对于 MySQL 的 JOIN,不知道大家有没有去想过他的执行流程,亦或有没有怀疑过自己的理解;如果大家不知道怎么检验,可以试着回答如下的问题。
驱动表的选择:MySQL 会如何选择驱动表,按从左至右的顺序选择第一个?
多表连接的顺序
假设我们有 3 张表:A、B、C,和如下 SQL
-- 伪 SQL,不能直接执行
A LEFT JOIN B ON B.aId = A.id
LEFT JOIN C ON C.aId = A.id
WHERE A.name = '666' AND B.state = 1 AND C.create_time > '2019-11-22 12:12:30'是 A 和 B 联表处理完之后的结果再和 C 进行联表处理,还是 A、B、C 一起联表之后再进行过滤处理 ,还是说这两种都不对,有其他的处理方式 ?
ON、WHERE 的生效时机
无意之间逛到了一篇博文,它里面有如下介绍

摘自 Mysql - JOIN详解
看完这个,第一时间有发现新大陆的感觉,原来 JOIN 的执行顺序是这样的,可后面越想越不对,感觉像是学错了技能。
如果两表各有几百上千万的数据,那这两张表做笛卡尔积,结果不敢想象!也就是说 正经图1 中的顺序还有待商榷,ON 和 WHERE 的生效时间也有待商榷。
如果你对上述问题都了如指掌,那请你走开,别妨碍我装逼;如果你对上述问题还不是特别清楚,那么请坐好,我要开始装逼了。
驱动表
何谓驱动表,指多表关联查询时,第一个被处理的表,亦可称之为基表,然后再使用此表的记录去关联其他表。
驱动表的选择遵循一个原则:在对最终结果集没影响的前提下,优先选择结果集最少的那张表作为驱动表。
这个原则说的不好懂,结果集最少,这个也许我们能估出来,但对最终结果集不影响,这个就不好判断了,难归难,但还是有一定规律的:
LEFT JOIN 一般以左表为驱动表(RIGHT JOIN一般则是右表 ),INNER JOIN 一般以结果集少的表为驱动表,如果还觉得有疑问,则可用 EXPLAIN 来找驱动表,其结果的第一张表即是驱动表。 你以为 EXPLAIN 就一定准吗 ? 执行计划在真正执行的时候是可能改变的! 绝大多少情况下是适用的,特别是 EXPLAIN。
LEFT JOIN 某些情况下会被查询优化器优化成 INNER JOIN;结果集指的是表中记录过滤后的结果,而不是表中的所有记录,如果无过滤条件则是表中所有记录
SQL 执行的流程图
当我们向 MySQL 发送一个请求的时候,MySQL 到底做了些了什么?
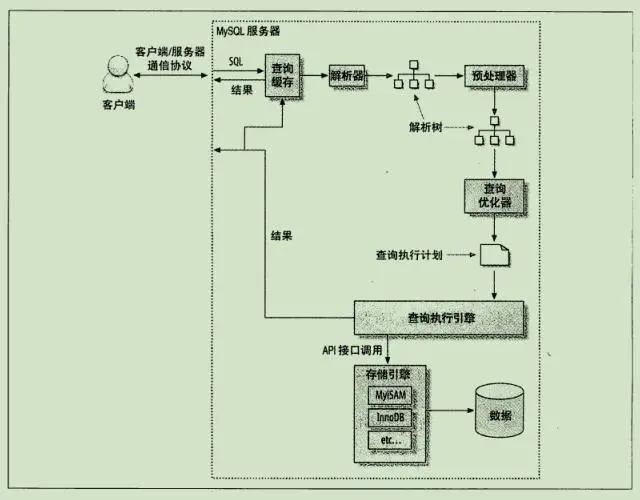
SQL 执行路径,摘自《高性能MySQL》
可以看到,执行计划是查询优化器的输出结果,执行引擎根据执行计划来查询数据。
数据准备
MySQL 5.7.1,InnoDB 引擎;建表 SQL 和 数据初始 SQL
-- 表创建与数据初始化
DROP TABLE IF EXISTS tbl_user;
CREATE TABLE tbl_user (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
sex TINYINT(1) NOT NULL COMMENT '性别, 1:男,0:女',
create_time datetime NOT NULL COMMENT '创建时间',
update_time datetime NOT NULL COMMENT '更新时间',
remark VARCHAR(255) NOT NULL DEFAULT '' COMMENT '备注',
PRIMARY KEY (id)
) COMMENT='用户表';
DROP TABLE IF EXISTS tbl_user_login_log;
CREATE TABLE tbl_user_login_log (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
ip VARCHAR(15) NOT NULL COMMENT '登录IP',
client TINYINT(1) NOT NULL COMMENT '登录端, 1:android, 2:ios, 3:PC, 4:H5',
create_time datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (id)
) COMMENT='登录日志';
INSERT INTO tbl_user(user_name,sex,create_time,update_time,remark) VALUES
('何天香',1,NOW(), NOW(),'朗眉星目,一表人材'),
('薛沉香',0,NOW(), NOW(),'天星楼的总楼主薛摇红的女儿,也是天星楼的少总楼主,体态丰盈,乌发飘逸,指若春葱,袖臂如玉,风姿卓然,高贵典雅,人称“天星绝香”的武林第一大美女'),
('慕容兰娟',0,NOW(), NOW(),'武林东南西北四大世家之北世家慕容长明的独生女儿,生得玲珑剔透,粉雕玉琢,脾气却是刚烈无比,又喜着火红,所以人送绰号“火凤凰”,是除天星楼薛沉香之外的武林第二大美女'),
('苌婷',0,NOW(), NOW(),'当今皇上最宠爱的侄女,北王府的郡主,腰肢纤细,遍体罗绮,眉若墨画,唇点樱红;虽无沉香之雅重,兰娟之热烈,却别现出一种空灵'),
('柳含姻',0,NOW(), NOW(),'武林四绝之一的添愁仙子董婉婉的徒弟,体态窈窕,姿容秀丽,真个是秋水为神玉为骨,芙蓉如面柳如腰,眉若墨画,唇若点樱,不弱西子半分,更胜玉环一筹; 摇红楼、听雨轩,琵琶一曲值千金!'),
('李凝雪',0,NOW(), NOW(),'李相国的女儿,神采奕奕,英姿飒爽,爱憎分明'),
('周遗梦',0,NOW(), NOW(),'音神传人,湘妃竹琴的拥有者,云髻高盘,穿了一身黑色蝉翼纱衫,愈觉得冰肌玉骨,粉面樱唇,格外娇艳动人'),
('叶留痕',0,NOW(), NOW(),'圣域圣女,肤白如雪,白衣飘飘,宛如仙女一般,微笑中带着说不出的柔和之美'),
('郭疏影',0,NOW(), NOW(),'扬灰右使的徒弟,秀发细眉,玉肌丰滑,娇润脱俗'),
('钟钧天',0,NOW(), NOW(),'天界,玄天九部 - 钧天部的部主,超凡脱俗,仙气逼人'),
('王雁云',0,NOW(), NOW(),'尘缘山庄二小姐,***蛮任性'),
('许侍霜',0,NOW(), NOW(),'药王谷谷主女儿,医术高明'),
('冯黯凝',0,NOW(), NOW(),'桃花门门主,娇艳如火,千娇百媚');
INSERT INTO tbl_user_login_log(user_name, ip, client, create_time) VALUES
('薛沉香', '10.53.56.78',2, '2019-10-12 12:23:45'),
('苌婷', '10.53.56.78',2, '2019-10-12 22:23:45'),
('慕容兰娟', '10.53.56.12',1, '2018-08-12 22:23:45'),
('何天香', '10.53.56.12',1, '2019-10-19 10:23:45'),
('柳含姻', '198.11.132.198',2, '2018-05-12 22:23:45'),
('冯黯凝', '198.11.132.198',2, '2018-11-11 22:23:45'),
('周遗梦', '198.11.132.198',2, '2019-06-18 22:23:45'),
('郭疏影', '220.181.38.148',3, '2019-10-21 09:45:56'),
('薛沉香', '220.181.38.148',3, '2019-10-26 22:23:45'),
('苌婷', '104.69.160.60',4, '2019-10-12 10:23:45'),
('王雁云', '104.69.160.61',4, '2019-10-16 20:23:45'),
('李凝雪', '104.69.160.62',4, '2019-10-17 20:23:45'),
('许侍霜', '104.69.160.63',4, '2019-10-18 20:23:45'),
('叶留痕', '104.69.160.64',4, '2019-10-19 20:23:45'),
('王雁云', '104.69.160.65',4, '2019-10-20 20:23:45'),
('叶留痕', '104.69.160.66',4, '2019-10-21 20:23:45');
SELECT * FROM tbl_user;
SELECT * FROM tbl_user_login_log;单表查询
单表查询的过程比较好理解,大致如下
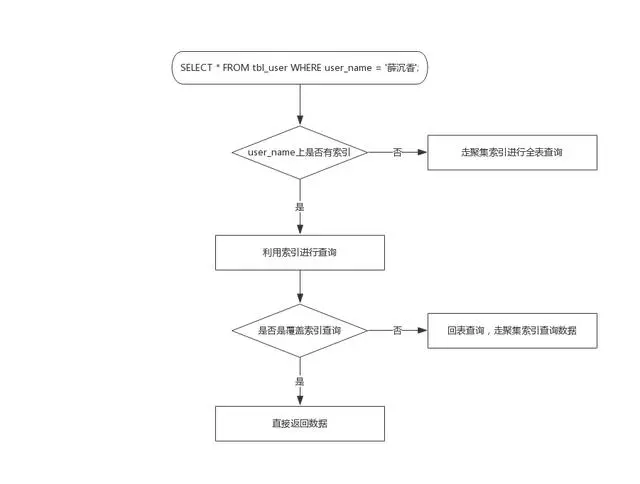
关于单表查询就不细讲了,主要涉及到:聚集索引,覆盖索引、回表操作,知道这 3 点,上图就好理解了(不知道的赶快去查资料,暴露了就丢人了!)。
联表算法
MySQL 的联表算法是基于嵌套循环算法(nested-loop algorithm)而衍生出来的一系列算法,根据不同条件而选用不同的算法:
- 在使用索引关联的情况下,有 Index Nested-Loop join 和 Batched Key Access join 两种算法;
- 在未使用索引关联的情况下,有 Simple Nested-Loop join 和 Block Nested-Loop join 两种算法。
Simple Nested-Loop
简单嵌套循环,简称 SNL;逐条逐条匹配,就像这样
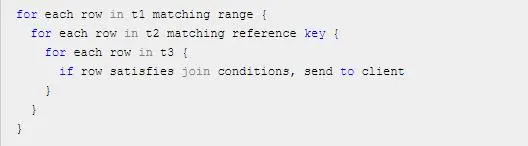
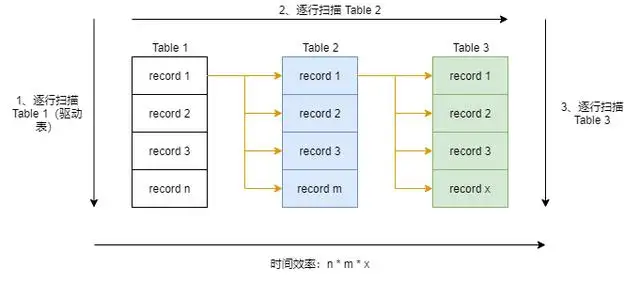
这种算法简单粗暴,但毫无性能可言,时间性能上来说是 n(表中记录数) 的 m(表的数量) 次方,所以 MySQL 做了优化,联表查询的时候不会出现这种算法,即使在无 WHERE 条件且 ON 的连接键上无索引时,也不会选用这种算法
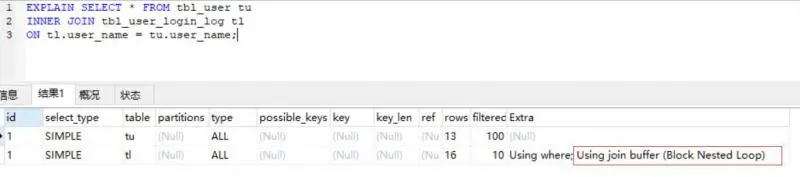
Block Nested-Loop
缓存块嵌套循环连接,简称 BNL,是对 INL 的一种优化;一次性缓存多条驱动表的数据,然后拿 Join Buffer 里的数据批量与内层循环读取的数据进行匹配,就像这样

将内部循环中读取的每一行与缓冲区中的所有记录进行比较,这样就可以减少内层循环的读表次数。举个例子,如果没有 Join Buffer,驱动表有 30 条记录,被驱动表有 50 条记录,那么内层循环的读表次数应该是 30 * 50 = 1500,如果 Join Buffer 可用并可以存 10 条记录(Join Buffer 存储的是驱动表中参与查询的列,包括 SELECT 的列、ON 的列、WHERE 的列,而不是驱动表中整行整行的完整记录),那么内层循环的读表次数应该是 30 / 10 * 50 = 150,被驱动表必须读取的次数减少了一个数量级。
当被驱动表在连接键上无索引且被驱动表在 WHERE 过滤条件上也没索引时,常常会采用此种算法来完成联表,如下所示
Index Nested-Loop
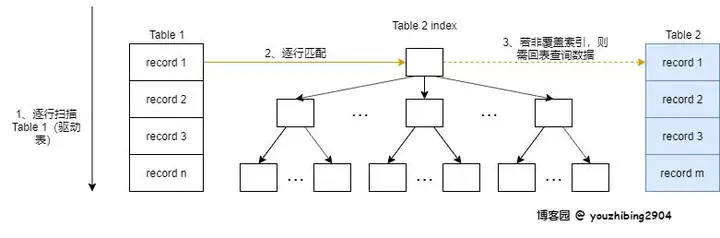
索引嵌套循环,简称 INL,是基于被驱动表的索引进行连接的算法;驱动表的记录逐条与被驱动表的索引进行匹配,避免和被驱动表的每条记录进行比较,减少了对被驱动表的匹配次数,大致流程如下图:
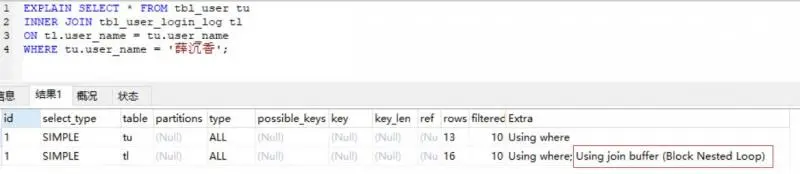
我们来看看实际案例,先给 tbl_user_login_log 添加索引 ALTER TABLE tbl_user_login_log ADD INDEX idx_user_name (user_name); ,我们再来看联表执行计划:
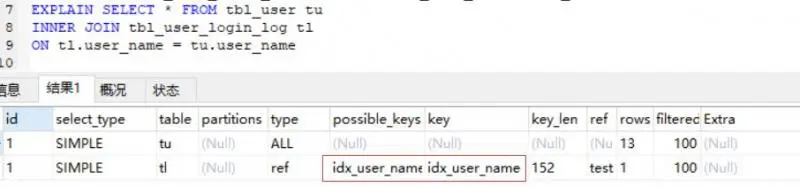
可以看到 tbl_user_login_log 的索引生效了,我们再往下看:

有趣的事发生了,驱动表变成了 tbl_user_login_log ,而 tbl_user 成了被驱动表, tbl_user_login_log 走索引过滤后得到结果集,再通过 BNL 算法将结果集与 tbl_user 进行匹配。这其实是 MySQL进行了优化,因为 tbl_user_login_log 走索引过滤后得到的结果集比 tbl_user 记录数要少,所以选择了 tbl_user_login_log 作为驱动表,后面的也就理所当然了,是不是感觉 MySQL 好强大?
总结
1、驱动表的选择有它的一套算法,有兴趣的可以去专研下;比较靠谱的确定方法是用 EXPLAIN
2、联表顺序,不是两两联合之后,再去联合第三张表,而是驱动表的一条记录穿到底,匹配完所有关联表之后,再取驱动表的下一条记录重复联表操作;
3、MySQL 的连接算法基于嵌套循环算法,基于不同的情况而采用不同的衍生算法
4、关于 ON 和 WHERE,我们下篇详细讲解,大家可以先考虑下它们的区别,以及生效时
标签:10,NOW,JOIN,45,tbl,MySQL,驱动,执行,user From: https://www.cnblogs.com/shijianchuzhenzhi/p/18056945