目录
SQL注入(扩展)
1.描述SQL注入攻击及其防范措施
SQL注入攻击是一种针对数据库驱动的应用程序的攻击技术。它通过在应用程序的输入字段中插入或“注入”恶意的SQL代码,从而改变应用程序原本的SQL查询逻辑,达到非法获取、篡改或删除数据的目的。这种攻击利用了应用程序对用户输入的不当处理或过滤不足。
2.SQL注入攻击的过程
- 攻击者识别应用程序中可能存在的注入点,这通常是通过输入字段、URL参数或其他用户可控的输入来完成的。
- 攻击者构造包含恶意SQL代码的输入,这些代码旨在绕过应用程序的安全机制,直接与数据库交互。
- 当应用程序执行包含恶意SQL代码的查询时,数据库将执行攻击者指定的恶意操作,如读取敏感数据、修改数据或执行其他恶意行为。
3.防范SQL注入攻击采取措施
- 参数化查询:使用参数化查询或预编译语句来执行数据库操作。这种方法将用户输入作为参数传递给查询,而不是将其直接拼接到SQL语句中,从而防止了恶意SQL代码的注入。
- 输入验证和过滤:对用户输入进行严格的验证和过滤,确保输入的数据符合预期的格式和范围。这可以通过正则表达式、白名单或黑名单等方法实现。
- 使用最小权限原则:为应用程序的数据库连接分配尽可能低的权限。这样,即使攻击者成功注入了恶意SQL代码,其能够执行的操作也将受到限制。
- 错误处理:避免在应用程序中直接显示详细的数据库错误信息。这可以防止攻击者利用错误信息来获取有关数据库结构或安全漏洞的信息。
Web应用程序防火墙(WAF):使用WAF来监控和拦截潜在的SQL注入攻击。WAF可以识别并阻止常见的SQL注入模式,为应用程序提供额外的安全层。 - 更新和修补程序:定期更新应用程序及其依赖的组件和库,以修复已知的安全漏洞。同时,关注安全公告和漏洞报告,及时应用相关的安全补丁。
- 安全编码实践:遵循安全编码实践,如避免使用不安全的函数或方法,对敏感数据进行加密处理等。
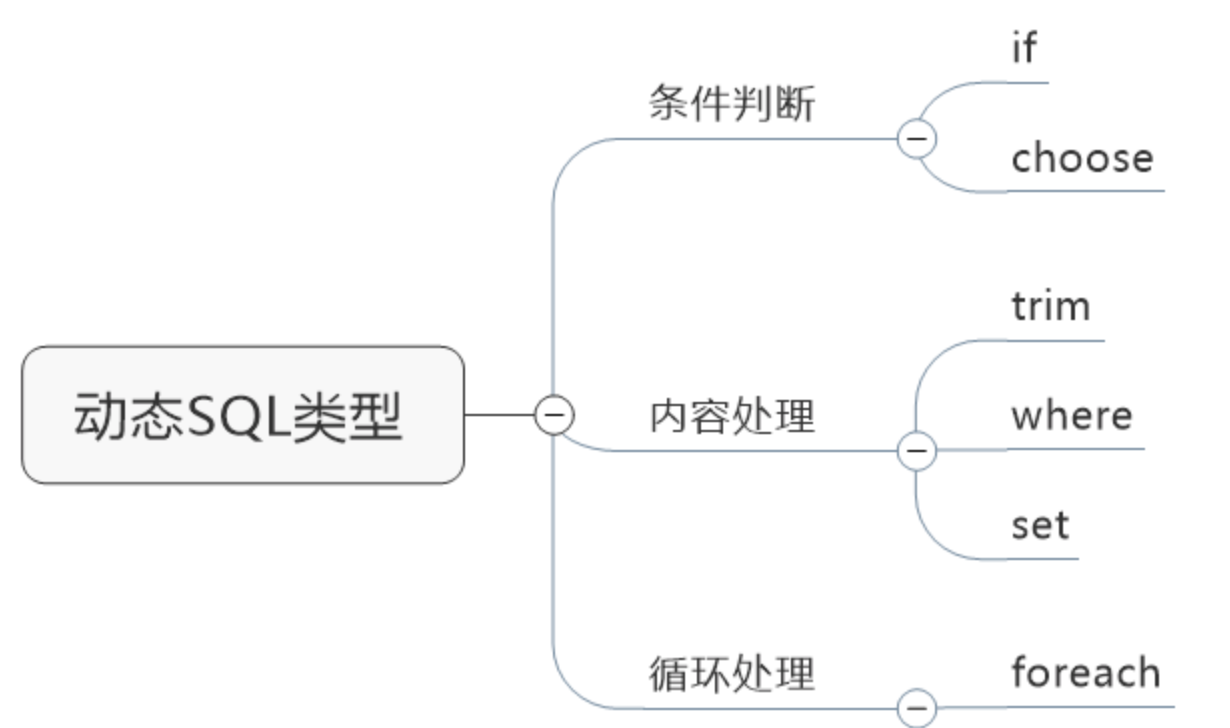
动态 SQL
动态条件查询
假设现在有一个需求,就是根据输入的用户年龄和性别,查询用户的记录信息。你可能会说,这太简单了,脑袋里立马蹦出如下的 SQL 语句:
SELECT * FROM `tb_user` where age = 21 and sex = 1
你可能会觉得这条 SQL 语句还不够完美,因为用户名和年龄是输入的参数,不是写死,应该用占位符替换一下,所以修改如下:
SELECT * FROM `tb_user` where age = ? and sex = ?
你可能认为一切到此结束了,但是你想过没有还有以下这些情况?
- 输入的年龄和性别都是 null
- 输入的性别有值,但年龄为 null
- 输入的年龄有值,但性别 null
- 输入的年龄和性别都有值
现在明白了吧,你其实只处理了以上四种情况中的一种,具体而言是最后一种,还有三种情况并没有处理。
你可能觉得,我看不出剩下的三种情况与已经处理的最后那种情况有什么区别。
好吧,我们一起看看吧,我把 SQL 语句改为第一种情况,也就是年龄和性别都是 null,如下:
SELECT * FROM `tb_user` where age = null and sex = null
这个结果并不是我们想要的,因为当输入的年龄和性别参数为空,正确结果应该是查到所有 user 记录才对。
所以,正确的 SQL 语句应该如下:
SELECT * FROM `tb_user`
这四种情况的处理,一条 SQL 语句是搞不定的,应该要用四条 SQL 语句。
-
SELECT * FROM `tb_user` SELECT * FROM `tb_user` where sex = ? SELECT * FROM `tb_user` where age = ? SELECT * FROM `tb_user` where age = ? and sex = ?
以上情况就是所谓动态条件查询,也就是当查询条件动态改变时,不同的查询条件对应不同的 SQL 语句。
之前我们动态查询条件是年龄和性别,那么如果我再增加一个查询条件,比如姓名,这又会有多少种情况呀?
相信你很快就有答案了,是八种,没错吧。
怎么得来的呀,这很简单,就是数学的排列组合。当两个动态查询条件,是四种处理情况,也就是2的平方;当三个动态查询条件,就是2的三次方,有八种;以此类推,当有四个动态查询条件,那么就是2的四次方,有十六种。
你可能会想,如果有四种动态查询条件,我得写十六条 SQL 语句,这也太夸张了吧。
那有没有什么办法,无论有多少个动态查询条件,都只需要写一条 SQL 语句。
答案是,有,当然有啦,那就是 MyBatis 动态 SQL。
MyBatis 动态 SQL
动态 SQL 是 MyBatis 的一个强大的特性之一,它提供了 OGNL 表达式动态生成 SQL 的功能。
if 元素(最常用)
if 语句用来解决动态条件查询问题,它可以实现根据条件拼接 SQL 语句。
if 语句的作用好比 Java 中的 if 语句,它根据 test 判断条件如果为 true 则拼接里面包含的 SQL 语句片段,如果为 false 则不拼接 SQL 语句片段,语法如下:
<if test="判断条件">
拼接的SQL语句片段
</if>
这里要注意一下,test 的判断条件直接是参数名,而不需要加 #{} 或者 ${}。
where 元素
where 语句用于格式化输出,并没有什么实质的作用。
<select id="selectUserByNameAndAge" resultMap="userResultMap">
<!--方式1:使用序号0,1,2作为参数顺序占位符-->
<!--select * from tb_user where name = #{0} and age = #{1}-->
<!--方式2:使用参数parm1,parm2,...作为参数顺序占位符-->
<!--select * from tb_user where name = #{parm1} and age = #{parm2}-->
<!--方式3:使用参数名作为参数顺序占位符(推荐使用)-->
<!--select * from tb_user where name = #{name} and age = #{age}-->
<!--方式4:动态SQL if语句,支持动态条件查询注意:test标签的参数不能使用$/#{}-->
select * from tb_user where 1=1
<if test="name!= null">
and name = #{name}
</if>
<if test="age != 0">
and age = #{age}
</if>
</select>
上图中where 1=1很明显不好看因此where元素解决了这个问题
<select id="selectUserByNameSexEx" resultMap="userResultMap">
<!--select * from tb_user where name like #{user1.name} and sex = #{user2.sex} and id = #{id}-->
<!--动态Sql if语句-->
select * from tb_user
<where>
<if test="user1.name != null">
and name = #{user1.name}
</if>
<if test="user2.sex != null">
and sex = #{user2.sex}
</if>
</where>
</select>
choose / when / otherwise 元素
choose / when / otherwise 语句类似于 Java 的 switch...case 语句,也可以作为 if 条件判断。
foreach 元素
MyBatis 提供的 foreach 语句主要用来对一个数组、集合、map 等进行遍历,通常是用来构建 IN 条件语句,也可用于其他情况下动态拼接 SQL 语句
语法:
<foreach collection="需要遍历的集合" item="集合中当前元素" index="" open="" separator="每次遍历的分隔符" close="">
动态sql部分
</foreach>
-
collection:可以是一个List、Set、Map或者数组
-
item:集合中的当前元素的引用
-
index:用来访问当前元素在集合中的位置
-
separator:各个元素之间的分隔符
-
open和close用来配置最后用什么前缀和后缀将foreach内部所有拼接的sql给包装起来
-
userMapper.java
/** *根据姓名集合查询用户信息 * @param names 姓名集合 * @return 用户实体集合 */ public List<UserEntity> selectUserByNameList(List<String> names); -
userMapper.xml
<!--批量插入--> <select id="selectUserByNameList" resultType="entity.UserEntity"> select * from tb_user where <foreach collection="list" item="name" index="index" open="name in (" separator="," close=")" > #{name} </foreach> </select> -
MyBatisTest.java
@Test public void selectUserByNameListTest(){ ArrayList<String> name = new ArrayList<>(); name.add("张三"); name.add("李四"); name.add("王五"); List<UserEntity> userEntityList = userMapper.selectUserByNameList(name); logger.debug("查询结果:"+userEntityList); //断言查询结果是否正确 Assert.assertNotNull(userEntityList); }
set 元素
set 语句用于更新操作,功能和 where 语句差不多,用于自动删除多余的逗号。
假设我们有一个需求,需要更新某个指定用户的姓名和用户名,但是只有姓名不为 null 才更新
映射接口方法:
/**
* 更新用户姓名
* @param user 用户姓名
* @return 影响行数
*/
public int updateUser(@Param("id") int id,@Param("name") String name);
SQL 语句映射:
<update id="updateUser">
update tb_user set
<if test="name != null">
name=#{name},
</if>
<if test="name != null">
user_name=#{name},
</if>
where id=#{id};
</update>
我们使用 if 语句就可以轻松搞定,而且用一个 if 就够了,但是我用了两个 if 语句,目的是为了讲解 set 语句的作用。
单元测试代码如下:
@Test
public void updateUserTest() {
int result = userMapper.updateUser(1,"张三三");
sqlSession.commit();
Assert.assertEquals(1,result);
}
执行测试,结果如下:
SQL: update tb_user set name=?, user_name=?, where id=?;
Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'where id=1' at line 8
报语法错误,很明显,执行的 SQL 语句语法不对,user_name 后面多了一个逗号。
怎么改?你会觉得这还不简单,把多余的逗号去掉就可以啦。
但是,你想一想如果只有第一个 if 语句满足条件,那么一样也会出问题,SQL 语句变为如下:
update tb_user set name=?, where id=?; #SQL 语法错误
update tb_user set name=?, where id=?; #SQL 语法错误
或者 两个 if 语句都不满足条件,那么 SQL语句变为如下:
复制代码
update tb_user set where id=?; #SQL 语法错误
结果都会报 SQL 语法错误问题。
看来这个问题还有点棘手,这时候就该我们的 set 语句出场啦,如下:
复制代码
update tb_user
name=#{name},
user_name=#{name},
where id=#{id};
set 语句的作用就是更新操作时自动删除多余的逗号
当然,还有一个问题 set 语句仍然无法解决,就是如果两个 if 语句都不满足条件,即 set 语句后面为空,如下:
复制代码
update tb_user set where id=?; #SQL 语法错误
trim
trim 元素的主要有两个功能:
可以在自己包含的内容前加上某些前缀,也可以在其后加上某些后缀
prefix 属性(添加前缀)
suffix 属性(添加后缀)
可以把包含内容的首部某些内容覆盖,即忽略,也可以把尾部的某些内容覆盖,
prefixOverrides 属性(覆盖首部)
suffixOverrides 属性(覆盖尾部)
正因为 trim 语句有这样的功能,trim 语句可以用来实现 where 语句和 set 语句的效果。
trim 语句实现 where 语句效果如下:
复制代码
prefix="where" 表示在 trim 语句包含的语句前添加前缀 where
prefixOverrides="and | or" 表示在 trim 语句包含的语句前出现 and 或 or 则自动忽略
想一想,这不就是之前 where 语句的功能,trim 语句确实可以代替 where 语句。
trim 语句实现 set 语句效果如下:
复制代码
prefix="set" 表示在 trim 语句包含的语句前添加前缀 setsuffixOverrides="," 表示在 trim 语句包含的语句后出现逗号则自动忽略
想一想,这不就是之前 set 语句的功能,trim 语句确实可以代替 set 语句。
以上可知,trim 语句比 set 语句和 where 语句更加灵活,但是使用也更复杂。 它不仅可以实现 set 语句和 where 语句的功能,还可以实现更多内容处理。
实际项目开发中,能用 set 语句或 where 语句尽量不用 trim 语句,可以理解 trim 语句是一个更加底层的内容处理语句。
总结
MyBatis注解模式
MyBatis 两种映射模式
注意:注解和xml不能混用
MyBatis 有两种 SQL 语句映射模式:一种是基于XML,一种是基于注解。
在这之前,我们都是使用基于 XML 映射文件这种模式实现数据库的各种操作。这次,我打算使用 MyBatis 注解的方式重新实现之前的数据库操作。
MyBatis 注解与 XML 映射文件不同之处在于不需要创建 XML 映射文件,SQL 语句映射是直接写在 Mapper 映射器接口方法上即可。
使用 MyBatis 注解后,需要修改 mybatis-config.xml 全局配置文件,如下:
<!--配置映射路径-->
<mappers>
<!--配置 XML 映射文件路径-->
<!-- <mapper resource="mappers/UserMapper.xml" />-->
<mapper resource="mappers/GameMapper.xml" />
<!--配置注解接口路径-->
<mapper class="mapper.UserMapper" />
</mappers>
我们把配置的 UserMapper.xml 映射文件路径注释掉,然后添加配置注解 UserMapper 接口路径。如果不注释的话,MyBatis 会优先使用 XML 映射文件,也就是说注释不会生效。
注解实现 CURD + 动态 SQL 操作
以下是之前已创建好 UserMapper 映射器接口,里面的接口方法对应数据库的 CURD 操作。
package mapper;
import entity.UserEntity;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Result;
import org.apache.ibatis.annotations.Results;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* @desc User映射器接口
* @date 2020/6/19 上午8:59
*/
public interface UserMapper {
/**
* 根据年龄查询用户信息
* @param age 年龄
* @return user 用户实体集合
*/
public List<UserEntity> selectUserByAge(@Param("age") int age);
/**
* 根据年龄和性别查询用户信息
* @param userOne 获取年龄
* @param userTwo 获取性别
* @return 用户实体集合
*/
public List<UserEntity> selectUserByAgeAndSex(@Param("userOne") UserEntity userOne,@Param("userTwo") UserEntity userTwo);
/**
* 根据姓名和年龄查询用户信息
* @param name 姓名
* @param user 获取年龄
* @return
*/
public List<UserEntity> selectUserByNameAndAge(@Param("name") String name, @Param("user") UserEntity user);
/**
* 查询所有用户信息
* @return 用户实体集合
*/
public List<UserEntity> selectUserAll();
/**
* 根据姓名集合查询用户
* @param names 姓名集合
* @return 用户实体集合
*/
public List<UserEntity> selectUserByNameList(List<String> names);
/**
* 新增用户
* @param user 用户实体
* @return 影响行数
*/
public int insertUser(UserEntity user);
/**
* 更新用户姓名
* @param user 用户姓名
* @return 影响行数
*/
public int updateUser(@Param("id") int id,@Param("name") String name);
/**
* 根据姓名删除用户
* @param name 用户姓名
* @return 影响行数
*/
public int deleteUserById(int id);
}
接下来,我直接在以上接口方法上使用 MyBatis 注解,以实现 SQL 语句映射,如下:
package mapper;
import entity.UserEntity;
import org.apache.ibatis.annotations.*;
import java.util.List;
/**
* @author benjamin.xu
* @desc User映射器接口
* @date 2020/6/19 上午8:59
*/
public interface UserMapper {
/**
* 根据年龄查询用户信息
* @param age 年龄
* @return user 用户实体集合
*/
@Select("select * from tb_user where age > #{age}")
@Results(id="userMap", value={
@Result(property = "id",column = "id",id = true),
@Result(property = "userName",column = "user_name"),
@Result(property = "password",column = "password"),
@Result(property = "name",column = "name"),
@Result(property = "age",column = "age"),
@Result(property = "sex",column = "sex"),
@Result(property = "birthday",column = "birthday"),
@Result(property = "created",column = "created"),
@Result(property = "updated",column = "updated")
})
public List<UserEntity> selectUserByAge(@Param("age") int age);
/**
* 根据年龄和性别查询用户信息
* @param userOne 获取年龄
* @param userTwo 获取性别
* @return 用户实体集合
*/
@Select("select * from tb_user where age > #{userOne.age} and sex = #{userTwo.sex}")
@ResultMap("userMap")
public List<UserEntity> selectUserByAgeAndSex(@Param("userOne") UserEntity userOne,@Param("userTwo") UserEntity userTwo);
/**
* 根据姓名和年龄查询用户信息
* @param name 姓名
* @param user 获取年龄
* @return
*/
@Select("select * from tb_user where name = #{name} and age < #{user.age}")
@ResultMap("userMap")
public List<UserEntity> selectUserByNameAndAge(@Param("name") String name, @Param("user") UserEntity user);
/**
* 查询所有用户信息
* @return 用户实体集合
*/
@Select("select * from tb_user")
@ResultMap("userMap")
public List<UserEntity> selectUserAll();
/**
* 根据姓名集合查询用户
* @param names 姓名集合
* @return 用户实体集合
*/
@Select("<script>" +
"select * from tb_user\n" +
" <where>\n" +
" <foreach item=\"name\" collection=\"list\" index=\"index\" open=\"name in (\" separator=\",\" close=\")\">\n" +
" #{name}\n" +
" </foreach>\n" +
" </where>" +
"</script>")
@ResultMap("userMap")
public List<UserEntity> selectUserByNameList(List<String> names);
/**
* 新增用户
* @param user 用户实体
* @return 影响行数
*/
@Insert("insert into tb_user (id,user_name, password, name, age, sex, birthday, created, updated) values \n" +
"(null,#{userName},#{password},#{name},#{age},#{sex},#{birthday},now(),now())")
@Options(useGeneratedKeys = true, keyProperty = "id")
public int insertUser(UserEntity user);
/**
* 更新用户姓名
* @param user 用户姓名
* @return 影响行数
*/
@Update("update tb_user set name=#{name} where id=#{id}")
public int updateUser(@Param("id") int id,@Param("name") String name);
/**
* 根据姓名删除用户
* @param name 用户姓名
* @return 影响行数
*/
@Delete("delete from tb_user where id=#{id}")
public int deleteUserById(int id);
}
执行测试,结果和 XML 映射文件一样,我这里就不截图了。
注解说明:
- @Insert:插入 SQL 语句注解,相当于 XML 映射文件的 insert 标记
- @Options:该注解有两个属性:一个是 useGeneratedKeys 属性,设置为 true 表示启动自增主键回传,它只针对 insert 语句有效;一个是 keyProperty 属性,表示主键回传对应的实体类属性名
- @Update:更新 SQL 语句注解,相当于 XML 映射文件的 update 标记
- @Delete:删除 SQL 语句注解,相当于 XML 映射文件的 delete 标记
- @Select:查询 SQL 语句注解,相当于 XML 映射文件的 select 标记
- @Results:结果集映射注解,相当于 XML 映射文件的结果集映射 ResultMap 标记
- @Result:实体类属性与数据表字段映射注解,相当于 XML 映射文件中 ResultMap 标记中的 result 子标记(id = true表示该字段是主键)
- @ResultMap:引用 @Results 注解定义好的结果集映射
- @Results:结果集映射注解,相当于 XML 映射文件的结果集映射 ResultMap 标记
如果你已经掌握了 XML 映射文件,想要掌握以上这些注解就太 easy 了;因为和 XML 映射文件相比,无非就是把 SQL 语句映射换了一个地方罢了。
说白了,你可以直接把 XML 映射文件的 SQL 语句复制过来,放到对应的注解里面就完事了。
动态 SQL说明:
注解实现动态 SQL 和 XML 映射文件一样,也是把 SQL 语句复制过来,不过需要将其放到 script 标记里面,告诉 MyBatis 这是动态 SQL 语句,如下:
@Select("<script>" +
" select * from tb_user\n" +
" <where>\n" +
" <foreach item=\"name\" collection=\"list\" index=\"index\" open=\"name in (\" separator=\",\" close=\")\">\n" +
" #{name}\n" +
" </foreach>\n" +
" </where>" +
"</script>")
@ResultMap("userMap")
public List<UserEntity> selectUserByNameList(List<String> names);
大家可以看到,里面很多斜杠转义符,所以在注解中实现 动态 SQL,要特别小心,弄不好就会报错,搞得你焦头烂额。
注解实现一对一关联查询
这里需要先修改 mybatis-config.xml 全局配置文件,如下:
<!--配置映射路径-->
<mappers>
<!-- <mapper resource="mappers/UserMapper.xml" />-->
<!-- <mapper resource="mappers/GameMapper.xml" />-->
<mapper class="mapper.UserMapper" />
<mapper class="mapper.GameMapper" />
</mappers>
目的是将原来配置的 XML 映射文件路径注释掉,然后添加注解接口路径。
以下是之前已创建好 GameMapper 映射器接口,如下:
package mapper;
import entity.GameEntity;
import entity.PlayerEntity;
import entity.RoleEntity;
/**
* @desc 游戏映射器接口
* @date 2020/7/10 下午6:20
*/
public interface GameMapper {
/**
* 根据角色ID查询账号信息
* @param id 角色Id
* @return 角色实体对象
*/
public RoleEntity selectRoleById(int id);
/**
* 根据游戏名查询游戏账号
* @param name 游戏名
* @return 游戏实体类
*/
public GameEntity selectGameByName(String name);
/**
* 根据玩家名查询游戏
* @param name 玩家名
* @return 玩家实体类
*/
public PlayerEntity selectPlayerByName(String name);
}
接下来,我直接在以上接口方法上使用 MyBatis 注解,以实现 SQL 语句映射,如下:
@Select("select r.*,a.* from tb_role as r join tb_account as a on r.account_id=a.id where r.id=#{id}")
@Results(value = {
@Result(property = "id",column = "id",id = true),
@Result(property = "profession",column = "profession"),
@Result(property = "rank",column = "rank"),
@Result(property = "money",column = "money"),
//一对一关联映射
@Result(property = "account.id",column = "id"),
@Result(property = "account.userName",column = "user_name"),
@Result(property = "account.password",column = "password")
})
public RoleEntity selectRoleById(int id);
注:暂时没有找到 MyBatis 注解如何实现一对多以及多对多的关联查询的方法
注解实现一对一、一对多和多对多子查询
子查询需要用到两个注解:
- @One:一对一映射注解,相当于 XML 映射文件的 association 标记
- @Many:一对多映射注解,相当于 XML 映射文件的 collection 标记
我直接在以上接口方法上使用 MyBatis 注解,以实现 SQL 语句映射,如下:
package mapper;
import entity.AccountEntity;
import entity.GameEntity;
import entity.PlayerEntity;
import entity.RoleEntity;
import org.apache.ibatis.annotations.*;
/**
* @desc 游戏映射器接口
* @date 2020/7/10 下午6:20
*/
public interface GameMapper {
/**
* 根据角色ID查询账号信息
* @param id 角色Id
* @return 角色实体对象
*/
@Select("select * from tb_role where id=#{id}")
@Results(value = {
@Result(property = "id",column = "id",id = true),
@Result(property = "profession",column = "profession"),
@Result(property = "rank",column = "rank"),
@Result(property = "money",column = "money"),
@Result(property = "account",column = "account_id",
one = @One(select = "selectAccountById"))
})
public RoleEntity selectRoleById(int id);
@Select("select * from tb_account where id=#{id}")
@ResultType(AccountEntity.class)
public AccountEntity selectAccountById(int id);
/**
* 根据游戏名查询游戏账号
* @param name 游戏名
* @return 游戏实体类
*/
@Select("select * from tb_game where name =#{name}")
@Results(value = {
@Result(property = "id",column = "id",id = true),
@Result(property = "name",column = "name"),
@Result(property = "type",column = "type"),
@Result(property = "operator",column = "operator"),
@Result(property = "accounts",column = "id",
many = @Many(select = "selectAccountById"))
})
public GameEntity selectGameByName(String name);
/**
* 根据玩家名查询游戏
* @param name 玩家名
* @return 玩家实体类
*/
@Select("select * from tb_player where name = #{name}")
@Results(value = {
@Result(property = "id",column = "id",id = true),
@Result(property = "name",column = "name"),
@Result(property = "age",column = "age"),
@Result(property = "sex",column = "sex"),
@Result(property = "games",column = "id",
many = @Many(select = "selectGameById"))
})
public PlayerEntity selectPlayerByName(String name);
@Select(" select * from tb_game where id in (select game_id from tb_player_game where player_id=#{id})")
@ResultType(GameEntity.class)
public GameEntity selectGameById(int id);
}
我在接口中新创建了两个查询方法,selectAccountById 和 selectGameById,这两个方法和 XML 映射文件中作用相同,也就是用于子查询。
性能优化
数据源
回顾JDBC
-
JDBC访问数据库流程
- 加载驱动
- 获取Connection连接对象(消耗性能)
- 获取PrepareStatement对象
- 执行SQL语句
- 获取结果集
- 关闭Connection连接对象
-
问题
频繁访问数据库时性能下降(高并发)
数据源的概念
数据源是一种提高 JDBC 访问数据库性能的常规手段
数据源的原理
数据源会负责维持一个数据库连接池,连接池中会一次性地提前创建多个 Connection 连接对象,并把这些Connection连接对象保存在连接池中。
当程序需要进行数据库访问时,无须进行重新获取 Connection 连接对象,而是从连接池中取出一个空闲的Connection连接对象。
当程序使用 Connection 连接对象访问数据库结束后,无须关闭 Connection 连接对象,而是归还给数据库连接池中。通过这种方式,就可以避免频繁访问数据库时性能下降的问题。
当 Connection 连接对象耗尽时,连接池会批量创建一批 Connection 连接对象存放到连接池中。当连接池中有长期未使用的 Connection 连接对象,则会自动将其释放,以节省内存空间。
数据源的本质
一种以空间换时间的性能优化思想
扩展知识
Java 线程池原理
数据源连接池总结
- JDBC 的弊端
- 数据源的概念
- 数据源的原理
- 数据源的本质
MyBatis 延迟加载
什么是延迟加载
延迟加载又叫懒加载,也叫按需加载,也就是说先加载主表信息,需要的时候,再去加载从表信息。代码中有查询语句,当执行到查询语句时,并不是马上去数据库中查询,而是根据设置的延迟策略将查询向后推迟
在 mybatis 中经常用到关联查询,但是并不是任何时候都需要立即返回关联查询结果。比如查询订单信息,并不一定需要及时返回订单对应的用户信息或者订单详情信息等,这种情况需要一种机制,当需要查看关联的数据时,再去执行对应的查询,返回需要的结果,这种需求在 mybatis 中可以使用延迟加载机制来实现。
延迟加载的目的
减轻数据库服务器的压力,因为我们延迟加载只有在用到需要的数据才会执行查询操作。
延迟加载 2 种设置方式
- 全局配置的方式
- sqlmap 中配置的方式
全局配置延迟加载
mybatis 配置文件中通过上面两个属性来控制延迟加载:
<settings>
<!-- 启用延迟加载开关(默认关闭)-->
<setting name="lazyLoadingEnabled" value="true"></setting>
<!-- true:调用任意延迟属性,会去加载所有延迟属性 false:则调用某个属性的时候,只会加载指定的属性 -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
Mybatis 配置文件中通过两个属性 lazyLoadingEnabled 和 aggressiveLazyLoading 来控制延迟加载和按需加载。
-
lazyLoadingEnabled:是否启用延迟加载,mybatis默认为false,不启用延迟加载。lazyLoadingEnabled属性控制全局是否使用延迟加载,特殊关联关系也可以通过嵌套查询中 fetchType 属性单独配置(fetchType属性值lazy或者eager)。
-
aggressiveLazyLoading:是否按需加载属性,默认值false。该属性为 true 时只要加载对象,就会加载该对象的所有属性;该属性为 false 则会按需加载,即使用到某关联属性时,实时执行嵌套查询加载该属性。
sqlmap 中设置延迟加载
全局的方式会对所有的关联查询起效,影响范围比较大,mybatis 也提供了在关联查询中进行设置的方式,只会对当前设置的关联查询起效。
关联查询,一般我们使用association、collection,这两个元素都有个属性fetchType,通过这个属性可以指定关联查询的加载方式。
fetchType 值有 2 种
- eager:立即加载
- lazy:延迟加载
<resultMap id="roleMap" type="entity.RoleEntity">
<association property="account"
fetchType="lazy"
column="acount_id"
select="queryAccountById">
</association>
</resultMap>
总结
- 什么是延迟加载
- 延迟加载的目的是什么
- 如何开启延迟加载
- 按需加载和完全加载在区别是什么
MyBatis 缓存机制
什么是缓存
缓存就是内存中存储数据的一个地方(称作:Cache),当程序要读取数据时,会首先从缓存中获取,有则直接返回,否则从其他存储设备中获取,缓存最重要的一点就是获取数据的速度是非常快,通过缓存可以加快数据的访问速度。比如我们从 db 中获取数据,中间需要经过网络传输耗时,db 服务器从磁盘读取数据耗时等,如果这些数据直接放在缓存中,访问是不是会快很多。
MyBatis 缓存机制原理
Mybatis 缓存机制原理是将第一次从数据库 SQL 查询的结果数据保存到缓存(内存中),当下一次 SQL 查询和第一次相同,如果缓存中有数据则直接获取,而不用再从数据库获取,从而减少数据库访问频率,大大提升数据库性能。
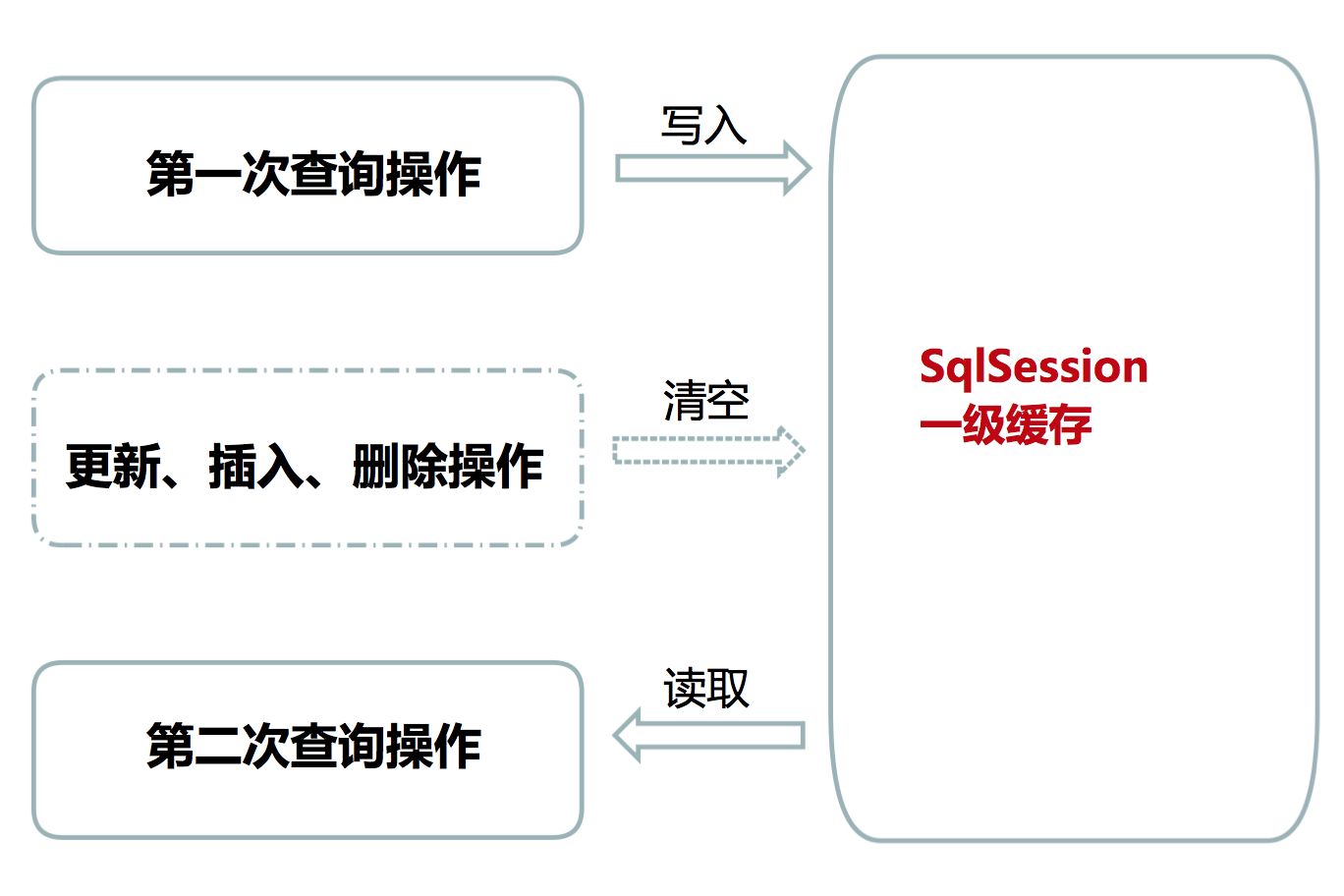
MyBatis 一级缓存
一级缓存是 Sqlssion 级别的缓存。
在操作数据库时需要构造 SqlSession 对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。
不同的 SqlSession 对象之间的缓存数据是互相不影响的。
一级缓存的作用范围是同一个 SqlSession 对象,在同一个 SqlSession 对象中再次执行相同的 SQL 语句,第一次执行完毕会将数据库中查询的数据写到缓存,第二次会从缓存中获取数据,不必再从数据库中查询,从而提升查询效率。当 SqlSession 对象释放后,该 SqlSession 对象中的一级缓存也就不存在了。
MyBatis 默认开启一级缓存,并且无法关闭
一级缓存工作原理如下:
一级缓存满足条件如下:
- 同一个 SqlSession 对象
- 相同的 SQL 语句和参数
注:使用 SqlSession.clearCache( ) 方法可以强制清除一级缓存
测试 MyBatis 一级缓存
既然每个 SqlSession 都会有自己的一个缓存,那么我们用同一个 SqlSession 是不是就能感受到一级缓存的存在呢?调用多次 getMapper 方法,生成对应的 SQL 语句,判断每次 SQL 语句是从缓存中取还是对数据库进行操作,下面的例子来证明一下
@Test
public void cacheTest() {
List<UserEntity> userEntities = userMapper.selectUserByAge(20);
System.out.println(userEntities);
List<UserEntity> userEntities2 = userMapper.selectUserByAge(20);
System.out.println(userEntities2);
List<UserEntity> userEntities3 = userMapper.selectUserByAge(20);
System.out.println(userEntities3);
}
执行测试,输出结果如下:
2020-08-10 16:14:44,790 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:14:44,837 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:14:44,884 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
可以看到,连续执行三次查询 SQL 语句,但只打印了一条 SQL 语句,其他两条 SQL 语句都是从缓存中查询的,所以它们生成了相同的 UsereEntity 对象。
接着我在第一条和第二条 SQL语句 之间插入更新的 SQL 语句,代码如下:
@Test
public void cacheTest() {
List<UserEntity> userEntities = userMapper.selectUserByAge(20);
System.out.println(userEntities);
int result = userMapper.updateUser(1,"张三");
sqlSession.commit();
List<UserEntity> userEntities2 = userMapper.selectUserByAge(20);
System.out.println(userEntities2);
}
执行测试,结果如下:
020-08-10 16:20:47,384 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:20:47,431 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.updateUser]-[DEBUG] ==> Preparing: update tb_user set name=? where id=?
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.updateUser]-[DEBUG] ==> Parameters: 张三(String), 1(Integer)
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.updateUser]-[DEBUG] <== Updates: 1
2020-08-10 16:20:47,493 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:20:47,493 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:20:47,509 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
可以看到,在两次查询 SQL 语句中使用插入 SQL 语句,会对一级缓存进行刷新,会导致一级缓存失效。
我们知道一级缓存就是 SqlSession 级别的缓存,而同一个 SqlSession 会有相同的一级缓存,那么使用不同的 SqlSession 是不是会对一级缓存产生影响呢?
@Test
public void cacheTest() {
List<UserEntity> userEntities = userMapper.selectUserByAge(20);
System.out.println(userEntities);
UserMapper userMapper2
= sqlSessionFactory.openSession().getMapper(UserMapper.class);
List<UserEntity> userEntities2 = userMapper2.selectUserByAge(20);
System.out.println(userEntities2);
执行测试,结果如下:
2020-08-10 16:26:36,243 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:26:36,290 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:26:36,322 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
2020-08-10 16:26:36,337 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:26:36,337 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:26:36,353 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
上面代码使用了不同的 SqlSession 对同一个 SQL 语句执行了相同的查询操作,却对数据库执行了两次相同的查询操作,生成了不同的 UserEnity 对象,由此可见,不同的 SqlSession 是肯定会对一级缓存产生影响的。
//手动清除一级缓存方法
sqlSession.clearCache();
在开启一级缓存时,当有两个 SqlSession 对象存在,一个用于查询数据,一个用于更新数据,如果查询和更新是同一张表的相同数据,这时可能会出现数据脏读,而解决办法是查询时手动清空缓存。
清空一级缓存 3 种方式
-
SqlSession 中执行增、删、改操作,此时sqlsession会自动清理其内部的一级缓存
-
调用 SqlSession 中的 clearCache 方法清理其内部的一级缓存
//手动清除一级缓存方法 sqlSession.clearCache(); -
设置 Mapper.xml 中 select 元素的 flushCache 属性值为 true,那么执行查询的时候会先清空一级缓存中的所有数据,然后去 db 中获取数据
<select id="queryUserByName" flushCache="true" resultType="entity.UserEntity" > select * from tb_user where name like concat(#{name},'%') </select>
MyBatis 二级缓存
一级缓存使用上存在局限性,必须要在同一个 SqlSession 中执行同样的查询,一级缓存才能提升查询速度,如果想在不同的 SqlSession之间使用缓存来加快查询速度,此时我们需要用到二级缓存了
二级缓存是 Mapper 级别的缓存
每个 mapper.xml 有个 namespace,二级缓存和 namespace 绑定的,每个 namespace 关联一个二级缓存,多个 SqlSession 可以共用二级缓存, 二级缓存是跨 SqlSession 的。
二级缓存是多个 SqlSesion 对象共用的。
其作用范围是 Mapper 的同一个 namespace ,不同的 SqlSession 对象再次执行相同 namepace 下的 SQL 语句,第一次执行会将数据库中查询结果数据存储到二级缓存中,第二次会从二级缓存中获取数据,而不再从数据库中获取,从而提高查询效率。
MyBatis 二级缓存默认关闭,需要手动开启二级缓存。
MyBatis 的二级缓存是 Mapper 范围级别,除了在 MyBatis 环境配置 mybatis-config.xml 设置二级缓存总开关,还要在具体的 mapper.xml 中加入
步骤如下:
-
mybatis-config.xml 设置二级缓存总开关
<settings> <!-- 开启二级缓存 --> <setting name="cacheEnabled" value="true" /> </settings> -
在具体的 mapper.xml 中加扩
标签 <mapper> <!--开启二级缓存(表示对哪个mapper 开启缓存)--> <cache /> </mapper>设置 cache 标签的属性
cache 标签有多个属性
-
eviction: 缓存回收策略
- LRU - 最近最少回收,移除最长时间不被使用的对象(默认)
- FIFO - 先进先出,按照缓存进入的顺序来移除它们
- SOFT - 软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK - 弱引用,更积极的移除基于垃圾收集器和弱引用规则的对象
-
flushinterval:缓存刷新间隔,缓存多长时间刷新一次,默认不清空,设置一个毫秒值
-
readOnly: 是否只读;true 只读,MyBatis 认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。MyBatis 为了加快获取数据,直接就会将数据在缓存中的引用交给用户。不安全,速度快。读写(默认):MyBatis 觉得数据可能会被修改
-
size : 缓存存放多少个元素
-
type: 指定自定义缓存的全类名(实现Cache 接口即可)
-
blocking: 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
注:开启二级缓存后,MyBatis要求返回的实体类对象必须是可序列化的
开启二级缓存后,在不同 SqlSesion 下执行相同查询 SQL 语句,代码如下:
@Test public void cacheTest() { List<UserEntity> userEntities = userMapper.selectUserByAge(20); System.out.println(userEntities); sqlSession.commit(); //提交SQL语句到数据库返回查询结果 UserMapper userMapper2 = sqlSessionFactory.openSession().getMapper(UserMapper.class); List<UserEntity> userEntities2 = userMapper2.selectUserByAge(20); System.out.println(userEntities2); }执行测试,结果如下 :
-
2020-08-10 16:41:43,119 [main] [mapper.UserMapper]-[DEBUG] Cache Hit Ratio [mapper.UserMapper]: 0.0
2020-08-10 16:41:43,509 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:41:43,572 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:41:43,603 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
2020-08-10 16:41:43,634 [main] [mapper.UserMapper]-[DEBUG] Cache Hit Ratio [mapper.UserMapper]: 0.5
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
通过结果可以得知,首次执行的SQL语句是从数据库中查询得到的结果,然后第一个 SqlSession 执行提交,第二个 SqlSession 执行相同的查询后是从二级缓存中查取的。
值得注意的是,SqlSession 在未提交的时候,SQL 语句产生的查询结果还没有放入二级缓存中,这个时候 SqlSession2 在查询的时候是感受不到二级缓存的存在的。
与一级缓存一样,更新操作很可能对二级缓存造成影响。
多表操作对二级缓存也会产生影响,如下:
GameMapper.java 文件添加一个接口方法,代码如下:
@Update("update tb_game set name = #{name} where id = #{id}")
public int updateGameNameById(@Param("name") String name, @Param("id") int id);
在测试 MyBatisTest.java中添加一个测试方法,代码 如下:
@Test
public void cacheJoinTableTest() {
GameEntity gameEntity = gameMapper.selectGameByName("英雄联盟");
System.out.println(gameEntity);
SqlSession sqlSession2 = sqlSessionFactory.openSession();
GameMapper gameMapper2 = sqlSession2.getMapper(GameMapper.class);
gameMapper2.updateGameNameById("王者荣耀",1);
sqlSession2.commit();
gameEntity = gameMapper.selectGameByName("英雄联盟");
System.out.println(gameEntity);
}
执行测试,结果如下:
2020-08-10 22:58:51,867 [main] [mapper.GameMapper]-[DEBUG] Cache Hit Ratio [mapper.GameMapper]: 0.0
2020-08-10 22:58:52,289 [main] [mapper.GameMapper.selectGameByName]-[DEBUG] ==> Preparing: select * from tb_game where name =?
2020-08-10 22:58:52,320 [main] [mapper.GameMapper.selectGameByName]-[DEBUG] ==> Parameters: 英雄联盟(String)
2020-08-10 22:58:52,367 [main] [mapper.GameMapper]-[DEBUG] Cache Hit Ratio [mapper.GameMapper]: 0.0
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectAccountById]-[DEBUG] ====> Preparing: select * from tb_account where id=?
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectAccountById]-[DEBUG] ====> Parameters: 1(Integer)
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectAccountById]-[DEBUG] <==== Total: 1
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectGameByName]-[DEBUG] <== Total: 1
GameEntity{id=1, name='英雄联盟', type='MOBA', operator='腾讯游戏', accounts=[AccountEntity{id=1, userName='潇洒哥', password='12345'}]}
2020-08-10 22:58:52,382 [main] [mapper.GameMapper.updateGameNameById]-[DEBUG] ==> Preparing: update tb_game set name = ? where id = ?
2020-08-10 22:58:52,382 [main] [mapper.GameMapper.updateGameNameById]-[DEBUG] ==> Parameters: 王者荣耀(String), 1(Integer)
2020-08-10 22:58:52,398 [main] [mapper.GameMapper.updateGameNameById]-[DEBUG] <== Updates: 1
2020-08-10 22:58:52,398 [main] [mapper.GameMapper]-[DEBUG] Cache Hit Ratio [mapper.GameMapper]: 0.0
GameEntity{id=1, name='英雄联盟', type='MOBA', operator='腾讯游戏', accounts=[AccountEntity{id=1, userName='潇洒哥', password='12345'}]}
在对 tb_game 表执行了一次更新后,再次进行联查,发现数据库中查询出的还是游戏名仍是王者荣耀,也就是说,最后一次联查实际上查询的是第一次查询结果的缓存,而不是从数据库中查询得到的值,这样就读到了脏数据。
如果是两个 mapper 命名空间的话,解决办法是可以使用 cache-ref 来把一个命名空间指向另外一个命名空间,从而消除上述的影响,再次执行,就可以查询到正确的数据。
清空或者跳过二级缓存的 3 种方式
当二级缓存开启的时候,在某个 mapper.xml 中添加 cache 元素之后,这个 mapper.xml 中所有的查询都默认开启了二级缓存,那么我们如何清空或者跳过二级缓存呢?3种方式如下:
- 对应的 mapper 中执行增删改查会清空二级缓存中数据
- select 元素的 flushCache 属性置为 true,会先清空二级缓存中的数据,然后再去 db 中查询数据,然后将数据再放到二级缓存中
- select 元素的 useCache 属性置为 true,可以使这个查询跳过二级缓存(不会清空),然后去查询数据
一级缓存和二级缓存的区别
二级缓存是 Mapper 级别,一级缓存是 SqlSession 级别,多个 SqlSession 级别的一级缓存可以共享一个 Mapper 级别的二级缓存。
当开启二级缓存后,数据的查询执行的流程是二级缓存 -> 一级缓存 -> 数据库
一二级缓存共存时查询原理
一二级缓存如果都开启的情况下,数据查询过程如下:
-
当发起一个查询的时候,mybatis 会先访问这个 namespace 对应的二级缓存,如果二级缓存中有数据则直接返回,否则继续向下
查询一级缓存中是否有对应的数据,如果有则直接返回,否则继续向下访问 db 获取需要的数据,然后放在当前 SqlSession 对应的二级缓存中,并且在本地内存中的另外一个地方存储一份(这个地方我们就叫 TransactionalCache)
-
当 SqlSession 关闭的时候,也就是调用 SqlSession 的 close 方法的时候,此时会将 TransactionalCache 中的数据放到二级缓存中,并且会清空当前 SqlSession 一级缓存中的数据
总结
- 一二级缓存访问顺序:一二级缓存都存在的情况下,会先访问二级缓存,然后再访问一级缓存,最后才会访问db
- 将 mapper.xml 中 select 元素的 flushCache 属性置为 true,最终会清除一级缓存所有数据,同时会清除这个 select 所在的 namespace 对应的二级缓存中所有的数据
- 将 mapper.xml 中 select 元素的 useCache 属性值为 false,会使这个查询跳过二级缓存
- 总体上来说使用缓存可以提升查询效率