目录
Redis持久化方式
通常两者结合一起使用
方式一:RDB
RDB全称Redis数据备份文件,也叫作Redis数据快照。简单的说就是把内存中的数据都记录到磁盘
1、实现命令
- 手动
save # 由Redis主进程执行,会阻塞所有命令
bgsave # 开启子进程执行,避免影响主进程
- 配置文件 redis.conf
save 100 1 # 指100秒内至少有一个key被修改时,则执行RDB备份
2、RDB执行原理
RDB执行时会从主进程fork一个子进程,子进程共享主进程的内存空间,实际上是复制了主进程的页表,因此子进程就可以读取内存中的数据到RDB文件中。
fork采用的是copy-on-write技术:
主进程读时,访问共享空间
主进程写时,复制一份副本,再进行写操作
方式二:AOF
AOF全称追加文件,Redis处理的每一个写命令都会记录在AOF文件中
1、开启AOF模式
默认关闭,开启需在redis.conf文件中进行配置:
appendonly=yes,
appendfilename="aofile.aof"
2、AOF记录的频率(又称刷盘策略)
在redis.conf文件中配置:
appendfsync always# 每执行一次写命令,立即写入AOF文件
appendfsync everysec(默认) # 写命令执行完先放入缓冲区,每隔1秒从缓冲区写入AOF文件
appendfsync no# 写命令执行完先放入缓冲区,由操作系统决定何时写入AOF文件
3、命令重写
由于AOF是记录命令,通常空间占用会高的多,可以使用
命令重写的策略来缩小文件体积,在redis.conf文件中配置如下:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
两种持久化方式对比

Redis数据过期策略
主要有
惰性删除和定时删除两种,定时删除又分为两种模式:SLOW和FAST模式通常两者结合一起使用
1、惰性删除
当key过期后,不立即删除,而是等到需要使用该key时,再进行检查并删除过期key
优点:对CPU友好
缺点:过期key积累对内存占用不友好
2、定时删除
每隔一段时间,就随机的对一些key进行检查,并删除过期key
SLOW:SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的hz选项来调整这个次数
FAST:FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
Redis数据淘汰策略
LRU: 最近最少使用算法。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高
LFU: 最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高redis提供了8中数据淘汰策略:
- noeviction
默认策略,不淘汰任何key,但是内存满时不允许写入新数据,并且会直接报错
- allkeys-lru
对全体key,基于LRU算法进行淘汰
- volatile-lru
对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu
对全体key,基于LFU算法进行淘汰
- 对设置了TTL的key,基于LFU算法进行淘汰
分布式锁
使用redisson集成的分布式锁有三大好处:
- 提供watchdog监控执行线程,可实现
锁自动续期,默认10秒一次- 其他线程想要加锁,会进行一定次数的
阻塞循环等待- 底层基于
LUA脚本,实现了原子操作可重入,在redis中进行存储的时候使用的hash结构,来存储线程信息和重入的次数,多个锁重入需要判断是否是当前线程,主要是根据线程ID进行判断缺点:
不能实现
主从一致性解决方案:
红锁,缺点是会导致性能变低- 采用
zonkeeper实现的CP思想的分布式锁

代码实现:
// 1.构造redisson实现分布式锁必要的Config
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:5379").setPassword("123456").setDatabase(0);
// 2.构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 3.获取锁对象实例(无法保证是按线程的顺序获取到)
RLock rLock = redissonClient.getLock(lockKey);
try {
/**
* 4.尝试获取锁
* waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败
* leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)
*/
boolean res = rLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);
if (res) {
//成功获得锁,在这里处理业务
}
} catch (Exception e) {
throw new RuntimeException("aquire lock fail");
}finally{
//无论如何, 最后都要解锁
rLock.unlock();
}
如何保证Redis的高并发高可用
一、高并发
要想提高redis的并发能力,就需要搭建
主从集群,实现读写分离,主节点用于写操作,从节点用于读操作

主从数据同步
从节点第一次与主节点建立连接时使用
全量同步


二、高可用
如果只是单纯的主从集群模式,并不能保证Redis的高可用性,因此Redis提供了一种保证高可用的
哨兵机制,来实现主从集群的自动故障恢复哨兵机制的三大特点:
- 监控:Sentinel会不断检查master和slave是否按预期工作,Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端以连接新的master
哨兵模式结构:

脑裂问题
使用哨兵模式时,当master网络卡顿时,选取了一个从节点作为主节点,但是旧的master在网络恢复后处理了之前的写操作,更新了数据,而新master为了同步从节点的数据,把老master的数据清空了,从而导致数据丢失,这种就叫做
脑裂问题
- 解决方法
只需要在redis配置文件中配置
min-replicas-to-write 1 # 表示最少的salve节点为1个
min-replicas-max-lag 5 # 表示数据复制和同步的延迟不能超过5秒
三、分片集群
前面主从哨兵模式解决了高并发高可用的问题,但是仍有两个问题没有解决
:
海量数据存储问题
高并发写的问题
使用分片集群可以解决上述问题,分片集群特征
:
集群中有多个master,每个master保存不同数据
每个master都可以有多个slave节点
master之间通过ping监测彼此健康状态
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
PS:Redis 分片集群引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
Redis是单线程,为什么还能这么快
原因很简单:
Redis是纯内存操作,执行速度非常快,并且基于C语言实现
采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
使用I/O多路复用模型,非阻塞IO
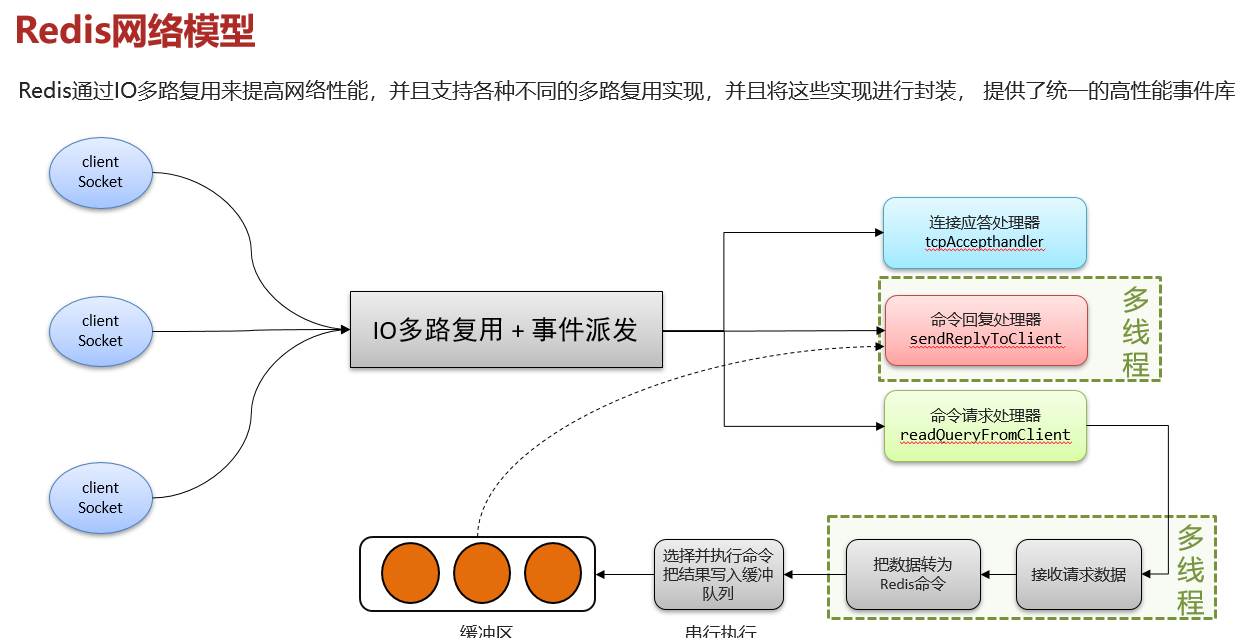
四、Redis网络模型