背景
假如有一张千万级的订单表,这张表没有采用分区分表,也没有使用ES等技术,分页查询进行到一定深度分页之后(比如1000万行后)查询比较缓慢,我们该如何进行优化?
数据准备
订单表结构如下:
CREATE TABLE `t_order` (
`id` BIGINT ( 20 ) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`order_no` VARCHAR ( 16 ) NOT NULL DEFAULT '' COMMENT '订单编号',
`customer_no` VARCHAR ( 16 ) NOT NULL DEFAULT '' COMMENT '客户编号',
`order_status` TINYINT ( 4 ) NOT NULL DEFAULT 0 COMMENT '订单状态',
`warehouse_code` VARCHAR ( 16 ) NOT NULL DEFAULT '' COMMENT '发货地仓库编码',
`country` VARCHAR ( 16 ) NOT NULL DEFAULT '' COMMENT '收货人国家',
`state` VARCHAR ( 32 ) NOT NULL DEFAULT '' COMMENT '收货人州',
`city` VARCHAR ( 32 ) NOT NULL DEFAULT '' COMMENT '收货人城市',
`street` VARCHAR ( 256 ) NOT NULL DEFAULT '' COMMENT '收货人街道',
`zip_code` VARCHAR ( 32 ) NOT NULL DEFAULT '' COMMENT '收货人邮编',
`contact_email` VARCHAR ( 128 ) NOT NULL DEFAULT '' COMMENT '收货人邮箱',
`contact_name` VARCHAR ( 32 ) NOT NULL DEFAULT '' COMMENT '收货人姓名',
`contact_mobile` VARCHAR ( 32 ) NOT NULL DEFAULT '' COMMENT '收货人手机号',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted` TINYINT ( 2 ) NOT NULL DEFAULT 0 COMMENT '是否已被删除',
PRIMARY KEY ( `id` ),
KEY `idx_customer` ( `customer_no`, `deleted` ),
KEY `idx_create_time` ( `create_time`, `deleted` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT = '销售订单表';
其中Mysql版本为8.0。我们使用Python脚本向表中插入2000万条数据。
import pymysql
from faker import Faker
import random
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor
# MySQL 连接配置
db_config = {
'host': 'your_database_host',
'user': 'your_database_user',
'password': 'your_database_password',
'database': 'your_database_name'
}
# 创建 MySQL 连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 使用 Faker 生成模拟数据
fake = Faker()
# 获取国家下发货仓库编码
def generate_warehousecode(country):
if country == "US":
return "US-"+random.choice(["WEST", "EAST", "MIDDLE", "SOUTH", "NORTH"])+"-0" + str(random.choice([1, 2, 3, 4, 5]))
else:
return country + "00" + str(random.choice([1, 2, 3, 4, 5]))
# 插入 t_order 表数据(多线程并发,每个线程插入1万条,共2000个线程)
def insert_data_thread(thread_id):
# 创建 MySQL 连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
order_data = []
for _ in range(10000):
order_no = "OC"+ fake.uuid4()[:12] # 取前16位
customer_no = fake.uuid4()[:16]
order_status = random.choice([1, 2, 3, 4, 5])
country = random.choice(
["CA", "US", "MX", "JP", "UK", "TR", "DE", "ES", "FR", "IT", "NL", "PL", "SE", "BR", "CN"])
warehouse_code = generate_warehousecode(country)
state = fake.uuid4()[:16]
city = fake.uuid4()[:16]
street = fake.uuid4()
zip_code = fake.uuid4()[:6]
contact_email = fake.email()
contact_name = fake.name()
contact_mobile = fake.phone_number()
create_time = fake.date_time_between(start_date=datetime(2019, 1, 1), end_date=datetime.now())
update_time = create_time
deleted = 0 # 默认未删除
cursor.execute("""
INSERT INTO t_order ( order_no, customer_no, order_status, warehouse_code, country, state, city, street, zip_code, contact_email, contact_name, contact_mobile, create_time, update_time, deleted ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) """, (order_no, customer_no, order_status, warehouse_code, country,
state, city, street, zip_code, contact_email, contact_name,
contact_mobile, create_time, update_time, deleted))
order_data.append((cursor.lastrowid, order_no, customer_no, create_time)) # 保存插入的行的 ID
# 提交 t_order 数据插入
conn.commit()
print(thread_id+ "已经跑完10000条数据。。。。。。。。。")
# 关闭数据库连接
cursor.close()
conn.close()
# 使用 ThreadPoolExecutor 并发插入
with ThreadPoolExecutor(max_workers=10) as executor: # 可以根据需要调整最大线程数
executor.map(insert_data_thread, range(500))
问题复现
导出数据时我们需要按照时间倒序。所以我们先执行以下sql查询前100条
select * FROM t_order ORDER BY create_time desc LIMIT 100;
共花费210ms。执行计划如下:

然后我们继续执行sql,我们从第100万行开始取100条数据:
select * FROM t_order ORDER BY create_time desc LIMIT 1000000,100;
此时耗时3分2秒,耗时明显增加。执行计划如下:


由执行计划看,此时索引已经失效了。。。。
我们继续执行sql,从第1000万行开始取100条数据:
select * FROM t_order ORDER BY create_time desc LIMIT 10000000,100;
此时耗时4分14秒,时间真是太长了,执行计划如下:


后面还有接近1000万条数据没有取出来,直接就废了。
原因分析
当我们使用 LIMIT offset, count 查询语句进行深度分页查询时,例如 LIMIT 10000000,100 ,会发生以下过程:
- MySQL首先会根据给定条件从相应的索引树中查找m+n条记录。对于聚集索引来说,它直接找到需要的结果即丢弃前
offset条数据,返回count条数据并返回;而对于二级索引,则可能涉及回表操作。 - 如果使用的是二级索引,在查到m+n条记录后还需要通过这些记录所关联的主键
ID去聚集索引里再次搜索出完整的行数据,然后再丢弃掉前offset条数据,返回count条数据。因此在这个过程中可能会产生大量的“回表”操作,这将导致性能下降。
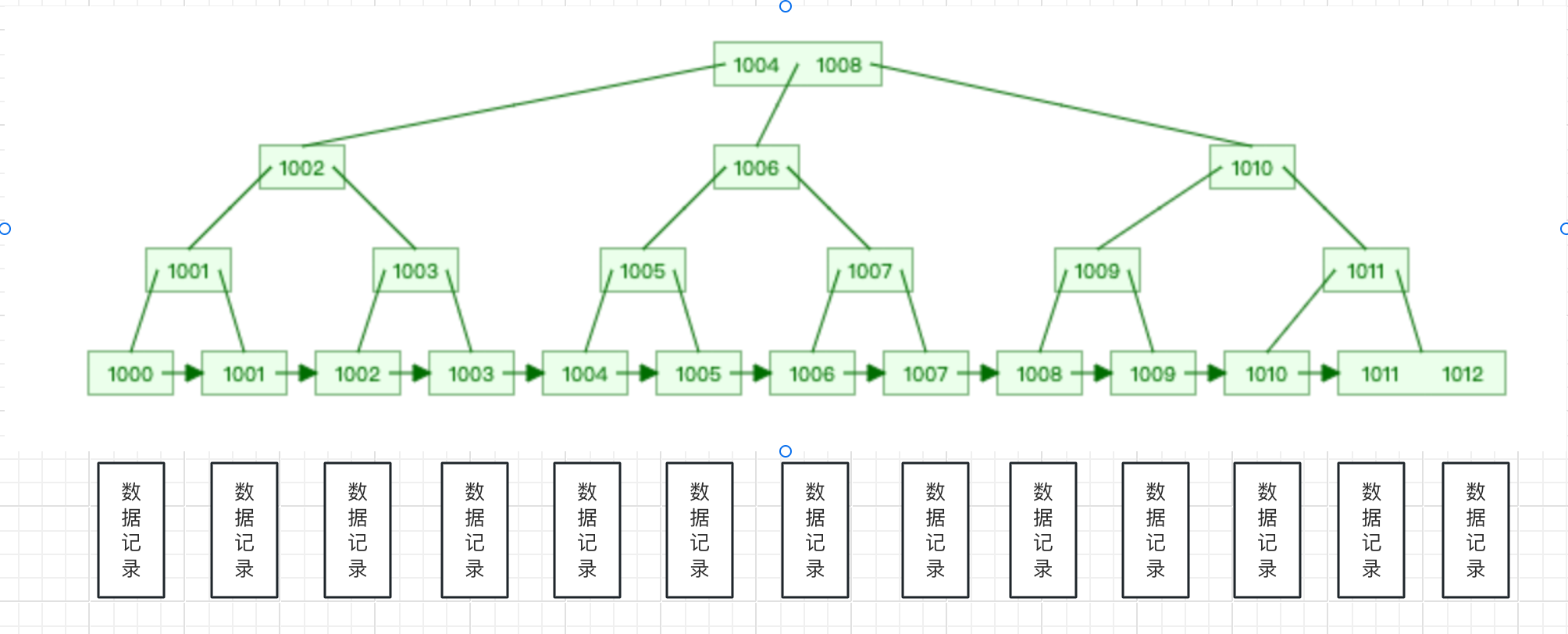
我们借助B+ Tree Visualization演示一下这张表的索引结构:
- 聚集索引(主键ID)
- 二级索引(idx_create_time)
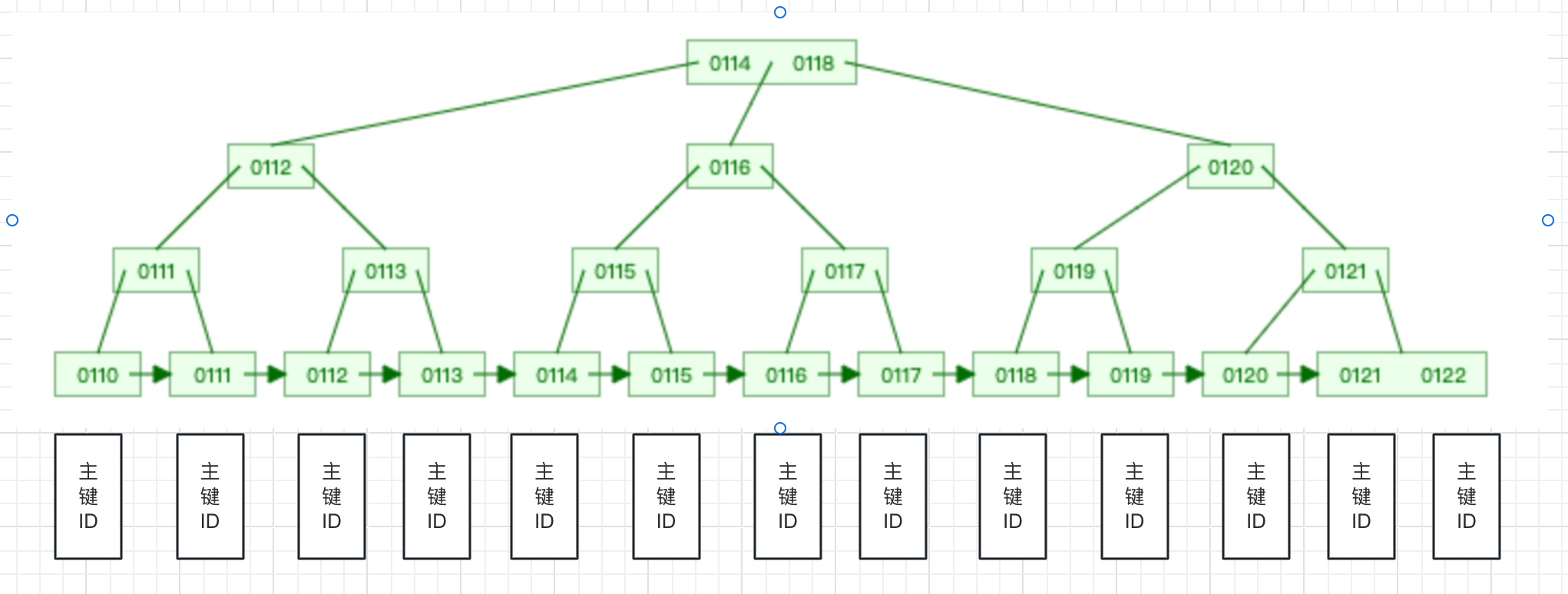
以上述例子来说,当我们查询LIMIT 10000000,100时,它会先从二级索引中查询10000000+100条记录对应的ID,然后再用这些记录的ID去聚集索引中查询ID对应的记录,然后舍弃掉前10000000条数据,返回后100条数据。
所以当offset+count量很大时,Mysql的执行器认为全表扫描的性能更由于使用索引,所以也导致索引失效。所以我们要做的尽可能的减少回表的记录数量。
解决方案
使用子查询
我们改造sql,通过一个子查询按照create_time倒排,获取第offset + 1条记录的最新的create_time,create_time直接从二级索引上可以获取,不会进行回表,然后我们再根据这个create_time传递到主查询时,取100条数据,即回表数据也仅仅只有count条即100条数据,大大减少了回表的记录数量。
SELECT * FROM t_order
WHERE create_time <= (
SELECT create_time FROM t_order ORDER BY create_time desc LIMIT 1000000,1
)
ORDER BY create_time desc LIMIT 100;
查询第100万时耗时556毫秒。
执行结果,执行计划

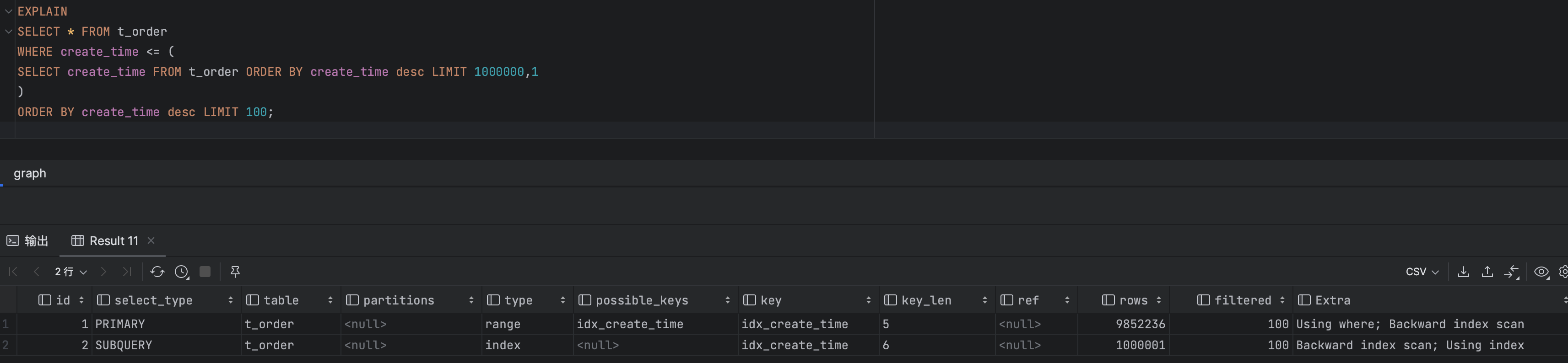
可以看出主查询以及子查询都使用到了索引,回表查询的数据记录数也大大减少。
继续查询到第1000万行时耗时接近6秒。
执行结果,执行计划

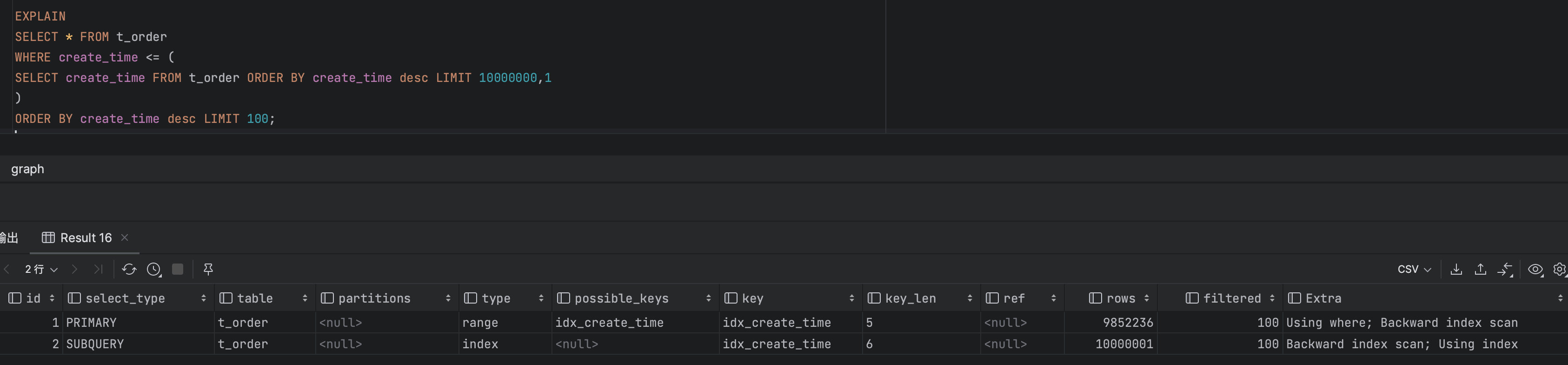
可以看出主查询以及子查询都使用到了索引,回表查询的数据记录数也大大减少。
这种方式需要create_time 的分布是相对均匀的,否则可能会导致某个时间段内的数据较多,影响查询性能。
INNER JOIN
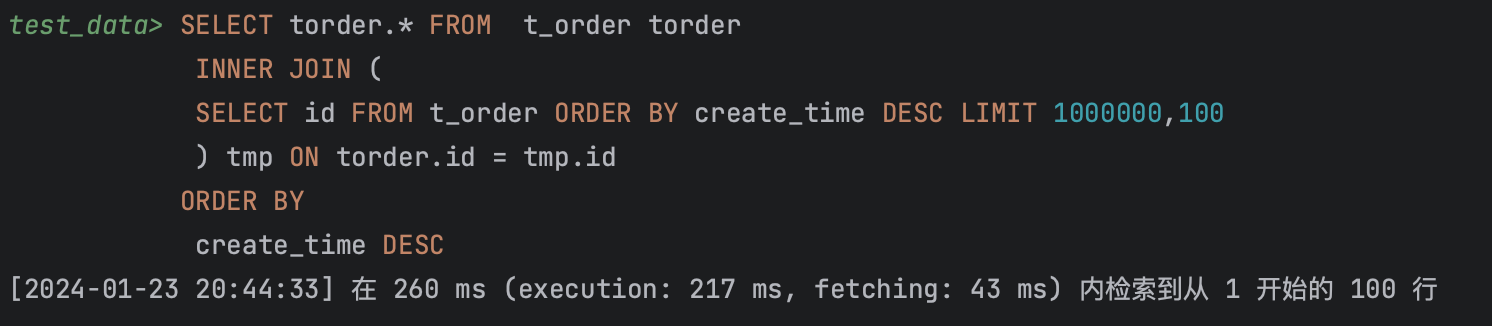
我们改造sql,create_time跟id都存储在二级索引中,我们获取这两列值不需要回表,所以我们创建一个偏移量为offset,个数为count并且包含create_time以及id的临时表,临时表中数据不需要回表。然后再跟自身通过主键ID进行关联,仅需要回表count条数据,大大减少了回表的记录格式。同时也使用了主键索引关联,效率也大大提高。
SELECT torder.* FROM t_order torder
INNER JOIN (
SELECT id FROM t_order ORDER BY create_time DESC LIMIT 1000000,100
) tmp ON torder.id = tmp.id
ORDER BY
create_time DESC
查询第100万时耗时260毫秒。
执行结果,执行计划。
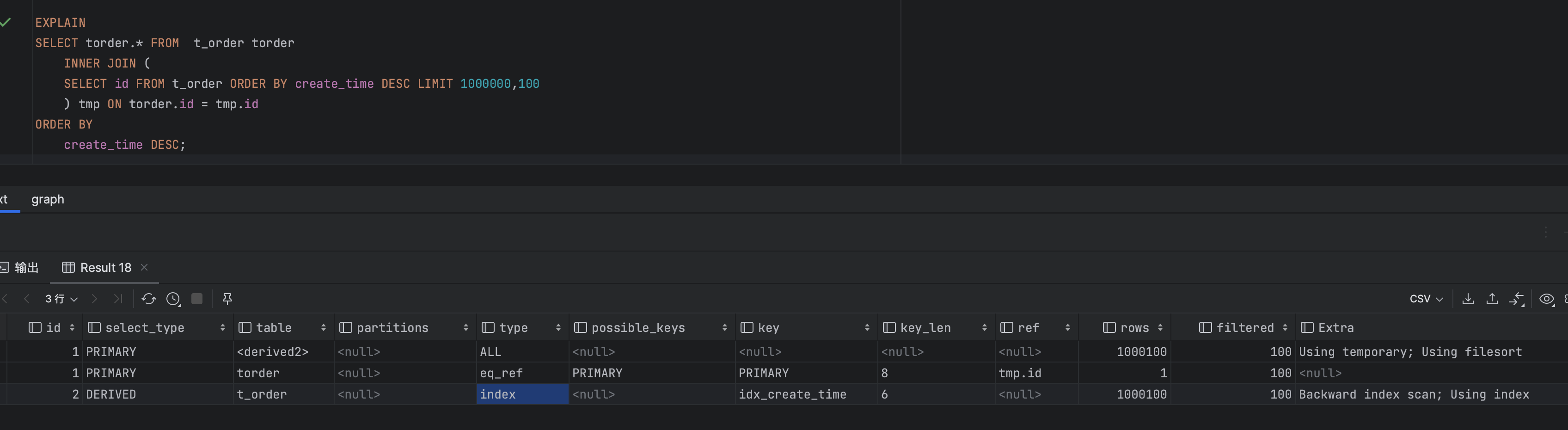
继续查询到第1000万行时耗时接近2秒
执行结果,执行计划
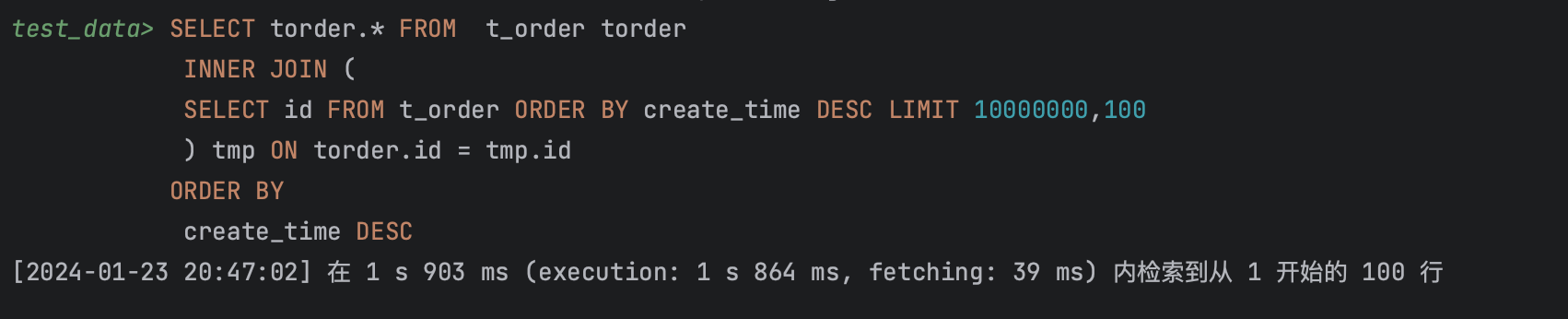
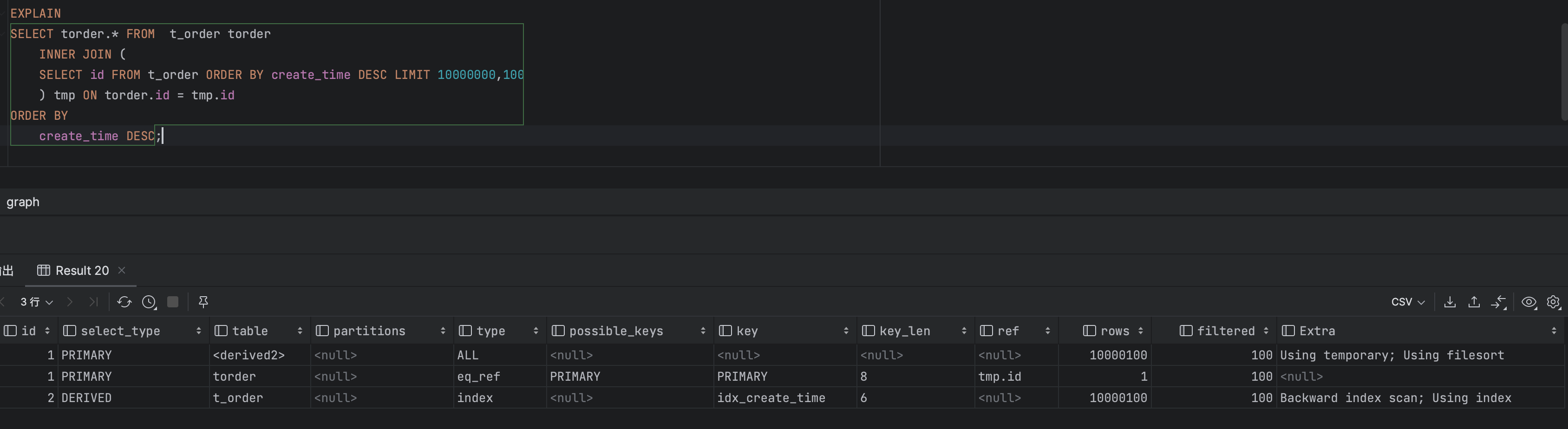
这种方式要保证INNER JOIN使用了合适的索引。
SEARCH AFTER
每次查询都保留上次的最小的create_time,然后下次查询只查询比上一页的create_time小的数据。单表查询,并且使用索引,回表数据少,不需要子查询以及关联查询,查询效率高。类似ES的SEARCH AFTER的查询方式。
-- 我们模拟连续分页到第1000000页,最小的一条数据的create_time
SELECT * FROM t_order
ORDER BY create_time ASC LIMIT 1000000, 1
SELECT * FROM t_order
WHERE create_time <= '2023-01-22 00:00:00'
ORDER BY create_time desc LIMIT 100;
查询第100万时耗时142毫秒。
执行结果,执行计划

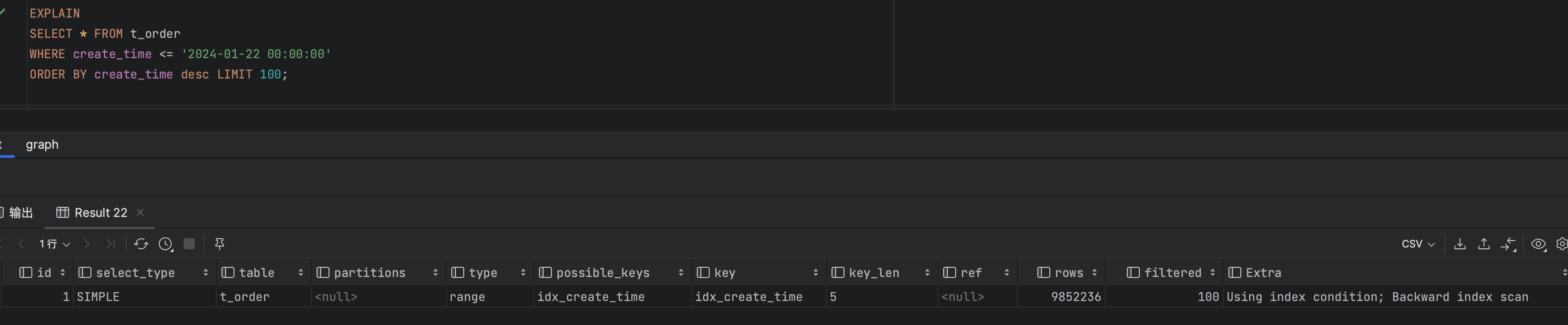
继续查询到第1000万行时耗时244毫秒
执行结果,执行计划


当然该种方式缺点也很明显:只能支持连续分页,不能支持获取随意页的数据。
其他方案
- 限制查询范围: 在需求层面,可以限制只能查询前100页数据,或者规定只能获取某个时间段内的数据,从而避免深度分页。
- 水平分表:考虑将数据按照某个维度进行水平分表,以减小单表的数据量
- 使用ES,Hive,ClickHouse等OLAP方案
本文已收录于我的个人博客:码农Academy的博客,专注分享Java技术干货,包括Java基础、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中间件、架构设计、面试题、程序员攻略等
标签:COMMENT,面试官,create,Mysql,千万级,查询,time,100,order From: https://www.cnblogs.com/coderacademy/p/17994562