Mysql
目录
目录- Mysql
- mysql 8.0.12 winx64详细安装教程
- linux mysql教程在Linux远程连接笔记中
- JDBC安装、使用
- JDBC安装
- JDBC使用
- 三种执行对象:用于将 SQL 语句发送到数据库中
- Statement createStatement() 创建一个 Statement 对象来将 SQL 语句发送到数据库。
- Statement createStatement(int resultSetType, int resultSetConcurrency) 创建一个 Statement 对象,该对象将生成具有给定类型和并发性的 ResultSet 对象。
- PreparedStatement prepareStatement(String sql) 创建一个 PreparedStatement 对象来将参数化的 SQL 语句发送到数据库。
- PreparedStatement prepareStatement(String sql, int autoGeneratedKeys) 创建一个默认 PreparedStatement 对象,该对象能获取自动生成的键。
- PreparedStatement prepareStatement(String sql, int[] columnIndexes) 创建一个能返回由给定数组指定的自动生成键的默认 PreparedStatement 对象。
- PreparedStatement prepareStatement(String sql, String[] columnNames) 创建一个能返回由给定数组指定的自动生成键的默认 PreparedStatement 对象。
- PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency) 创建一个 PreparedStatement 对象,该对象将生成具有给定类型和并发性的 ResultSet 对象。
- 获取(ResultSet)结果
- 事务:Connection提供了对于事务相关操作的支持
- 释放资源
- 实践测试
- Druid连接池的使用
- sql语言
- mysql集群
- PL/SQL安装&使用教程(12.0.7)
- 面试真题:
- 个人经验:
mysql 8.0.12 winx64详细安装教程
1、到MySQL官网下载安装包:https://dev.mysql.com/downloads/mysql/;
选择合适的版本
2、将下载好的安装包(mysql-8.0.12-winx64 .zip)解压到相应路径下;
3、在安装目录下新建一个配置文件,命名为my.ini,并输入以下内容:
(安装目录和数据存放目录需根据自己安装路径配置自己的目录)
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=E:SQLServer\MySQL
# 设置mysql数据库的数据的存放目录
datadir=E:SQLServer\MySQL\DBData
# 允许最大连接数
max_connections=20
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
4、以管理员身份运行cmd.exe命令行工具:
5、进到MySQL安装目录bin目录下
cd /d E:SQLServer\MySQL\bin
6、执行命令安装MySQL
mysqld install
7、执行以下命令初始化data目录(5.7之后必须执行该命令之后才可以启动mysql)
mysqld --initialize-insecure
8、执行以下命令启动mysql
net start mysql
9、执行以下命令登录mysql,第一次登录无需输入密码,直接回车就好
mysql -u root -p
10、登录成功之后,执行以下命令修改密码( newpassword修改为自己设置的密码):
alter user 'root'@'localhost' identified with mysql_native_password by 'newpassword';
11、修改完密码之后,执行以下命令刷新权限
flush privileges;
12、至此,最新版MySQL已经安装完成!
13、参考:https://www.yingsoo.com/news/database/59720.html
linux mysql教程在Linux远程连接笔记中
JDBC安装、使用
参考:https://blog.csdn.net/weixin_53601359/article/details/115574284
JDBC安装
1、网络下载mysql-connector-java-8.0.12.jar
mysql官网地址:https://www.mysql.com
jdbc下载地址:https://dev.mysql.com/downloads/connector/j/
2、maven下载(推荐)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
JDBC使用
package mysql;
import java.sql.*;
public class MyJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//通过java访问mysql数据库
//这个对象获取数据库链接
//注册驱动,输入链接地址,用户名,密码
String driver = "com.mysql.cj.jdbc.Driver";
//访问本机的mysql数据库,格式 jdbc:数据库://本地端口3306/数据库名?跨时区参数
String url = "jdbc:mysql://localhost:3306/student?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false";
String username = "root";
String password = "123456";
//加载驱动
Class.forName(driver);
//获取到数据库链接
Connection connection = DriverManager.getConnection(url, username, password);
//创建一个Statement语句对象
Statement stat = connection.createStatement();
//执行SQL语句
String sql = "select * from student";
System.out.println(sql);
//把查询的结果(表记录)存放到ResultSet对象中,结果集
ResultSet resultSet = stat.executeQuery(sql);
}
}
三种执行对象:用于将 SQL 语句发送到数据库中
createStatement
- 作用:用于执行不带参数的简单 SQL 语句
- 特点:每次执行 SQL 语句,数据库都要执行 SQL 语句的编译,仅执行一次查询并返回结果的情形建议使用这个,此时效率高于 PreparedStatement
静态执行对象创建createStatement
Statement createStatement()
创建一个 Statement 对象来将 SQL 语句发送到数据库。Statement createStatement(int resultSetType, int resultSetConcurrency)
创建一个 Statement 对象,该对象将生成具有给定类型和并发性的 ResultSet 对象。Statement createStatement(int resultSetType, int resultSetConcurrency, int
resultSetHoldability)
创建一个 Statement 对象,该对象将生成具有给定类型、并发性和可保存性的 ResultSet 对象。
PreparedStatement
- 作用:用于执行带 或 不带参数的预编译 SQL 语句
- 特点:是预编译的, 在执行可变参数的一条 SQL 语句时,比 Statement 的效率高,安全性好,有效防止 SQL 注入等问题,对于多次重复执行的语句,效率会更高
动态执行对象创建prepareStatement
PreparedStatement prepareStatement(String sql)
创建一个 PreparedStatement 对象来将参数化的 SQL 语句发送到数据库。PreparedStatement prepareStatement(String sql, int autoGeneratedKeys)
创建一个默认 PreparedStatement 对象,该对象能获取自动生成的键。PreparedStatement prepareStatement(String sql, int[] columnIndexes)
创建一个能返回由给定数组指定的自动生成键的默认 PreparedStatement 对象。PreparedStatement prepareStatement(String sql, String[] columnNames)
创建一个能返回由给定数组指定的自动生成键的默认 PreparedStatement 对象。PreparedStatement prepareStatement(String sql, int resultSetType, int
resultSetConcurrency)
创建一个 PreparedStatement 对象,该对象将生成具有给定类型和并发性的 ResultSet 对象。PreparedStatement prepareStatement(String sql, int resultSetType, int
resultSetConcurrency, int resultSetHoldability)
创建一个 PreparedStatement 对象,该对象将生成具有给定类型、并发性和可保存性的 ResultSet 对象。
CallableStatement
- 作用:用于执行对数据库存储过程 的调用
执行SQL语句
Statement对象常用方法:
| 方法 | 内容 |
|---|---|
| executeQuery(String sql) | 用于向数据发送查询语句。 |
| executeUpdate(String sql) | 用于向数据库发送insert、update或delete语句 |
| execute(String sql) | 用于向数据库发送任意sql语句 |
| addBatch(String sql) | 把多条sql语句放到一个批处理中。 |
| executeBatch() | 向数据库发送一批sql语句执行。 |
获取(ResultSet)结果
Jdbc中的ResultSet封装了Sql语句的执行结果集。Resultset封装执行结果时,采用的类似于表格的方式,ResultSet 对象维护了一个指向表格数据行的指针。初始的时候,索引值是从1开始(数据库要求)指针指向第一个数据。调用ResultSet.next() 方法,使指针指向下一个数据,可以判断下个数据是否为空,或者可以调用getObject(int index)、getString(int index)等方法来获取指向的数据。
获取行
ResultSet提供了对结果集进行指针的方法:
| 方法 | 内容 |
|---|---|
| next() | 移动到下一行 |
| Previous() | 移动到前一行 |
| absolute(int row) | 移动到指定行 |
| beforeFirst() | 移动resultSet的最前面。 |
| afterLast() | 移动到resultSet的最后面。 |
获取值
ResultSet封装的数据通过get方法取出:
| 方法 | 内容 |
|---|---|
| getObject(int index) | 通过下标获取任意类型的数据 |
| getObject(string columnName) | 通过列名获取任意类型的数据 |
| getString(int index) | 通过下标获取指定类型的数据 |
| getString(String columnName) | 通过列名获取指定类型的数据 |
事务:Connection提供了对于事务相关操作的支持
boolean getAutoCommit()
获取此 Connection 对象的当前自动提交模式。
void commit()
使所有上一次提交/回滚后进行的更改成为持久更改,并释放此 Connection 对象当前持有的所有数据库锁。
void rollback()
取消在当前事务中进行的所有更改,并释放此 Connection 对象当前持有的所有数据库锁。
void rollback(Savepoint savepoint)
取消所有设置给定 Savepoint 对象之后进行的更改。
void setAutoCommit(boolean autoCommit)
将此连接的自动提交模式设置为给定状态。
void setTransactionIsolation(int level)
试图将此 Connection 对象的事务隔离级别更改为给定的级别。
int getTransactionIsolation()
获取此 Connection 对象的当前事务隔离级别。
Savepoint setSavepoint()
在当前事务中创建一个未命名的保存点 (savepoint),并返回表示它的新 Savepoint 对象。
Savepoint setSavepoint(String name)
在当前事务中创建一个具有给定名称的保存点,并返回表示它的新 Savepoint 对象。
void releaseSavepoint(Savepoint savepoint)
从当前事务中移除指定的 Savepoint 和后续 Savepoint 对象。
释放资源
Jdbc程序运行完后,切记要释放程序在运行过程中,创建的那些与数据库进行交互的对象,这些对象通常是ResultSet, Statement和Connection对象。后创建的对象先关闭,先关闭Statement对象再关闭Connection对象。
实践测试
package mysql;
import java.sql.*;
public class MyJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//通过java访问mysql数据库
//这个对象获取数据库链接
//注册驱动,输入链接地址,用户名,密码
String driver = "com.mysql.cj.jdbc.Driver";
//访问本机的mysql数据库,格式 jdbc:数据库://本地端口3306/数据库名?跨时区参数
String url = "jdbc:mysql://localhost:3306/student?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false";
String username = "root";
String password = "123456";
//加载驱动
Class.forName(driver);
//获取到数据库链接
Connection connection = DriverManager.getConnection(url, username, password);
//创建一个Statement语句对象
Statement stat = connection.createStatement();
//执行SQL语句
String sql = "select * from student";
//把查询的结果(表记录)存放到ResultSet对象中,结果集
ResultSet resultSet = stat.executeQuery(sql);
//输出
while(resultSet.next()){
System.out.print(resultSet.getString(1)+" ");
System.out.print(resultSet.getString(2)+" ");
System.out.print(resultSet.getString(3)+" ");
System.out.print(resultSet.getInt(4)+" ");
System.out.println(resultSet.getString(5));
}
resultSet.close();
stat.close();
connection.close();
}
}
Druid连接池的使用
参考:
https://zhuanlan.zhihu.com/p/157607448
连接池解决了以下两个问题
1. 频繁创建和销毁连接所带来的系统开销
2. 在高并发的情况下,要同时创建非常多的连接,可能会导致服务器内存溢出或者mysql服务器崩溃
代码
druid.properties
url=jdbc:mysql://localhost:3306/[这里输入数据库文件名路径]
username=[这里输入数据库用户名]
password=[这里输入数据库密码]
driverClassName=com.mysql.jdbc.Driver//驱动
# 连接池的参数
initialSize=10//初始化连接数
maxActive=10//最大最大活动连接数
maxWait=2000//最大等待时间
TestDruid
package com.zy.demo;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import com.zy.utils.DruidUtil;
import org.junit.Test;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TestDruid {
@Test
public void test01() throws Exception {
//配置文件的方式使用Druid连接池
//1. 创建Properties对象
Properties properties = new Properties();
//2. 将配置文件转换成字节输入流
InputStream is = TestDruid.class.getClassLoader().getResourceAsStream("properties/druid.properties");
//3. 使用properties对象加载is
properties.load(is);
//druid底层是使用的工厂设计模式,去加载配置文件,创建DruidDataSource对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection conn1 = dataSource.getConnection();
Connection conn2 = dataSource.getConnection();
Connection conn3 = dataSource.getConnection();
Connection conn4 = dataSource.getConnection();
Connection conn5 = dataSource.getConnection();
Connection conn6 = dataSource.getConnection();
Connection conn7 = dataSource.getConnection();
Connection conn8 = dataSource.getConnection();
Connection conn9 = dataSource.getConnection();
Connection conn10 = dataSource.getConnection();
//Connection conn11 = dataSource.getConnection();
assert is != null;
is.close();//关流
}
@Test
public void test02() throws SQLException {
Connection connection = DruidUtil.getConnection();
Statement statement = connection.createStatement();
//执行SQL语句
String sql = "select * from app_user where id=200004 or id=200005";
//把查询的结果(表记录)存放到ResultSet对象中,结果集
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
System.out.print(resultSet.getString(1)+" ");
System.out.print(resultSet.getString(2)+" ");
System.out.print(resultSet.getString(3)+" ");
System.out.print(resultSet.getString(4)+" ");
System.out.println(resultSet.getString(5));
}
DruidUtil.close(connection,statement,resultSet);
}
}
DruidUtil
public class DruidUtil {
//声明dataSource
private static DataSource dataSource;
/*
* 通过配置文件创建Druid连接池
* */
static {
try {
//1. 创建Properties对象
Properties properties = new Properties();
//2. 将配置文件转换成字节输入流
InputStream is = DruidUtil.class.getClassLoader().getResourceAsStream("properties/druid.properties");
//3. 使用properties对象加载is
properties.load(is);
//druid底层是使用的工厂设计模式,去加载配置文件,创建DruidDataSource对象
dataSource = DruidDataSourceFactory.createDataSource(properties);
if (is != null) {
is.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 获取Druid连接池
* */
public static DataSource getDataSource(){
return dataSource;//返回dataSource
}
/*
* 获取jdbc连接
* */
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
/*
* 关闭连接
* */
public static void close(Connection connection, Statement stat, ResultSet resultSet) throws SQLException {
resultSet.close();
stat.close();
connection.close();
}
}
sql语言
数据表中数据类型
- 数据库中表中的数据类型


常用类型
| 类型 | 描述 |
|---|---|
| int | 整形 |
| double | 浮点型 |
| varchar | 字符型 |
| date | 日期型 |
常用约束
| 约束名称 | sql表示 | 说明 |
|---|---|---|
| 主键约束 | primary key | 唯一性,非空性 |
| 唯一约束 | unique | 唯一性,可以空,但只能有一个 |
| 默认约束 | default | 该数据的默认值 |
| 自增长 | auto_increment | 一般用于主键自动增长 |
| 非空约束 | not null | 数据不能为空 |
数据库操作
- 创建数据库
create database 库名或者 create database 库名 character set 编码
create database mydb character set 'utf-8';
show create database 库名
show databases;
- 删除数据库
drop database 库名
drop database mydb;
- 使用数据库
use 库名
use mydb;
-
查看当前操作的库
select database() -
查看当前所有的数据库
show databases -
导入数据
source D:\ mdb.sql
- 查询当前使用的数据库版本
mysql --version
mysql -V
数据表操作
- 创建表
create table 表名(
字段名 类型(长度) [约束],
字段名 类型(长度) [约束],
字段名 类型(长度) [约束]
);
eg:
DROP TABLE IF EXISTS `sc`;
CREATE TABLE `sc` (
`S#` varchar(255) NOT NULL DEFAULT '' COMMENT '学号',
`C#` varchar(255) NOT NULL DEFAULT '' COMMENT '课程编号',
`CN` varchar(255) DEFAULT NULL COMMENT '课程名称',
PRIMARY KEY (`S#`, `C#`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
查看当前数据库中的表
show tables # 查看其他库中的表 show tables from 其他数据库名; -
查看表结构
desc 表名 -
删除表 drop table 表名
-
修改表
-
添加一列
alter table 表名 add 字段名 类型(长度) [约束] -
修改列的类型(长度,类型)
alter table 表名 modify 要修改的字段名 类型(长度) [约束] -
修改列名
alter table 表名 change 旧列名 新列名 类型(长度) [约束] -
删除表中的列
alter table 表名 drop 列名 -
修改表名
rename table 表名 to 新表名 -
修改表的字符集
alter table 表名 character set 编码 -
查看创建当前表的sql语句
show create table 表名
数据表中记录(数据)的操作
查询操作
-
查询所有
select * from product; -
查询列
select pname,price from product; -
查询所有商品信息使用表别名:
select * from product as p; -
查询商品使用列别名
select pname as p from product; # 将查询出来的字段显示为中文 select empno as ‘员工编号’, ename as ‘员工姓名’, sal*12 as ‘年薪’ from emp; # 注意:字符串可加添加单引号 | 双引号 # 可以采用as关键字重命名表字段,其实as也可以省略,如: select empno "员工编号", ename "员工姓名", sal*12 "年薪" from emp; -
查询去掉重复
select distinct(price) from product; -
将所有的商品的价格+10进行显示
select pname,price+10 from product;
条件查询优先级问题:
() > and > or, or 后面加and判断可能会由于优先级而出错。
参考:https://www.cnblogs.com/hua-qing/p/14538554.html
条件查询
| 运算符分类 | 运算符表示 | 说明 |
|---|---|---|
| 比较运算符 | < <= >= = <> | 大于、小于、大于(小于)等于、不等于 |
| BETWEEN …AND… | 显示在某一区间的值(含头含尾) | |
| IN(set) | 显示在in列表中的值,例:in(100,200) | |
| LIKE 通配符 | 模糊查询,Like语句中有两个通配符: % 用来匹配多个字符;例first_name like ‘a%’; _ 用来匹配一个字符。例first_name like ‘a_’; | |
| IS NULL | 判断是否为空,is null; 判断为空 is not null; 判断不为空 | |
| 逻辑运算符 | and | 多个条件同时成立 |
| or | 多个条件任一成立 | |
| not | 不成立,例:where not(salary>100); |
-
查询商品名称为洗衣机的商品信息
select * from product where pname='洗衣机'; -
查询价格>60的商品信息
select * from product where price > 60;
模糊查询
-
查询名字中含有机的商品信息
select * from product where pname like '%机%'; 或者 select * from product where pname like contact("%",'机',"%"); -
Like可以实现模糊查询,like支持%和下划线匹配
select * from product where pname like '_机%'; # %匹配任意字符出现的个数, 下划线只匹配一个字符 -
查询id在(3,6,9)范围的商品信息
select * from product where pid in (3,6,9); -
查询商品名称中含有机并且id为6的商品信息
select * from product where pname like '%机%' and pid=6; -
查询id为2或者6的商品信息
select * from product where pid=2 or pid=6;
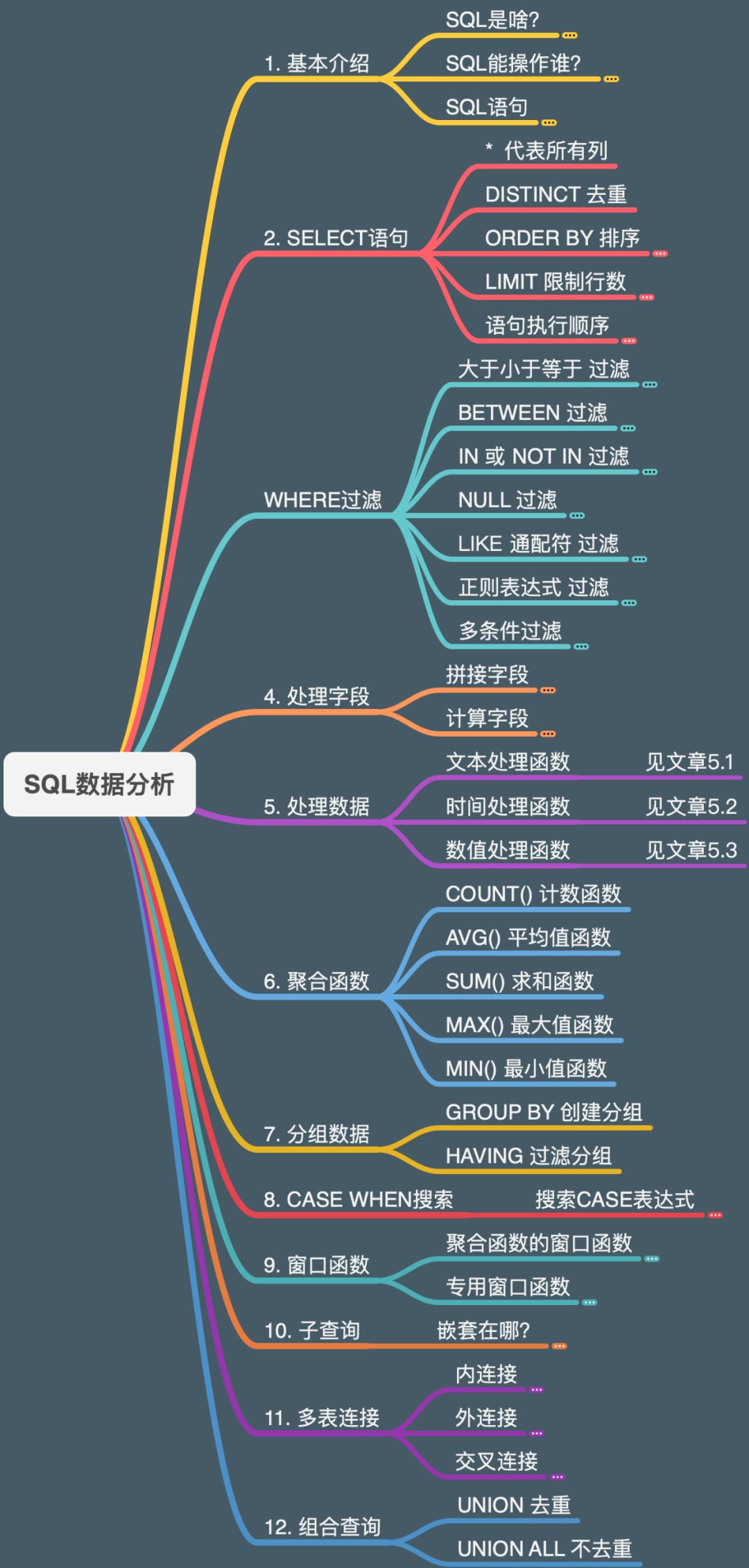
去重查询
参考:https://www.php.cn/faq/344283.html
select distinct name, id from A
执行后结果如下:
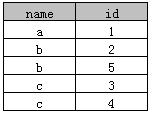
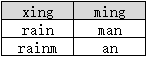
实际上是根据name和id两个字段来去重的,Access和SQL Server同时支持。
select distinct xing, ming from B
排序
-
按照商品价格(升序/降序 )
select * from product order by price asc; select * from product order by price desc; # 多字段排序 SELECT * FROM emp ORDER BY job DESC,sal DESC; -
查询名称含有器的并且按照价格降序排序
select * from product where pname like '%器%' order by price desc;
嵌套查询
参考:https://blog.csdn.net/albenxie/article/details/77450255
**聚合函数查询: **
-
获取所有商品的价格总和
select sum(price) as "价格总和" from product; -
获取所有商品的平均价格
select avg(price) as "平均价格" from product; -
获取所有商品的个数
select count(*) as "总数量" from product; -
取得某个一列的最大/小值
SELECT MAX(sal) FROM emp; SELECT MIN(sal) FROM emp; -
可以将这些聚合函数都放到select中一起使用
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp;
分组查询
group by
- 取得每个工作岗位的工资合计,要求显示岗位名称和工资合计
SELECT SUM(sal),job FROM emp GROUP BY job;
# 输出结果会根据‘job’分组后输出
如果使用了order by,order by必须放到group by后面
- 按照工作岗位和部门编码分组,取得的工资合计
select job,deptno,sum(sal) from emp group by job,deptno;
先根据job分组,然后再根据deptno分组,如果你的job和deptno都一样,就合并记录
在SQL语句中若有group by 语句,那么在select语句后面只能跟分组函数+参与分组的字段。
否则会报错,参考:
https://blog.csdn.net/u012660464/article/details/113977173
sql_mode=only_full_group_by错误修改方法:
参考:https://blog.csdn.net/weixin_54514751/article/details/130505055
set sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
set @@sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
set @@sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
having
如果想对分组数据再进行过滤需要使用having子句
-
取得每个岗位的平均工资大于2000
SELECT AVG(sal),job FROM emp GROUP BY job HAVING AVG(sal) >2000;
多表查询
参考:https://blog.csdn.net/qq_36501591/article/details/116234694?ydreferer=aHR0cHM6Ly9jbi5iaW5nLmNvbS8%3D
五表查询
SELECT sys_user.id,sys_user.user_name,sys_user.`password`,sys_role.`name`,sys_menu.menu_name
FROM sys_user,sys_user_role,sys_role,sys_role_menu,sys_menu
WHERE sys_user.id=sys_user_role.user_id
AND sys_user_role.role_id=sys_role.id
AND sys_role.id=sys_role_menu.role_id
AND sys_role_menu.menu_id=sys_menu.id
//where中的字段可以不是select中的字段
左连接五表查询
SELECT sys_user.id,sys_user.user_name,sys_user.`password`,sys_role.`name`,sys_menu.menu_name
FROM sys_user
LEFT JOIN sys_user_role ON sys_user.id=sys_user_role.user_id
LEFT JOIN sys_role ON sys_user_role.role_id=sys_role.id
LEFT JOIN sys_role_menu ON sys_role.id=sys_role_menu.role_id
LEFT JOIN sys_menu ON sys_role_menu.menu_id=sys_menu.id
增加操作
-
单行插入
insert into 表名(列名1,列名2,列名3……) values(值1,值2,值3……) 或者 insert into 表名 values(值1,值2,值3……) -
多行插入
INSERT INTO TestTable(UserName,Subject,Source) VALUES ('张三','语文',60), ('王五','英语',80), ('李四','数学',70), ('王五','数学',75), ('王五','语文',57), ('李四','语文',80), ('张三','英语',100); -
插入记录中文乱码问题
set names gbk;
删除操作
-
删除表记录带条件
delete from 表名 where 条件 -
删除表记录不带条件
delete * from 表名; 或者 truncate table 表名; -
Mysql 删除某条数据使自增id重置
alter table table名 auto_increment = 自增位置;
使用 truncate table 表名; 会删除自增的序列, 但会清空整张表
而 delete 则不会删除之前的自增序列
修改操作
-
修改表记录
update 表名 set 字段名=值, 字段名=值, 字段名=值…… -
修改表记录带条件
update 表名 set字段名=值, 字段名=值, 字段名=值…… where 条件
case when
参考:
https://baijiahao.baidu.com/s?id=1713792474999998421&wfr=spider&for=pc
-
用法一
CASE case_value WHEN when_value THEN statement_list [WHEN when_value THEN statement_list] ... [ELSE statement_list] END CASE -
用法二
CASE WHEN search_condition THEN statement_list [WHEN search_condition THEN statement_list] ... [ELSE statement_list] END CASE
MySQL中THEN
参考:https://www.dbs724.com/224947.html
行转列操作
参考:https://blog.51cto.com/u_15800767/6068085
https://blog.csdn.net/qq_34869990/article/details/106916791
- 建表testtable
DROP TABLE IF EXISTS `testtable`;
CREATE TABLE `testtable` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`UserName` varchar(50) DEFAULT NULL,
`Subject` varchar(50) DEFAULT NULL,
`Source` decimal(18,0) DEFAULT NULL,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of testtable
-- ----------------------------
INSERT INTO TestTable(UserName,Subject,Source)
VALUES
('张三','语文',60),
('王五','英语',80),
('李四','数学',70),
('王五','数学',75),
('王五','语文',57),
('李四','语文',80),
('张三','英语',100);

方法一:case when
set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
# 表中每一行都会产生一个对应记录,max与group必不可少
select testtable.UserName as "姓名",
max(case testtable.`Subject` WHEN "语文" THEN testtable.Source END) as "语文",
max(case testtable.`Subject` WHEN "数学" THEN testtable.Source END) as "数学",
max(case testtable.`Subject` WHEN "英语" THEN testtable.Source END) as "英语"
from testtable
GROUP BY testtable.UserName
方法二:join连表
数据库视图
参考:https://blog.csdn.net/qq_50675319/article/details/126722820
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自我们定义视图的查询中使用的表,并且是在使用视图时动态生成的。
通俗的讲,视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图基本语法
-
创建视图
create [or replace] view 视图名称[(列表名称)] as select语句 [with [cascaded|local] check option] # 例如 CREATE view backs_view AS( SELECT sys_user.id,sys_user.user_name,sys_user.`password`,sys_role.`name`,sys_menu.menu_name FROM sys_user LEFT JOIN sys_user_role ON sys_user.id=sys_user_role.user_id LEFT JOIN sys_role ON sys_user_role.role_id=sys_role.id LEFT JOIN sys_role_menu ON sys_role.id=sys_role_menu.role_id LEFT JOIN sys_menu ON sys_role_menu.menu_id=sys_menu.id ) -
查询视图
show create view 视图名称 -- 查看创建视图语句 select * from 视图名称 -- 查询视图数据 -
删除视图
drop view [if exists] 视图名称 [,视图名称]
mysql索引
参考:MySQL索引详解(一文搞懂)-阿里云开发者社区 (aliyun.com)
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
什么是mysql索引
- 官方上面说索引是帮助MySQL
高效获取数据的数据结构,通俗点的说,数据库索引好比是一本书的目录,可以直接根据页码找到对应的内容,目的就是为了加快数据库的查询速度。- 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
- 一种能帮助mysql提高了查询效率的数据结构:索引数据结构。
索引数据结构
B-tree、B+tree索引、Hash索引、Full-text索引。
索引原理
索引的存储原理大致可以概括为一句话:以空间换时间。
一般来说索引本身也很大,不可能全部存储在内存中,因此
索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。数据库在未添加索引进行查询的时候默认是进行全文搜索,也就是说有多少数据就进行多少次查询,然后找到相应的数据就把它们放到结果集中,直到全文扫描完毕。
索引的分类
主键索引:primary key
- 设定为主键后,数据库自动建立索引,InnoDB为聚簇索引,主键索引列值不能为空(Null)。
唯一索引:
- 索引列的值必须唯一,但允许有空值(Null),但只允许有一个空值(Null)。
复合索引:
- 一个索引可以包含多个列,多个列共同构成一个复合索引。
全文索引:
- Full Text(MySQL5.7之前,只有MYISAM存储引擎引擎支持全文索引)。
- 全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找允许在这些索引列中插入重复值和空值。全文索引可以在Char、VarChar 上创建。
空间索引:
- MySQL在5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型,MySQL在空间索引这方年遵循OpenGIS几何数据模型规则
前缀索引:
- 在文本类型为char、varchar、text类列上创建索引时,可以指定索引列的长度,但是数值类型不能指定。
索引的优缺点
优点:
- 大大提高数据查询速度。
- 可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
- 通过索引列对数据进行排序,降低数据的排序成本降低了CPU的消耗。
- 被索引的列会自动进行排序,包括【单例索引】和【组合索引】,只是组合索引的排序需要复杂一些。
- 如果按照索引列的顺序进行排序,对order 不用语句来说,效率就会提高很多。
缺点:
- 索引会占据磁盘空间。
- 索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改查操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
- 维护索引需要消耗数据库资源。
创建索引的基本操作
查看user表中索引
show index from user;

创建单列索引:
#创建单列索引,只能包含一个字段
create index name_index on user(name);
show index from user;

创建唯一索引:
#创建唯一索引,只能有一个列
create unique index age_index on user(age);
创建复合索引:
#复合索引
create index name_age_index on user(name,age);

满足复合索引的查询的两大原则:
最左前缀原则
如下四种都满足条件
select * from user where name = ?
select * from user where name = ? and age = ?
select * from user where name = ? and sex = ?
select * from user where name = ? and age = ? and sex = ?
自动排序
MySQL 引擎在执行查询时,为了更好地利用索引,在查询过程中会动态调整查询字段的顺序!(也就是说,当条件中的字段全部达到复合索引中的字段时,可以动态调整字段顺序,使其满足最前左缀)
#可以使用复合索引:索引中包含的字段数都有,只是顺序不正确,在执行的时候可以动态调整为最前左缀
select * from user where sex = ? and age = ? and name = ?
select * from user where age = ? and sex = ? and name = ?
#不可以使用复合索引:因为缺少字段,并且顺序不正确
select * from user where sex = ? and age = ?
select * from user where age = ? and name = ?
select * from user where age = ?
select * from user where sex = ?
索引优化指南
参考: https://blog.csdn.net/weixin_47138646/article/details/129797696
判断其是否使用索引
通过explain关键字查看这条语句的执行计划
show index from user;
explain select name from user;
mysql函数
参考:
https://www.cnblogs.com/meteor119/p/15206067.html
https://blog.csdn.net/Leon_Jinhai_Sun/article/details/126921587
创建函数
我们创建函数时必须指定我们的函数是否是
- DETERMINISTIC 不确定的
- NO SQL 没有 SQL 语句,当然也不会修改数据
- READS SQL DATA 只是读取数据,当然也不会修改数据
- MODIFIES SQL DATA 要修改数据
- CONTAINS SQL 包含了 SQL 语句
解决方法
在 MySQL 中创建函数时出现这种错误的解决方法:
1、在 MySQL 数据库中执行以下语句,临时生效,重启后失效
set global log_bin_trust_function_creators=TRUE;
2、在配置文件 my.ini 的 [mysqld] 配置,永久生效
log_bin_trust_function_creators=1
CREATE DEFINER = CURRENT_USER FUNCTION `NewProc`(`year` int)
RETURNS int
BEGIN
#Routine body goes here...
RETURN 0;
END;;
table
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `admit`;
CREATE TABLE `admit` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`year` int(255) DEFAULT NULL COMMENT '入学年度',
`num` int(255) DEFAULT NULL COMMENT '录取学生人数',
`stu_len` varchar(255) DEFAULT NULL COMMENT '学生学制',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='录取人数';
-- ----------------------------
-- Records of admit
-- ----------------------------
INSERT INTO `admit` VALUES ('1', '2018', '2000', '3');
INSERT INTO `admit` VALUES ('2', '2019', '2000', '4');
INSERT INTO `admit` VALUES ('3', '2020', '1000', '4');
INSERT INTO `admit` VALUES ('4', '2020', '2000', '3');
INSERT INTO `admit` VALUES ('5', '2025', '500', '3');
问题:计算出每年在校人数
set global log_bin_trust_function_creators=TRUE;
DELIMITER $$
DROP FUNCTION IF EXISTS `test1`$$
CREATE FUNCTION `test1`(`year` INT) RETURNS INT
BEGIN
DECLARE mynum INT DEFAULT 0;
select SUM(admit.num) from admit
WHERE ((`year`-admit.`year`)<=admit.stu_len AND (`year`-admit.`year`)>=0)
INTO mynum;
RETURN mynum;
END $$
SELECT admit.`year`,test1(admit.`year`) as `在校学生数` FROM admit GROUP BY admit.`year`;
方法2
SELECT year_b.year,SUM(admit_b.num) AS stu_sum
FROM (
SELECT DISTINCT year
FROM admit
) AS year_b
JOIN admit AS admit_b
ON year_b.year BETWEEN admit_b.year AND admit_b.year + admit_b.stu_len - 1
GROUP BY year_b.year;
一个例子
附上一个随机生成中文名字的SQL函数,配合给上面创建测试数据函数使用效果更好:
DELIMITER $$
DROP FUNCTION IF EXISTS `generateUserName`$$
CREATE FUNCTION `generateUserName`() RETURNS VARCHAR(30) CHARSET utf8
BEGIN
DECLARE xing VARCHAR(2056) DEFAULT '赵钱孙李周郑王冯陈楮卫蒋沈韩杨朱秦尤许何吕施张孔曹严华金魏陶姜戚谢喻柏水窦章云苏潘葛奚范彭郎鲁韦昌马苗凤花方俞任袁柳酆鲍史唐费廉岑薛雷贺倪汤滕殷罗毕郝邬安常乐于时傅皮齐康伍余元卜顾孟平黄和穆萧尹姚邵湛汪祁毛禹狄米贝明臧计伏成戴谈宋茅庞熊纪舒屈项祝董梁杜阮蓝闽席季麻强贾路娄危江童颜郭梅盛林***锺徐丘骆高夏蔡田樊胡凌霍虞万支柯昝管卢莫经裘缪干解应宗丁宣贲邓郁单杭洪包诸左石崔吉钮龚程嵇邢滑裴陆荣翁';
DECLARE ming VARCHAR(2056) DEFAULT '嘉懿煜城懿轩烨伟苑博伟泽熠彤鸿煊博涛烨霖烨华煜祺智宸正豪昊然明杰诚立轩立辉峻熙弘文熠彤鸿煊烨霖哲瀚鑫鹏致远俊驰雨泽烨磊晟睿天佑文昊修洁黎昕远航旭尧鸿涛伟祺轩越泽浩宇瑾瑜皓轩擎苍擎宇志泽睿渊楷瑞轩弘文哲瀚雨泽鑫磊梦琪忆之桃慕青问兰尔岚元香初夏沛菡傲珊曼文乐菱痴珊恨玉惜文香寒新柔语蓉海安夜蓉涵柏水桃醉蓝春儿语琴从彤傲晴语兰又菱碧彤元霜怜梦紫寒妙彤曼易南莲紫翠雨寒易烟如萱若南寻真晓亦向珊慕灵以蕊寻雁映易雪柳孤岚笑霜海云凝天沛珊寒云冰旋宛儿绿真盼儿晓霜碧凡夏菡曼香若烟半梦雅绿冰蓝灵槐平安书翠翠风香巧代云梦曼幼翠友巧听寒梦柏醉易访旋亦玉凌萱访卉怀亦笑蓝春翠靖柏夜蕾冰夏梦松书雪乐枫念薇靖雁寻春恨山从寒忆香觅波静曼凡旋以亦念露芷蕾千兰新波代真新蕾雁玉冷卉紫山千琴恨天傲芙盼山怀蝶冰兰山柏翠萱乐丹翠柔谷山之瑶冰露尔珍谷雪乐萱涵菡海莲傲蕾青槐冬儿易梦惜雪宛海之柔夏青亦瑶妙菡春竹修杰伟诚建辉晋鹏天磊绍辉泽洋明轩健柏煊昊强伟宸博超君浩子骞明辉鹏涛炎彬鹤轩越彬风华靖琪明诚高格光华国源宇晗昱涵润翰飞翰海昊乾浩博和安弘博鸿朗华奥华灿嘉慕坚秉建明金鑫锦程瑾瑜鹏经赋景同靖琪君昊俊明季同开济凯安康成乐语力勤良哲理群茂彦敏博明达朋义彭泽鹏举濮存溥心璞瑜浦泽奇邃祥荣轩';
DECLARE I_xing INT DEFAULT CHAR_LENGTH(xing); -- 姓氏字符串,CHAR_LENGTH可以统计中文字符个数
DECLARE I_ming INT DEFAULT CHAR_LENGTH(ming);
DECLARE return_str VARCHAR(2056) DEFAULT '';
SET return_str = CONCAT(return_str, SUBSTRING(xing, FLOOR(1 + RAND() * I_xing), 1)); -- 姓氏一个中文字
SET return_str = CONCAT(return_str, SUBSTRING(ming, FLOOR(1 + RAND() * I_ming), 1)); -- 名中第一个字
IF RAND() > 0.400 THEN -- 名中第二个字,有没有是随机的
SET return_str = CONCAT(return_str, SUBSTRING(ming, FLOOR(1 + RAND() * I_ming), 1));
END IF;
RETURN return_str; -- 名字有可能是2个字,也有可能是3个字
END $$
系统函数
concat函数
concat('%', #{materialName}, '%')
split函数(不存在)
split(${incomeReqCode},',')
实际应使用SUBSTRING函数
参考:https://blog.csdn.net/liqinglonguo/article/details/134673961
mysql存储过程
CREATE PROCEDURE sp_split(in words varchar(2000),in regex varchar(20))
BEGIN
CREATE TEMPORARY TABLE IF NOT EXISTS temp_key_split (
key_words varchar(20)
);
DELETE FROM temp_key_split;
while(instr(words,regex)<>0) DO
INSERT temp_key_split(key_words) VALUES (substring(words,1,instr(words,regex)-1));
SET words = INSERT(words,1,instr(words,regex),'');
END WHILE;
INSERT temp_key_split(key_words) VALUES (words);
END
mybatis操作存储过程
<select id="callStoredProcedure" parameterType="pd" statementType="CALLABLE">
call sp_split((
SELECT GROUP_CONCAT(seo_keywords) FROM shopping_goods WHERE seo_keywords LIKE CONCAT(CONCAT('%', #{goods_key}),'%')
), ',');
</select>
mysql事务
-- 开始事务
START TRANSACTION;
-- 执行一些SQL语句
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
-- 判断是否要提交还是回滚
IF (条件) THEN
COMMIT; -- 提交事务
ELSE
ROLLBACK; -- 回滚事务
END IF;
常用小技巧
MySQL在windows下不区分大小写
将script文件导入MySQL后表名也会自动转化为小写,结果再 想要将数据库导出放到linux服务器中使用时就出错了。
因为在linux下表名区分大小写而找不到表,查 了很多都是说在linux下更改MySQL的设置使其也不区分大小写,但是有没有办法反过来让windows 下 大小写敏感呢。其实方法是一样的,相应的更改windows中MySQL的设置就行了。
具体操作:
在MySQL的配置文件my.ini中 [mysqld]增加一行:
lower_case_table_names = 0
# 其中 0:区分大小写,1:不区分大小写
MySQL在Linux下数据库名、表名、列名、别名大小写规则是这样的:
1、数据库名与表名是严格区分大小写的;
2、表的别名是严格区分大小写的;
3、列名与列的别名在所有的情况下均是忽略大小写的;
4、变量名也是严格区分大小写的; MySQL在Windows下都不区分大小写
like支持%和下划线匹配
select * from product where pname like '_机%';
%匹配任意字符出现的个数, 下划线只匹配一个字符
使用 truncate table 表名
清空整个表中的数据
会删除自增的序列, 而 delete 则不会删除之前的自增序列
上面说过truncate与delete,drop很相似,其实这三者还是与很大的不同的,下面简单对比下三者的异同。
truncate与drop是DDL语句,执行后无法回滚;delete是DML语句,可回滚。
truncate只能作用于表;delete,drop可作用于表、视图等。
truncate会清空表中的所有行,但表结构及其约束、索引等保持不变;drop会删除表的结构及其所依赖的约束、索引等。
truncate会重置表的自增值;delete不会。
truncate不会激活与表有关的删除触发器;delete可以。
truncate后会使表和索引所占用的空间会恢复到初始大小;delete操作不会减少表或索引所占用的空间,drop语句将表所占用的空间全释放掉。
mysql集群
Centos7版的也在Linux远程连接教程
PL/SQL安装&使用教程(12.0.7)
https://blog.csdn.net/qq_57610796/article/details/133358858
官网下载地址:
https://www.allroundautomations.com/registered-plsqldev/
面试真题:
新信澜
个人经验:
java.lang.IllegalArgumentException: invalid comparison: java.util.Date and java.lang.String
参考:https://cloud.tencent.com/developer/article/1648237
原因:对于时间参数进行比较时的一个bug. 如果拿传入的时间类型参数与空字符串''进行对比判断则会引发异常。
错误写法:
正确写发:
所以比较的时候去掉比较'',只比较null就可以了。
XML 大于号 小于号 处理
1.使用转义字符

- 使用
<![CDATA[ ]]>
<test>
this is a <![CDATA[<]]>;that is a <![CDATA[>]]>;
</test>
解析出:this is a <;that is a >;