MySQL有哪些数据类型?
数值类型
整数
- TINYINT:1字节整数,范围-128到127(无符号0到255)
- SMALLINT:2字节整数,范围-32768到32767(无符号0到65535)
- MEDIUMINT:3字节整数,范围-8388608到8388607(无符号0到16777215)
- INT或INTEGER:4字节整数,范围-2147483648到2147483647(无符号0到4294967295)
- BIGINT:8字节整数,范围-9223372036854775808到9223372036854775807(无符号0到18446744073709551615)
浮点
- FLOAT:单精度浮点数
- DOUBLE:双精度浮点数
FLOAT和DOUBLE有什么区别?
float是单精度浮点数,占用4个字节的存储空间,适用对精度要求不高,节省存储空间的场合。
double是双精度浮点数,占用8个字节的存储空间,适用需要高精度计算的场合。
定点
- DECIMAL或NUMERIC:
使用DECIMAL(M,D)的方式表示高精度小数,M表示总位数,D表示有几位小数。
例如:DECIMAL(10,2)表示有10位数字,2位小数。
浮点数与定点数的区别?
定点数意味着小数点位是固定的,而浮点数会有精度限制,四舍五入时会有相应的误差。 且定点数需要更多的存储空间,更慢的计算效率,浮点数一般用于对精度要求不那么严格的领域,如科学计算、工程领域和地理信息系统(GIS),定点数则更多用于金融、测量统计等。
位
- bit:存储的是二进制值,可指定存储的位数,如果不指定默认为1。
字符串类型
非二进制字符串
- CHAR:固定长度的非二进制字符串
- VARCHAR:可变长度的非二进制字符串
- TINYTEXT:最大长度255的非二进制字符串
- TEXT:最大长度65,535的非二进制字符串
- MEDIUMTEXT:最大长度16,777,215的非二进制字符串
- LONGTEXT:最大长度4,294,967,295的非二进制字符串
- ENUM:枚举类型,可从列表中选择一个值
- SET:集合类型,可从列表中选择多个值
CHAR、VARCHAR和varchar2有什么区别?
char是一种固定长度的类型,无论存储的数据多少都会固定长度,如果插入的长度小于定义长度,则可以用空格进行填充。所以char可能更会浪费空间。
varchar是一种可变长度的类型,当插入的长度小于定义的长度是,插入多上就存多长。
varchar是标准sql中定义的,而varchar2是oracle所提供的独有的数据类型。
二进制字符串
- BINARY:固定长度的二进制字符串
- VARBINARY:可变长度的二进制字符串
- TINYBLOB:最大长度255的二进制字符串
- BLOB:最大长度65,535的二进制字符串
- MEDIUMBLOB:最大长度16,777,215的二进制字符串
- LONGBLOB:最大长度4,294,967,295的二进制字符串
查找二进制的校对规则:
select * from information_schema.collations where collation_name like '%bin';
时间类型
- DATE:日期,格式为YYYY-MM-DD
- TIME:时间,格式为HH:MM:SS
- DATETIME:日期和时间,格式为YYYY-MM-DD HH:MM:SS
- TIMESTAMP:日期和时间,与DATETIME类似,但时间戳范围较小
- YEAR:年份,格式为YYYY或YY
timestamp和datetime的区别?
对于timestamp来说,如果储存时的时区和检索时的时区不一样,那么拿出来的数据也不一样。
对于datetime来说,存什么拿到的就是什么。
如果存进去的是NULL,timestamp会自动储存当前时间,而 datetime会储存 NULL。
什么是最左匹配原则?
在使用复合索引进行查询时,MySQL会首先匹配索引的最左边的列(第一个列),然后依次匹配后续的列。如果最左边的列没有被包含在查询条件中,则MySQL将不会使用该复合索引。
例如:有一个复合索引包含3个字段(A、B、C)
如果只包含了A列,则索引可能被使用。
如果包含了A、B列,则索引可以较为高效的使用。
如果包含了A、B、C列,则索引可以完全使用。
如果只包含了B、C或A、C列,则不符合最左匹配原则,索引失效。
注意事项:
列顺序:应该注意把使用频率更高的字段放在最前面。
覆盖:如果符合索引完全覆盖了查询所需的列/字段,则查询效率会得到提升。
SQL语法:
常见的聚合索引
- sum(列名) 求和
- max(列名) 最大值
- min(列名) 最小值
- avg(列名) 平均值
- first(列名) 第一条记录
- last(列名) 最后一条记录
- count(列名) 统计记录数
UNION和UNION ALL有什么区别?
UNION操作符用于合并两个或多个SELECT语句的结果集,并且会默认去除重复的行,只返回唯一的行。
UNION ALL操作符也用于合并两个或多个SELECT语句的结果集,但它不会去除重复的行,即如果存在重复行,UNION ALL会将它们全部包含在最终的结果集中。
如果你需要一个不包含任何重复行的结果集,并且不介意MySQL为你去除这些重复行,那么使用UNION。
如果你需要包含所有行,包括重复行,并且希望操作更快地执行,那么使用UNION ALL。
drop、truncate 和 delete 的区别?
drop:从数据库中完全删除指定的对象,如表、数据库、索引、视图等。一旦执行DROP操作,被删除的对象将无法恢复,除非有备份。
truncate:快速删除表中的所有数据,但保留表的结构。它的执行速度通常比DELETE快,尤其是对于大型表。
delete:根据指定的条件删除表中的行数据。如果不指定条件,将删除表中的所有行,但表的结构和约束仍然保留。
| 区别 | delete | truncate | drop |
|---|---|---|---|
| SQL类型 | DML | DDL | DDL |
| 支持回滚 | √ | × | × |
| 删除内容 | 表结构还在,删除所有/部分数据 | 表结构还在,删除全部数据 | 删除表结构及数据 |
| 执行速度 | 慢 | 快 | 更快 |
关联查询
内连接(inner join):取出两张表中匹配到的数据,匹配不到的不保留。
外连接(outer join):取出连接表中匹配到的数据,匹配不到的也会保留,其值为NULL。
sql语句的执行顺序是什么?
1、FROM
FROM 子句是查询的起点,它指定要从中检索数据的表或视图。在此阶段,将处理链接、子查询和表引用。本质上此子句是为数据检索设置上下文。
2、JOIN
JOIN 子句是在FROM子句之后,根据相关列合并两个或多个表中的行,它决定了如何匹配不同表中的行。此步骤包括各种类型的连接,如内部连接(inner join)、外部连接(left join、right join)和交叉连接(cross join)。
3、WHERE
WHERE 子句根据指定条件筛选行。它在表联接后但在任何分组或聚合发生之前对行应用条件。此步骤对于将数据集缩小到仅相关行至关重要。
4、GROUP BY
GROUP BY 子句将具有相同值的行分组。这通常与聚合函数(COUNT、SUM、AVG等)一起使用,以对分组数据执行计算。该子句是根据指定的列将数据组织到群组中。
5、HAVING
HAVING 子句与 WHERE 子句类似,根据指定的条件过滤组。但它是在分组完成后应用的。该子句可用于过滤聚合后不符合某些条件的组。
6、SELECT
SELECT 子句指定要包含在结果集中的列或表达式。您可以在此处定义查询的输出,包括任何计算、表达式和别名。该子句确定将从查询中返回哪些数据。
7、DISTINCT
DISTINCT 关键字从结果集中删除重复的行。它在子句之后应用,以确保输出仅包含唯一行。
8、ORDER BY
ORDER BY 子句根据一个或多个列对结果集进行排序。应用此语句,可以将结果集按所需顺序显示。还可以根据需要指定升序或降序排序来组织数据。ORDER BY SumOrderAmount DESC。
9、LIMIT 或 TOP
LIMIT(MySQL)或 TOP(SQL Server)子句限制了查询返回的行数,并选择性地跳过指定的行数。
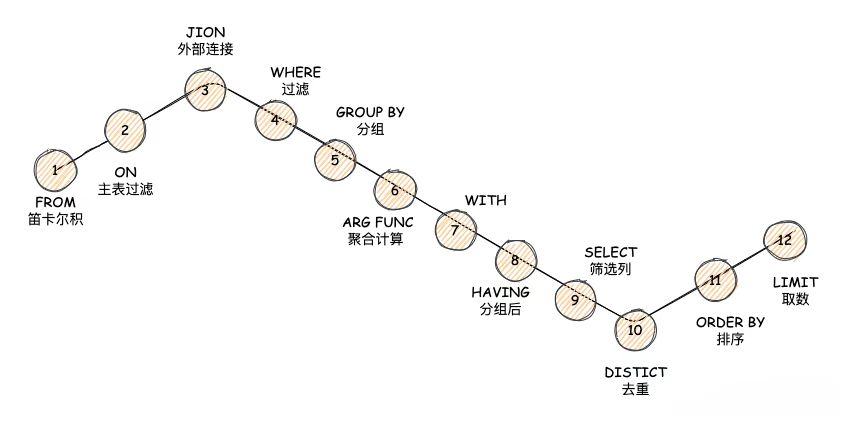
sql语句的执行过程
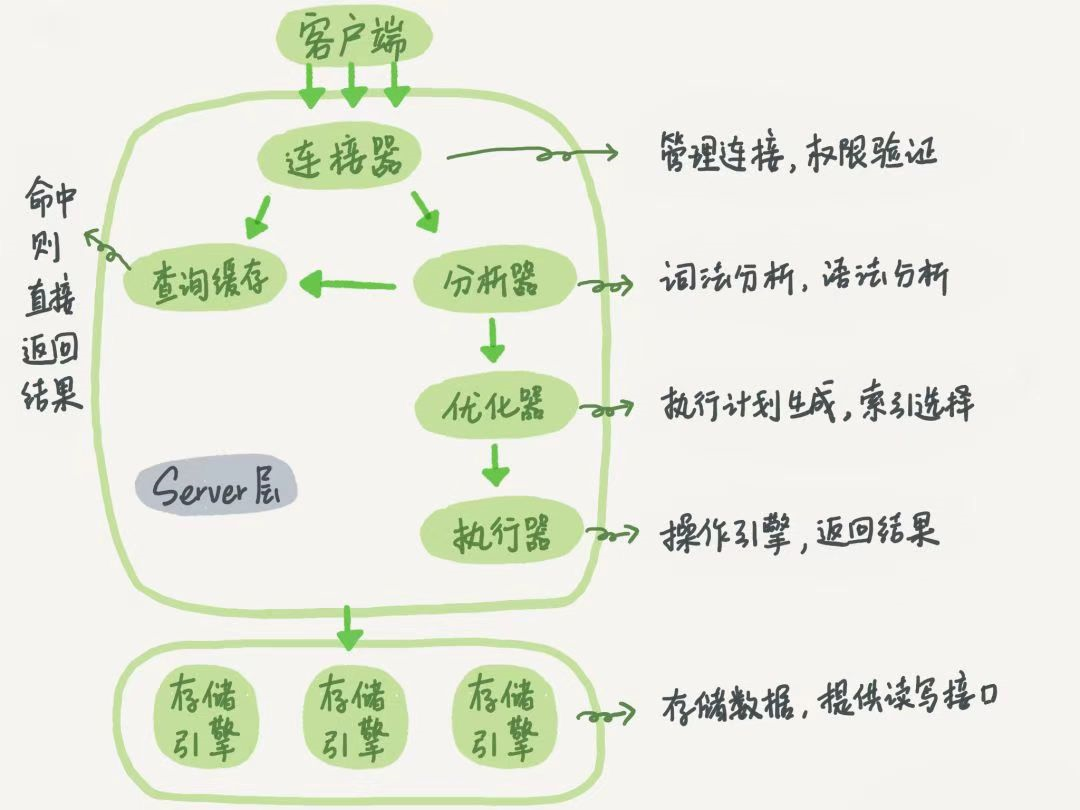
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5版本开始成为了默认存储引擎。
1.连接器,这里负责跟客户端建立连接、获取权限、维持和管理连接,这里需要我们输入在命令行输入mysql -u root -p 输入密码或使用navicat等客户端登录。
2.查询缓存,在这里,mysql拿到查询语句,会先去缓存里找,如果之前执行过相同的语句,那么这里就可以直接从缓存中取出结果返回,如果不在缓存中就继续向下执行。
3.分析器,这里对sql语句进行解析,根据关键字识别是什么样的sql,然后判断这条sql是否有语法错误,如果有则会报错:You have an error in your SQL syntax。
4.优化器,这里要对执行效率进行优化,从几种方案中选出效率最高的一种。
5.执行器,这里开始执行sql语句,执行之前会先判断有没有对应权限,没有的话会报错,如果有权限,优化器就会根据表的引擎定义,去使用这个引擎提供的接口。
Mysql中having和where的区别
- having是在分组后对数据进行过滤
- where是在分组前对数据进行过滤
- having后面可以使用聚合函数
- where后面不可以使用聚合函数
- 如果mysql创建函数报错1418 有可能是开起来binlog日志
SET GLOBAL log_bin_trust_function_creators = 1;