##sample 1 文章1 OceanBase 慢查询排查思路
https://open.oceanbase.com/blog/4030499840?_gl=1*1muepo8*_ga*MTg4MDgzMzI3Mi4xNzE1NDE3MjEw*_ga_T35KTM57DZ*MTcxNTg0MDQ3OS4xMi4xLjE3MTU4NDU2NTkuNjAuMC4w
本文汇总了项目实践中前辈的经验和笔者的理解,旨在帮助初学 OceanBase(以下简称 OB)的工程师,快速解决 SQL 执行缓慢等性能问题。当遇到性能问题时,很多工程师可能会感到无从下手,本文将根据关键日志提供多种分析方向,以加速问题排查。
作者:任仲禹
爱可生 DBA 团队成员,擅长故障分析和性能优化,文章相关技术问题,欢迎大家一起讨论。
背景
应用连接 OB 的生产架构,一般有两种:
- 应⽤ → OBProxy → OBServer
- 应⽤ → OBProxy-Sharding → OBServer
前者是大多数客户使⽤场景,后者是少数客户使⽤的单元化架构场景,后文将 OBProxy 和 OBProxy-Sharding 统称为 ODP(OceanBase Database Proxy)。
当我们发现某条语句耗时较长时,我们需要排查的点有:应⽤到 ODP 的⽹络时间、ODP 的执行时间、ODP 到 OBServer 的⽹络时间、OBServer 的执行时间。
从哪些信息入手?
要诊断哪部分时间消耗长,以及原因是什么,大多数情况会从如下几个组件获取信息。
ODP 组件
- obproxy_digest.log:审计⽇志,记录执⾏失败的 SQL 语句、执行时间大于参数
query_digest_time_threshold阈值(默认是 2ms)请求。 - obproxy_slow.log:慢 SQL 请求日志,记录执⾏时间大于参数
slow_query_time_threshold阈值(默认是 500ms)的请求。 - obproxy.log:ODP 总日志。
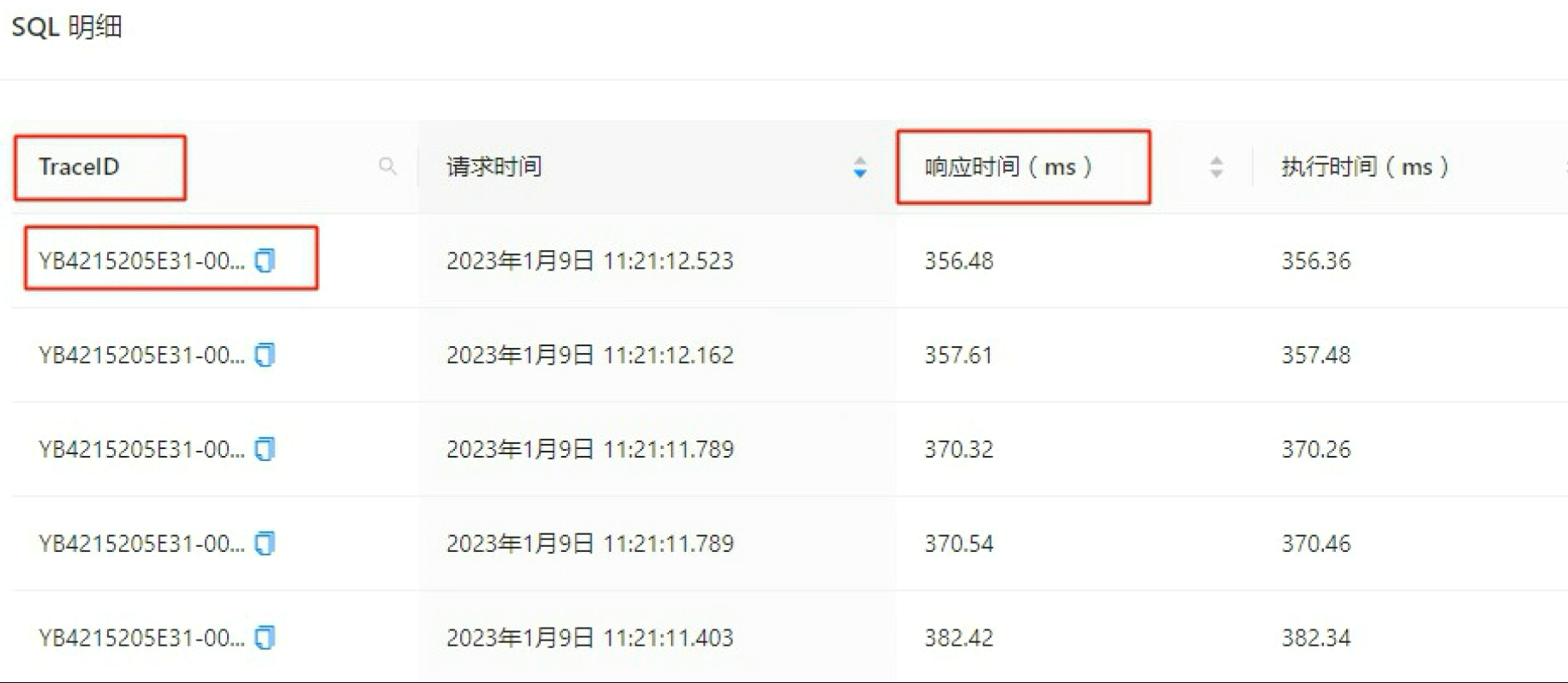
在 obproxy_digest.log 和 obproxy_slow.log 中,第 15、16、17、18 列(即 8353us,179us,0us,5785us)分别表示:ODP 处理总时间、ODP 预处理时间、ODP 获取连接时间、OBServer 执⾏时间。示例如下:
2023-05-04
16:46:03.513268,test_obproxy,,,,test:ob_mysql:sbtest,OB_MYSQL,sbtest1,sbtest1,COM_QUERY
,SELECT,failed,1064,select t1.*%2Ct2.* from sbtest1 t1%2Csbtest2 t2 where t1.id = t2.id
where id <10000,8353us,179us,0us,5785us,Y0-7FA25BB4A2E0,YB420ABA3FAC-0005FA2415BE0F81-
0-0,,,0,10.186.63.172:2881
- ODP 处理总时间的起点:ODP 接收到客户端请求的时间;
- ODP 处理总时间的终点:ODP 把所有的数据都写回给客户端;
- ODP 预处理时间:包含去
oceanbase.__all_virtual_proxy_schema查询 Leader 的时间; - ODP 获取连接时间:目前不做记录,看到的都是 0;
- OBServer 执行时间:起点是 ODP 发送请求给 OBServer,终点是收到 OBServer 返回第一条记录。
从上面的原理可以看出,后三项时间相加并不等于第一项时间,比如 ODP 处理总时间比较长,但是预处理时间和 OBServer 执行时间都很短,有可能时间消耗在 OBServer 将第一条记录返回给 ODPServer 和 ODPServer 把所有数据写回给客户端之间,这在结果集较大的 SQL 语句中⽐较常⻅。
OBserver 组件
- gv$audit_sql:该视图⽤于展示所有 OBServer 上每⼀次 SQL 请求的来源、执⾏状态等统计信息。
该视图是按照租户拆分的,除了系统租户,其他租户不能跨租户查询。⼀般常⽤的字段有:request_time,sql_id,plan_id,plan_type,trace_id,svr_ip,client_ip,user_client_ip,user_name,db_name,elapsed_time,queue_time,get_plan_time,execute_time,retry_cnt,table_scan,ret_code,query_sql……
# 大致的归类如下
标识信息:tenant_id,sql_id,trace_id,plan_id ,sid,transaction_hash,......
来自哪⾥:user_name,user_client_ip,client_ip(OBProxy) ,......
在哪执行:svr_ip,db_name,plan_type, ......
开始时间:request_time
执行耗时:elapsed_time,get_plan_time,execute_time ,......
等待耗时:total_wait_time_micro,queue_time,net_time,user_io_wait_time,......
数据扫描:table_scan(全表扫描),disk_reads,memstore_read_row_count,sstable_read_row_count ,......
并行执行:expected_worker_count,used_worker_count, qc_id,sqc_id,worker_id ,......
请求类型:request_type, ......
强弱读:consistency_level
数据量:affected_rows,return_rows,partition_cnt,......
返回码:ret_code
- observer.log:OBServer 运行的主要⽇志,这里面的信息非常全面,外部用户不易解读,很多情况下会根据
trace_id去搜索,例如通过 OCP 的 SQL 诊断功能获取到TraceID,再进⾏查询。
常见 OB 慢查询分析思路
1. ODP 给应用回写数据耗时长
当 SQL 的结果集很大,ODP 就需要较长时间将数据返回给应用,这时候会发现 OBServer 执行时间和 ODP 预处理时间相加,比 ODP 执行总时间要小,以下面的 obproxy.log 记录为例:
[2023-04-19 19:12:31.662602] WARN [PROXY.SM] update_cmd_stats (ob_mysql_sm.cpp:8633)
[5628][Y0-7F820F6C7960] [lt=38] [dc=0] Slow Query: ((client_ip={x.x.x.x:51555},
server_ip={x.x.x.x:2881}, obproxy_client_port={x.x.x.x:33584},
server_trace_id=YB420A97B009-0005F6EF28FSFS11-0-0, route_type=ROUTE_TYPE_LEADER,
user_name=depo, tenant_name=su, cluster_name=cmcluster, logic_database_name=,
logic_tenant_name=, ob_proxy_protocol=0, cs_id=1077902,
proxy_sessid=1513983664671181892, ss_id=611834, server_sessid=3221841415, sm_id=260155,
cmd_size_stats={client_request_bytes:87, server_request_bytes:122,
server_response_bytes:0, client_response_bytes:185002181}, cmd_time_stats=
{client_transaction_idle_time_us=0, client_request_read_time_us=11,
client_request_analyze_time_us=10, cluster_resource_create_time_us=0,
pl_lookup_time_us=4, pl_process_time_us=4, congestion_control_time_us=1,
congestion_process_time_us=0, do_observer_open_time_us=2, server_connect_time_us=0,
server_sync_session_variable_time_us=0, server_send_saved_login_time_us=0,
server_send_use_database_time_us=0, server_send_session_variable_time_us=0,
server_send_all_session_variable_time_us=0, server_send_last_insert_id_time_us=0,
server_send_start_trans_time_us=0, build_server_request_time_us=2,
plugin_compress_request_time_us=0, prepare_send_request_to_server_time_us=65,
server_request_write_time_us=20, server_process_request_time_us=337792,
server_response_read_time_us=2353609, plugin_decompress_response_time_us=1299449,
server_response_analyze_time_us=17505, ok_packet_trim_time_us=0,
client_response_write_time_us=1130104, request_total_time_us=5309727}, sql=SELECT x,x,x
FROM sbtest.sbtest1 where id =1)
client_response_bytes:185002181client_response_write_time_us=1130104
该示例中,ODP 回写给应用的数据为 185MB,耗时 1.1s,可以通过该信息观测下是否是 SQL 的结果集较大。
2. ODP 获取 location cache 慢
ODP 要把 SQL 路由到准确的 OBServer 上,只需要知道每个 Table 的 Partition 的 Leader 所在位置,获取位置的过程叫做 “get location cache”。通常这个过程很快,并且获取后会缓存在本地,少数情况下,这个时间消耗会慢,以下面为例:
[2023-05-07 00:01:04.506809] WARN [PROXY.SM] update_cmd_stats (ob_mysql_sm.cpp:8607)
[363][Y0-7F4521AA21A0] [lt=28] [dc=0] Slow Query: ((client_ip={x.x.x.x:36246},
server_ip={x.x.x.x:2881}, obproxy_client_port={21.2.1
92.29:40556}, server_trace_id=, route_type=ROUTE_TYPE_LEADER, user_name=mY14OyQ1tF,
tenant_name=bu06, cluster_name=cscluster2, logic_database_name=budb,
logic_tenant_name=odp-h170kfw30w7l, ob_proxy_protocol=2, cs_id=2993079,
proxy_sessid=1513983656080750373, ss_id=53737247, server_sessid=3223571471,
sm_id=44290320, cmd_size_stats={client_request_bytes:342, server_request_bytes:385,
server_response_bytes:66, client_response_bytes:66}, cmd_time_stats=
{client_transaction_idle_time_us=0, client_request_read_time_us=25,
client_request_analyze_time_us=25, cluster_resource_create_time_us=0,
pl_lookup_time_us=4998993, pl_process_time_us=126, congestion_control_time_us=2,
congestion_process_time_us=0, do_observer_open_time_us=5, server_connect_time_us=0,
server_sync_session_variable_time_us=0, server_send_saved_login_time_us=0,
server_send_use_database_time_us=0, server_send_session_variable_time_us=0,
server_send_all_session_variable_time_us=0, xxxxxxxx
pl_lookup_time_us=4998993
耗时 4s 明显有异常,获取到该日志后可以快速和 OB 研发缩小问题排查范围。
3. 表的路由选择
在 OceanBase 数据库中,有 Local 计划、Remote 计划和 Distributed 计划三种表路由。Local 计划、Remote 计划均为单分区的路由。ODP 的作⽤就是尽量消除 Remote 计划,将路由尽可能的变为 Local 计划。
如果表路由类型为 Remote 计划的 SQL 过多,则表示该 SQL 性能可能不是最优,通常的原因有 ODP 路由问题、无法计算表分区 ID、使用了全局索引、需要开启二次路由等等。
通过 gv$sql_audit 的 PLAN_TYPE 字段可以判断 SQL 的执行计划类型:
- 1:Local
- 2:Remote
- 3:Distributed
4. OBServer 写入限速
当 memstore 已使⽤的内存达到 writing_throttling_trigger_percentage 时(默认 100),触发写入限速。当该配置项的值为 100 时,表示关闭写入限速机制。在触发写入限速后,剩余 memstore 内存必须保证在writing_throttling_maximum_duration(默认 1h)内不会分配完,也就是写入速度上限为 memstore * (1- writing_throttling_trigger_percentage) / writing_throttling_maximum_duration。
通过监控 gv$memstore 可以知道 memstore 使用的百分比。当发生了写入限速,observer.log 中会看到如下记录:
[2023-04-10 10:52:09.076066] INFO [COMMON] ob_fifo_arena.cpp:301 [68425][1739]
[YB420A830ADF-00058B41370AAF4F] [lt=85] [dc=0] report write throttle
info(cur_mem_hold=162644623360, throttle_info_={decay_factor_:"0.000000005732",
alloc_duration_:2400000000, trigger_percentage_:70, memstore_threshold_:231928233960,
period_throttled_count_:140, period_throttled_time_:137915965,
total_throttled_count_:23584, total_throttled_time_:27901629728})
关键字:report,write,throttle,info
还有⼀种场景就是发现 QPS 异常下降时(尤其是包含⼤量写⼊,可以通过查询系统表的⽅式确认是否是由于写⼊限速导致。
select * from v$session_event where EVENT='memstore memory page alloc wait' \G;
*************************** 94. row ***************************
CON_ID: 1
SVR_IP: x.x.x.x
SVR_PORT: 22882
SID: 3221487713
EVENT: memstore memory page alloc wait
TOTAL_WAITS: 182673
TOTAL_TIMEOUTS: 0
TIME_WAITED: 1004.4099
AVERAGE_WAIT: 0.005498403704981032
MAX_WAIT: 12.3022
TIME_WAITED_MICRO: 10044099
CPU: NULL
EVENT_ID: 11015
WAIT_CLASS_ID: 109
WAIT_CLASS#: 9
WAIT_CLASS: SYSTEM_IO
关键字:memstore,memory,page,alloc,wait
5. 访问执行计划
访问计划也是影响 SQL 耗时的⼀个因素,没有命中 plan cache、访问计划发生了预期外的变化都会造成 SQL 执行变慢。
没有命中 plan cache 可以在 gv$sql_audit 中看到 IS_HIT_PLAN=0。
要查看 SQL 具体的执行计划有两种⽅式:一是执行 explain extended <query_sql>,但这只能看到当前环境下,该语句的执行计划,可能并不是现场缓慢 SQL 的执行计划,需要查看缓慢 SQL 正在使用的访问计划,需要首先记录下 gv$sql_audit 中的四个值:SVR_IP,SVR_PORT,TENANT_ID,PLAN_ID。并在 gv$plan_cache_plan_explain中进行查询:
select SVR_IP, SVR_PORT, TENANT_ID, PLAN_ID from gv$sql_audit where query_sql ...
select * from gv$plan_cache_plan_explain where ip=<SVR_IP> and port=<SVR_PORT> and
tenant_id=<TENANT_ID> and plan_id=<PLAN_ID>
6. OBServer 锁等待
OceanBase 选择 MVCC 来实现事务并发性和一致性,支持读写不互斥。因此事务间的锁等待一般发生在写请求上(lock_for_write),极少情况下也会发生在读请求(lock_for_shared)。
当发生了锁等待,SQL执⾏耗时也会变长,通常的表现是:在 gv$sql_audit 中看到 elapsed_time 较大,execute_time 较小,retry_cnt 较大(>0),伴随 observer.log 可以观察到如下日志:
[2023-03-29 12:00:26.310172] WARN [STORAGE.TRANS] on_wlock_retry
(ob_memtable_context.cpp:393) [135700][2338][Y1312AC1C4140-0005EFC759EADC21] [lt=10]
[dc=0] lock_for_write conflict(*this=alloc_type=0 ctx_descriptor=700817166
trans_start_time=1680062426310071 min_table_version=1679627152331552
max_table_version=1679627152331552 is_safe_read=false has_read_relocated_row=false
read_snapshot=1680062426310007 start_version=-1 trans_version=9223372036854775807
commit_version=0 stmt_start_time=1680062426310074 abs_expired_time=1680062436209982
stmt_timeout=9899908 abs_lock_wait_timeout=1680062436209982 row_purge_version=0
lock_wait_start_ts=0 trx_lock_timeout=-1 end_code=0 is_readonly=false ref=2 pkey=
{tid:1116004302242691, partition_id:0, part_cnt:0} trans_id={hash:4021727895899886621,
inc:669379877, addr:"172.28.65.64:4882", t:1680062426310046} data_relocated=0
relocate_cnt=0 truncate_cnt=0 trans_mem_total_size=0 callback_alloc_count=0
callback_free_count=0 callback_mem_used=0 checksum_log_ts=0,
key=table_id=1116004302242691 rowkey_object=[{"BIGINT":2024021}] ,
conflict_ctx="alloc_type=0 ctx_descriptor=700817301 trans_start_time=1680062426309892
xx
- 关键字:lock_for_write,conflict
7. SQL 语句有问题
一般 SQL 语句查询慢排除上述问题后,大部分跟自身有关,例如 SQL 语句没有走到索引、写法有问题等。这种情况就需要:
- 通过
gv$sql_audit表或 ODP 日志拿到具体的 SQL 文本。
# 查询以某个租户⼀段范围内执⾏耗时的SQL语句进⾏排序
SELECT usec_to_time(request_time) as request_time,
sql_id, plan_id, plan_type, trace_id,
svr_ip, client_ip, user_client_ip, user_name, db_name elapsed_time, queue_time,
get_plan_time, execute_time, retry_cnt, table_scan,
ret_code,
query_sql
FROM gv$sql_audit
WHERE tenant_id=1001
AND request_time BETWEEN time_to_usec('2023_05_12 13:00:00')
AND time_to_usec('2023_05_13 13:10:00') AND is_executor_rpc = 0
ORDER BY elapsed_time DESC limit 10;
2. 拿到 SQL 文本后,再通过 Explain 查询计划进⾏分析(例如对下文语句进⾏ Explain 分析,比如 name 中只有表名不包含索引列的话,则该 SQL 语句可能使用的主键或全表扫描)。
obclient [sbtest]> explain select * from sbtest1 where k like '%111181823%' \G
*************************** 1. row ***************************
Query Plan: ========================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
----------------------------------------
|0 |TABLE SCAN|sbtest1|283098 |333648|
========================================
Outputs & filters:
-------------------------------------
0 - output([sbtest1.id], [sbtest1.k], [sbtest1.c], [sbtest1.pad]),
filter([(T_OP_LIKE, cast(sbtest1.k, VARCHAR(1048576)), '%111181823%', '\\')]),
access([sbtest1.k], [sbtest1.id], [sbtest1.c], [sbtest1.pad]), partitions(p0)
1 row in set (0.004 sec)
3. 排查 SQL 成本和执行计划中访问顺序是否有问题,就不具体展开了。
以上就是导致 OB 慢查询常见的原因及分析思路,希望对读者有所帮助。
##sample 2
OceanBase 4.1.0 clog 目录探究
https://open.oceanbase.com/blog/5203648257
于OceanBase 4.x 版本如何统计租户每日 clog 日志生成量的背景下,探究以及如何查看租户 clog 的使用情况。
作者:姜宇爱可生 DBA 团队成员,擅长数据库故障排查和处理。对技术抱有热忱,实践是检验真理的唯一标准~本文来源:原创投稿爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
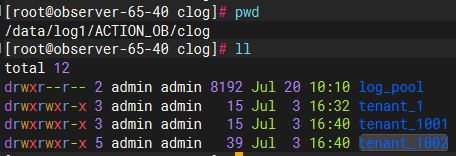
我们知道 clog 目录是存放 OceanBase 数据库记录修改操作的物理日志目录。目录具体的物理存放位置为 /data/log1/clustername/clog。比如,集群 ACTION_OB 的 clog 目录如下图所示:
OceanBase 4.1.0 版本采用了租户级别的日志流,将物理的变更记录聚合成了组织良好的若干日志流:一个系统日志流和多个用户日志流。系统的所有物理变更信息被记录在这些日志流中,故障恢复、日志归档、备库同步等均使用一套物理变更信息。在一个租户内,一个日志流允许有多个副本,多个副本之间基于 Paxos 协议同步数据。
OceanBase 4.1.0 版本 clog 目录下不再是 OBServer 的 clog 文件,而是新增了一层目录:log_pool 和 tenant_id 两类目录。下面我们分别介绍一下这两类目录的作用。
log_pool 目录
OceanBase 会为每一个 OBServer 节点初始化一个日志预分配池,即为该 OBServer 节点的日志盘总容量 LOG_DISK_CAPACITY,clog 文件默认 64M 一个,log_pool 会根据 log_disk_capacity/64M 预分配所有的 clog 日志文件;它受到集群配置项 log_disk_size 和 log_disk_percentage 共同影响。
- 如果
log_disk_size的值为 0,且log_disk_percentage的值不为 0,则系统以log_disk_percentage配置项设置的值分配日志盘空间。 - 如果
log_disk_size的值不为 0,则无论log_disk_percentage的值是否为 0,系统均以log_disk_size配置项设置的值分配日志盘空间。 - 如果
log_disk_size和log_disk_percentage的值均为 0,则系统会根据日志和数据是否共用同一磁盘来自动计算 Redo 日志占用其所在磁盘总空间的百分比:
log_disk_size 和 log_disk_percentage 默认为 0,如果没有特殊配置的情况下,OBServer 的日志盘总容量使用根据上述第三种情况决定。本地测试环境 OceanBase 日志盘没有划分磁盘,和 OceanBase 数据盘 data 目录共用一个磁盘。所以 OceanBase 日志盘占用其所在磁盘总空间的百分比为 30%,即 30G。
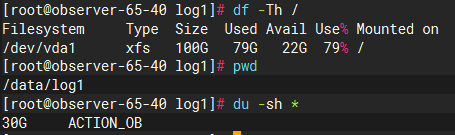
我们可以通过系统表 __all_virtual_server 来查看具体使用情况。其中 log_disk_capacity 即为当前 OBServer 节点的日志盘总容量,大约为 30G 左右。

那 log_disk_assigened 日志盘分配 和 log_disk_in_use 日志盘使用 又代表了什么意思呢?我们继续向下看。
tenant_id 目录
租户在一个 OBServer 的表现为一个 unit 资源单元,v4 新增 unit_config 属性 LOG_DISK_SIZE(注意和系统参数 log_disk_size 区分),为创建的租户初始化 log_disk_size 大小的 clog 目录空间。具体存放位置就是上边说的 /data/log1/clustername/clog/tenant_id 目录了。根据不同租户的 tenant_id 创建不同租户所属的日志目录。
需要注意的是这部分空间并不是一开始就分配到租户的所属目录下的,而是预占,在租户未使用 clog 文件时,会保留在 log_pool 中,表现为 all_virtual_server 表的 log_disk_assigned 字段。当租户需要写入新的 clog 文件时,OceanBase 才会将 log_pool 中的 clog 文件分配到所属的租户目录下,表现为 all_virtual_server 表的 log_disk_in_use 字段。
我们可以通过视图 gv$ob_units 查看具体 OBServer 节点的 unit 配置情况:
- log_disk_size:表示某一租户 unit 资源单元的日志磁盘可用的最大容量。
- log_disk_in_use:表示某一租户 unit 资源单元的日志磁盘使用容量。
可以看到下图中,all_virtual_server 的 log_disk_assinged 列对应 gv$ob_units 的 log_disk_size 列值之和,即 OBServer 节点的日志盘是根据租户的unit规格配置来预分配每个租户的日志盘容量的。all_virtual_server 的 log_disk_in_use 列对应 gv$ob_units 的 log_disk_in_use 列值之和,即当租户需要申请新的 clog 文件时,log_pool 才会将 clog 文件分配到租户的日志目录下。
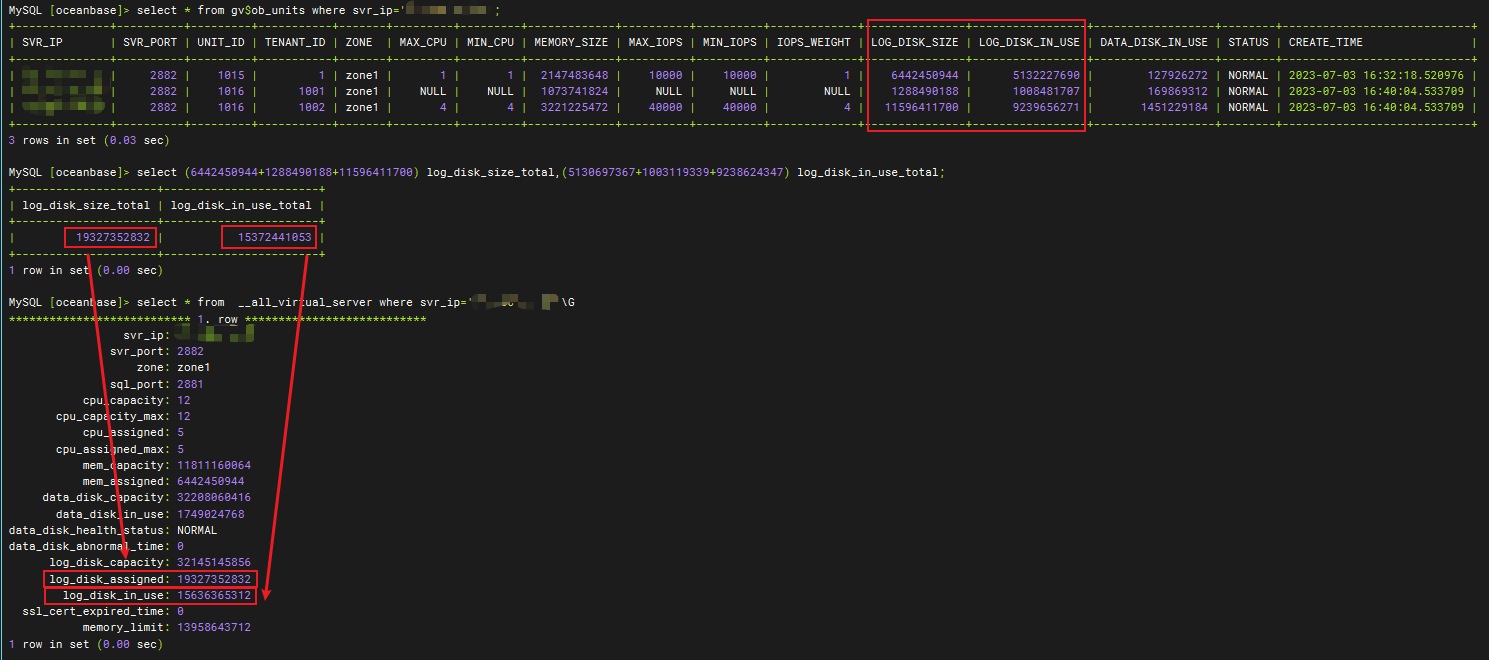
我们也可以通过磁盘目录使用来观察到 log_pool+tenant_id 的目录之和大约是 30G 左右,即 LOG_DISK_CAPACITY=30G;而 tenant_id 目录大小与 gv$ob_units 的 log_disk_in_use 对应;

目录空间使用的问题明白后,当我在看 OCP 的集群租户信息时发现,日志盘目录下为什么会多了一个 tenant_1001 的目录呢,这个租户我没有创建过呀,为什么会多了一个租户呢?
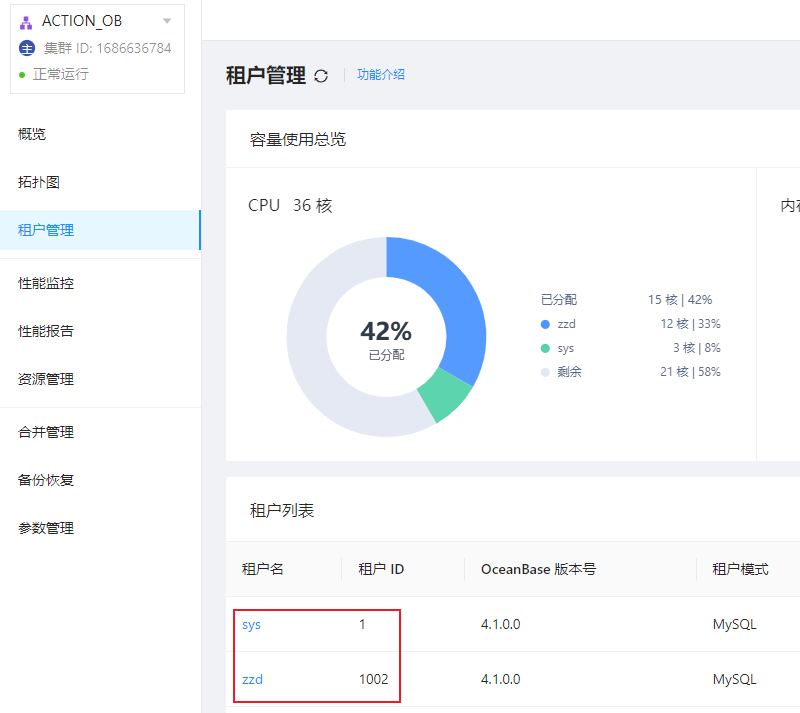
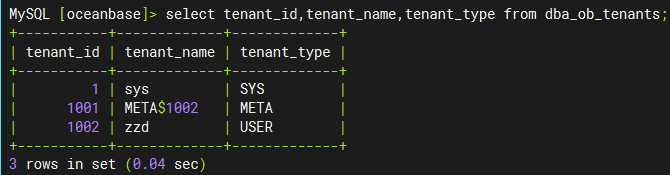
其实 tenant_1001 是 1002 租户的 Meta 租户,从 4.0.0 版本开始,引入了 Meta 租户概念。Meta 租户是 OceanBase 数据库内部自管理的租户,每创建一个用户租户系统就会自动创建一个对应的 Meta 租户,其生命周期与用户租户保持一致。Meta 租户用于存储和管理用户租户的集群私有数据,这部分数据不需要进行跨库物理同步以及物理备份恢复,这些数据包括:配置项、位置信息、副本信息、日志流状态、备份恢复相关信息、合并信息等。Meta 租户不能直接登录。我们可以通过 DBA_OB_TENANTS 视图查看具体的租户信息:
下图中,我们看到tenant_id目录下并不是具体的clog文件,而是又有一层数字id目录,数字id目录下的log目录才是具体存放clog文件的地方,那这些数字id有代表的是什么意思呢,我们继续向下看。

3、日志流目录
OcenaBase 4.x 版本引入了日志流 和分片的概念。每个分区都有其对应的数据存储对象,称之为分片(Tablet),它具备存储数据的能力,支持在机器之间迁移(transfer),是数据均衡的最小单位。日志流是由 OceanBase 数据库自动创建和管理的实体,它代表了一批数据的集合,包括若干 Tablet 和有序的 Redo 日志流。它通过 Paxos 协议实现了多副本日志同步,保证副本间数据的一致性,实现了数据的高可用。
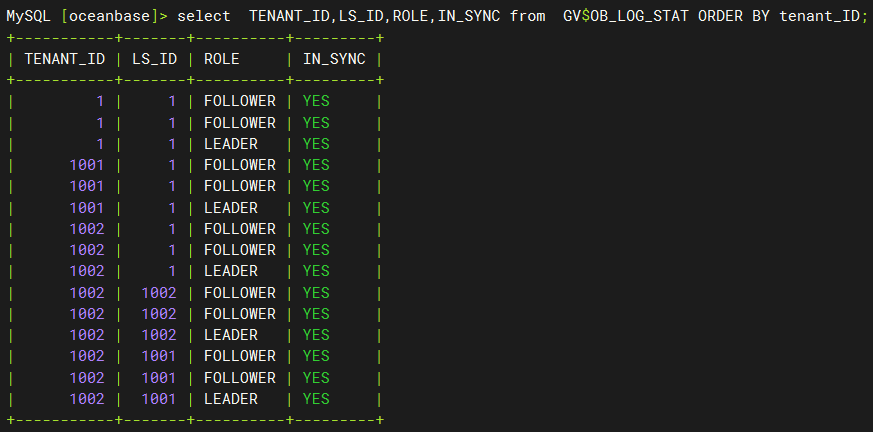
上图中的数字 id 其实就是对应了这里的日志流 id,即 LS_ID。我们可以通过 gv$ob_log_stat 查看租户的日志流 ID。通过下图我们可以看到 tenant_id=1 的租户对应的日志流 id 为 1;tenant_id=1001 的租户对应的日志流 id 为 1;tenant_id=1002 的租户对应的日志流 id 为 1、1001、1002 与上图目录结构一致。
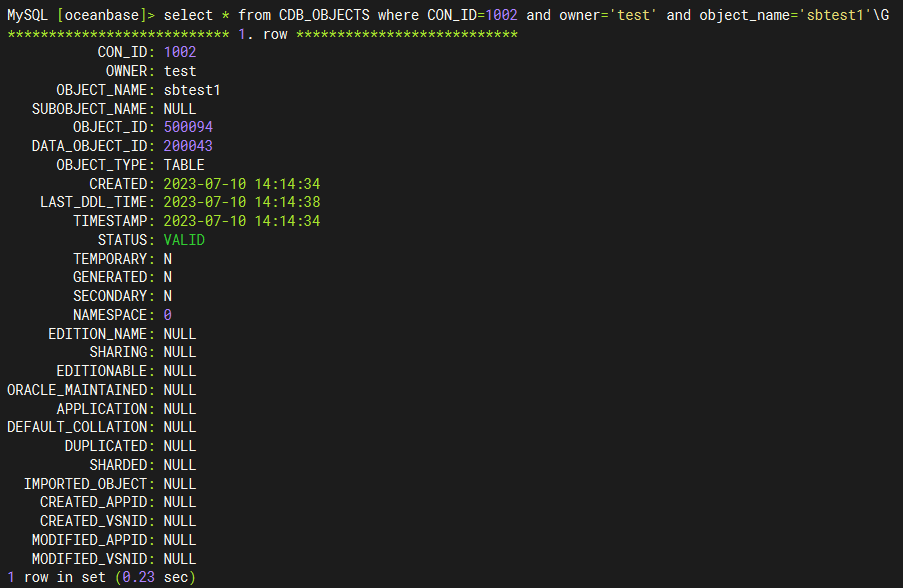
我们也可以通过视图 CDB_OBJECTS 和 CDB_OB_TABLET_TO_LS 查看表分区对应的分片、分片与日志流的映射关系,以及日志流副本的位置信息。比如我们想看 tenant_id=1002 租户的 test 库的 sbtest1 表所在的日志流信息:
- 通过
CDB_OBJECTS我们可以查询对指定表对应的分片 ID:tablet_id(DATA_OBJECT_ID)
- 通过
CDB_OB_TABLET_TO_LS我们可以查询到指定分片的日志流 ID:LS_ID。

clog 磁盘使用控制
租户可使用的 clog 磁盘容量是有限度的,当租户 unit 的 clog 日志容量使用比例(log_disk_in_use/log_disk_size*100%)达到指定阈值(log_disk_utilization_threshold,默认为 80%,不可修改)后,不会再向 log_pool 申请 clog 文件,而是直接复用最老的 clog 文件。
可以看到下图中租户的 clog 磁盘使用率也符合预期值。

clog 的使用量统计
在知道了 clog 目录结构之后,我们就可以通过计算租户目录下 clog 文件的生成量来统计租户每小时、每天的日志生成量,可以用于预估 OceanBase 备份盘的使用量。
#统计租户 clog 的生成量
--每小时
find $clog_dir/tenant_$tenant_id/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ':' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$3" | "$1" | "$1*64/1024 "G"}'
--每天
find tenant_1001/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ' ' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$3" | "$1" | "$1*64/1024 "G"}'
# 统计租户 data 数据大小
select tenant_id,svr_ip,sum(required_size/1024/1024/1024) from CDB_OB_TABLET_REPLICAS group by tenant_id,svr_ip,svr_port;
#!/usr/bin/bash
clog_dir=/data/log1/ACTION_OB/clog
echo "-- 检查时间:`date "+%Y-%m-%d %H:%M:%S"` --"
echo "+++++++++++++++++++++++++++++++++++++++++++++++++++"
echo "log_pool剩余clog文件数量: `ls -l $clog_dir/log_pool/|grep -v meta|wc -l`"
echo "log_pool剩余空间: $(echo "scale=2;`ls -l $clog_dir/log_pool/|grep -v meta|wc -l` * 64 / 1024 "|bc) G"
for tenant_id in `ls $clog_dir|grep "tenant_*"|awk -F '_' '{print $2}'`
do
echo "+++++++++++++++++++++++++++++++++++++++++++++++++++"
echo "$tenant_id 租户当前clog文件数量: `find $clog_dir/tenant_$tenant_id/* -regex '.*/[0-9]+' -type f |wc -l`"
echo "$tenant_id 租户当前clog文件总大小: $(echo "scale=2;`find $clog_dir/tenant_$tenant_id/* -regex '.*/[0-9]+' -type f |wc -l` * 64 / 1024 "|bc) G"
echo -e "$tenant_id 租户clog按照天统计:(YYYY-mm-dd|file_num|count_size)\n`find $clog_dir/tenant_$tenant_id/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ' ' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$1" | "$1*64/1024 "G"}'`"
done
脚本执行结果如下图所示:

标签:log,租户,数据库,us,国产,time,日志,id,obase From: https://www.cnblogs.com/feiyun8616/p/18196147