原文链接:mysql对结果集进行遍历(mysql双重for循环如何写) – 每天进步一点点
0.背景
有这么一个需求:对以下的类型结果集进行更新。
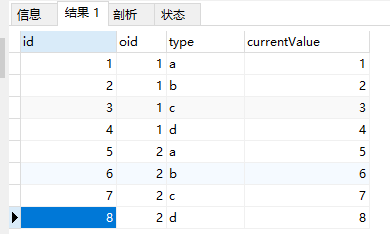
更新的原则是type为c的currentValue的值= (type为b的currentValue) / ((type为b的currentValue) + (type为a的currentValue)) *100。
上面这个需求有很多种实现方法,看到这个需求的时候,我想到的双重for循环:先查询第一个结果集,第一个结果集合里面包含oid字段。
然后对第一个结果集进行遍历,把oid作为参数更新到第二个sql语句中进行更新。
本文是用定义存储过程的方式实现对结果集的遍历,也就是我所希望的双重for循环。
工具:navicat。
数据:
| 1 2 3 4 5 6 7 8 |
DROP TABLE IF EXISTS `report_data`;
CREATE TABLE `report_data` (
`id` int(255) NOT NULL,
`oid` int(255) NOT NULL,
`type` varchar(10) not NULL,
`currentValue` double not NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
|
| 1 2 3 4 5 6 7 8 |
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (1, 1, 'a', 1);
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (2, 1, 'b', 2);
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (3, 1, 'c', 3);
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (4, 1, 'd', 4);
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (5, 2, 'a', 5);
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (6, 2, 'b', 6);
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (7, 2, 'c', 7);
INSERT INTO `report_data` (`id`, `oid`, `type`, `currentValue`) VALUES (8, 2, 'd', 8);
|
1.对查询结果进行遍历
先展示结果模板:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE PROCEDURE [存储过程名称()]
BEGIN
DECLARE s int DEFAULT 0;
DECLARE [变量名 1 ] INT DEFAULT 0;
DECLARE [变量名 2 ] VARCHAR ( 255 );
DECLARE [游标名] CURSOR FOR [包含结果集的 SQL ]
DECLARE CONTINUE HANDLER FOR NOT FOUND SET s=1;
OPEN [游标名];
FETCH [游标名] INTO [变量名 1 ],[变量名 2 ];
WHILE s <> 1 DO
[你想操作的 SQL语句 ]
FETCH [游标名] INTO [变量名 1 ],[变量名 2 ];
END WHILE;
CLOSE [游标名];
END;
|
说明:
1.CREATE PROCEDURE [存储过程名称()] 表示创建一个存储过程。我们这里假设名称叫processdata,那么这行代码就写成 CREATE PROCEDURE processdata()
2. BEGIN 和 END 是函数的开始和结束
3.
DECLARE [变量名 1 ] INT DEFAULT 0;
DECLARE [变量名 2 ] VARCHAR ( 255 );这两行代码是定义变量,为什么要定义变量呢,是因为我们查询出的结果集要放到变量中进行二次操作。这里需要注意的是,变量名的命名规则除了跟普通变量一样以外,还不能够跟结果集中对应的字段名重复。比如 select id,name from student;这个sql中有两个字段,id和name。那么定义变量的时候就不要再定义id和name了。可以换成idTemp 和nameTemp。
另外,变量的类型要和查询结果集的字段类型对应。
DECLARE s int DEFAULT 0; 这行sql比较特别是定义循环变量s的,下面的while循环要用到。
4.
DECLARE [游标名] CURSOR FOR [包含结果集的 SQL ] 这行sql就是定义游标,其中包含了我们的结果集,比如下面这样:
DECLARE stu CURSOR FOR select id,name from student group by id;这样的话,我们第一个结果集就出来了。后面就考虑遍历这个结果集。
5.DECLARE CONTINUE HANDLER FOR NOT FOUND SET s=1; 声明当游标遍历完后将标志变量置成某个值
6. OPEN [游标名]; 这个不用过多解释,上面定义完游标后,这里打开游标。
7.FETCH [游标名] INTO [变量名 1 ],[变量名 2 ]; 这段sql是将我们查询的结果集与我们定义的变量进行关联,注意顺序应该一一对应。比如下面这样
FETCH stu INTO idTemp,nameTemp;
这里的idTemp就表示上面结果集中的id,nameTemp就表示上面结果集中的nameTemp
8.
WHILE s <> 1 DO
....
END WHILE;
这段代码是while循环。
9.
[你想操作的sql语句]
这个地方就是内部for循环了,比如我们在这个地方写一个update语句。
update student set score=’91’ where id=idTemp and name = nameTemp;
这个语句就会去寻找上方结果集中的id和name,然后把值代入到idTemp中和nameTemp中,进行操作。
10.
FETCH [游标名] INTO [变量名 1 ],[变量名 2 ];
这段表示将游标中的值再赋值给变量,供下次循环使用。
当定义完了以后,执行sql。然后就是navicat的函数,找个我们刚才定义的函数进行执行。
2.完成需求
上面已经说明白了整个过程的含义,下面我们来完成本文的需求。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE PROCEDURE processData()
BEGIN
DECLARE s int DEFAULT 0;
DECLARE oidTemp int DEFAULT 20;
DECLARE report CURSOR FOR SELECT oid from report_data GROUP BY oid;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET s=1;
open report;
fetch report into oidTemp;
while s<>1 do
SET @fenzi= (SELECT currentValue from report_data WHERE type='b' and oid =oidTemp);
set @fenmu= (SELECT currentValue from report_data WHERE type='a' and oid =oidTemp) +
(SELECT currentValue from report_data WHERE type='b' and oid =oidTemp);
set @result = @fenzi/@fenmu *100;
update report_data set currentvalue = @result WHERE oid =oidTemp and type='c';
fetch report into oidTemp;
end while;
close report;
END;
|
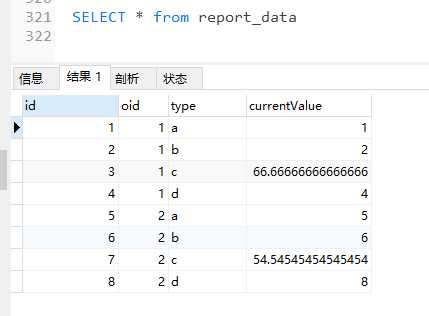
结果
本文链接:https://www.longkui.site/mysql/mysqlfor/5403/
标签:currentValue,遍历,双重,DECLARE,mysql,report,type,id,oid From: https://www.cnblogs.com/longkui-site/p/18487826