为什么要有 Buffer Pool?
虽然说 MySQL 的数据是存储在磁盘里的,但是也不能每次都从磁盘里面读取数据,这样性能是极差的。
要想提升查询性能,那就加个缓存。所以,当数据从磁盘中取出后,缓存内存中,下次查询同样的数据的时候,直接从内存中读取。
为此,Innodb 存储引擎设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能。
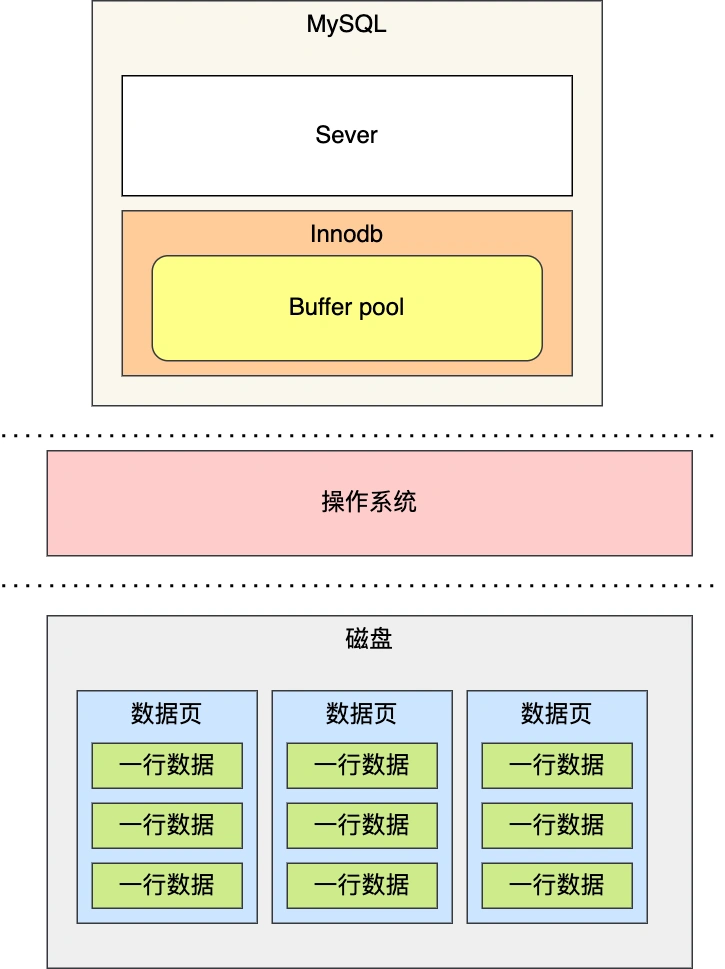
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
Buffer Pool里有什么
InnoDB 会把存储的数据划分为若干个页,以页作为磁盘和内存交互的基本单位,一个页的默认大小为 16KB。因此,Buffer Pool 同样需要按页来划分。
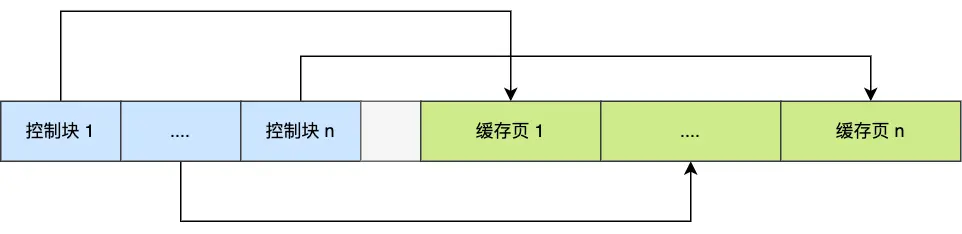
Buffer Pool里面包含很多个缓存页,同时每个缓存页还有一个描述数据,也可以叫做是控制数据,也可以叫做描述数据,或者缓存页的元数据。控制块数据,控制数据包括「缓存页的表空间、页号、缓存页地址、链表节点」等等,控制块数据就是为了更好的管理Buffer Pool中的缓存页的。
控制块也是占有内存空间的,它是放在 Buffer Pool 的最前面,接着才是缓存页,如下图:
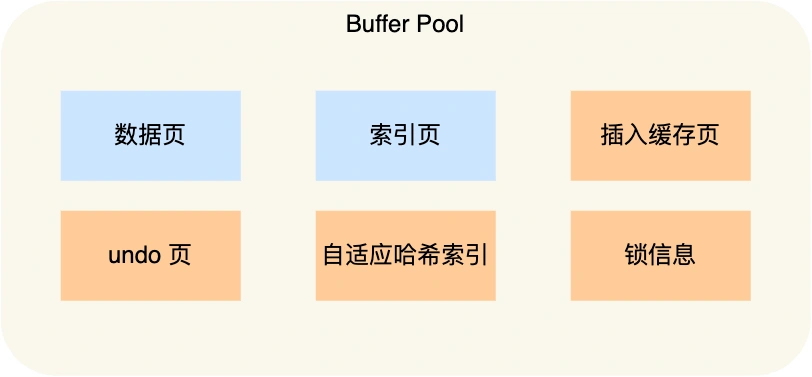
Buffer Pool 除了缓存「索引页」和「数据页」,还包括了 undo 页,插入缓存、自适应哈希索引、锁信息等等。
数据库启动的时候,是如何初始化Buffer Pool的
数据库只要一启动,就会按照设置的Buffer Pool大小,稍微再加大一点,去找操作系统申请一块内存区域,作为Buffer Pool的内存区域。
当内存区域申请完毕之后,数据库就会按照默认的缓存页的16KB的大小以及对应的800个字节左右的描述数据的大小,在Buffer Pool中划分出来一个一个的缓存页和一个一个的他们对应的描述数据。
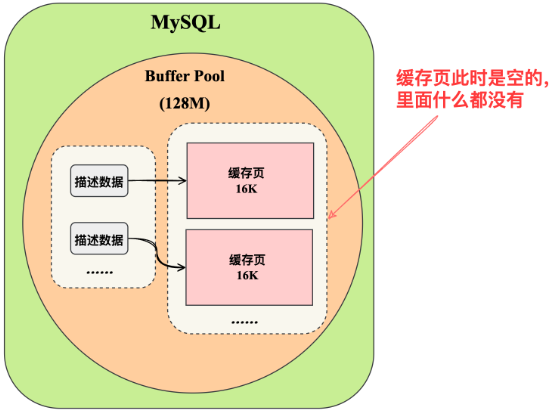
只不过这个时候,Buffer Pool中的一个一个的缓存页都是空的,里面什么都没有,要等数据库运行起来之后,当对数据执行增删改查的操作的时候,才会把数据对应的页从磁盘文件里读取出来,放入Buffer Pool中的缓存页中。
管理Buffer Pool
管理空闲页-free链表
如何知道哪些缓存页是空的
当数据库运行起来之后,系统肯定会不停的执行增删改查的操作,此时就需要不停的从磁盘上读取一个一个的数据页放入Buffer Pool中的对应的缓存页里去,把数据缓存起来,那么以后就可以在内存里对这个数据执行增删改查了。
但是此时在从磁盘上读取数据页放入Buffer Pool中的缓存页的时候,必然涉及到一个问题,那就是哪些缓存页是空闲的?
因为默认情况下磁盘上的数据页和缓存页是一 一对应起来的,都是16KB,一个数据页对应一个缓存页。数据页只能加载到空闲的缓存页里,所以MySql必须要知道Buffer Pool中哪些缓存页是空闲的状态?
MySQL数据库会为Buffer Pool设计了一个free链表,是一个双向链表数据结构,这个free链表里,每个节点就是一个空闲的缓存页的描述数据块的地址,也就是说,只要你一个缓存页是空闲的,那么它的描述数据块就会被放入这个free链表中。
刚开始数据库启动的时候,所有的缓存页都是空闲的,因为此时可能是一个空的数据库,一条数据都没有,所以此时所有缓存页的描述数据块,都会被放入这个free链表中。
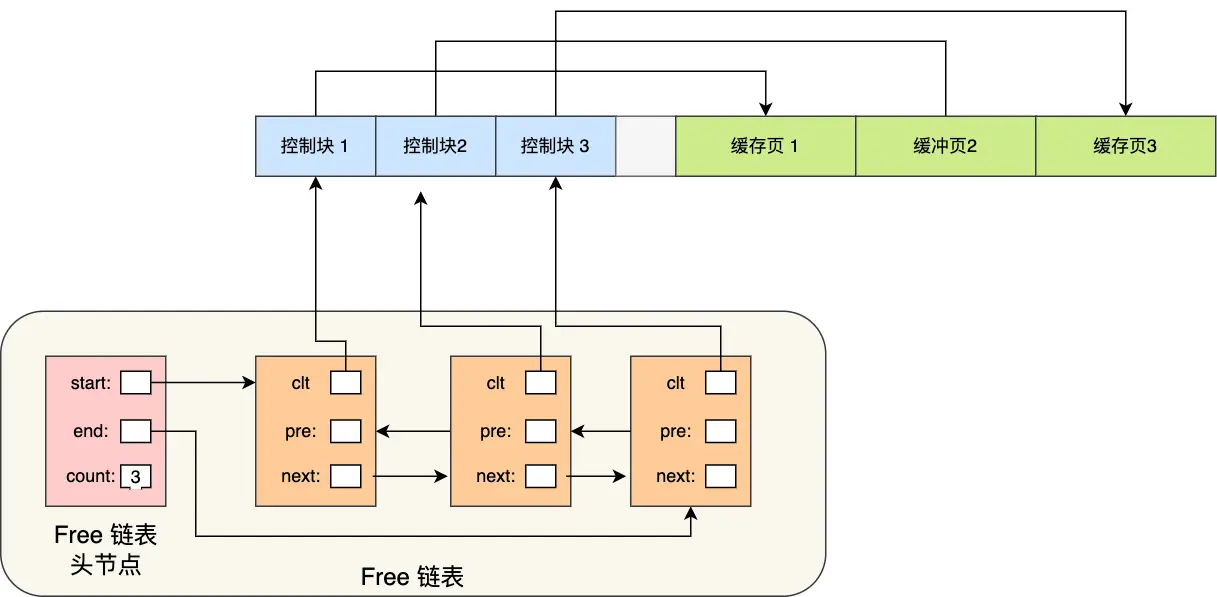
这个free链表里面就是各个缓存页的控制块,只要缓存页是空闲的,那么他们对应的控制块就会加入到这个free链表中,每个节点都会双向链接自己的前后节点,组成一个双向链表。
除此之外,这个free链表有一个基础节点,它会引用链表的头节点和尾节点,里面还存储了链表中当前有多少个节点,也就是链表中有多少个控制块的节点,也就是有多少个空闲的缓存页。
磁盘上的页如何读取到Buffer Pool的缓存页中去?
- 首先,需要从free链表里获取一个控制块,然后就可以获取到这个控制块对应的空闲缓存页;
- 接着就可以把磁盘上的数据页读取到对应的缓存页里去,同时把相关的一些数据写入控制块里去,比如这个数据页所属的表空间之类的信息
- 最后把那个控制块从free链表里去除就可以了。
MySQL怎么知道某个数据页已经被缓存了
- 在执行增删改查的时候,肯定是先看看这个数据页有没有被缓存,如果没被缓存就走上面的逻辑,从free链表中找到一个空闲的缓存页,从磁盘上读取数据页写入缓存页,写入控制数据,从free链表中移除这个控制块。
- 但是如果数据页已经被缓存了,那么就会直接使用了。所以其实数据库还会有一个哈希表数据结构,他会用表空间号+ 数据页号,作为一个key,然后缓存页的地址作为value。当你要使用一个数据页的时候,通过“表空间号+数据页号”作为key去这个哈希表里查一下,如果没有就读取数据页,如果已经有了,就说明数据页已经被缓存了
MySQL引入了一个数据页缓存哈希表的结构,也就是说,每次你读取一个数据页到缓存之后,都会在这个哈希表中写入一个key-value对,key就是表空间号+数据页号,value就是缓存页的地址,那么下次如果你再使用这个数据页,就可以从哈希表里直接读取出来它已经被放入一个缓存页了。
管理脏页-flush链表
为什么会有脏页
如果你要更新的数据页都会在Buffer Pool的缓存页里,供你在内存中直接执行增删改的操作。mysql此时一旦更新了缓存页中的数据,那么缓存页里的数据和磁盘上的数据页里的数据,就不一致了,那么就说这个缓存页是脏页。
脏页怎么刷回磁盘
为了能快速知道哪些缓存页是脏的,于是就设计出 Flush 链表,它跟 Free 链表类似的,链表的节点也是控制块,区别在于 Flush 链表的元素都是脏页。
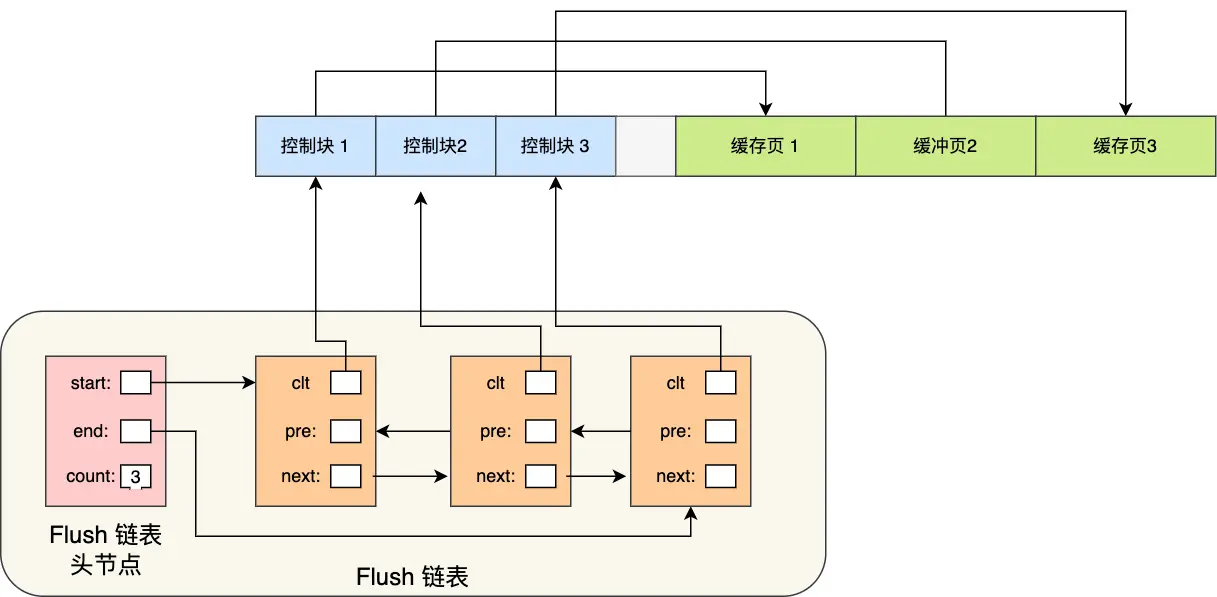
有了 Flush 链表后,后台线程就可以遍历 Flush 链表,将脏页写入到磁盘。
提高缓存命中率-LRU链表
Buffer Pool 的大小是有限的,对于一些频繁访问的数据希望可以一直留在 Buffer Pool 中,而一些很少访问的数据希望可以在某些时机可以淘汰掉,从而保证 Buffer Pool 不会因为满了而导致无法再缓存新的数据,同时还能保证常用数据留在 Buffer Pool 中。
缓存命中率是什么?
假设现在有两个缓存页,一个缓存页的数据,经常会被修改和查询,比如在100次请求中,有30次都是在查询和修改这个缓存页里的数据。那么此时我们可以说这种情况下,缓存命中率很高,为什么呢?因为100次请求中,30次都可以操作缓存,不需要从磁盘加载数据,这个缓存命中率就比较高了。
另外一个缓存页里的数据,就是刚从磁盘加载到缓存页之后,被修改和查询过1次,之后100次请求中没有一次是修改和查询这个缓存页的数据的,那么此时我们就说缓存命中率有点低,因为大部分请求可能还需要走磁盘查询数据,他们要操作的数据不在缓存中。
所以针对上述两个缓存页,当缓存页都满了的时候,第一个缓存页命中率很高,因此肯定是选择将第二个缓存页刷入磁盘中,从而释放缓存页。
因此就引入LRU链表来判断哪些缓存页是不常用的。Least Recently Used,最近最少使用。整体思想就是,链表头部的节点是最近使用的,而链表末尾的节点是最久没被使用的。那么,当空间不够了,就淘汰最久没被使用的节点,从而腾出空间。
简单版的LRU链表
- 当访问的页在 Buffer Pool 里,就直接把该页对应的 LRU 链表节点移动到链表的头部。
- 当访问的页不在 Buffer Pool 里,除了要把页放入到 LRU 链表的头部,还要淘汰 LRU 链表末尾的节点。
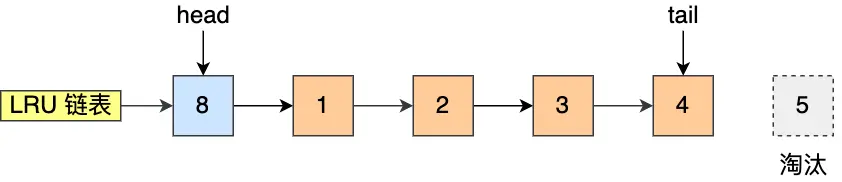
比如下图,假设 LRU 链表长度为 5,LRU 链表从左到右有 1,2,3,4,5 的页。

如果访问了 3 号的页,因为 3 号页在 Buffer Pool 里,所以把 3 号页移动到头部即可。

而如果接下来,访问了 8 号页,因为 8 号页不在 Buffer Pool 里,所以需要先淘汰末尾的 5 号页,然后再将 8 号页加入到头部。
简单版的LRU链表存在两个问题
- 预读失效
- Buffer Pool 污染;
什么是预读失效?
MySQL 的预读机制:程序是有空间局部性的,靠近当前被访问数据的数据,在未来很大概率会被访问到。所以,MySQL 在加载数据页时,会提前把它相邻的数据页一并加载进来,目的是为了减少磁盘 IO。
但是可能这些被提前加载进来的数据页,并没有被访问,相当于这个预读是白做了,这个就是预读失效。
如果使用简单的 LRU 算法,就会把预读页放到 LRU 链表头部,而当 Buffer Pool空间不够的时候,还需要把末尾的页淘汰掉。
如果这些预读页如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是频繁访问的页,这样就大大降低了缓存命中率。
如何解决
首先不能害怕预读失效就把预读机制去了,空间局部性原理在大部分场景下是成立且有效的
而要避免预读失效带来影响,最好就是让预读的页停留在 Buffer Pool 里的时间要尽可能的短,让真正被访问的页才移动到 LRU 链表的头部,从而保证真正被读取的热数据留在 Buffer Pool 里的时间尽可能长。
Mysql将LRU链表划分成了两个区域:old 区域 和 young 区域。
young 区域在 LRU 链表的前半部分,old 区域则是在后半部分
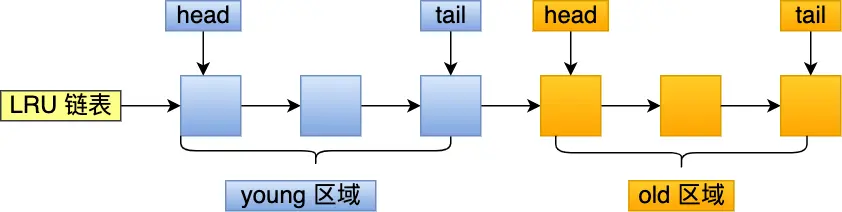
划分这两个区域后,预读的页就只需要加入到 old 区域的头部,当页被真正访问的时候,才将页插入 young 区域的头部。如果预读的页一直没有被访问,就会从 old 区域移除,这样就不会影响 young 区域中的热点数据。
什么是 Buffer Pool 污染?
即使有了以上划分young区的old区的链表也会存在这个问题。
当某一个 SQL 语句扫描了大量的数据时,因为被读取了,这些数据就都会放在young区的头部,那么由于 Buffer Pool 空间有限,就有可能会将 Buffer Pool 里的所有页都替换出去,导致LRU的young区域的大量热数据被淘汰,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 IO,MySQL 性能就会急剧下降,这个过程被称为 Buffer Pool 污染。
如何解决
MySQL 将进入到 young 区域条件增加了一个停留在 old 区域的时间判断。
Mysql在对某个处在 old 区域的缓存页进行第一次访问时,就在它对应的控制块中记录下来这个访问时间:
- 如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该缓存页就不会被从 old 区域移动到 young 区域的头部;
- 如果后续的访问时间与第一次访问的时间不在某个时间间隔内,那么该缓存页移动到 young 区域的头部;
MYsql缓存能否替代Redis
- Redis缓存支持的场景更多。
- 实际工作中缓存的结果不单单是Mysql Select语句返回的结果,有可能是在此基础上又加工的结果;而Mysql缓存的是Select语句的结果
- Redis可以提供更丰富的数据类型的访问,如List、Set、Map、ZSet
- Redis缓存命中率要远高于Mysql缓存。
- Mysql选择要缓存的语句的方式不是根据访问频率,主要是根据select语句里边是否包含动态变化的值,没有动态变化值的则缓存,比如用了now函数就不会缓存。Redis是由客户端自主根据访问频率高进行缓存。
- Redis丰富的数据结构使得缓存复用率更高,比如缓存的是List,可以随意访问List中的部分元素,比如分页需求
- Mysql缓存的失效粒度很粗,只要表有更新,涉及该表的所有缓存(不管更新是否会影响缓存)都失效,这样使得缓存的利用率会很低,只是适用更新很少的表
- 当存在主从结点,并且会从多个结点读取数据时,各个结点的缓存不会同步3. 性能:Redis的查询性能要远高于Mysql缓存,最主要的原因是Redis是全部放在内存的,但是因为mysql缓存的命中率问题使得Mysql无法全部放到内存中。Redis性能好也还有一些其他原因
- Redis的存储结构有利于读写性能Redis是IO多路复用,可以支持更大的吞吐,Mysql的数据特征使得做成IO多路复用绝大多数情况下也没有意义
- 数据更新时会同时将该表的所有缓存失效,会使得数据更新的速度变慢。
面试题专栏
Java面试题专栏已上线,欢迎访问。
- 如果你不知道简历怎么写,简历项目不知道怎么包装;
- 如果简历中有些内容你不知道该不该写上去;
- 如果有些综合性问题你不知道怎么答;
那么可以私信我,我会尽我所能帮助你。
标签:缓存,Buffer,链表,三大,磁盘,数据,Pool From: https://www.cnblogs.com/seven97-top/p/18540775