文 / 识货运维总监 瞿晟荣
识货APP致力于为广大用户提供专业的网购决策指导,为喜欢追求性价比的网购朋友带来及时劲爆的运动、潮流、生活、时尚等网购优惠资讯,产品覆盖国内外主流购物商城。它提供了全球范围内的时尚品牌、潮流单品的信息,帮助用户发现和购买最新、最热、最具性价比的时尚商品。近年来,各大电商平台上的商品信息持续增加,海量商品信息增加了消费者的选购成本。识货从用户视角出发,不断整合行业渠道供给,降低发现和筛选成本,帮助用户更高效地购买到最具性价比的产品。
1. 业务高速发展,平台挑战加剧
识货作为一个购物商城,为用户提供最核心的价值就是性价比。它提供的商品比价、价格订阅等特色服务为消费者在选购商品时提供了及时而精准的推荐。这一切归功于识货的数据加工平台,它负责收集同类商品全网渠道的价格信息、折扣信息、满减政策,并计算出同类商品在不同平台不同渠道的售价,通过数据服务平台推送给消费者,以便于准确锁定性价比最高的渠道。然而,随着商品种类的不断增加,大促政策的日趋复杂,数据加工平台面临着巨大的挑战。
1.1 大促期间,数据加工性能难以保证
现在各渠道平台大促期间满减、折扣越来越多样,越来越复杂。商品价格变更瞬息万变,为了在第一时间向消费者推送最及时的价格信息,数据加工性能尤为关键。在以往大促期间,最核心的价格变更动作就需要数小时完成,导致大促期间经常会接到业务部门的投诉,比如商品渠道价格波动、更新不及时等。我们也曾尝试使用更大规格的MySQL(104核),通过增加多个只读节点、读写分离、业务模块剥离等一系列举措,但问题始终得不到有效解决。
1.2 传统读写分离,延迟不可控,稳定性堪忧
为了缓解数据加工的压力,我们尝试剥离部分只读业务,通过只读实例实现读写分离,这也是大部分业务都会做的选择。然而,识货的情况有些特别,核心数据加工场景的复杂度和并发度都非常高,对数据库的写压力非常大,高峰期单单写的QPS就能突破20万,所以主备延迟是摆在我们面前很严峻的问题,当只读业务长时间读不到准确的数据时,我们又会被迫将其临时搬回主实例,又进一步加剧了主实例的压力,陷入了无穷的死循环当中。同时,过高的主备延迟,也给数据库自身稳定性带来了极大风险。
1.3 商城扩品在即,平台处理能力捉襟见肘
识货的GMV已突破百亿,规模持续增长,预计未来几年商城将扩品3~5倍,对识货整个数据加工平台的存储和计算能力都是非常严峻的考验。目前核心业务数据库已经是最高规格,升无可升,在过去的几年大促里,资源使用率偏高,处理能力急需突破。
2. 集中分布式一体化,性能提升400%
在过去的几年里,识货试图通过各种方式突破加工平台的性能瓶颈,也调研过市面上主流的分布式数据库产品,尝试通过分布式数据库的替换来解决当下问题。但是,市面上分布式数据库产品的架构、技术各不相同,为了发挥其最佳性能,都需要遵循各自的最佳实践。然而,识货的核心渠道库是自2012年创业以来的第一个库,经过十多年的沉淀,积累了众多业务模块,相互依赖关系错综复杂,且开发设计完全是单机习惯。一来很难将业务进行剥离,二来短期内也不具备分布式改造的可能,所以我们一直未能坚定地迈出分布式升级这条道路。
在我们踌躇不前、极度迷茫的时候,阿里云瑶池数据库技术团队从实际情况出发,为我们指出了一条不一样的分布式升级道路。PolarDB分布式版(PolarDB for Xscale,简称PolarDB-X)是集中分布式一体化的分布式数据库,对每一个表来说,既可以打散到不同的节点,也可以单节点存储。我们核心库的特点是表的个数非常多,并且单表体量也达到了亿级别,数据量仍然保持持续增长的势头。结合这两个特性,阿里云瑶池数据库技术团队给出了如下方案:
-
按业务模块区分,各个模块的表:
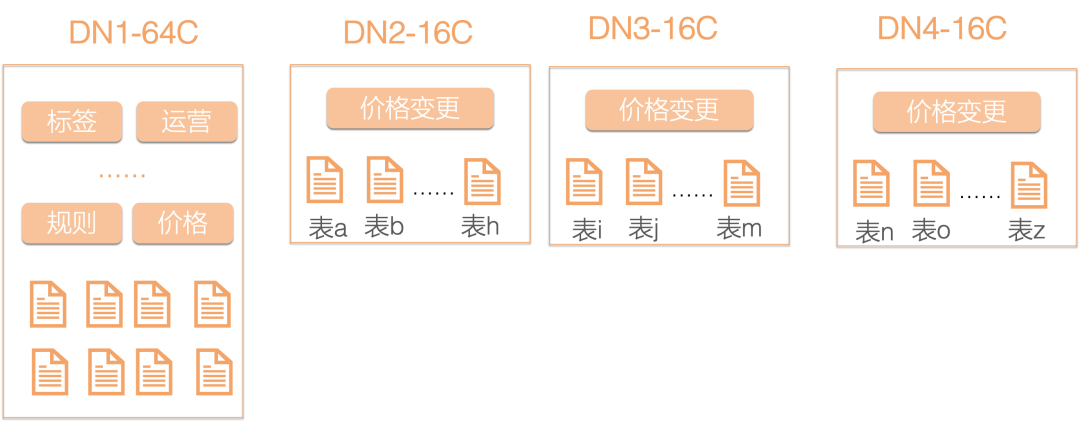
以单表形式存储在不同节点;
-
通过不同规格的DN支撑不同业务的特性,避免同一规格的DN带来的资源浪费;
-
通过Locality能力,确保任何表都具备任意节点间腾挪的能力,应对未来业务模型发生变化。
识货运维总监瞿晟荣表示:“这就好比我们拿出一个大规格的DN当作收纳桶,所有理不清业务逻辑的表先统一放在这里,一些核心流程上的关键业务表,我们进行单独的DN处理,上面通过CN统一管理调度,对业务代码完全无感,而底层已经悄悄完成了分布式的改造。”
在进行分布式改造后,经过大促实战验证,数据处理能力提升6倍,价格变更场景性能提升4倍,从小时级别缩短到分钟级别。

3. 平滑迁移,性价比提升500%
PolarDB分布式版除了提供极致的MySQL兼容,确保识货APP业务代码0修改之外,在整个迁移过程中,也提供了丰富的手段,助力我们完成丝滑地迁移。
3.1 热力分区图
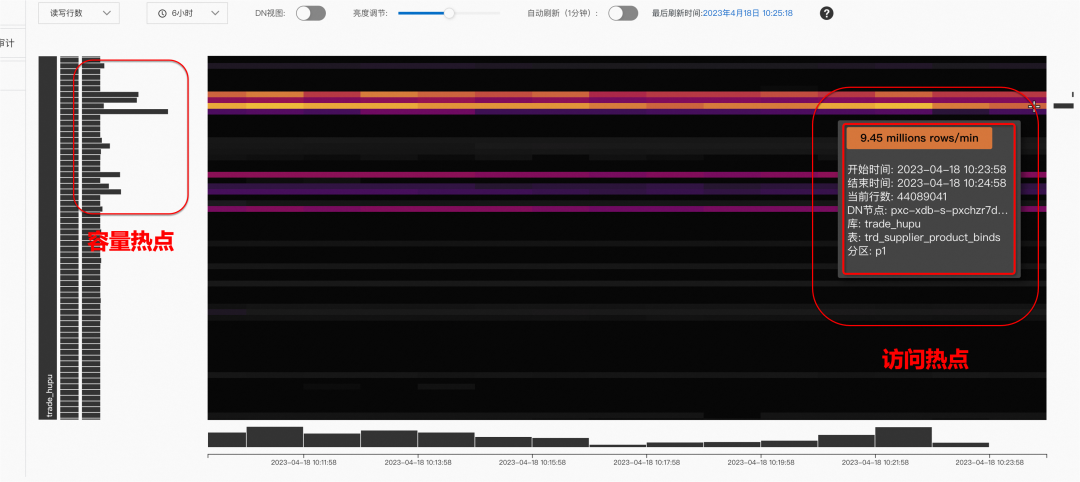
集中式往分布式的演进过程中,数据会被打散到不同节点,大家普遍担心的问题是:关联的表是否被打散到了不同的节点带来了性能瓶颈?是否访问频繁的表被打散到了同一个节点上?导致该节点资源消耗过大。
为了解决上述困扰,PolarDB分布式版提供了热力分区的功能,通过可视化的方式,实时观测各个节点的容量瓶颈和访问瓶颈,准确定位大大降低了迁移和日常运维的难度。
3.2 智能压测
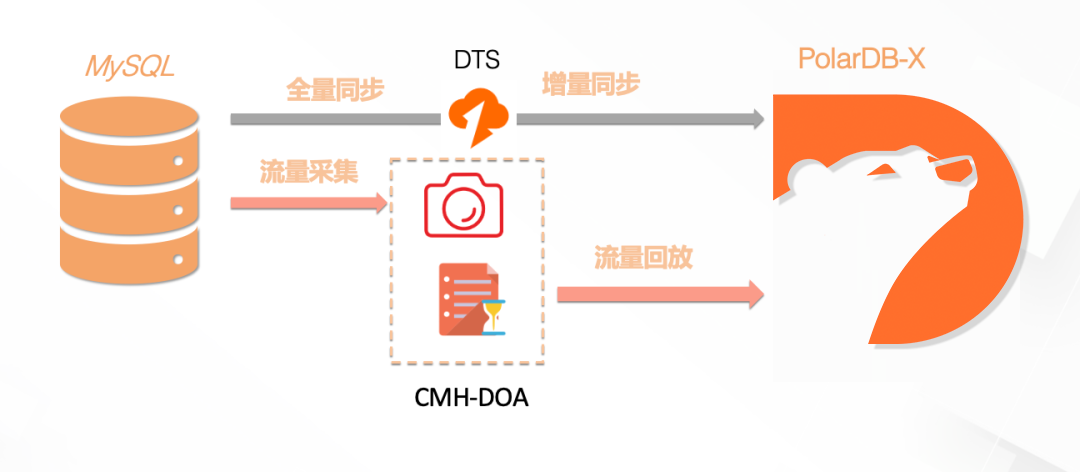
核心渠道库数据加工逻辑的大量信息是来自淘宝、亚马逊、拼多多等渠道的实时价格信息,在测试环境下无法模拟,导致我们无法在测试环境进行业务压测,这给割接带来了很大风险。阿里云提供了智能压测方案CMH-DOA(也称frodo),CMH-DOA可以全量录制原生产端MySQL的全量SQL,在目标端PolarDB分布式版进行完整回放。不仅保证执行顺序与生产保持一致,同时也支持倍速回放,能够模拟更大的生产压力场景。让我们对当前数据库实例的处理能力拥有非常好的判断基准,不仅降低了割接风险,也为未来大促扩容提供了很好的参考依据。该工具目前已开源,相信未来会帮助更多的开源或商业用户,让分布式这条路更加丝滑平顺:
标签:15,数据库,节点,大促,识货,PolarDB,分布式 From: https://www.cnblogs.com/aliyunyaochidatabase/p/18066203