NewLife.Redis 是一个Redis客户端组件,以高性能处理大数据实时计算为目标。
Redis协议基础实现位于Redis/RedisClient,FullRedis为扩展实现,主要增加列表结构、哈希结构、队列等高级功能。
源码: https://github.com/NewLifeX/NewLife.Redis
Nuget:NewLife.Redis / NewLife.Extensions.Caching.Redis
视频:https://www.bilibili.com/video/BV1KP41177a6
视频:https://www.bilibili.com/video/BV1R34y1d7dZ
https://newlifex.com/core/redis
特性
- 2017年在ZTO大数据实时计算广泛应用,200多个Redis实例稳定工作一年多,每天处理近1亿条包裹数据,日均调用量80亿次。(2017~2019)
- 低延迟,Get/Set操作平均耗时200~600us(含往返网络通信)
- 大吞吐,自带连接池,最大支持100000并发,峰值每秒220万次操作(单节点管道)
- 高性能,支持二进制序列化,362G内存存放100亿包裹轨迹数据
Redis经验分享
- 在Linux上多实例部署,实例个数等于处理器个数,各实例最大内存直接为本机物理内存,避免单个实例内存撑爆
- 把海量数据(10亿+)根据key哈希(Crc16/Crc32)存放在多个实例上,读写性能成倍增长,类似集群。
- 采用二进制序列化,而非常见Json序列化
- 合理设计每一对Key的Value大小,包括但不限于使用批量获取,原则是让每次网络包控制在1.4k字节附近,减少通信次数
- Redis客户端的Get/Set操作平均耗时200~600us(含往返网络通信),以此为参考评估网络环境和Redis客户端组件
- 使用管道Pipeline合并一批命令
- Redis的主要性能瓶颈是序列化、网络带宽和内存大小,滥用时处理器也会达到瓶颈
- 其它可查优化技巧 以上经验,源自于300多个实例4T以上内存空间一年多稳定工作的经验,并按照重要程度排了先后顺序,可根据场景需要酌情采用!
X组件缓存架构以ICache接口为核心,包括MemoryCache、Redis和DbCache实现,支持FX和netstandard2.0!
后续例程与使用说明均以Redis为例,各缓存实现类似。
一、内存缓存 MemoryCache
MemoryCache核心是并发字典ConcurrentDictionary,由于省去了序列化和网络通信,使得它具有千万级超高性能(普通台式机实测1600万tps)。
MemoryCache支持过期时间,默认容量10万个Key,未过期key超过该值后,每60秒根据LRU清理溢出部分。
常用于进程内千万级以下数据缓存场景。
// 缓存默认实现Cache.Default是MemoryCache,可修改
//var ic = Cache.Default;
var ic = new MemoryCache();
var key = "Name";
var key2 = "Company";
ic.Set(key, "大石头");
ic.Set(key2, "新生命");
Assert.Equal("大石头", ic.Get<String>(key));
Assert.Equal("新生命", ic.Get<String>(key2));
var count = ic.Count;
Assert.True(count >= 2);
// Keys
var keys = ic.Keys;
Assert.True(keys.Contains(key));
// 过期时间
ic.SetExpire(key, TimeSpan.FromSeconds(1));
var ts = ic.GetExpire(key);
Assert.True(ts.TotalSeconds is > 0 and < 2, "过期时间");
var rs = ic.Remove(key2);
Assert.Equal(1, rs);
Assert.False(ic.ContainsKey(key2));
ic.Clear();
Assert.True(ic.Count == 0);
二、基础 Redis
Redis实现标准协议以及基础字符串操作,完整实现由独立开源项目NewLife.Redis提供。
采取连接池加同步阻塞架构,具有超低延迟(200~600us)以及超高吞吐量(实测222万ops/900Mbps)的特点。
在物流行业大数据实时计算中广泛应有,经过日均100亿次调用量验证。
// 实例化Redis,默认端口6379可以省略,密码有两种写法
//var rds = new FullRedis("127.0.0.1", null, 7);
var rds = new FullRedis("127.0.0.1:6379", "pass", 7);
//var rds = new FullRedis();
//rds.Init("server=127.0.0.1:6379;password=pass;db=7");
rds.Log = XTrace.Log;
rds.ClientLog = XTrace.Log; // 调试日志。正式使用时注释
强烈建议!!! Redis对象或FullRedis对象保持单例,它的内部有连接池,能够很好支持多线程操作。
三、数据库 DbCache
DbCache属于实验性质,采用数据库存储数据,默认SQLite。
四、基本操作
在基本操作之前,我们先做一些准备工作:
新建控制台项目,并在入口函数开头加上 XTrace.UseConsole(); ,这是为了方便查看调试日志
具体测试代码之前,需要加上前面MemoryCache或Redis的实例化代码
准备一个模型类User
class User
{
public String Name { get; set; }
public DateTime CreateTime { get; set; }
}
添删改查(Set/Get/ContainsKey/Remove):
var rds = new FullRedis("127.0.0.1:6379", null, 3);
rds.Log = XTrace.Log;
rds.ClientLog = XTrace.Log; // 调试日志。正式使用时注释
var user = new User { Name = "NewLife", CreateTime = DateTime.Now };
rds.Set("user", user, 3600);
var user2 = rds.Get<User>("user");
XTrace.WriteLine("Json: {0}", rds.Get<String>("user"));
if (rds.ContainsKey("user")) XTrace.WriteLine("存在!");
rds.Remove("user");
执行结果:
14:14:25.990 1 N - SELECT 7
14:14:25.992 1 N - => OK
14:14:26.008 1 N - SETEX user 3600 [53]
14:14:26.021 1 N - => OK
14:14:26.042 1 N - GET user
14:14:26.048 1 N - => [53]
14:14:26.064 1 N - GET user
14:14:26.065 1 N - => [53]
14:14:26.066 1 N - Json: {"Name":"NewLife","CreateTime":"2018-09-25 14:14:25"}
14:14:26.067 1 N - EXISTS user
14:14:26.068 1 N - => 1
14:14:26.068 1 N - 存在!
14:14:26.069 1 N - DEL user
14:14:26.070 1 N - => 1
保存复杂对象时,默认采用Json序列化,所以上面可以按字符串把结果取回来,发现正是Json字符串。
Redis的strings,实质上就是带有长度前缀的二进制数据,[53]表示一段53字节长度的二进制数据。
五、集合操作
GetAll/SetAll 在Redis上是很常用的批量操作,同时获取或设置多个key,一般有10倍以上吞吐量。
批量操作:
var rds = new FullRedis("127.0.0.1:6379", null, 3);
rds.Log = XTrace.Log;
rds.ClientLog = XTrace.Log; // 调试日志。正式使用时注释
var dic = new Dictionary<String, Object>
{
["name"] = "NewLife",
["time"] = DateTime.Now,
["count"] = 1234
};
rds.SetAll(dic, 120);
var vs = rds.GetAll<String>(dic.Keys);
XTrace.WriteLine(vs.Join(",", e => $"{e.Key}={e.Value}"));
执行结果:
MSET name NewLife time 2018-09-25 15:56:26 count 1234 => OK EXPIRE name 120 EXPIRE time 120 EXPIRE count 120 MGET name time count name=NewLife,time=2018-09-25 15:56:26,count=1234
集合操作里面还有 GetList/GetDictionary/GetQueue/GetSet 四个类型集合,分别代表Redis的列表、哈希、队列、Set集合等。
基础版Redis不支持这四个集合,完整版NewLife.Redis支持,MemoryCache则直接支持。
六、高级操作
- Add 添加,当key不存在时添加,已存在时返回false。常用于做Redis去重,保障业务幂等。
- Replace 替换,替换已有值为新值,返回旧值。
- Increment 累加,原子操作
- Decrement 递减,原子操作
高级操作:
var rds = new FullRedis("127.0.0.1:6379", null, 3);
rds.Log = XTrace.Log;
rds.ClientLog = XTrace.Log; // 调试日志。正式使用时注释
var flag = rds.Add("count", 5678);
XTrace.WriteLine(flag ? "Add成功" : "Add失败");
var ori = rds.Replace("count", 777);
var count = rds.Get<Int32>("count");
XTrace.WriteLine("count由{0}替换为{1}", ori, count);
rds.Increment("count", 11);
var count2 = rds.Decrement("count", 10);
XTrace.WriteLine("count={0}", count2);
执行结果:
SETNX count 5678 => 0 Add失败 GETSET count 777 => 1234 GET count => 777 count由1234替换为777 INCRBY count 11 => 788 DECRBY count 10 => 778 count=778
七、分布式锁
Redis是分布式锁的绝佳搭档,主要方法是 AcquireLock
IDisposable AcquireLock(String key, Int32 msTimeout);
创建分布式锁的常见用法
var rds = new FullRedis("127.0.0.1:6379", null, 3);
rds.Log = XTrace.Log;
rds.ClientLog = XTrace.Log; // 调试日志。正式使用时注释
var ck = rds.AcquireLock("lock:TestLock1", 3000);
var k2 = ck as CacheLock;
Assert.NotNull(k2);
Assert.Equal("lock:TestLock1", k2.Key);
// 实际上存在这个key
Assert.True(rds.ContainsKey(k2.Key));
// 取有效期
var exp = rds.GetExpire(k2.Key);
Assert.True(exp.TotalMilliseconds <= 3000);
// 释放锁
ck.Dispose();
// 这个key已经不存在
Assert.False(rds.ContainsKey(k2.Key));
这里AcquireLock锁定 lock:TestLock1 这个key,当然,这个key 可以任意设置,不一定非得lock:开头。
Dispose时主动释放锁,这么写是为了更直观演示功能。实际上在申请锁时加上using,后面就不需要Dispose了。
抢死锁的场景
var rds = new FullRedis("127.0.0.1:6379", null, 3);
rds.Log = XTrace.Log;
rds.ClientLog = XTrace.Log; // 调试日志。正式使用时注释
using var ck = rds.AcquireLock("TestLock3", 1000);
// 已经过了一点时间
Thread.Sleep(500);
// 循环多次后,可以抢到
using var ck2 = rds.AcquireLock("TestLock3", 1000);
Assert.NotNull(ck2);
using让该锁在离开作用域时自动释放,上文中,ck并没有释放,ck2上去就抢,实际上前500ms是抢不到的,之后ck锁会从Redis里面消失,ck2就能抢到了,即使ck还没有主动释放,但是它的保护期已经过了。
抢锁失败
var rds = new FullRedis("127.0.0.1:6379", null, 3);
rds.Log = XTrace.Log;
rds.ClientLog = XTrace.Log; // 调试日志。正式使用时注释
var ck1 = rds.AcquireLock("lock:TestLock2", 2000);
// 故意不用using,验证GC是否能回收
//using var ck1 = rds.AcquireLock("TestLock2", 3000);
var sw = Stopwatch.StartNew();
// 抢相同锁,不可能成功。超时时间必须小于3000,否则前面的锁过期后,这里还是可以抢到的
Assert.Throws<InvalidOperationException>(() => rds.AcquireLock("lock:TestLock2", 1000));
// 耗时必须超过有效期
sw.Stop();
XTrace.WriteLine("TestLock2 ElapsedMilliseconds={0}ms", sw.ElapsedMilliseconds);
Assert.True(sw.ElapsedMilliseconds >= 1000);
Thread.Sleep(2000 - 1000 + 1);
// 那个锁其实已经不在了,缓存应该把它干掉
Assert.False(rds.ContainsKey("lock:TestLock2"));
八、性能测试
Bench 会分根据线程数分多组进行添删改压力测试。
rand 参数,是否随机产生key/value。
batch 批大小,分批执行读写操作,借助GetAll/SetAll进行优化。
Redis默认设置AutoPipeline=100,无分批时打开管道操作,对添删改优化。
Redis性能测试[随机],批大小[100],逻辑处理器 40 个 2,400MHz Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz 测试 100,000 项, 1 线程 赋值 100,000 项, 1 线程,耗时 418ms 速度 239,234 ops 读取 100,000 项, 1 线程,耗时 520ms 速度 192,307 ops 删除 100,000 项, 1 线程,耗时 125ms 速度 800,000 ops 测试 200,000 项, 2 线程 赋值 200,000 项, 2 线程,耗时 548ms 速度 364,963 ops 读取 200,000 项, 2 线程,耗时 549ms 速度 364,298 ops 删除 200,000 项, 2 线程,耗时 315ms 速度 634,920 ops 测试 400,000 项, 4 线程 赋值 400,000 项, 4 线程,耗时 694ms 速度 576,368 ops 读取 400,000 项, 4 线程,耗时 697ms 速度 573,888 ops 删除 400,000 项, 4 线程,耗时 438ms 速度 913,242 ops 测试 800,000 项, 8 线程 赋值 800,000 项, 8 线程,耗时 1,206ms 速度 663,349 ops 读取 800,000 项, 8 线程,耗时 1,236ms 速度 647,249 ops 删除 800,000 项, 8 线程,耗时 791ms 速度 1,011,378 ops 测试 4,000,000 项, 40 线程 赋值 4,000,000 项, 40 线程,耗时 4,848ms 速度 825,082 ops 读取 4,000,000 项, 40 线程,耗时 5,399ms 速度 740,877 ops 删除 4,000,000 项, 40 线程,耗时 6,281ms 速度 636,841 ops 测试 4,000,000 项, 64 线程 赋值 4,000,000 项, 64 线程,耗时 6,806ms 速度 587,716 ops 读取 4,000,000 项, 64 线程,耗时 5,365ms 速度 745,573 ops 删除 4,000,000 项, 64 线程,耗时 6,716ms 速度 595,592 ops
九、骨灰级操作
自2017年设计Redis组件以来,已经过4年多系列,总结出一些列骨灰级经验。
1,连接字符串
Redis常见用法是 new Redis 或者 new FullRedis,设置主机、密码和库。而在实际项目中,不可能代码写死地址和密码,一般就涉及做配置文件了,有些工作量,关键要存的东西还不少。
其实,Redis类支持连接字符串,在配置文件中存储整个连接字符串更合适一些。
var redis = new FullRedis();
redis.Log = XTrace.Log;
redis.Init("server=127.0.0.1:6379;db=3");
此外,连接字符串还可以设置其它属性
str = "server=127.0.0.1:6379,127.0.0.1:7000;password=test;db=9;" +
"timeout=5000;MaxMessageSize=1024000;Expire=3600";
var redis = new FullRedis();
redis.Init(str);
上面的连接字符串,指定了双地址(主备),还有密码和库,另外设置了超时时间、最大消息大小和默认超时时间。
2,集成星尘配置中心
在新生命团队的内部项目中,直接把Redis连接字符串存放到星尘配置中心
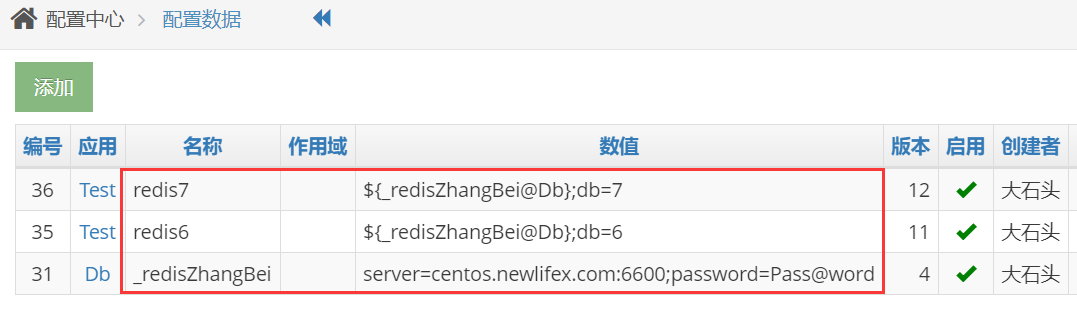
上面新增了张北机房Redis服务器,然后Test应用内新建两个配置分别指向db6和db7。使用代码:
var prv = new HttpConfigProvider
{
Server = "http://star.newlifex.com:6600",
AppId = "Test"
};
var rds = new FullRedis();
rds.Log = XTrace.Log;
rds.Init(prv["redis6"]);
Assert.Equal(6, rds.Db);
在.NETCore项目中,使用IOC更加直接,Startup注册星尘工厂,控制器或服务直接消费解析Redis即可。以下为模拟代码:
var star = new StarFactory("http://star.newlifex.com:6600", "Test", null);
var services = ObjectContainer.Current;
services.AddSingleton(star.Config);
services.AddSingleton(p => new FullRedis(p, "redis6"));
var provider = services.BuildServiceProvider();
var rds = provider.GetService<Redis>();
Assert.Equal(6, rds.Db);
3,非常有用的属性
Redis还有一些高级属性,试用于高吞吐场合:
- Timeout 超时,默认3000毫秒。Tcp层超时时间,内网通信一般是毫秒级,设置一个较小的值,让其感知第一服务器失败然后转移到下一个服务器。但如果有耗时过大的操作,可能导致被误判为失败。
- Retry 重试,默认3次。如果出现网络错误,Redis组件将会重发命令。该设置用于抵御网络抖动而导致的少量失败,在公有云里面特别有效。
- MaxMessageSize 最大消息大小,默认1024*1024。
- Encoder 消息编码器。决定对象存储在redis中的格式,默认json。如果对json格式有要求,可以自己实现编码器,例如有的朋友喜欢使用Json.Net的序列化。
- Info 服务器信息。可用于获取Redis服务器运行时信息。
4,集群部署
本Redis组件支持Redis Cluster,配置任意节点地址,它将能够自动发现其它地址以及Slot分布,执行读写操作时使用正确的节点。
本Redis组件并没有直接支持Redis哨兵,而是通过主备故障转移的形式来支持。
// 配置两个地址,第一个地址是不可访问的,它会自动切换到第二地址 var config = "server=127.0.0.1:6000,127.0.0.1:7000,127.0.0.1:6379;db=3;timeout=7000"; var redis = new FullRedis(); redis.Log = XTrace.Log; redis.Init(config);
如上,可以把哨兵地址设置在前面,然后把具体节点地址防止在后面。在过去,公司的其它系统发生过哨兵切换失败的事故。
在公有云(阿里云、腾讯云、华为云和Ucloud),一般使用主从版Redis,便宜(1G版每年900块)。此时可以配置多个地址。例如 Ucloud 中,会提供Redis主从版的前置VIP地址,以及后面的实际节点地址,可以按照前后顺序填写到连接字符串中。
Redis组件:Nuget包NewLife.Redis,源码 https://github.com/NewLifeX/NewLife.Redis
X组件:Nuget包NewLife.Core,源码 https://github.com/NewLifeX/X
如果你喜欢我们的开源项目,到github赏个star呗^_^
Redis大数据
此处为视频卡片,点击链接查看:Redis大数据.mp4
标签:缓存,14,rds,Redis,NewLife,000,var,Log From: https://www.cnblogs.com/webenh/p/17919747.html