目录
一、同步与异步
同步与异步:用来描述任务的提交方式
1.同步:提交完任务之后原地等待任务的返回结果,期间不做任何事
一个任务调起另一个任务的时候,会去等待其任务返回结果(或执行结束),然后再继续执行。
如下两图都是同步操作:
在Task A调用Task B后,Task A会等待Task B执行结束后,再继续执行。

2.异步:提交完任务之后不原地等待,直接去做其他事情,结果通过反馈机制获得,有结果自动通知
一个任务调起另一个任务的时候,不会去等待其返回结果(或执行结束),仍然继续执行自己的逻辑。
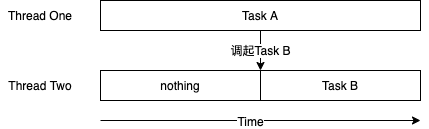
如下图,在Task A调用Task B后,Task A不会停止执行,Task A与Task B并行执行。
二、阻塞非阻塞
用来表达任务的执行状态
1.阻塞:任务处于阻塞态
是指调用结果返回之前,当前线程(进程)会被挂起。
在调用的结果返回之前,当前线程(进程)不会执行其他操作。
2.非阻塞:任务处于就绪态、运行态
指执行一个调用,当前线程(进程)不会挂起。
当前线程(进程)如果还有其他操作,不会影响执行。
我们常常看到的是同步与异步、阻塞非阻塞,四者的组合
三、综合使用
1.同步阻塞
效率最低,单任务按顺序执行
2.同步非阻塞
多任务,定时查看任务执行状态
3.异步阻塞
单任务,自动提交任务执行状态。
4.异步非阻塞
效率最高,提交完任务之后不原地等待,直接去做其他事情,并且cpu也不会被剥夺走。多任务,自动提交任务执行状态,合理分配,最大化利用资源。
TASK A在执行过程中调起了Task B,与Task B并行执行,因此是异步。
Task A调起Task B后,并没有挂起当前线程,因此是非阻塞。
四、创建进程的多种方式
1.方式1:鼠标双击创建进程
系统中,鼠标双击软件图标,创建进程
2.方式2:代码创建进程
python代码创建进程,使用multiprocessing模块中的类Process来创建进程
(1)生成类Process的对象创建进程
为子进程传参需要用类Process中的arg位置传参或者kwargs关键值传参,如args=('jason',18)中,参数需要在元组中赋值给args
# 创建进程模块multiprocessing
from multiprocessing import Process
import time
def task(name,age):
print('task is running',name)
time.sleep(3)
print('task is over',age)
if __name__ == '__main__':
"让一个函数在同一时间执行多次"
p1 = Process(target=task,args=('jason',18))
p1.start() # 异步操作:子进程 告诉操作系统创建一个新的进程,并在该进程中执行task函数
# task() # 同步操作
print('主进程')
==========运行结果===============
主进程
task is running jason
# 3s后
task is over 18
(2)编写类继承Process,来创建子进程
1.使用类继承Process类,来创建子进程
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
print('run is running')
time.sleep(3)
print('run is over')
if __name__ == '__main__':
obj = MyProcess()
obj.start()
print('主进程')
==========运行结果===============
主进程
run is running
run is over
2.传参问题:利用__init__实例化方法和super派生方法传参
由于Process中已经存在名为name的属性了,当仍然想用属性name的时候,需要在super方法后赋值
class MyProcess(Process):
def __init__(self,name,age):
super().__init__()
self.name = name
self.age = age
def run(self,):
print('run is running',self.name)
time.sleep(3)
print('run is over',self.age)
if __name__ == '__main__':
obj = MyProcess('jason',18)
obj.start()
print('主进程')
3.在不同的操作系统中创建进程的注意事项
由于在不同的操作系统中创建进程的底层原理不同:
在 windows 系统中,是以导入模块的形式创建进程,所以创建子进程会循环创建,直到报错。
在linux/mac 系统中, 是以拷贝代码的形式创建子进程。

总之使用 if __name__ == '__main__':语句来创建子进程更为合适
4.进程的join方法
join方法的作用:让主进程代码等待子进程代码运行结束再执行
from multiprocessing import Process
import time
def task(name, n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p = Process(target=task, args=('jason', 1)) # 拿类产生一个对象
p.start() # 异步
"""主进程代码等待子进程代码运行结束再执行"""
p.join()
拓展:join方法位置不同,运行时间不同
from multiprocessing import Process
import time
def task(name, n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('jason', 1)) # 拿类产生一个对象
p2 = Process(target=task, args=('jason', 2))
p3 = Process(target=task, args=('jason', 3))
"""主进程代码等待子进程代码运行结束再执行"""
print('主进程')
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
print(time.time()-start_time)
==========运行结果===============
3.058879852294922
当进程同时执行,然后在用join方法等待时,时间是3s
"join方法位置不同,运行时间不同"
start_time = time.time()
p1.start() # 对象产生进程
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
print(time.time() - start_time)
==========运行结果===============
6.190535068511963
改变join方法的位置,则结果变成6s
五、进程间数据隔离
同一台计算机上的多个进程数据上严格意义上的物理隔离(默认情况下),也就是说默认情况下进程之间无法互相传递信息
import time
from multiprocessing import Process
name = 1000
def task():
global name
name = 'duoduo'
print('子进程', name)
if __name__ == '__main__':
p1 = Process(target=task)
p1.start() # 通过对象创建子进程
time.sleep(3) # 使主进程代码等待三秒
print(name) # 主进程代码打印变量名name
=======代码运行=========
子进程 duoduo
1000
结果发现子进程运行,并不能改变主进程的变量名的值
六、ipc机制
ipc:一台计算机上的进程间通行
消息队列:存储数据的地方,公共仓库,所有人都可以存,都可以取
"当台计算机上的消息队列"
from multiprocessing import Queue
q = Queue(3) # 括号内可以指定存储数据的个数
# 往消息队列中存放消息
q.put(1)
print(q.full()) # 判断队列是否已满返回布尔值
q.put(2)
q.put(3)
print(q.full())
# q.put(4) # 程序等在这里了
print(q.get())
print(q.get())
print(q.empty()) # False 判断队列是否为空
print(q.get())
# print(q.get()) # 程序等在这里了长期进入io状态
print(q.get_nowait()) # 直接报错_queue.Empty
full() ``empty() 在多进程中都不能使用,因为判断会失真,当某一个去判断的时候,立即有别的进程存取消息队列的数据,会改变消息队列的数据,此时的判断并不准确就会失真

七、生产者消费者模型
主要爬虫领域
生产者:负责产生数据的人
消费者:负责处理数据的人
该模型必须在生产者和消费者之间必须要有消息队列(能存储数据的地方也可以是文件,数据库),减少了生产者和消费者的耦合
八、进程对象的多种方法
1.如何查看进程号
from multiprocessing import Process, current_process
import os
def task():
# print(current_process())
# print(current_process().pid) # .pid获取当前进程的进程号
print('子', os.getpid())
print('子进程的主进程号', os.getppid())
if __name__ == '__main__':
p1 = Process(target=task)
p1.start()
# print(current_process())
# print(current_process().pid)
print('主', os.getpid()) # os.getpid()获取当前进程的进程号
2.终止进程
(1)代码实现
p1.terminate()
(2)命令行实现
3.判断进程是否存活
p1.is_alive() 光速看
4.其他
start()
九、守护进程
守护进程会随着守护的进程结束而立刻结束
当子进程是主进程的守护进程时,主进程一旦结束,那么子进程不需要手动结束也会被结束掉
from multiprocessing import Process
import time
def task(name):
print('子进程:%s' % name)
time.sleep(3)
print('子进程结束')
if __name__ == '__main__':
p = Process(target=task, args=('运行',))
p.daemon = True # 声明p对象生成的子进程是主进程的守护进程
p.start()
time.sleep(1)
print('主进程结束')

十、僵尸进程与孤儿进程
1.僵尸进程
进程执行完毕后并不会立刻销毁所有的数据,会有一些信息短暂保留下来
比如一些信息:进程号、进程执行时间、进程消耗功率等会交给父进程查看
所有的进程都会变成僵尸进程的时刻
2.孤儿进程
子进程正常运行,父进程意外死亡:操作系统针对孤儿进程会派遣
福利院管理
十一、多进程数据错乱问题
模拟抢票软件:多进程操作数据很有可能会造成数据错乱>>>:互斥锁
互斥锁:将并发变成串行,牺牲了效率但是保障了数据的安全
模拟抢票软件
from multiprocessing import Process
import time
import json
import random
# 查票
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
print('%s在查票 当前余票为:%s' % (name, data.get('ticket_num')))
# 买票
def buy(name):
# 再次确认票
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1, 3))
# 判断是否有票 有就买
if data.get('ticket_num') > 0:
data['ticket_num'] -= 1
with open(r'data.json', 'w', encoding='utf8') as f:
json.dump(data, f)
print('%s买票成功' % name)
else:
print('%s很倒霉 没有抢到票' % name)
def run(name):
search(name)
buy(name)
if __name__ == '__main__':
for i in range(10):
p = Process(target=run, args=('用户%s'%i, ))
p.start()
此时多进程操作数据很有可能会造成数据错乱
 标签:__,name,Process,创建,print,time,进程
From: https://www.cnblogs.com/DuoDuosg/p/16903873.html
标签:__,name,Process,创建,print,time,进程
From: https://www.cnblogs.com/DuoDuosg/p/16903873.html