背景
数据结转过程中经常进行 delete 操作,产生空白空间,如果进行新的插入操作,MySQL将尝试利用这些留空的区域,但仍然无法将其彻底占用,于是造成了数据的存储位置不连续,以及物理存储顺序与理论上的排序顺序不同,久而久之就产生了碎片。
碎片治理思路
根据线上处理经验总结比对4种处理磁盘碎片优缺点
| 优势 | 缺点 | 备注 | |
| 将数据量巨大的表设计成分区表,按时间分区 | 通过结转分区数据,删除分区释放磁盘碎片,磁盘IO抖动秒级别,对线上业务影响小 | 估算数据量,每个分区不超过3亿数据350G为佳;库存流水,订单表这些表应该在创建时就应该设计成分区表,避免以后磁盘碎片痛点 | |
| 重建表存储引擎,重新组织数据(ALTER TABLE tablename ENGINE=InnoDB;) | 整理过程加锁,周期长,且对线上业务影响较大:10亿数据量,1000G,tp99会持续超过60s | 谨慎操作 | |
| 主从切换(DBA可使用一个磁盘更大的干净的库,进行主从切换) | 涉及面广,牵扯范围较大,处理时长在分钟级 | 谨慎操作 | |
| 创建临时表进行数据双写最后进行数据库表名切换 | 零延迟,无抖动,对线上无任何影响 | 需要磁盘空间较大 |
创建分区表
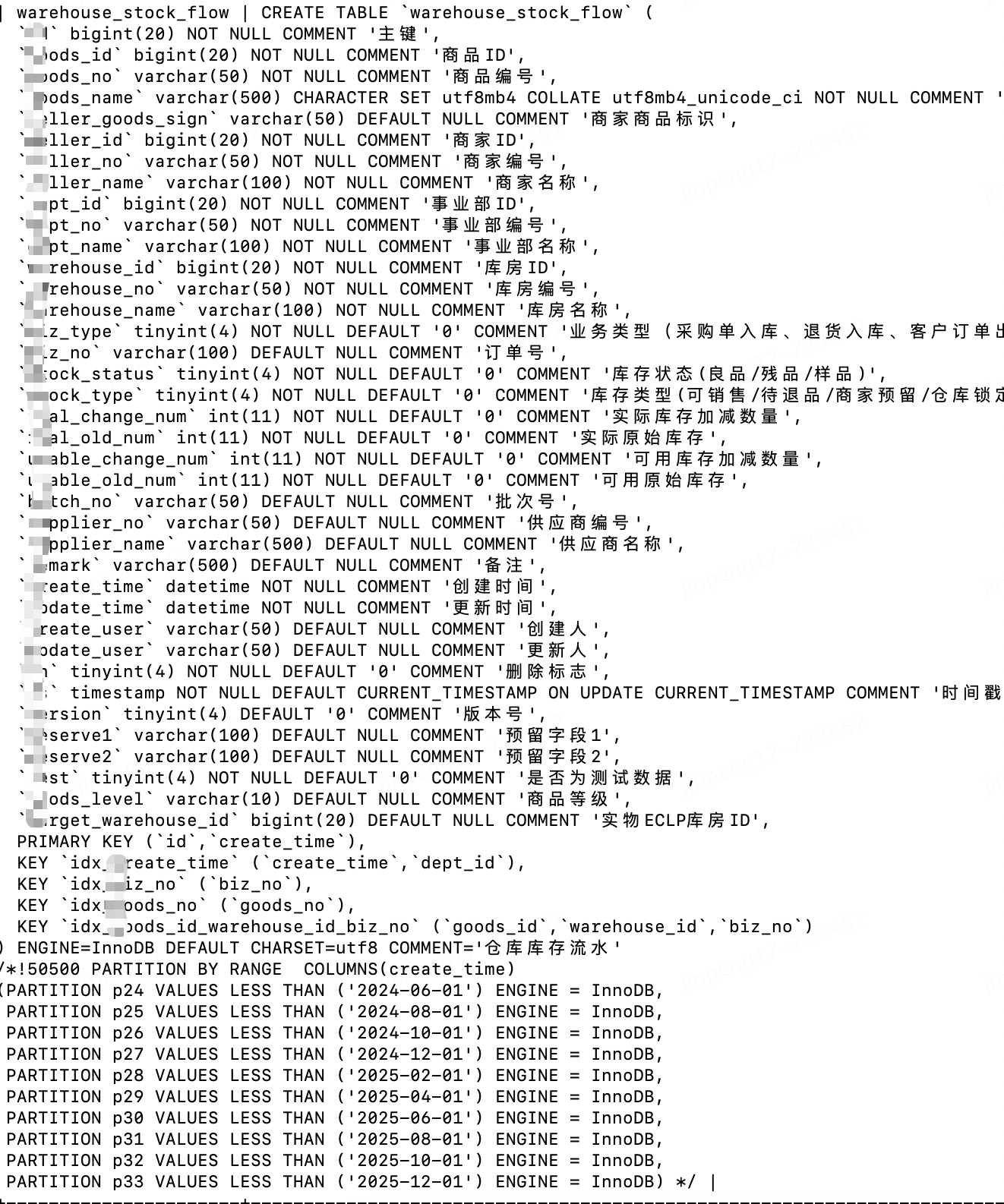
上述分区表,在某一分区内数据结转完成后,
ALTER TABLE warehouse_stock_flow drop PARTITION p24;
当然不是所有的表都是可以创建分区表的。如果某一张数据表在很长一段时间内没有进行数据结转,且无法创建分区表的话,可以利用以下方法。
表名切换
如果某一张数据表在很长一段时间内没有进行数据结转,可以创建临时表,通过大数据将某一结转周期内数据推送至临时表,在代码层面进行数据的双写,最后再通过表名更换的方式进行表名转换。其实,治理磁盘碎片最好的方法就是删除表,不同业务对数据的要求不同。如果有可能的话新建一个临时表。
利用rename语句对数据库表信息进行修改,不会锁表,可以达到零延迟,无抖动,对线上无任何影响。

rename table xx_record to xx_record_temp1,xx_temp to xx_record,xx_record_temp1 to xx_record_temp;
总结
不管是使用云还是商城数据库,只要使用mysql,必然会遇到Mysql碎片问题痛点,数据量大的业务表应该设计成分区表方便磁盘碎片整理,降低维护成本和业务影响。碎片清理前后,IO性能会上升,SQL执行效率更快。所以,在日常运维工作中,应对碎片进行定期清理,保证数据库有稳定的性能和充足的空间。
扩展
提到提高IO性能,在紧急情况下还可以考虑开启刷盘(设置 sync_binlog=0;innodb_flush_log_at_trx_commit=0),但开启刷盘会有数据丢失风险(集团数据库模板配置参数默认sync_binlog=1;innodb_flush_log_at_trx_commit=1)。
附件
mysql数据库核心参数介绍:https://www.cnblogs.com/klvchen/p/10861850.html
标签:结转,record,xx,分区表,mysql,整理,数据,磁盘碎片 From: https://www.cnblogs.com/Jcloud/p/18382834