本次慢sql优化是大促准备时的一个优化,优化4c16g单实例mysql支持QPS从437到4610,今天发文时618大促已经顺利结束,该mysql库和应用在整个大促期间运行也非常稳定。本文复盘一下当时的sql优化过程
1. 问题背景
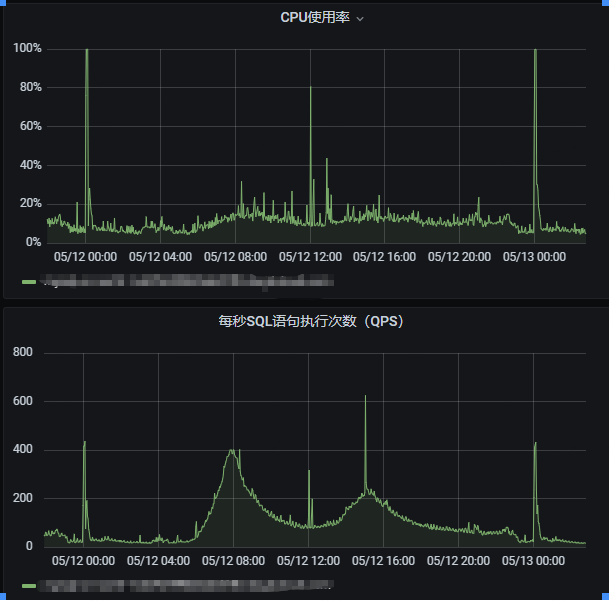
大促准备期间发现4c16G的单实例mysql数据库,每逢流量高峰都会有cpu 100%的问题,集中在0点和12点。
但也存在相近大小的流量cpu利用率相差很大的情况:从图中可见在5.12日0点查询437QPS时cpu利用率达到100%,而5.12日15:02分时 625QPS时CPU利用率不到20%
可见应该是查询语句有差异造成CPU利用率高,而此时并没有慢sql出现。
2. 问题分析
2.1 分析应用请求及日志
通过应用监控看到0点时流量大,很多路由排班表的本地缓存没有命中,导致查询较多。所以想到是否可以通过提高缓存命中率,减少sql查询,以降低CPU利用率。调整缓存大小,和缓存的有效期。经过测试验证仍然没有解决问题
2.2 分析sql
虽然没有慢sql出现,但还是分析了下sql。经分析sql 查询是不是用了索引,发现查询字段也是“走了idx_road_site索引”的(注意这里是引号,其实索引并未完全生效)
表结构及索引如下
CREATE TABLE `road_schedule` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`courier_id` VARCHAR(240) DEFAULT NULL COMMENT 'courier_id',
`courier_name` VARCHAR(240) DEFAULT NULL COMMENT 'courier_name',
`road_id` VARCHAR(240) DEFAULT NULL COMMENT 'road_id',
`site_id` VARCHAR(240) DEFAULT NULL COMMENT 'site_id',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
`ts` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '时间戳',
PRIMARY KEY (`id`),
KEY `idx_road_site` (`road_id` , `site_id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=UTF8代码sql如下:
@Select("select courier_id,courier_name,road_id,site_id from road_schedule where road_id = #{roadId} and site_id = #{siteId} order by id desc limit 1")
RoadScheduleDto getRoadScheduleById(@Param("roadId")String roadId, @Param("siteId")Integer siteId);2.3 分析mysql连接数指标
前两步都没定位到原因,继续分析mysql其他监控指标。
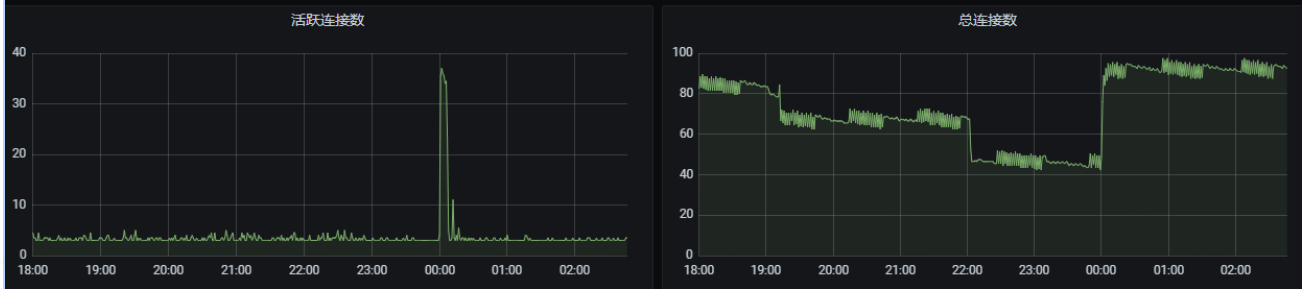
从上图mysql监控发现0点时连接数突增,所以分析是不是有没有提前创建数据库连接。修改应用连接池配置,单应用最少空闲连接为50,应用有4个实例,这样整个数据库连接数在4*50=200个以上,大于图中突增后的总连接数100
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.druid.initial-size=50
spring.datasource.druid.min-idle=50
spring.datasource.druid.max-active=200
spring.datasource.druid.keep-alive=true
spring.datasource.druid.validation-query=select 1
spring.datasource.druid.filters=stat,log4j2但是验证后仍然没有解决问题,就犯难了。但是思考原因可能就上面这三点,却没有解决问题。所以又回过来继续从新分析检查,同时也做好了升级CPU为8核再试的心理准备。
2.4 sql优化--误入歧途--意外暴露问题
再次分析查询语句,怀疑是不是排序的字段没有走索引,所以将sql做了如下调整,并分析了执行计划
#应用中sql
select * from road_schedule where site_id = '19275xxx' and road_id = '02xx' order by ts desc limit 1;
#认为的按id排序更好的sql
select * from road_schedule where site_id = '19275xxx' and road_id = '02xx' order by id desc limit 1;从执行计划看按ts排序 Extra 信息为 Using index condition; Using filesort 猜测按文件排序是不是影响查询的原因
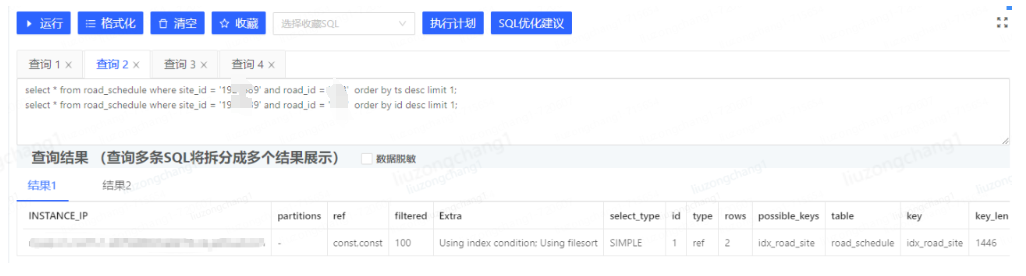
按id排序的执行计划如下,Extra信息为 Using where
对比两个执行计划又都用到了idx_road_site索引,所以猜测按id排序肯定会快一点
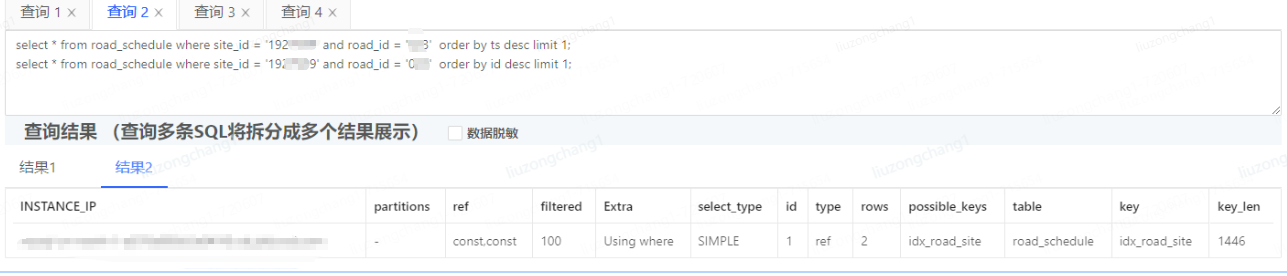
事与愿违,慢sql出现了
从优化建议可以看出按id排序时,优先使用了主键索引,并没有使用idx_road_site索引,所以造成了慢sql。但同时原始sql也显而易见的展现在了眼前,发现组合索引idx_road_site的第二个字段site_id 和表中`site_id` VARCHAR(240) DEFAULT NULL COMMENT '站点id',字段类型并不一致
sql中site_id 传参为整型,表中字段为字符串类型,所以断定是字段类型不一致造成的索引失效
select courier_id,courier_name,road_id,site_id from road_schedule where road_id = 'xxx' and site_id = xxxxx order by id desc limit 1;
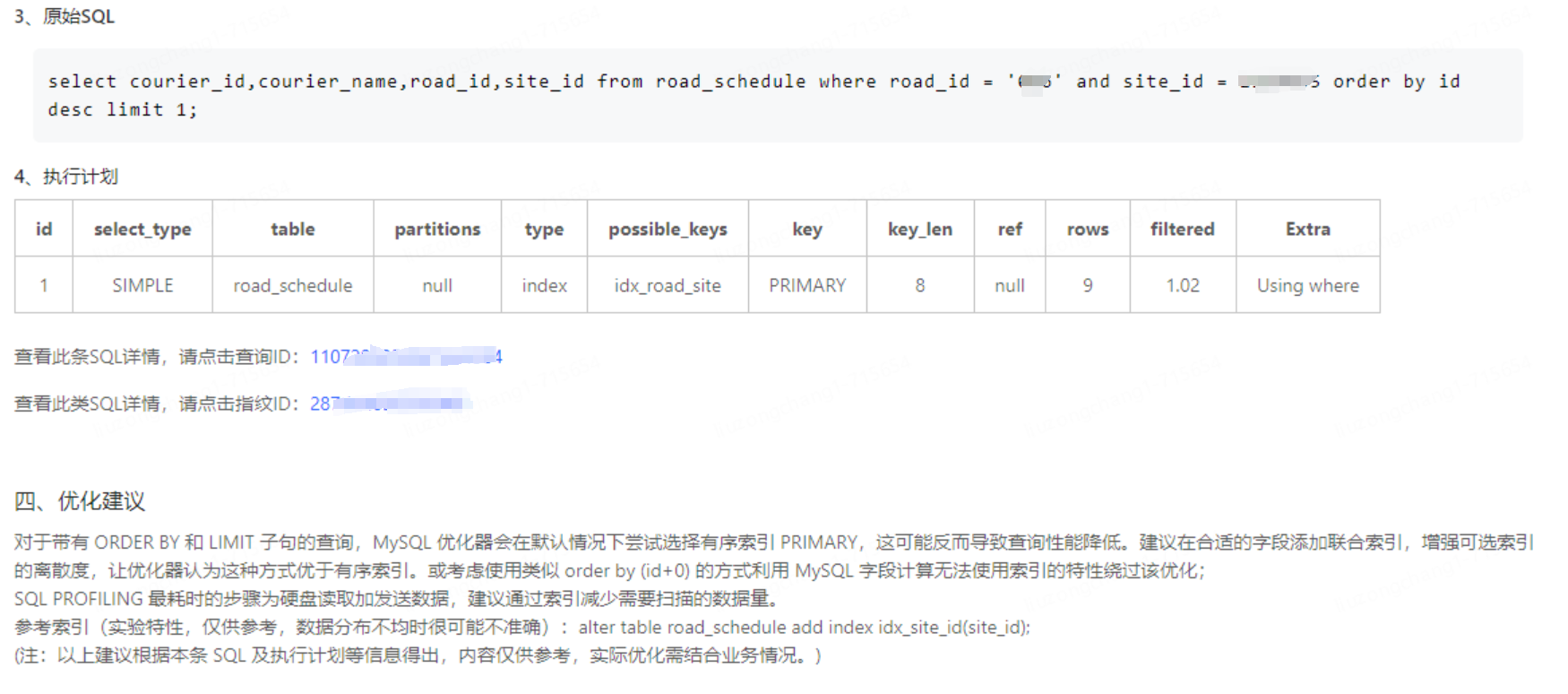
2.5 sql修复验证
上一步已经定位到原因,修复sql如下,siteId传参类型为字符串类型
@Select("select courier_id,courier_name,road_id,site_id from road_schedule where road_id = #{roadId} and site_id = #{siteId} order by ts desc limit 1")
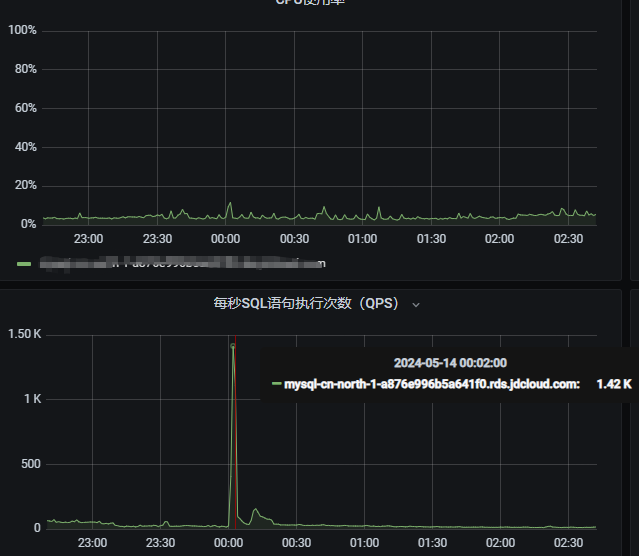
RoadScheduleDto getRoadScheduleById(@Param("roadId")String roadId, @Param("siteId")String siteId);经验证完成,完美解决CPu利用率在0点高的问题。在0点时4c16g数据库实例轻松支持1420QPS 的查询,CPU利用率在20%以下
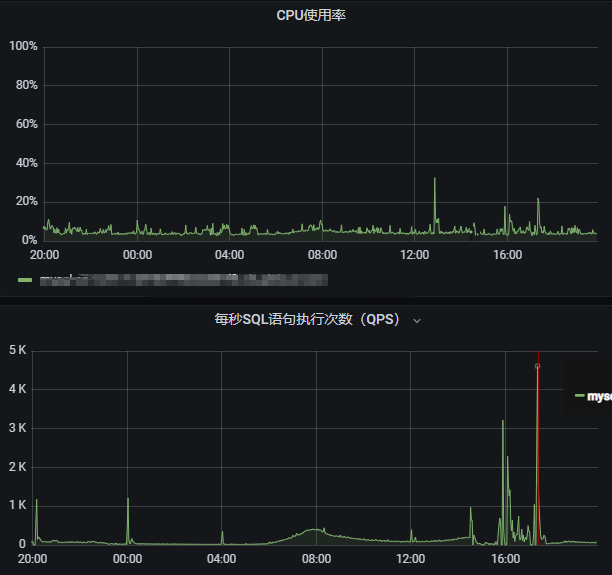
后又观测到4c16g支持4610QPS都没有问题,至此不但优化了SQL,还节约了实例升级带来的机器成本。
3. 总结
总结本次优化经历
•慢sql 往往是影响数据库性能的大瓶颈,sql写好了不但可以优化性能,还能节约机器成本,降本增效。 •最好能看到sql语句执行的第一现场,本次主要是由于查看代码时没有及时注意到索引字段的传参类型不对这一细节,造成花了很多时间分析问题 •虽然整个问题分析过程比较曲折,但问题分析的方向应该还是对的,过程中学到不少知识。 •表结构的设计也有一些历史遗留原因,site_id 字段在表中定义为整型可能比较符合业务含义。表字段定义和业务含义一致,写sql也不容易犯错
欢迎大家评论交流!
标签:COMMENT,10,courier,site,sql,QPS,id,road From: https://www.cnblogs.com/Jcloud/p/18371254