while(channel.read(buff) !=-1) {
buff.flip();
buff.clear();
long end=System.currentTimeMillis();
System.out.printIn("time is:"+(end-begin) );
}
程序输出为312毫秒, 看来比普通的NIO通道操作(468毫秒) 来的快, 但是比mmap内存映射的63秒差距太多了, 通过修改; ByteBuffer buff=ByteBuffer.allocateDirect(1024) ;
ByteBuffer buff=ByteBuffer.allocateDirect((in) file.length 0) , 即一次性分配整个文件长度大小的堆外内存,最终输出为78毫秒,由此可以得出堆外内存的分配耗时比较大,还是比mmap内存映射来得慢。
Direct Memory的内存回收(非常重要总结)
最后一点为Direct Memory的内存只有在JVM执行full gc的时候才会被回收, 那么如果在其上分配过大的内存空间, 那么也将出现OOM, 即便JVM堆中的很多内存处于空闲状态。
JVM堆内存的限制范围
关于JVM堆大小的设置是不受限于物理内存, 而是受限于虚拟内存空间大小,理论上来说是进程的虚拟地址空间大小,但是实际上我们的虚拟内存空间是有限制的, 一般windows上默认在C盘, 大小为物理内存的2倍左右。
标签:文件,JVM,映射,内存,IO,缓冲区,NIO From: https://www.cnblogs.com/liboware/p/16972966.html