- 案例背景
很多事件记录在最初一段时间读写比较频繁,存储在postgresql比较合适,后期数据量变大,且仅作为历史记录查询,更适合存储在mongodb中,可能需要定期将postgresql中的数据转存到mongodb。
- 案例分析
postgresql数据定时转存mongodb,可以采用jdbc方式将postgresql读入内存,对每条数据进行解析,转成json格式,按mongodb的语法写入数据库。这种方法弊端是,需要对各表建立实体对象,依次解析,或者用更不优雅的方式拼接字符串,整个方案扩展性低,可维护性差。因此,我们采用kettle来完成数据的postgresql读取和mongodb插入脚本编写,并在java工程中进行kettle调用。
- 实现方案
1****、transformation
采用transformation完成针对数据的基础转换,执行SQL和数据postgresql读取和mongodb插入等,job则设定定时任务调用transformation,完成对整个工作流程的控制。
1、表输入
表输入查询要转存到mongodb中的数据记录,提供数据源。
其中数据库连接,要编辑数据库连接类型、IP、端口、密码、数据库名等信息。
2、json输出
json输出中操作选择Output value,json条目名称输入json名称,输出值也选择Output value,字段中选择需要插入的字段。
3、插入mongodb
在Big Data中选择MongoDB Output插件,在Configure connection中输入连接信息。
在Output options中设置插入时的模式
Truncate:插入数据之前先把集合里的所有数据删除,此模式慎用,仅用于首次全量同步;
Update:更新数据,存在则修改,不存在不操作。
upsert:更新添加,找到匹配项则修改,找不到匹配项则添加。
如果设置了Update模式,在Mongo document fields中需要选择某一字段的Modifier operation设为N/A,其他字段设为$set,表示将该字段作为更新标准,当该字段值存在时,其他字段更新。
可以在Create/drop indexes中创建索引。
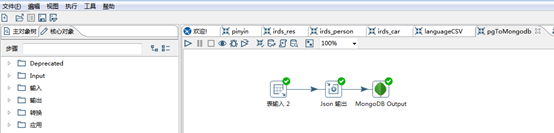
注:mongodb插件可能遇到报错:java.lang.NoClassDefFoundError: javax/crypto/spec/PBEKeySpec
在data-integration\system\karaf\etc\config.properties中org.osgi.framework.bootdelegation参数添加“,javax.crypto,javax.crypto.*”,保证能正常加载加解密相关类。
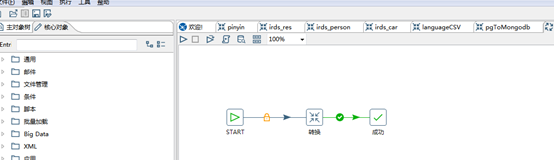
2****、job
在start中选择合适的时间间隔,以图为例10分钟执行一次。
将之前的transformation添加至转换中
3****、java工程调用
1、导入jar包
将kettle基础的jar包导入工程,另外将mongodb驱动mongo-java-driver-2.13.0.jar也导入工程中
2、导入插件
将\data-integration\system\karaf\system\pentaho 目录下的插件文件夹pentaho-mongo-utils和pentaho-mongodb-plugin导入工程根目录
3、传入kettle job脚本路径,如果有需要传入脚本中的参数,在params中设定入参:
public static void main(String[] args) throws IOException {
String[] params = { "101", "content", "" };
runJob(params,"E:\\dict_data\pgToMongodb.kjb");
}
4、将需要的参数在job中设定,设置日志级别,ERROR错误日志,BASIC基础日志,ROWLEVEL行级日志,环境初始化并运行job:
public static boolean runJob(String[] params, String jobPath) { try { KettleEnvironment.init(); // jobPath是Job脚本的路径及名称 JobMeta jobMeta = new JobMeta(jobPath, null); Job job = new Job(null, jobMeta); job.setLogLevel(LogLevel.ROWLEVEL); job.start(); job.waitUntilFinished(); // 向Job 脚本传递参数,脚本中获取参数值:${参数名} job.setLogLevel(LogLevel.ROWLEVEL); job.start(); job.waitUntilFinished(); if (job.getErrors() > 0) { return false; } else { return true; } } catch (Exception e) { e.printStackTrace(); } return false; }
- 结束语
1、 kettle中postgresql数据转存mongodb,单线程任务Truncate模式下每秒6000-11000条数据,Update模式下每秒600-1000条数据,相差10倍效率,初次全量同步时尽量采用Truncate模式。
2、要控制合理的同步时间间隔,避免过于频繁导致数据传输失败。
3、数据转存不能做到实时,没有数据库连接守护进程,只能重连一定次数,如果数据库连接可能断开,需要另外的补偿机制。
4、本文中完成了在同一表中查询,可以输入postgresql关系型数据库中联表查询的结果,保证适当的冗余,建立合适的索引。
标签:postgresql,mongodb,数据库,job,数据,转存 From: https://www.cnblogs.com/bigleft/p/18147155