NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]
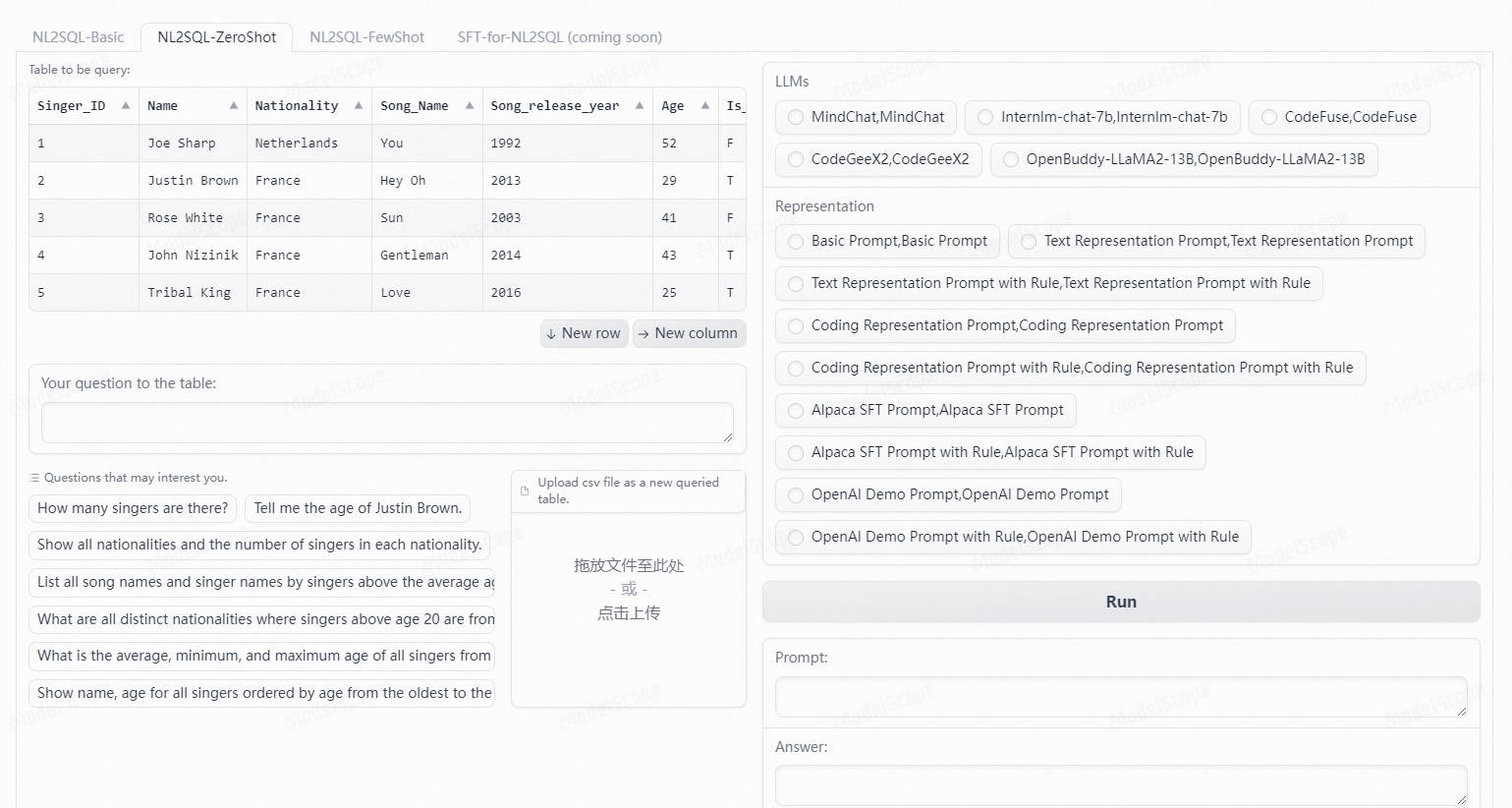
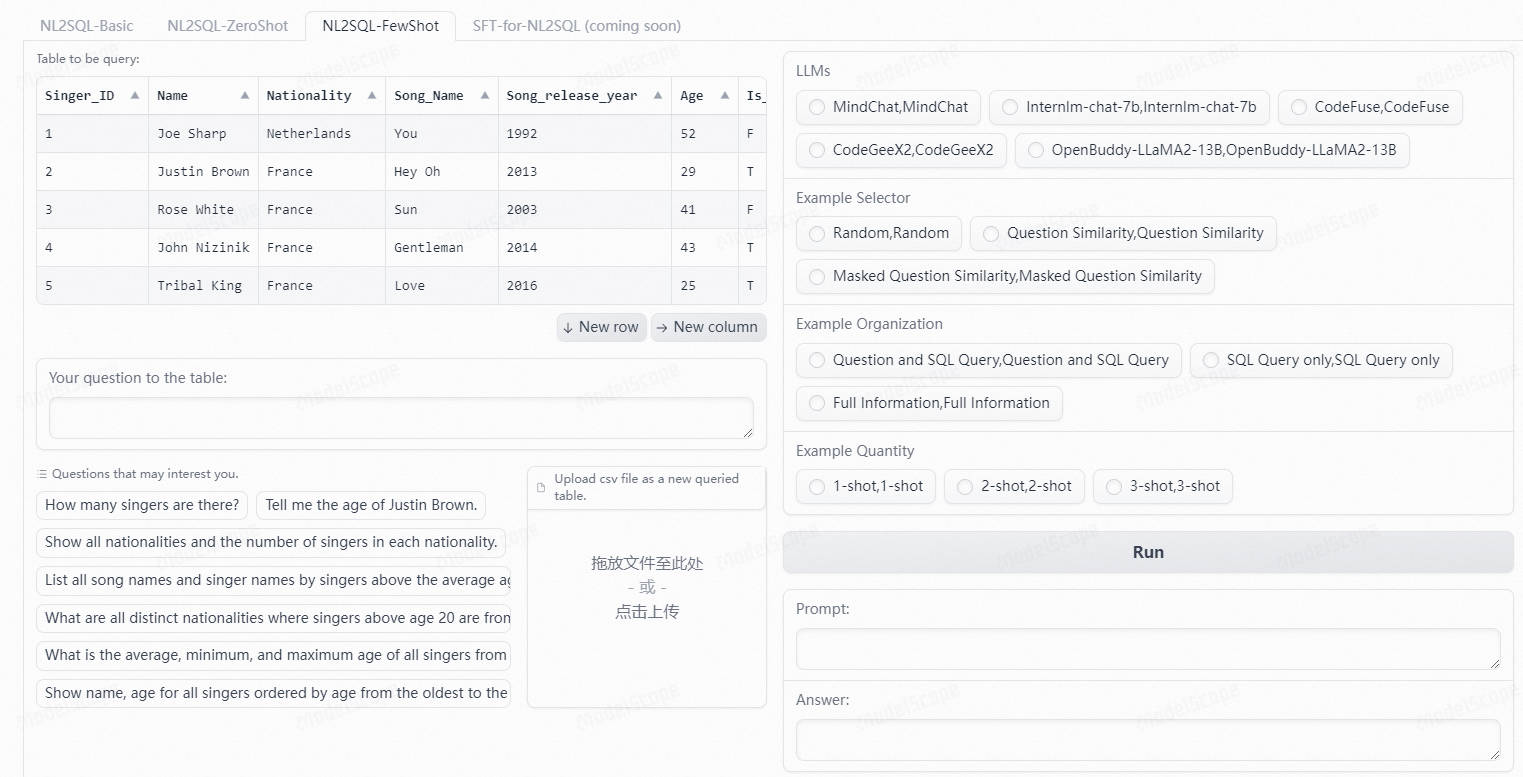
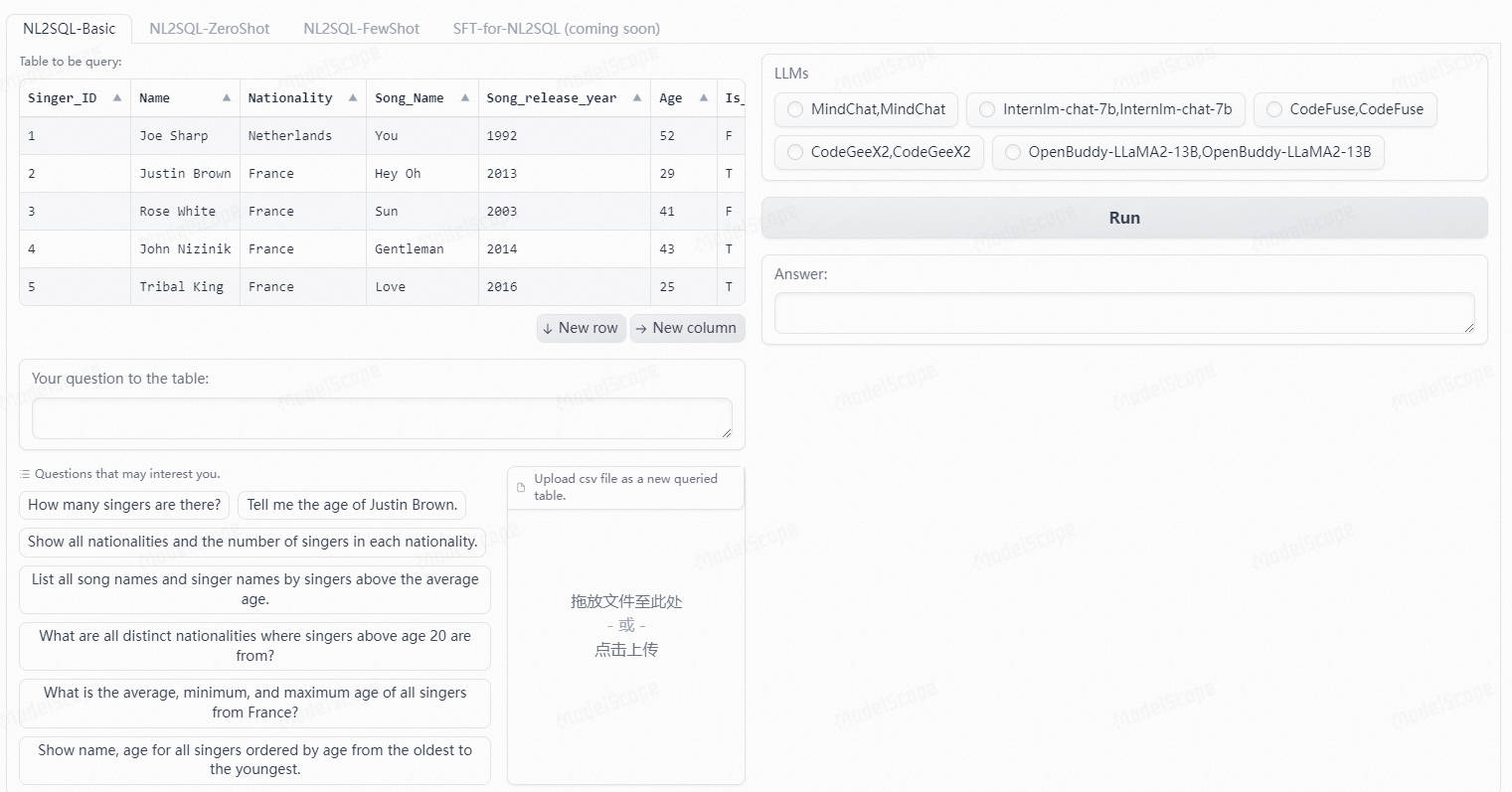
NL2SQL任务的目标是将用户对某个数据库的自然语言问题转化为相应的SQL查询。随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
1.DB-GPT
官方链接:https://github.com/eosphoros-ai/DB-GPT/blob/main/README.zh.md
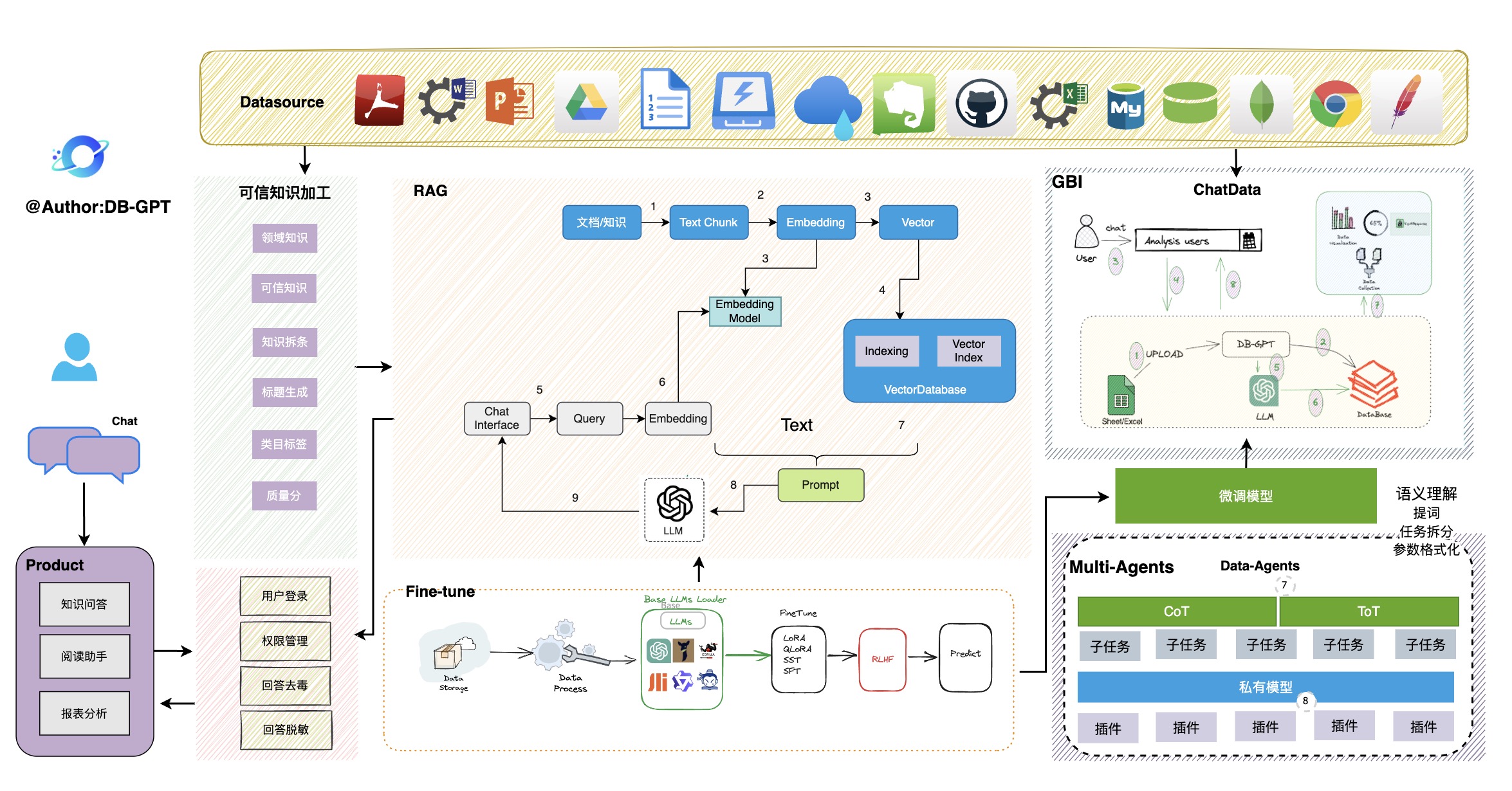
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。
目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
1.1 架构方案
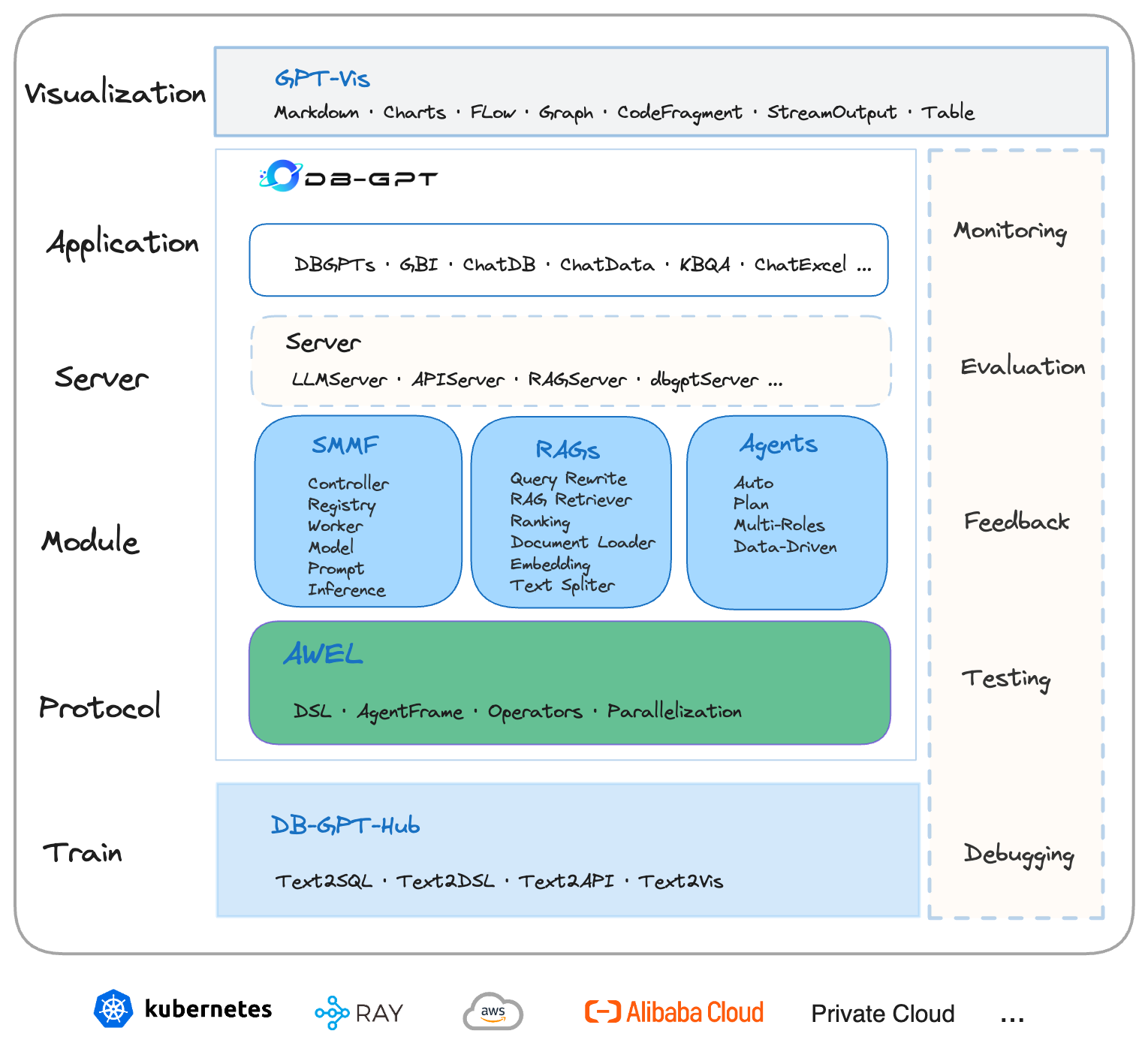
核心能力主要有以下几个部分:
-
RAG(Retrieval Augmented Generation),RAG是当下落地实践最多,也是最迫切的领域,DB-GPT目前已经实现了一套基于RAG的框架,用户可以基于DB-GPT的RAG能力构建知识类应用。
-
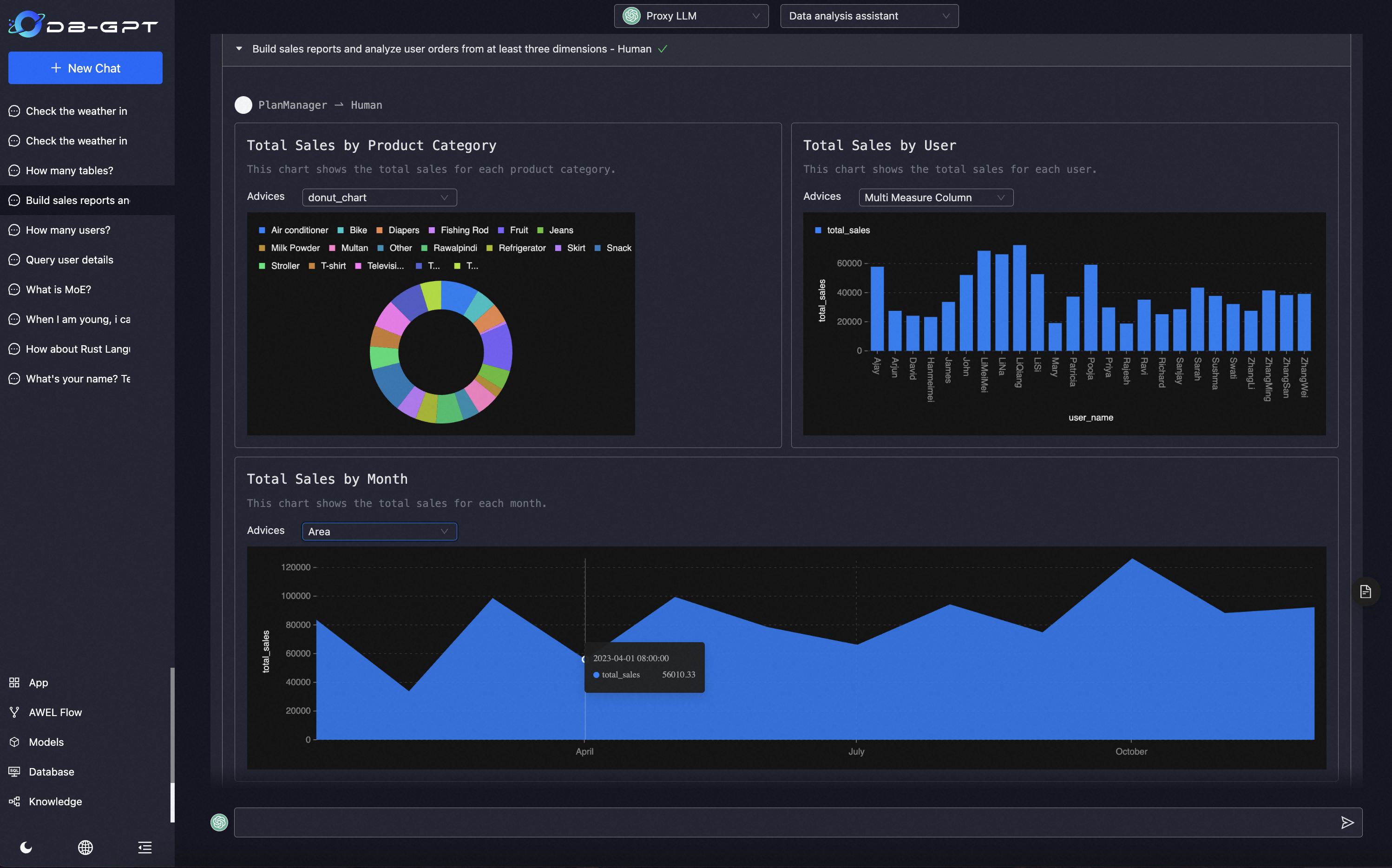
GBI:生成式BI是DB-GPT项目的核心能力之一,为构建企业报表分析、业务洞察提供基础的数智化技术保障。
-
微调框架: 模型微调是任何一个企业在垂直、细分领域落地不可或缺的能力,DB-GPT提供了完整的微调框架,实现与DB-GPT项目的无缝打通,在最近的微调中,基于spider的准确率已经做到了82.5%
-
数据驱动的Multi-Agents框架: DB-GPT提供了数据驱动的自进化Multi-Agents框架,目标是可以持续基于数据做决策与执行。
-
数据工厂: 数据工厂主要是在大模型时代,做可信知识、数据的清洗加工。
-
数据源: 对接各类数据源,实现生产业务数据无缝对接到DB-GPT核心能力。
1.2 RAG生产落地实践架构
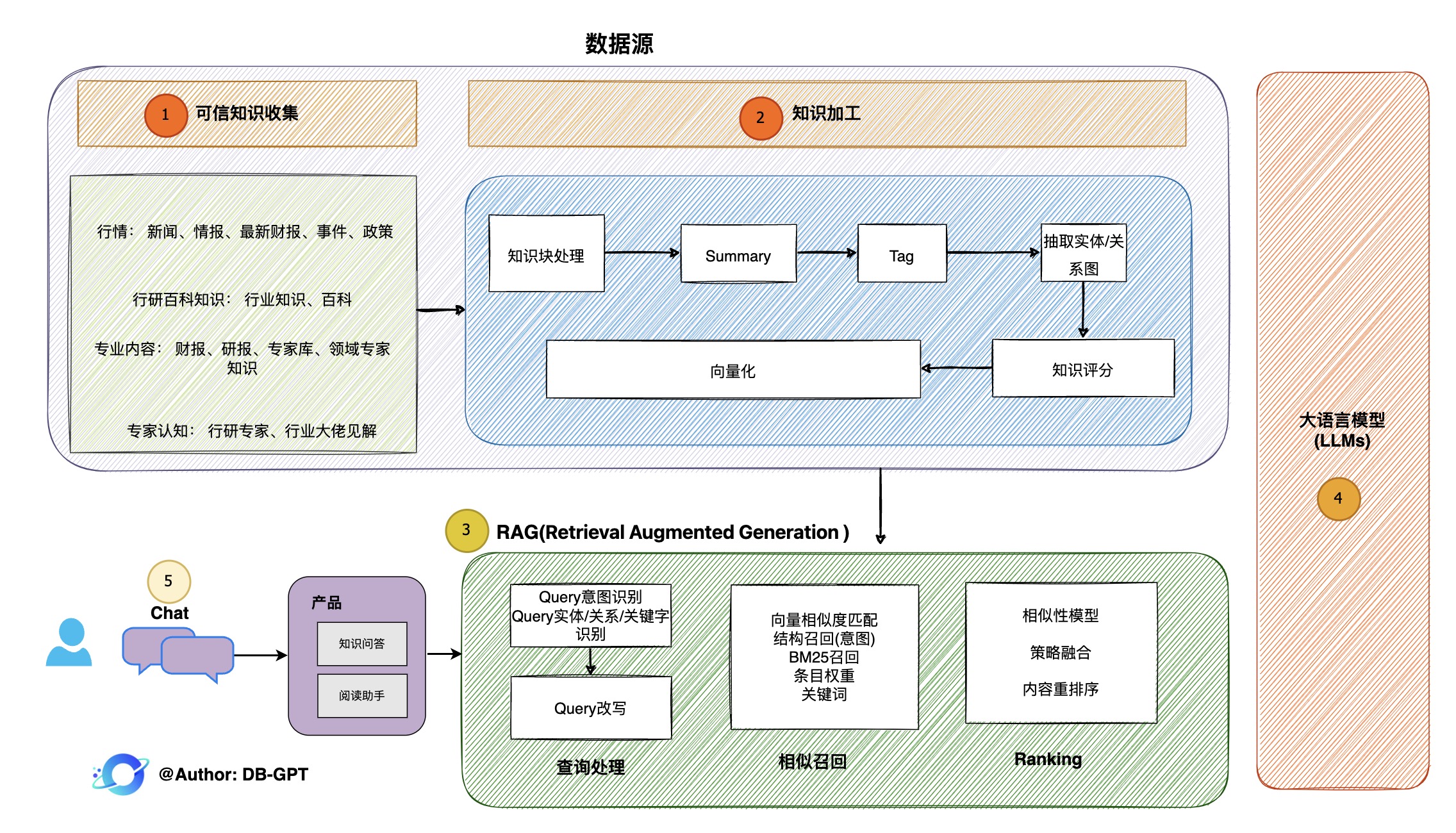
- 子模块
- DB-GPT-Hub 通过微调来持续提升Text2SQL效果
- DB-GPT-Plugins DB-GPT 插件仓库, 兼容Auto-GPT
- GPT-Vis 可视化协议

- 特性一览
-
私域问答&数据处理&RAG
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
-
多数据源&GBI
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。
-
自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。详见: DB-GPT-Hub
-
数据驱动的Agents插件
支持自定义插件执行任务,原生支持Auto-GPT插件模型,Agents协议采用Agent Protocol标准
-
多模型支持与管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱等。当前已支持如下模型:
-
更多内容官方链接:https://github.com/eosphoros-ai/DB-GPT/blob/main/README.zh.md
2.DAIL-SQL
DAIL-SQL是一种非常有效的方法,用于优化LLM在Text-to-SQL上的利用率。在GPT-4测试中,它在Spider排行榜上取得了86.2%的优异成绩,证明了自己的优势。值得注意的是,在蜘蛛侠开发中,每个问题只需要大约1600个令牌。除此之外,通过GPT-4的自一致性投票,我们在spider测试中获得了更高的86.6%的分数。
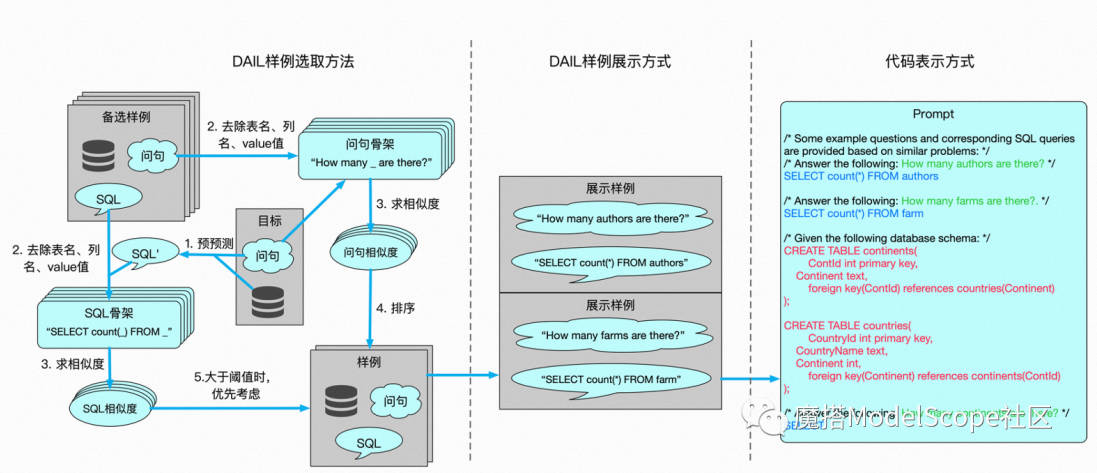
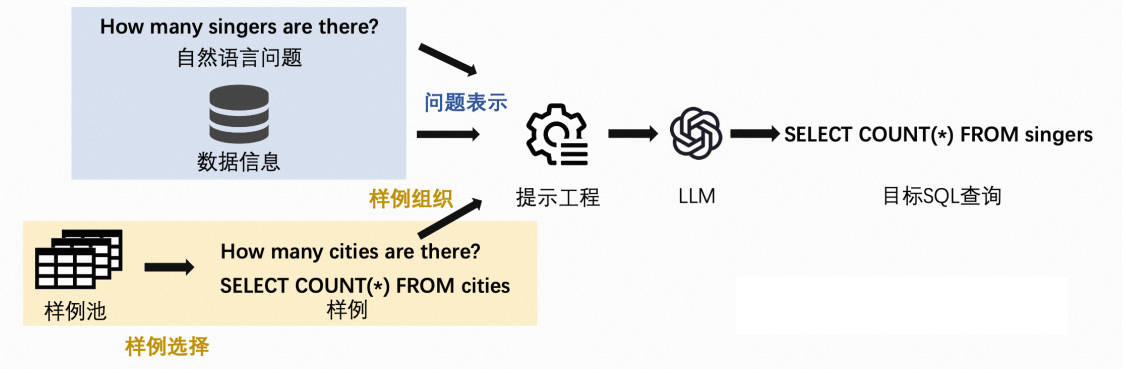
在问题的表示上,DAIL-SQL发现SQL语句加注释的代码表示方式可以有效发掘LLM在预训练中学习的代码能力。在样例的选择上,以往的方法着重于选择与用户问题相似的样例问题,或者选择与目标SQL相似的样例SQL。然而,DAIL-SQL发现通过同时考虑问题相似度和SQL相似度来选择样例,可以得到更好的结果。在样例的展示上,以往的方法通常会展示所有样例信息,包括问题、SQL和数据库信息,或者仅展示SQL以追求样例数量。DAIL-SQL采用了一种折中的方式,同时展示样例的问题和SQL,以保留问题和SQL之间的映射关系,并去除了token数最多的数据库信息,以确保能展示更多的样例。最终,DAIL-SQL在NL2SQL的国际权威榜单Spider上取得了86.6的执行准确率,比第二名的DIN-SQL高1.3个百分点。同时,每个问题大约只需700个token,比DIN-SQL少一个数量级。
零样本场景下评估了从其他作品中总结的五个问题表征,使用了四个llm: GPT-4, GPT-3.5-TURBO, text - davincic -003和Vicuna-33B
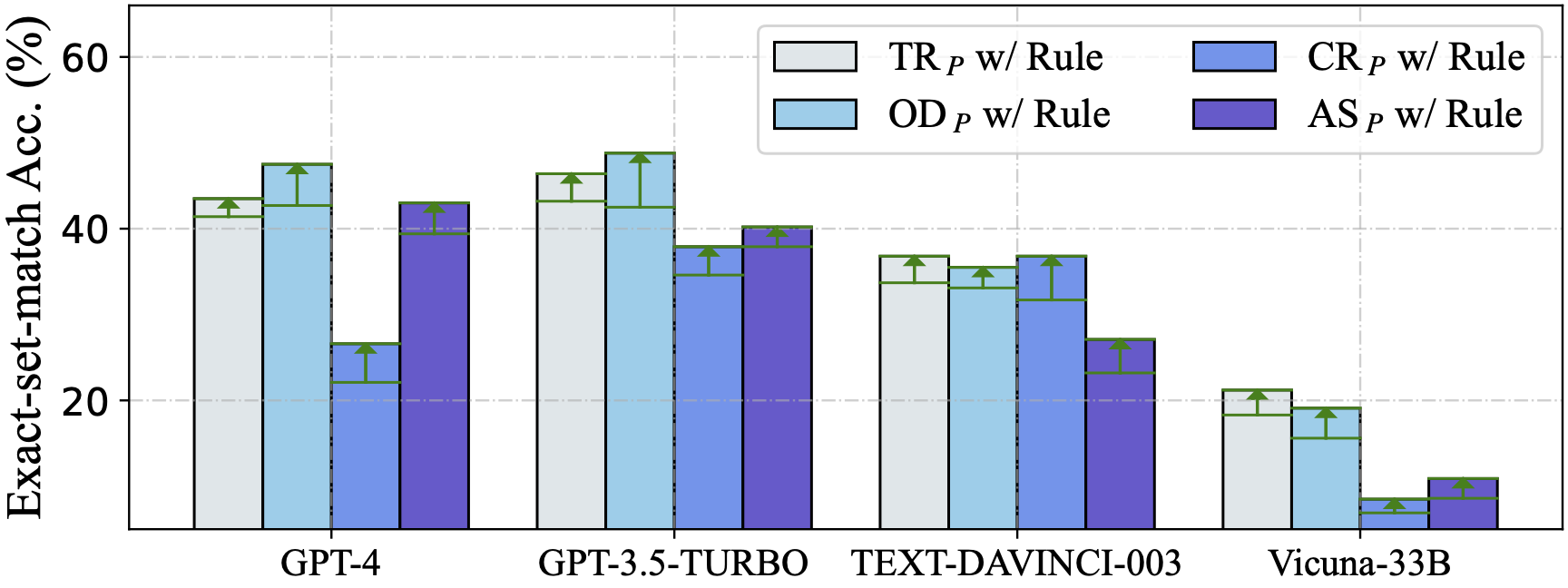
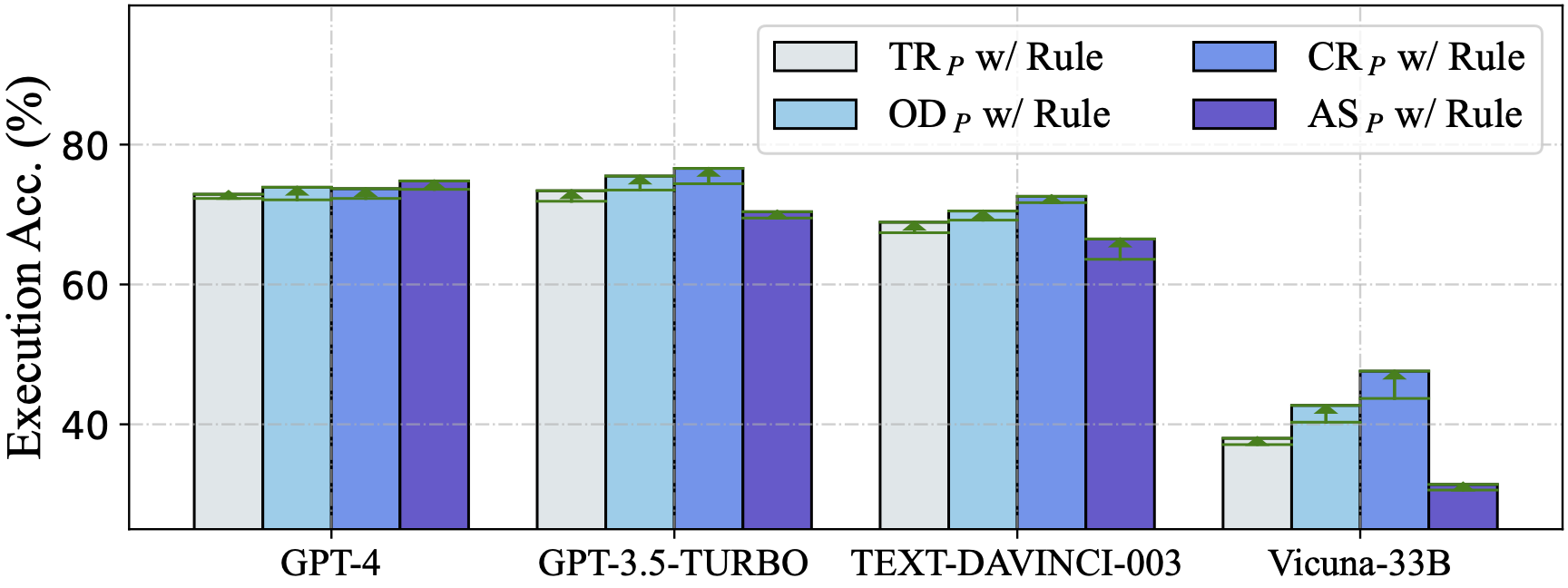
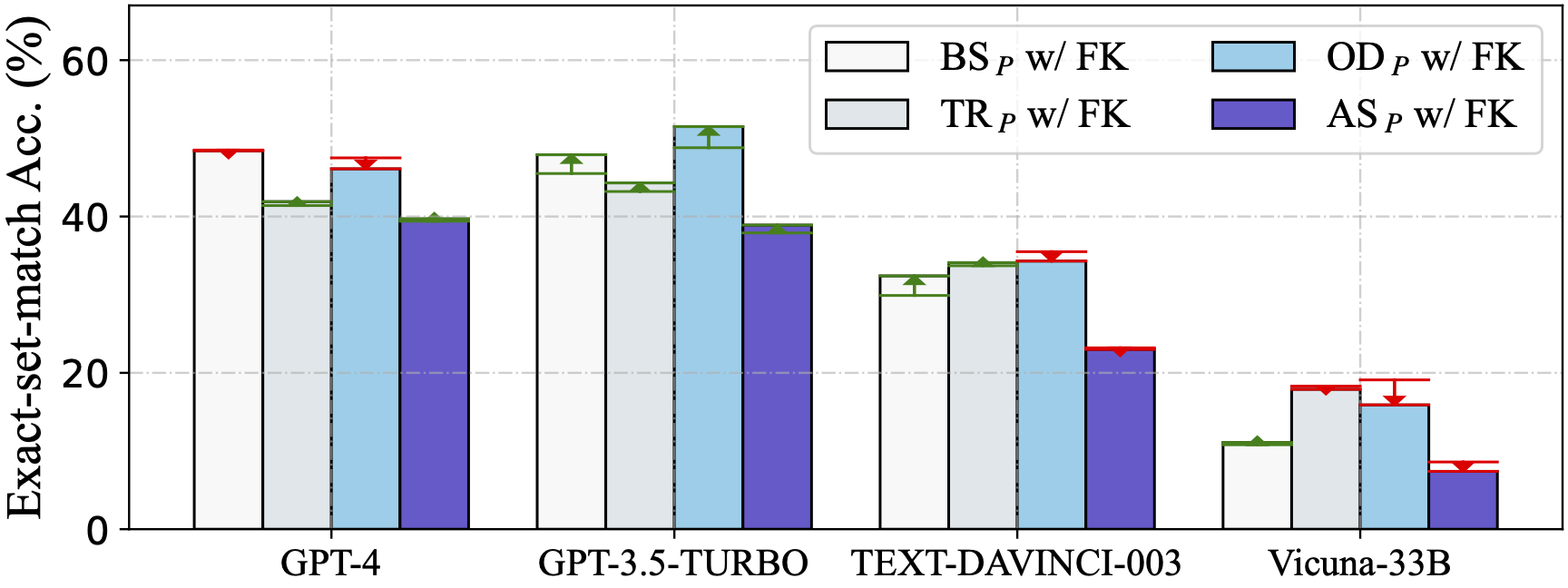
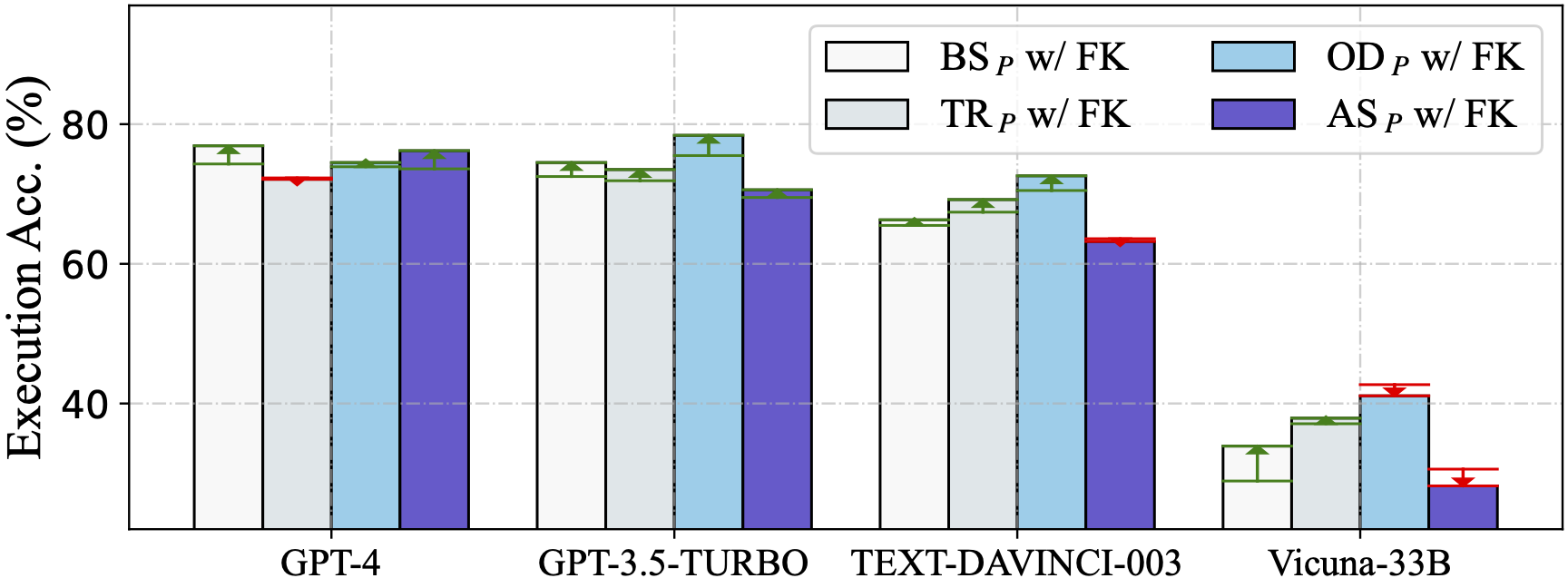
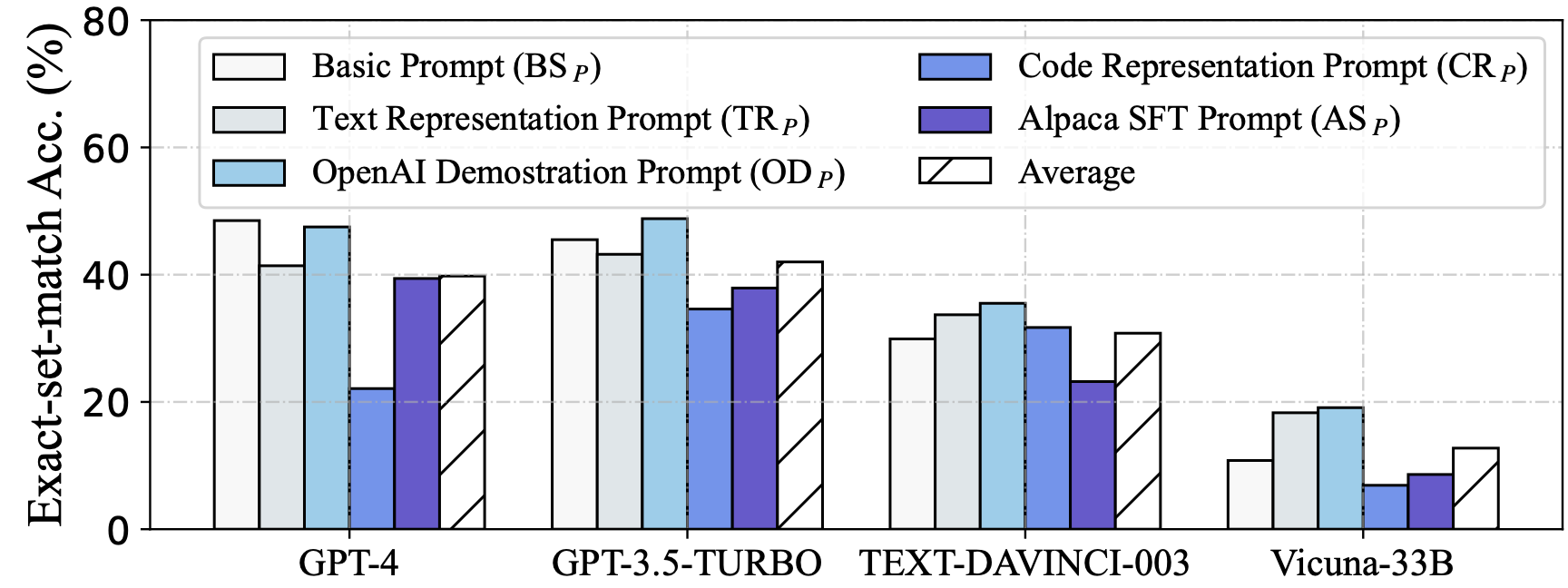
DAIL- sql组织与Full-Information和SQL-Only组织进行了对比,发现DAIL组织对于强大的llm来说是一种非常有效和高效的方法。
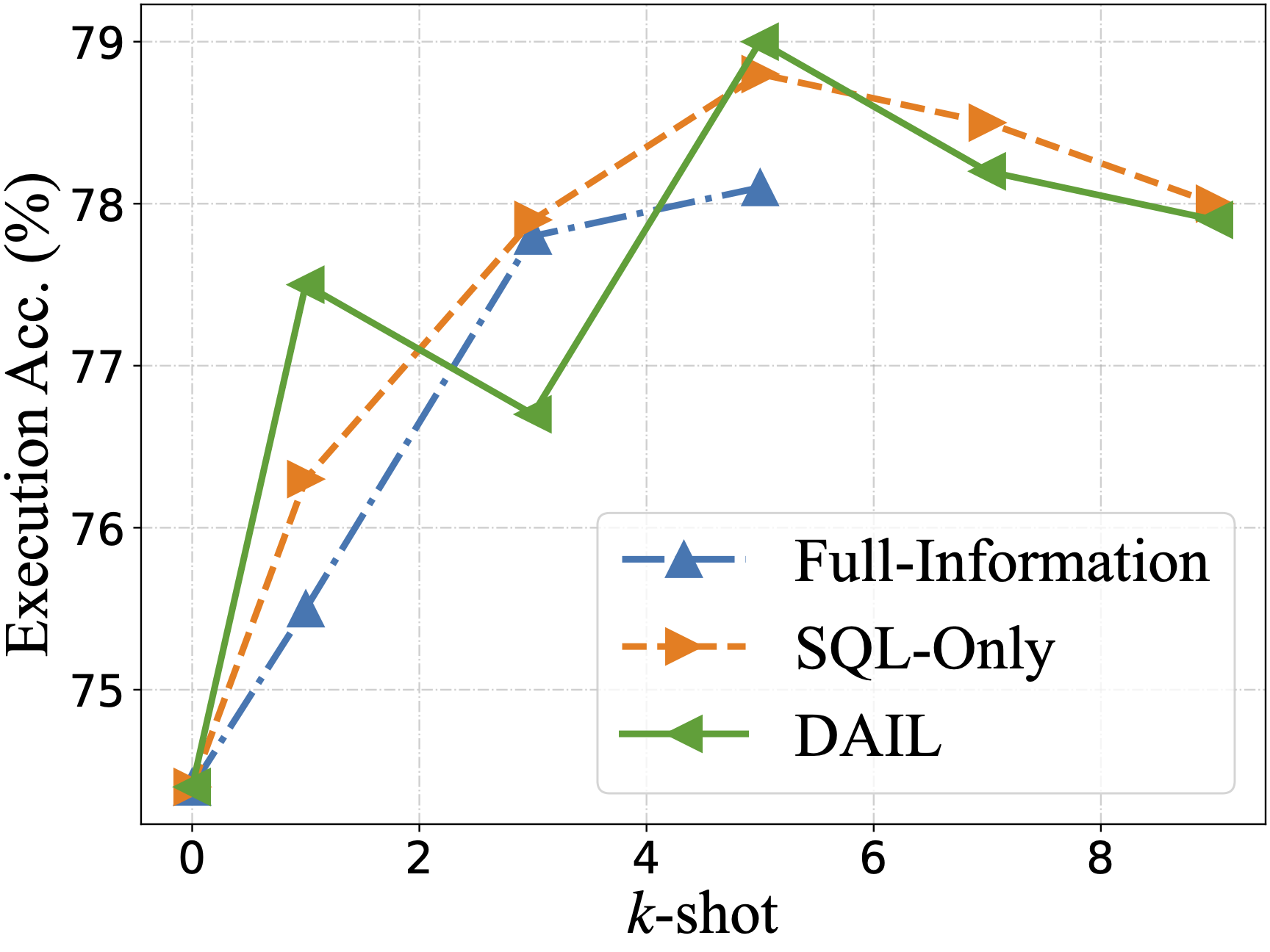
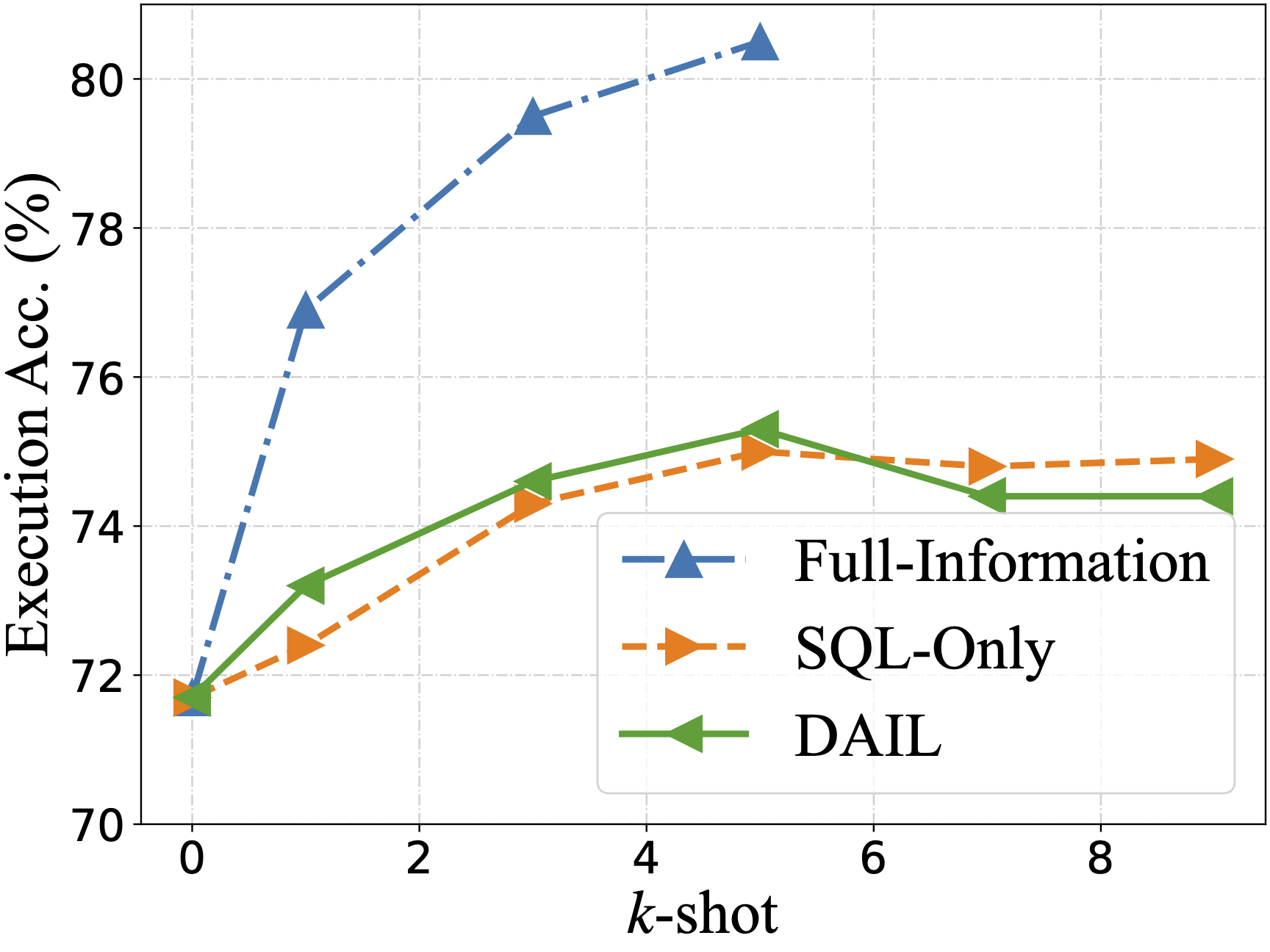
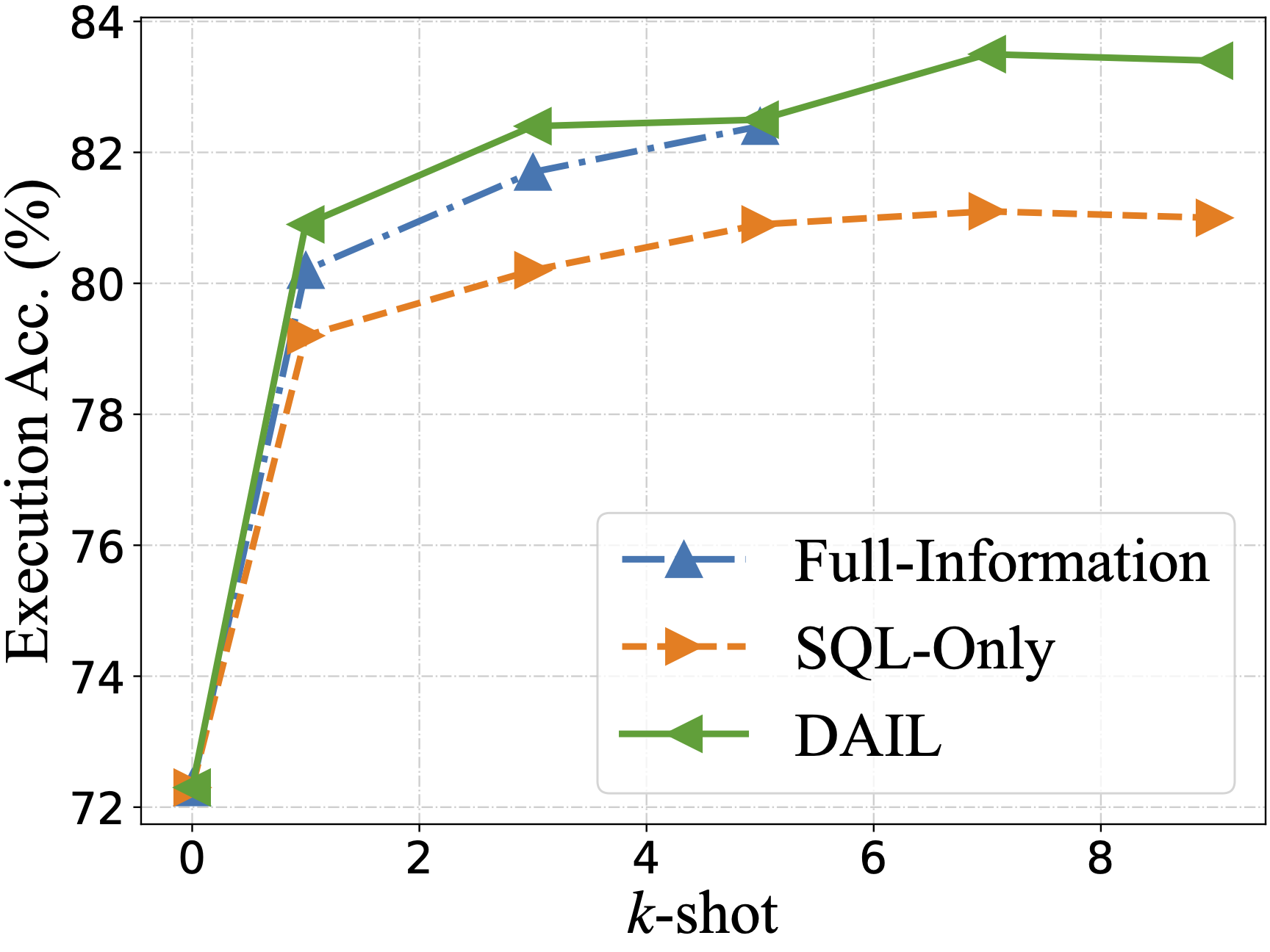
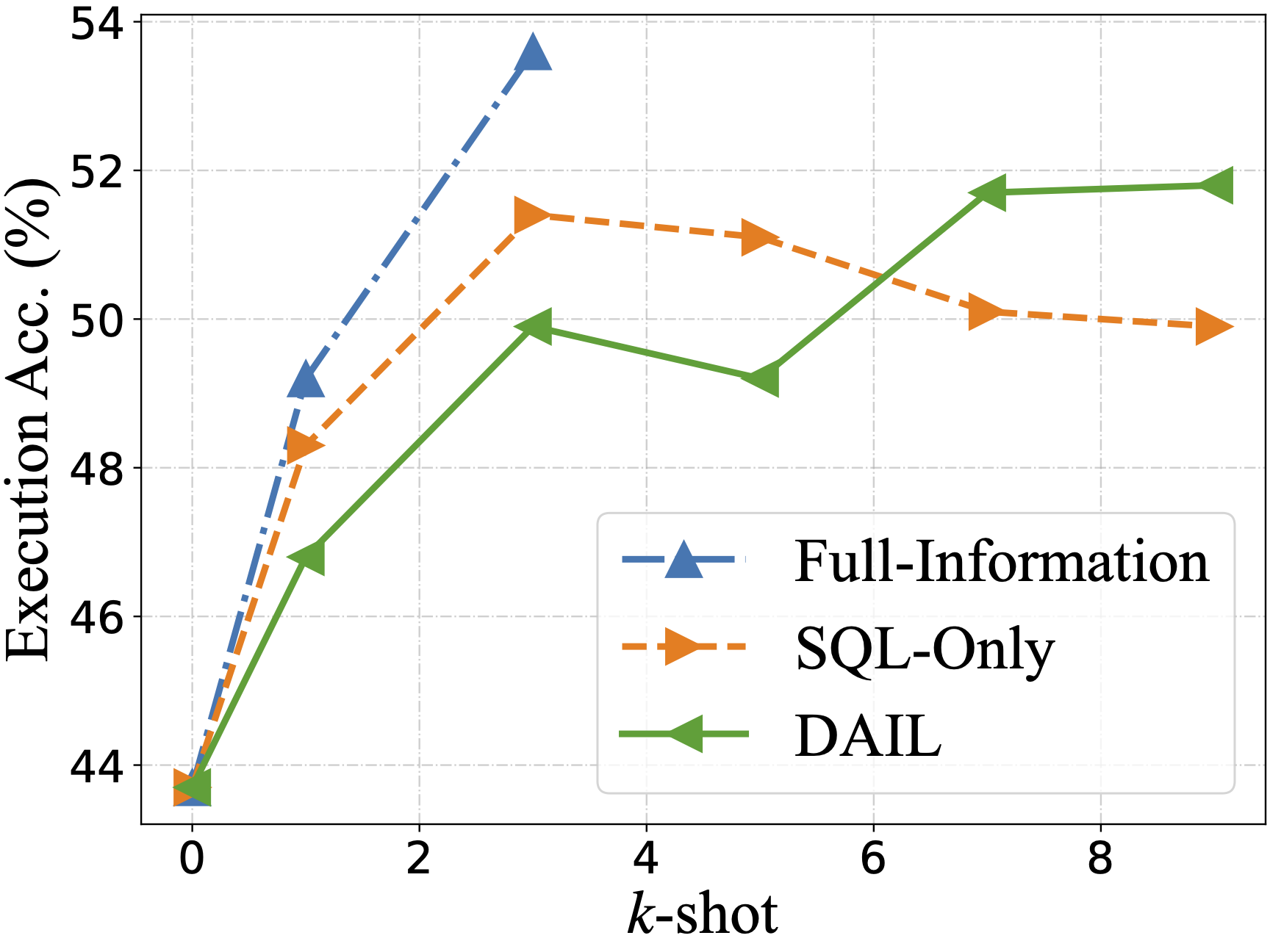
- 效果展示:
| Method | Dev EM | Dev EX | Test EM | Test EX |
| --------- | --------- | --------- | --------- | --------- |
| DAIL-SQL+GPT-4 | 70.0 | 83.1 | 66.5 | 86.2 |
| DAIL-SQL+GPT-4+Self-consistency | 68.7 | 83.6 | 66.0 | 86.6 |
-
Spider榜单:https://yale-lily.github.io/spider
-
参考链接
-
Awesome Text2SQL:https://github.com/eosphoros-ai/Awesome-Text2SQL/blob/main/README.zh.md
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
标签:DAIL,进阶,DB,NL2SQL,SQL,GPT,Text2SQL From: https://www.cnblogs.com/ting1/p/18130940