MySQL8.0 Clone Plugin 实现解析浅析
从8.0.17版本开始官方实现了clone的功能,允许用户通过简单的SQL命令把远端/本地的数据库实例拷贝到其他实例后快速拉起一个新的实例。
该功能由一些列的WL组成 :
- Clone local replica(WL#9209) : 实现了数据本地Clone。
- Clone remote replica(WL#9210) : 在本地Clone的基础上,实现了远程Clone。将数据保存到远程的一个目录中,解决跨节点部署MySQL的问题。
- Clone Remote provisioning(WL#11636) : 将数据直接拷贝到需要重新初始化的MySQL实例中。此外这个WL还增加了预检查的功能。
- Clone Replication Coordinates(WL#9211) : 完成了获取和保存Clone点位的功能,方便Clone实例正常的加入到集群中。
- Support cloning encrypted database (WL#9682): 最后一个worklog解决了数据加密情况下的数据拷贝问题。
本文主要初步的介绍 Clone Plugin的原理以及和Xtrabackup的异同,以及整体实现的框架。
1. Xtrabackup备份的不足
在Xtrabackup备份的过程中,可能遇到的最大的问题在于拷贝Redo Log的速度跟不上线上生产Redo Log的速度。因为Redo Log是会循环利用的,当Ck过后旧的Redo Log可能会被新的Redo Log覆盖,而此时如果Xtrabackup没有完成旧的Redo Log的拷贝,那么没法保证备份过程中的数据一致性。
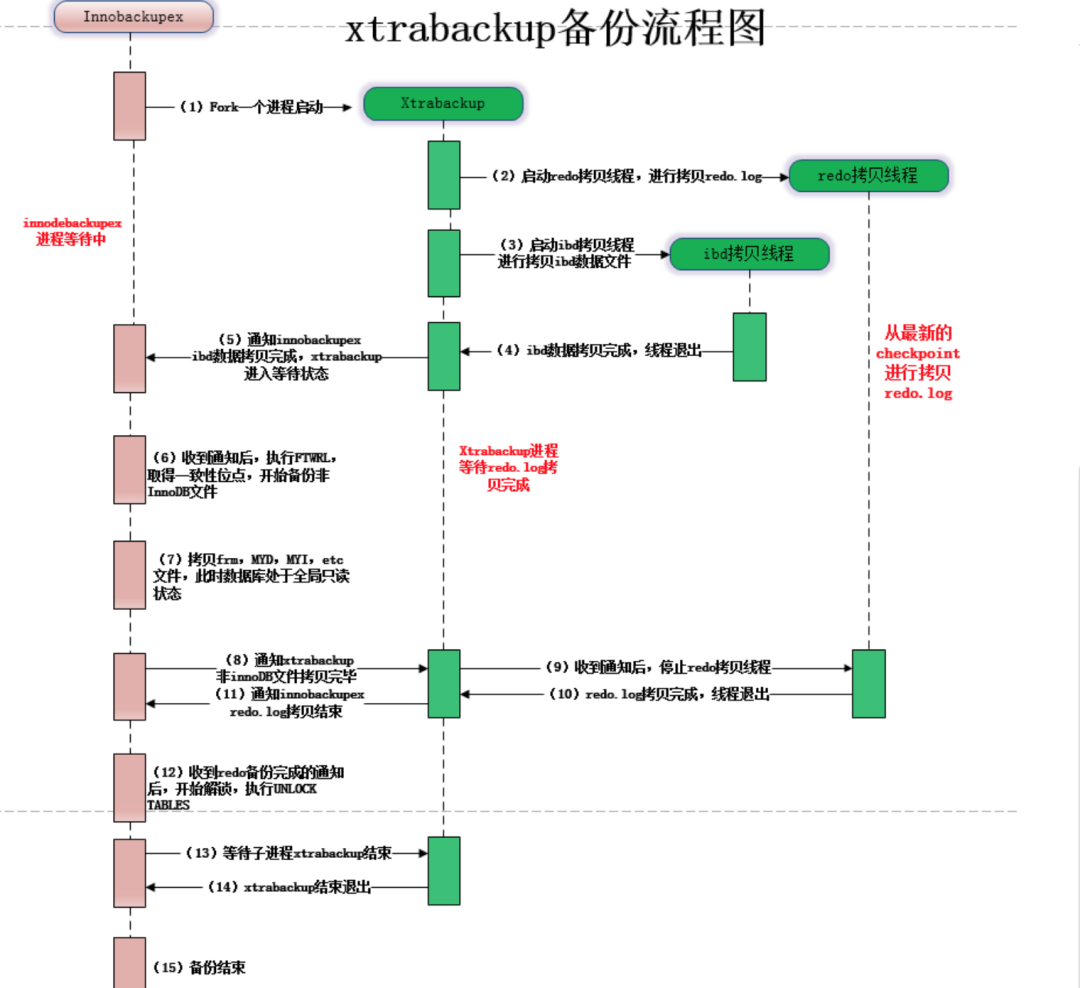
(图片引用出处:https://www.modb.pro/db/28846)
2. Clone 实现的基本原理
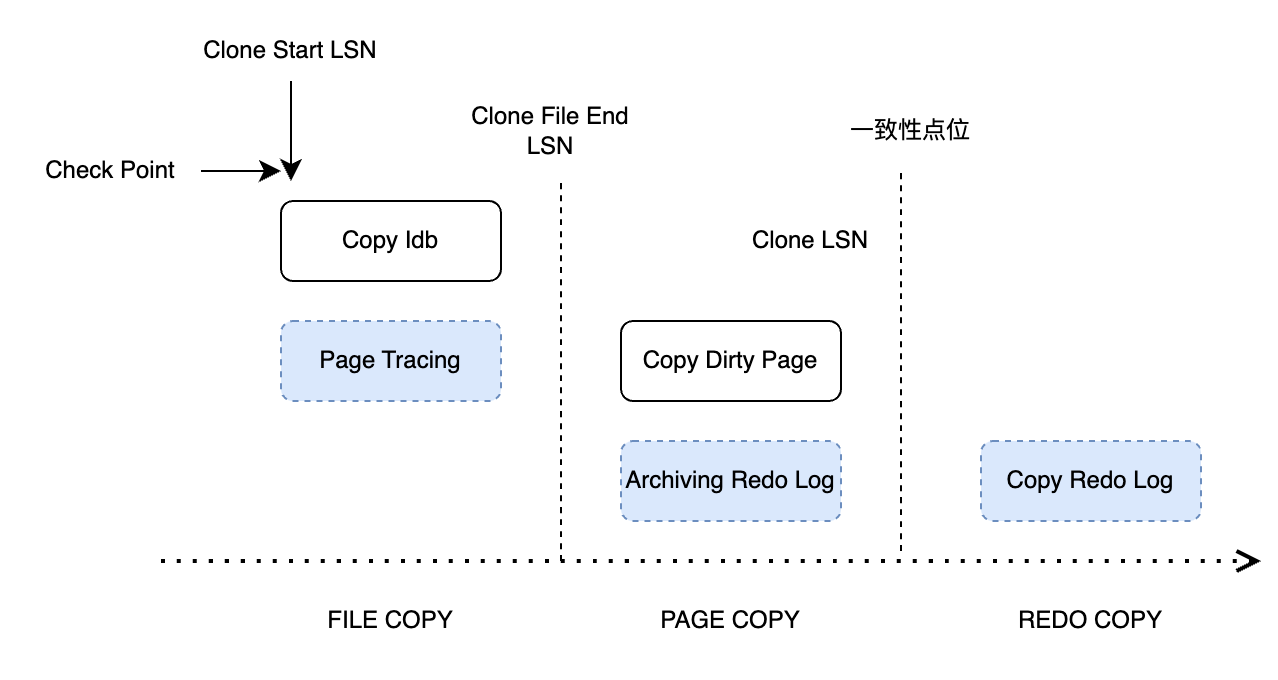
那么在Clone Plugin中如何去解决这个问题? 从WL#9209中可以看到官方整体的设计思路。在完成Clone的过程中将过程分为了5步:
- INIT: The clone object is initialized identified by a locator.
- FILE COPY: The state changes from INIT to "FILE COPY" when snapshot_copy
interface is called. Before making the state change we start "Page Tracking" at
lsn "CLONE START LSN". In this state we copy all database files and send to the
caller.- PAGE COPY: The state changes from "FILE COPY" to "PAGE COPY" after all files are
copied and sent. Before making the state change we start "Redo Archiving" at lsn
"CLONE FILE END LSN" and stop "Page Tracking". In this state, all modified pages
as identified by Page IDs between "CLONE START LSN" and "CLONE FILE END LSN" are
read from "buffer pool" and sent. We would sort the pages by space ID, page ID
to avoid random read(donor) and random write(recipient) as much as possible.- REDO COPY: The state changes from "PAGE COPY" to "REDO COPY" after all modified
pages are sent. Before making the state change we stop "Redo Archiving" at lsn
"CLONE LSN". This is the LSN of the cloned database. We would also need to
capture the replication coordinates at this point in future. It should be the
replication coordinate of the last committed transaction up to the "CLONE LSN".
We send the redo logs from archived files in this state from "CLONE FILE END
LSN" to "CLONE LSN" before moving to "Done" state.- Done: The clone object is kept in this state till destroyed by snapshot_end() call.
这中间最重要的便是 :
- FILE COPY : 跟Xtrabackup一样,会物理的拷贝所有的innodb表空间文件,同时会启动一个Page Tracking进程监控从CLONE START LSN 开始监控所有Innodb PAGE的改动。
- PAGE COPY : PAGE COPY 是在Xtrabackup中没有的一个阶段。主要完成2个工作:
- 在完成数据库库文件拷贝之后,会开启Redo Archiving,同时停止Page Tracking进程(PS开始前会做一次checkpoint)。Redo Archiving 会从指定的lsn位置开始拷贝Redo Log。
- 将Page Tracking记录的脏页发送到指定位置,为了保持高效,会基于spaceid和page id进行排序,尽可能确保磁盘读写的顺序性。
- Redo Copy : 这个阶段,会加锁获取Binlog文件及当前偏移位置和gtid_executed信息并停止Redo Archiving进程。之后将所有归档的Redo Log日志文件发往目标端。
3. 代码结构和调用逻辑
整体实现上分为了三个部分:
- Sql/Server层 :
sql/sql_lex.h
sql/sql_yacc.yy
增加了对clone 语法的支持
sql_admin.cc
增加了客户端处理sql(clone instance)和服务端处理COM_XXX命令
clone_handler.cc
增加调用plugin的具体实现响应sql层处理。
- Plugin插件层
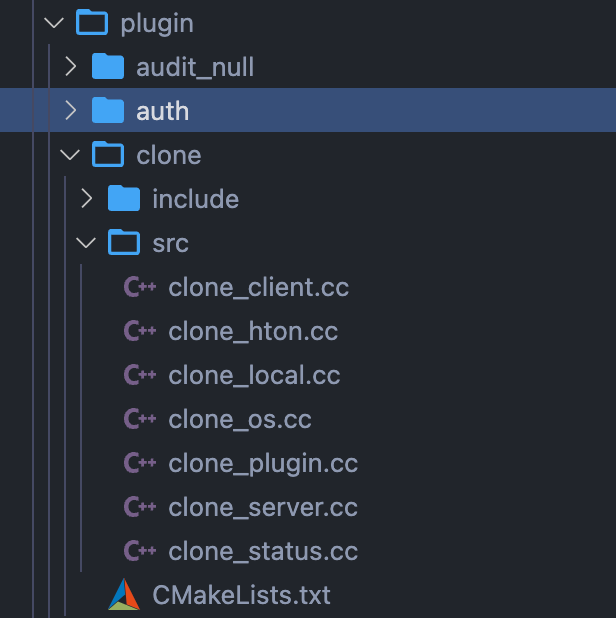
clone_plugin.cc : plugin interface
clone_local.cc : 具体的clone操作
clone_os.cc : 系统层面具体的一些操作函数,包括OS [sendfile/read/write]
clone_hton.cc : 与存储引擎层的接口。
clone_client.cc 和clone_server.cc : clone的客户端和服务端。
clone_status.cc : clone的时候的整体任务的进度和状态。会有一个Clone_Task_Manager去记录状态信息。
clone_plugin.cc : clone插件的入口以及初始化和系统变量等内容。
- Innodb 引擎层
Clone: storage/innobase/clone
clone0clone.cc : clone task and runtime operation
clone0snapshot.cc : snapshot management
clone0copy.cc : copy specific methods
clone0apply.cc : apply specific methods
clone0desc.cc : serialized data descriptor
Archiver: storage/innobase/arch : Page tracing 相关的内容。
arch0arch.cc
arch0page.cc
arch0log.cc
本地Clone的函数调用栈:
Clone_Handle::process_chunk(Clone_Task*, unsigned int, unsigned int, Ha_clone_cbk*) (/mysql-8.0.33/storage/innobase/clone/clone0copy.cc:1440)
Clone_Handle::copy(unsigned int, Ha_clone_cbk*) (/mysql-8.0.33/storage/innobase/clone/clone0copy.cc:1379)
innodb_clone_copy(handlerton*, THD*, unsigned char const*, unsigned int, unsigned int, Ha_clone_cbk*) (/mysql-8.0.33/storage/innobase/clone/clone0api.cc:561)
hton_clone_copy(THD*, std::__1::vector<myclone::Locator, std::__1::allocator<myclone::Locator>>&, std::__1::vector<unsigned int, std::__1::allocator<unsigned int>>&, Ha_clone_cbk*) (/mysql-8.0.33/plugin/clone/src/clone_hton.cc:152)
myclone::Local::clone_exec() (/mysql-8.0.33/plugin/clone/src/clone_local.cc:172)
myclone::Local::clone() (/mysql-8.0.33/plugin/clone/src/clone_local.cc:73)
plugin_clone_local(THD*, char const*) (/mysql-8.0.33/plugin/clone/src/clone_plugin.cc:456)
Clone_handler::clone_local(THD*, char const*) (/mysql-8.0.33/sql/clone_handler.cc:135)
Sql_cmd_clone::execute(THD*) (/mysql-8.0.33/sql/sql_admin.cc:2017)
mysql_execute_command(THD*, bool) (/mysql-8.0.33/sql/sql_parse.cc:4714)
dispatch_sql_command(THD*, Parser_state*) (/mysql-8.0.33/sql/sql_parse.cc:5363)
dispatch_command(THD*, COM_DATA const*, enum_server_command) (/mysql-8.0.33/sql/sql_parse.cc:2050)
do_command(THD*) (/mysql-8.0.33/sql/sql_parse.cc:1439)
handle_connection(void*) (/mysql-8.0.33/sql/conn_handler/connection_handler_per_thread.cc:302)
pfs_spawn_thread(void*) (/mysql-8.0.33/storage/perfschema/pfs.cc:3042)
_pthread_start (@_pthread_start:40)
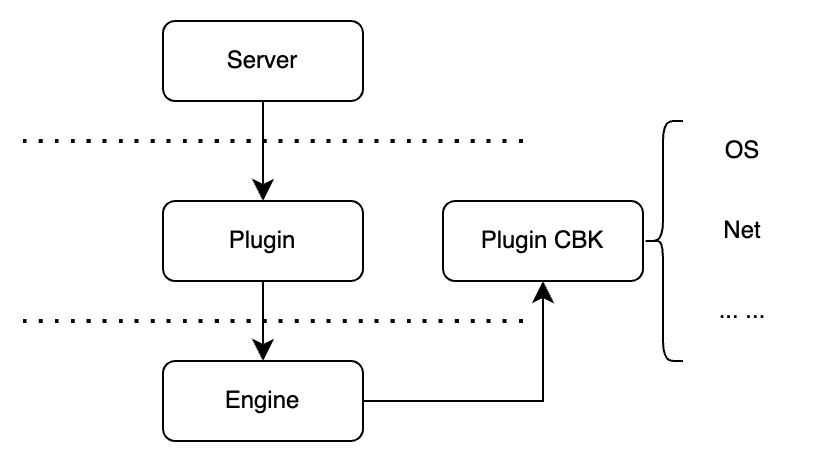
4. Page Archiving 系统
Page Archiving是之前xtrabackup中没有的部分,因此在这里特别介绍下整体实现的过程。
为了减少在Clone过程中的Redo Log的拷贝量,Clone插件中使用了对Dirty Page进行跟踪和收集的方法,在拷贝表空间的过程中追踪Dirty Page,并在File Copy结束的阶段将Dirty Page打包发送到目标端。
Page Tracking脏页监控的方式可以有两种实现方案:
- mtr提交的时候收集。
- 在purge进程刷脏的时候收集。
为了不阻塞MySQL 事务的提交,当前Clone插件选择的是方案2。
Purge进程刷脏的入口是buf_flush_page函数。
buf0flu.cc
if (flush) {
/* We are committed to flushing by the time we get here */
mutex_enter(&buf_pool->flush_state_mutex);
....
arch_page_sys->track_page(bpage, buf_pool->track_page_lsn, frame_lsn,
false);
}
在将脏页刷回到磁盘的时候,会将需要追踪的脏页加入arch_page_sys中。如果在加入脏页的过程中block满了,需要开辟新的空间,会阻塞刷脏的进程。
/** Check and add page ID to archived data.
Check for duplicate page.
@param[in] bpage page to track
@param[in] track_lsn LSN when tracking started
@param[in] frame_lsn current LSN of the page
@param[in] force if true, add page ID without check */
void Arch_Page_Sys::track_page(buf_page_t *bpage, lsn_t track_lsn,
lsn_t frame_lsn, bool force) {
Arch_Block *cur_blk;
uint count = 0;
... ...
/* We need to track this page. */
arch_oper_mutex_enter();
while (true) {
if (m_state != ARCH_STATE_ACTIVE) {
break;
}
... ...
cur_blk = m_data.get_block(&m_write_pos, ARCH_DATA_BLOCK);
if (cur_blk->get_state() == ARCH_BLOCK_ACTIVE) {
if (cur_blk->add_page(bpage, &m_write_pos)) {
/* page added successfully. */
break;
}
/* Current block is full. Move to next block. */
cur_blk->end_write();
m_write_pos.set_next();
/* Writing to a new file so move to the next reset block. */
if (m_write_pos.m_block_num % ARCH_PAGE_FILE_DATA_CAPACITY == 0) {
Arch_Block *reset_block =
m_data.get_block(&m_reset_pos, ARCH_RESET_BLOCK);
reset_block->end_write();
m_reset_pos.set_next();
}
os_event_set(page_archiver_thread_event);
++count;
continue;
} else if (cur_blk->get_state() == ARCH_BLOCK_INIT ||
cur_blk->get_state() == ARCH_BLOCK_FLUSHED) {
ut_ad(m_write_pos.m_offset == ARCH_PAGE_BLK_HEADER_LENGTH);
cur_blk->begin_write(m_write_pos);
if (!cur_blk->add_page(bpage, &m_write_pos)) {
/* Should always succeed. */
ut_d(ut_error);
}
/* page added successfully. */
break;
} else {
bool success;
... ...
/* Might release operation mutex temporarily. Need to
loop again verifying the state. */
success = wait_flush_archiver(cbk);
count = success ? 0 : 2;
continue;
}
}
arch_oper_mutex_exit();
}
脏页收集的整体入口在Page_Arch_Client_Ctx::start 和 Arch_Page_Sys::start。
这里需要注意的是,在开启Page Archiving之前需要强制一次checkpoint,因此如果系统处于比较高的负载(比如IO Wait很高)可能会导致系统卡顿。
int Page_Arch_Client_Ctx::start(bool recovery, uint64_t *start_id) {
... ...
/* Start archiving. */
err = arch_page_sys->start(&m_group, &m_last_reset_lsn, &m_start_pos,
m_is_durable, reset, recovery);
... ...
}
int Arch_Page_Sys::start(Arch_Group **group, lsn_t *start_lsn,
Arch_Page_Pos *start_pos, bool is_durable,
bool restart, bool recovery) {
... ...
log_sys_lsn = (recovery ? m_last_lsn : log_get_lsn(*log_sys));
/* Enable/Reset buffer pool page tracking. */
set_tracking_buf_pool(log_sys_lsn); // page_id
... ...
auto err = start_page_archiver_background(); sp_id, page_id
... ...
if (!recovery) {
/* Request checkpoint */
log_request_checkpoint(*log_sys, true); checkpoint
}
}
脏页的归档由page_archiver_thread线程进行:
/** Archiver background thread */
void page_archiver_thread() {
bool page_wait = false;
... ...
while (true) {
/* Archive in memory data blocks to disk. */
auto page_abort = arch_page_sys->archive(&page_wait);
if (page_abort) {
ib::info(ER_IB_MSG_14) << "Exiting Page Archiver";
break;
}
if (page_wait) {
/* Nothing to archive. Wait until next trigger. */
os_event_wait(page_archiver_thread_event);
os_event_reset(page_archiver_thread_event);
}
}
}
bool Arch_Page_Sys::archive(bool *wait) {
... ...
db_err = flush_blocks(wait);
if (db_err != DB_SUCCESS) {
is_abort = true;
}
... ...
return (is_abort);
}
dberr_t Arch_Page_Sys::flush_blocks(bool *wait) {
... ...
err = flush_inactive_blocks(cur_pos, end_pos);
... ...
}
dberr_t Arch_Page_Sys::flush_inactive_blocks(Arch_Page_Pos &cur_pos,
Arch_Page_Pos end_pos) {
/* Write all blocks that are ready for flushing. */
while (cur_pos.m_block_num < end_pos.m_block_num) {
cur_blk = m_data.get_block(&cur_pos, ARCH_DATA_BLOCK);
err = cur_blk->flush(m_current_group, ARCH_FLUSH_NORMAL);
if (err != DB_SUCCESS) {
break;
}
... ...
}
return (err);
}
在最后会调用Arch_Block去归档脏页。这里当把脏页归档的时候也需要使用doublewrite buffer。
/** Flush this block to the file group.
@param[in] file_group current archive group
@param[in] type flush type
@return error code. */
dberr_t Arch_Block::flush(Arch_Group *file_group, Arch_Blk_Flush_Type type) {
... ...
switch (m_type) {
case ARCH_RESET_BLOCK:
err = file_group->write_file_header(m_data, m_size);
break;
case ARCH_DATA_BLOCK: {
bool is_partial_flush = (type == ARCH_FLUSH_PARTIAL);
/* Callback responsible for setting up file's header starting at offset 0.
This header is left empty within this flush operation. */
auto get_empty_file_header_cbk = [](uint64_t, byte *) {
return DB_SUCCESS;
};
/* We allow partial flush to happen even if there were no pages added
since the last partial flush as the block's header might contain some
useful info required during recovery. */
err = file_group->write_to_file(nullptr, m_data, m_size, is_partial_flush,
true, get_empty_file_header_cbk);
break;
}
default:
ut_d(ut_error);
}
return (err);
}
dberr_t Arch_Group::write_to_file(Arch_File_Ctx *from_file, byte *from_buffer,
uint length, bool partial_write,
bool do_persist,
Get_file_header_callback get_header) {
... ...
if (do_persist) {
Arch_Page_Dblwr_Offset dblwr_offset =
(partial_write ? ARCH_PAGE_DBLWR_PARTIAL_FLUSH_PAGE
: ARCH_PAGE_DBLWR_FULL_FLUSH_PAGE);
/** Write to the doublewrite buffer before writing archived data to a file.
The source is either a file context or buffer. Caller must ensure that data
is in single file in source file context. **/
Arch_Group::write_to_doublewrite_file(from_file, from_buffer, write_size,
dblwr_offset);
}
... ...
return (DB_SUCCESS);
}
5. 总结
- 相对于使用Xtrabackup拉起一个Slave,Clone功能更加的方便。
- 相对于Xtrabackup,Clone的拷贝的Redo Log 日志量更少,也更不容易遇到失败的问题(arch_log_sys会控制日志写入以避免未归档的日志被覆盖)。
- 从源码的分析来看,启动Clone的时候会强制做一次CK,在Redo Log Archiving的时候会控制日志写入量,因此从原理上看,如果处于高负载的主库做Clone操作,可能会对系统有影响。
6. 参考文献
- MySQL · 引擎特性 · 初探 Clone Plugin : http://mysql.taobao.org/monthly/2019/09/02/
- MySQL:插件回调的方式 : https://greatsql.cn/blog-74-1158.html
- MySQL · 引擎特性 · clone_plugin: http://mysql.taobao.org/monthly/2019/08/05/
- 技术分享 | 实战 MySQL 8.0.17 Clone Plugin : https://opensource.actionsky.com/20190726-mysql/
- 全网最完整的 MySQL Clone Plugin 实现原理解析 : https://zhuanlan.zhihu.com/p/433606318
- MySQL/InnoDB数据克隆插件(clone plugin)实现剖析 : https://sq.sf.163.com/blog/article/364933037836570624
- MySQL 8 新特性之Clone Plugin : https://www.cnblogs.com/ivictor/p/13818440.html