1.mysql回表查询
在这里提起主要是用于说明mysql数据和索引的结构,有助于理解后续加锁过程中的一些问题。
mysql索引结构和表数据结构是相互独立的,根据索引查询,只能找到索引列和主键聚簇索引。如果select语句中不包含索引列,mysql会根据主键聚簇索引二次回表查询所需要的数据,查询出来的数据是根据聚簇索引排序的。如果select中只包含索引列和聚簇索引,那么mysql不会再根据聚簇索引回查表。而且查出来的数据根据查询索引列是排序的。
需要注意的是,mysql即使没有声明主键,mysql也会默认根据一个非空列,生成聚簇索引。
我们有以下的表,其中name和age为索引列,id为主键:
CREATE TABLE `test_user_info` (
`id` bigint(20) NOT NULL COMMENT '主键ID',
`name` varchar(255) DEFAULT NULL COMMENT '用户姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`salary` decimal(15,2) DEFAULT '100.00' COMMENT '奖金',
PRIMARY KEY (`id`),
KEY `index_name` (`name`),
KEY `index_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息表'
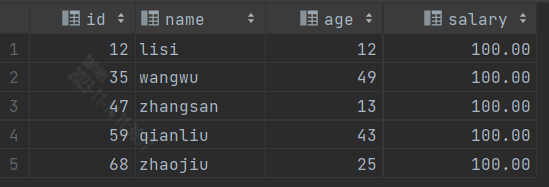
默认数据如下:

覆盖查询:如果执行SELECT NAME,id FROM my_test.test_user_info WHERE NAME IN ('zhangsan','lisi'),mysql是不会回表查询的,因为索引数据结构上已经包含所需要查询的所有值,且查询出来的值是有序的。

回表查询:如果执行SELECT NAME,id,age FROM dongfeng_batch.test_user_info WHERE NAME IN ('zhangsan','lisi'), 由于索引查询列上无age字段,mysql在根据name索引找到聚簇索引后,还要再根据聚簇索引回表查询对应的age值,最后数据默认是根据主键id排序的。
查询过程如下:

2.mysql innodb事务隔离级别
查询mysql事务隔离级别:
SHOW VARIABLES LIKE 'transaction_isolation';

REPEATABLE-READ为mysql默认的事务隔离级别。
mysql InnoDB引擎下有以下4种隔离级别:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(READ UNCOMMITTED) | 出现 | 出现 | 出现 |
| 读已提交(READ COMMITTED) | 不出现 | 出现 | 出现 |
| 可重复读(REPEATABLE READ) | 不出现 | 不出现 | 可能出现 |
| 串行化(SERIALIZABLE) | 不出现 | 不出现 | 不出现 |
按照隔离级别水平从低到高排序,隔离级别越高,性能越差。
| 脏读 | 一个事务访问到了另一个事务未提交的数据 | 事务A更新了id=1的数据的age为90但还未提交,事务B这时候去读id=1的数据,发现age由25变为90。如果事务A回滚了,事务B读取到的数据就是无效的。 |
|---|---|---|
| 不可重复读 | 一个事务读取同一条数据2次,得到得结果不一致 | 事务A读取id=1的数据,age=25;这时候事务B更新id=1的数据,将age修改为90并提交。这时候事务A再去读取,发现age=90,同一事务中对同一条数据读取的不一致。 |
| 幻读 | 一个事务读取2次,得到的数据行数不一致 | 事务A读取name=张三的数据,一次读取出两条;这时候事务B插入一条name=张三,age=18的数据并提交;事务A再次读取name=张三的数据,这时候读取出三条。 |
3.mysql锁分类

3.1按锁粒度分类
(1)表(Table Lock)级锁:表级锁是对整张表进行锁定,它是mysql最基本的锁策略,所有存储引擎都支持。表锁开销最小,粒度最大,发生锁冲突的概率最高,所以并发度最低,可以很好的避免死锁问题。
(2)行级锁:也称为记录锁。行级锁是最细粒度的锁,它只锁定数据表中的某一行数据。InnoDB引擎才支持行级锁。行级锁开销大,粒度最小,发生锁冲突概率低,所以并发度最高,容易产生死锁。
(3)页级锁:页级锁是最粗粒度的锁,它锁定整个数据页面,即数据库中存储数据的最小单位。在使用页级锁时,如果有多个用户想要访问同一个页面,则只有一个用户能够获得锁定,其他用户要么等待,要么被阻塞。页级锁也会产生死锁。BDB引擎支持页级锁。
三种级别的锁分别对应存储引擎关系如下:
| 引擎 | 行锁 | 表锁 | 页锁 |
|---|---|---|---|
| MyISAM | 支持 | ||
| InnoDB | 支持 | 支持 | |
| BDB | 支持 | 支持 |
3.1.1表级锁分类
表级锁细分为以下几种:
表读锁(共享锁-S锁)及表写锁(排他锁-X锁)
元数据锁(meta data lock)
自增锁(AUTO-INC Locks)
意向锁(Intention lock),意向锁又分为意向共享锁(intention shared lock,IS):事务有意向对表中的某些行加共享锁(S锁),意向排他锁(intention exclusive lock,IX):事务有意向对表中的某些行加排他锁(X锁)。
3.1.1.1表读锁(共享锁-S锁)及表写锁(排他锁-X锁)
一般在MyISAM引擎中会用到,MyISAM引擎不支持行锁。InnoDB也支持,但是一般需要手动获取。
在对某个表执行SELECT、INSERT、DELETE、UPDATE语句时,InnoDB存储引擎是不会为这个表添加表级别的S锁或者X锁的。在对某个表执行一些诸如ALTER TABLE、DROP TABLE这类的DDL语句时,其他事务对这个表并发执行诸如SELECT、INSERT、DELETE、UPDATE的语句会发生阻塞。同理,某个事务中对某个表执行SELECT、INSERT、DELETE、UPDATE语句时,在其他会话中对这个表执行DDL语句会发生阻塞。这个过程其实是通过在server层使用一种称之为元数据锁(英文名:Metadata Locks,简称MDL)结构来实现的。
需要注意的是,在SERIALIZABLE, 任何查询都是会加读锁的。
MyISAM引擎在对表做查询的时候不会显式地加锁,当一个查询需要修改表中的数据(写操作)时,会加上写锁,这会阻塞其他的写操作和读操作,直到该写操作完成。
一般情况下,不会使用InnoDB存储引擎提供的表级别的S锁和X锁。只会在一些特殊情况下,比方说崩溃恢复过程中用到。比如,在系统变量autocommit=0,innodb_table_locks=1时,手动获取InnoDB存储引擎提供的表t的S锁或者X锁可以这么写:
LOCK TABLES t READ:InnoDB存储引擎会对表t加表级别的S锁。
LOCK TABLES t WRITE:InnoDB存储引擎会对表t加表级别的X锁。
3.1.1.2意向锁(Intention lock)
InnoDB支持,MyISAM不支持
上面说到,InnoDB存储引擎在做SELECT、INSERT、DELETE、UPDATE操作的时候,不会为表加上S锁或者X锁的,但是会使用到意向锁这种表级别锁。MyISAM引擎是不支持意向锁的。
意向锁又分为意向共享锁(intention shared lock,IS):事务有意向对表中的某些行加共享锁(S锁);意向排他锁(intention exclusive lock,IX):事务有意向对表中的某些行加排他锁(X锁)。事务在给一个数据行加共享锁前必须取得该表的IS锁;事务在给一个数据行加排他锁前必须取得该表的IX锁。意向锁的引入主要是为了在进行行级锁或页级锁时,提供一种机制来表示事务可能会对表中的某些行或页面进行锁定操作的意向,从而提高并发控制的效率。
需要注意的是,意向锁是MySQL内部自动管理的,通常不需要显式地进行操作。在实际应用中,开发人员只需了解意向锁的概念,而无需直接干预它们的使用。 MySQL会在需要时自动处理意向锁,以确保事务的并发操作能够正确进行
InnoDB支持多粒度锁(multiple granularity locking),它允许行级锁与表级锁共存,而意向锁就是其中的一种表锁。
1、意向锁的存在是为了协调行锁和表锁的关系,支持多粒度(表锁与行锁)的锁并存。
2、意向锁是一种不与行级锁冲突表级锁,这一点非常重要。
3、表明“某个事务正在某些行持有了锁或该事务准备去持有锁”。
如果没有意向写锁,mysql在加行锁之前,需要循环扫描表,判断表是否有行锁。如果有了意向写锁,这样,mysql在加行写锁时,如果判断表上没有意向写锁,可以直接加行写锁,无需扫描。
事务要获取某些行的S锁,必须先获得表的IS锁
SELECT column FROM table ... LOCK IN SHARE MODE;
事务要获取某些行的X锁,必须先获得表的IX锁。
SELECT column FROM table ... FOR UPDATE;
3.1.1.3自增锁(AUTO-INC锁)
InnoDB支持,MyISAM不支持
自增锁通常是指对自增主键列的并发控制,这就要求我们设计表的时候,添加了一列做为自增主键才会使用到。在使用MyISAM存储引擎时,对于自增主键列的并发控制并不是通过锁来实现的,而是通过维护一个全局计数器来实现的。MyISAM存储引擎中的自增字段是通过维护一个计数器来生成新的自增值,而不是通过加锁的方式来保证唯一性。这也意味着在高并发的情况下,可能会出现自增值的重复或者不连续的情况。相比之下,InnoDB存储引擎支持的自增字段会通过锁机制来保证并发插入时自增值的唯一性和连续性,从而避免了在高并发情况下可能出现的问题。
在数据库中,插入数据的方式可以总结为三种:
- 简单插入(Simple Inserts):可以
预先确定要插入的行数(当语句被初始处理时)的语句。包括没有嵌套子查询的单行和多行INSERT ... VALUES()和REPLACE语句。。 - 批量插入(Bulk Inserts):
事先不知道要插入的行数(和所需自动递增值的数量)的语句。比如INSERT ... SELECT,REPLACE ... SELECT和LOAD DATA语句,但不包括纯INSERT。InnoDB在每处理一行,为AUTO_INCREMENT列分配一个新值。 - 混合模式插入(Mixed-mode Inserts):这些是“Simple inserts”语句但是指定部分新行的自动递增值。例如INSERT INTO teacher (id,name) VALUES (1,'a'),(NULL,'b'),(5,'c'),(NULL,'d');只是指定了部分id的值。另一种类型的“混合模式插入”是INSERT ... ON DUPLICATE KEY UPDATE。
对于上面数据插入的案例,MySQL中采用了自增锁的方式来实现,AUTO-INC锁是当向使用含有AUTO_INCREMENT列的表中插入数据时需要获取的一种特殊的表级锁,在执行插入语句时就在表级别加一个AUTO-INC锁,然后为每条待插入记录的AUTO_INCREMENT修饰的列分配递增的值,在该语句执行结束后,再把AUTO-INC锁释放掉。一个事务在持有AUTO-INC锁的过程中,其他事务的插入语句都要被阻塞,可以保证一个语句中分配的递增值是连续的。也正因为此,其并发性显然并不高,当我们向一个由AUTO_INCREMENT关键字的主键插入值的时候,每条语句都要对这个表锁进行竞争,这样的并发潜力其实是很低下的,所以innodb通过innodb_autoinc_lock_mode的不同取值来提供不同的锁定机制,来显著提高SQL语句的可伸缩性和性能。
我们可以使用**SHOW VARIABLES LIKE '%innodb_autoinc_lock_mode%'**命令查询自增锁的锁定模式。

innodb_autoinc_lock_mode有三种取值,分别对应与不同锁定模式:
(1)innodb_autoinc_lock_mode = 0(“传统”锁定模式)
在此锁定模式下,所有类型的insert语句都会获得一个特殊的表级AUTO-INC锁,用于插入具有AUTO_INCREMENT列的表。这种模式其实就如我们上面的例子,即每当执行insert的时候,都会得到一个表级锁(AUTO-INC锁),使得语句中生成的auto_increment为顺序,且在binlog中重放的时候,可以保证master与slave中数据的auto_increment是相同的。因为表级锁,当在同一时间多个事务中执行insert的时候,对于AUTO-INC锁的争夺会限制并发能力。
(2)innodb_autoinc_lock_mode = 1(“连续”锁定模式)
在MySQL8.0之前,连续锁定模式是默认的。
在这个模式下,“bulk inserts”仍然使用AUTO-INC表级锁,并保持语句结束。这适用于所有INSERT … SELECT,REPLACE … SELECT和LOAD DATA语句。同一时刻只有一个语句可以持有AUTO-INC锁。
对于“Simple inserts”(要插入的行数事先已知),则通过mutex(轻量锁)的控制下获得所需数量的自动递增值来避免表级AUTO-INC锁,它只在分配过程的持续时间内保持,而不是直到语句完成。不使用表级AUTO-INC锁,除非AUTO-INC锁由另一个事务保持。如果另一个事务保持AUTO-INC锁,则“Simple inserts”等待AUTO-INC锁。
(3)innodb_autoinc_lock_mode = 2(“交错”锁定模式)
从MySQL8.0开始,交错模式是默认设置。
在这种锁定模式下,所有类INSERT语句都不会使用表级AUTO-INC锁,而是使用较为轻量的mutex锁,并且可以同时执行多个语句。这是最快和最可扩展的锁定模式。副作用就是单个Insert的自增值有可能是不连续的,因为AUTO_INCREMENT的值会在多个INSERT语句中来回交叉执行。
优点:效率高;
缺点:在并发情况下无法保持数据一致性。我们知道mysql通过Binlog主从同步有三种模式:statement,row,mixed;如果采用的是statement模式同步的数据,并且采用了交错锁定模式,数据会有不一致问题。
3.1.1.4元数据锁(meta data lock)
innodb支持,MyISAM不支持
MySQL5.5引入了meta data lock,简称MDL锁,属于表锁范畴。MDL的作用是,保证读写的正确性。比如,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,增加了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。
因此,当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。
读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性,解决了DML和DDL操作之间的一致性问题。不需要显式使用,在访问一个表的时候会被自动加上。
思考:我们在对表做Alter操作的时候,是否能立即执行?
答案是不一定,如果此时还有事务在进行增删改查操作,Alter操作会阻塞,必须等待所有事务执行完毕才能执行。
需要注意的是,我们在对大表做DDL的时候,有可能会造成数据库崩溃。所以要求我们尽量在业务不繁忙的时候执行DDL,或者是使用第三方工具,如pt-online-schema-change等来安全的执行表的DDL操作。
3.1.1.5表级锁兼容性
| IS | IX | AUTO-INC | S | X | |
|---|---|---|---|---|---|
| IS | 兼容 | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 兼容 | 兼容 | 兼容 | 不兼容 | 不兼容 |
| AUTO-INC | 兼容 | 兼容 | 不兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 不兼容 | 兼容 | 不兼容 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
3.1.2行级锁分类
InnoDB引擎支持行级锁,行级锁只在存储引擎层实现。
优点:锁粒度小,发生锁冲突概率低,并发度高;
缺点:锁开销较大,加锁较慢,容易出现死锁。
3.1.2.1记录锁(Record Locks)
在 MySQL 中,记录锁可以分为共享锁(S锁)和排他锁(X锁)。共享锁允许多个事务同时对同一行进行读取操作,但是不允许任何事务对该行进行写入操作;而排他锁则会阻止其他事务对该行进行读取或写入操作,直到持有排他锁的事务释放锁定。记录锁始终锁定索引记录,即使表没有定义索引。对于这种情况,InnoDB会创建一个隐藏的聚簇索引并使用这个索引进行记录锁定。
当事务需要修改数据时,会根据需要获取相应的锁,以确保并发修改操作的正确性和一致性。这些锁会在事务提交或回滚时自动释放。
记录锁也就是仅仅一条记录锁上,官方的类型名称为:LOCK_REC_NOT GAP
当一个事务获取了一条记录的S型锁后,其他事务也可以继续获取该记录的S型记录锁,但不可以继续获取X型记录锁;
当一个事务获取了一条记录的X型记录锁后,其他事务即不可以继续获取该记录的S型记录锁,也不可以继续获取X型记录锁。
3.1.2.2间隙锁(Gap Locks)
间隙锁(Gap Lock)是InnoDB引擎RR隔离级别下特有的锁机制,用于防止幻读(Phantom Reads),但不能完全避免幻读。间隙锁锁定的是索引记录之间的间隙,或者在第一个索引记录之前或最后一个索引记录之后的间隙。间隙锁只会阻塞insert操作。
当多个事务执行范围查询并且涉及相同的间隙时,它们可以共享同一个间隙锁。这意味着这些事务不会互相阻塞,它们可以同时持有同一个间隙锁,并且可以读取该间隙范围内的数据。这种情况下的共享间隙锁可以提高并发性能。此外,即使多个事务可以共享同一个间隙锁,它们之间仍然可能存在冲突。例如,如果一个事务持有了间隙锁并尝试插入新的键值,而另一个事务持有了间隙锁并尝试在同一间隙内插入另一个新的键值,那么它们之间仍然会发生冲突,其中一个事务将被阻塞。
然而,多个事务无法同时持有相互重叠的间隙锁。这可能会导致一些事务被阻塞,直到其他事务释放了锁。
3.1.2.3临键锁(Next-Key Locks)
MySQL的临键锁(next-key lock)是一种加强版的间隙锁,用于解决间隙锁无法完全避免的幻读问题。临键锁不仅会锁定范围内的间隙,还会锁定范围内的已有记录。所以InnoDB就提出了一种称之为Next-Key Locks的锁,官方的类型名称为:LOCK_ORDINARY,我们也可以简称为net-key锁。Next-Key Locks是存储引擎innodb、事务级别在RR(可重复读)的情况下使用的数据库锁,innodb默认的锁就是Next-Key locks
类似是一个记录锁和一个gap锁的合体。gap锁是允许多个事务持有相同间隙的,但临键锁是不允许多个事务共同持有的。临键锁锁住的间隙是不允许其他事务操作的。它即能保护该条记录,又能阻止别的事务将新纪录插入被保护纪录的间隙。
临建锁遵循左开右闭的原则。
需要注意的是,临建锁会退化。
退化规则如下:如果是RC隔离级别,是没有间隙锁的,只会有行锁。
| 查询描述 | 查询值是否存在 | 加锁情况 |
|---|---|---|
| 非唯一索引等值查询 | 查询值存在 | 加next-key Lock和间隙锁 |
| 非唯一索引等值查询 | 查询值不存在 | 加next-key Lock,后退化为间隙锁 |
| 非唯一索引范围查询 | 不管值是否存在 | 加next-key Lock,可能数据行加记录锁 |
| 唯一索引等值查询 | 查询值存在 | 加next-key Lock,但会退化为记录锁 |
| 唯一索引等值查询 | 查询值不存在 | 加next-key Lock,但会退化为间隙锁 |
| 唯一索引范围查询 | 不管值是否存在 | 加next-key Lock,可能会退化为间隙锁/记录锁 |
| 非索引列查询 | 不管值是否存在 | 全表主键范围内加临键锁 |
临建锁加锁过程是一个比较复杂的过程,后面在mysql加锁分析中举例论证。
3.1.2.4插入意向锁(Insert Intention Locks)
插入意向锁是一种在 INSERT 操作之前设置的一种间隙锁,插入意向锁表示了一种插入意图,即当多个不同的事务,同时往同一个索引的同一个间隙中插入数据的时候,它们互相之间无需等待,即不会阻塞(要是单纯按照之前间隙锁的理论,必须要等一个间隙锁释放了,下一个事务才可以往相同的间隙处插入数据)。假设有值为 4 和 7 的索引记录,现在有两个事务,分别尝试插入值为 5 和 6 的记录,在获得插入行的排他锁之前,每个事务使用插入意向锁锁定 4 和 7 之间的间隙,但是这两个事务不会相互阻塞,因为行是不冲突的。
这就是插入意向锁。插入意向锁和临建锁和间隙锁是互斥的。
3.1.2.5空间索引谓词锁(Predicate Locks for Spatial Indexes)
MySQL的空间索引用于处理地理空间数据,允许对存储地理位置信息的列进行高效的空间查询。通过空间索引,可以加快对地理空间数据的搜索、分析和操作。
在MySQL中,空间索引通常用于存储地理位置坐标、多边形区域等地理空间数据。它可以支持多种空间函数,如计算两点之间的距离、查找某一点所在的区域等操作。
要创建空间索引,需要使用特定的索引类型,例如SPATIAL索引。下面是一个创建空间索引的示例:
CREATE TABLE spatial_table (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100),
location POINT,
SPATIAL INDEX(location)
);
在这个示例中,我们创建了一个名为spatial_table的表,其中包含一个用于存储地理位置的location列。通过使用SPATIAL INDEX关键字,我们为location列创建了一个空间索引。
一旦创建了空间索引,就可以使用MySQL的空间函数来执行各种地理空间数据的查询和分析操作。例如,可以使用ST_Distance函数计算两个地理位置之间的距离,使用ST_Contains函数检查一个区域是否包含另一个区域,等等。
总之,MySQL的空间索引为处理地理空间数据提供了便利和高效性,使得开发地理信息系统和地图应用变得更加容易和高效。
空间索引的谓词锁实际上是一种行级锁。当使用空间索引进行查询时,InnoDB会在涉及到的行上设置谓词锁,以确保其他事务不能插入或修改与查询条件匹配的行。这样可以保证空间数据的一致性和完整性。因此,谓词锁可以看作是对行级操作的一种锁定机制。
4.mysql加锁分析
文章结合mysql8.0+版本(8.0.35)的performance_schema.data_locks分析。
当前mysql5.7.30的information_schema.INNODB_LOCKS表不够直观,不能很轻松的看出加锁情况。
mysql8.0+和mysql5.7.30在加锁情况上没有较大差异。后续所有操作都是基于mysql8.0.35。
备注:
mysql5.7.30要打开information_schema.INNODB_LOCKS的功能,需开启以下配置:
#开启innodb锁功能
SET GLOBAL innodb_status_output_locks = ON;
#查询是否开启
SHOW GLOBAL VARIABLES LIKE 'innodb_status_output_locks';
正常查询不涉及行锁,这里不分析查询的情况。数据库默认使用RR隔离级别。
RR隔离级别下,对如下数据分析,name和age分别为普通索引,id为主键
数据说明
注意插入的顺序,我这里打乱了id=68和id=59的顺序。mysql查询锁日志默认是按数据库插入顺序排序的,但是并不代表加锁的顺序。
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('12','lisi','12','100.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('35','wangwu','49','100.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('47','zhangsan','13','100.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('68','zhaojiu','25','100.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('59','qianliu','43','100.00');
performance_schema.data_locks表说明:
- 如果 LOCK_MODE 为
X, REC_NOT_GAP,说明是记录锁; - 如果 LOCK_MODE 为
X, GAP,说明是间隙锁; - 如果LOCK_MODE 为
X,说明是 next-key 锁;
总结:(这是非常重要的结论,否则没法直观的通过performance_schema.data_locks表分析出加锁情况)
1.LOCK_MODE=X,GAP类型,LOCK_DATA是间隙锁的结束范围,从该行数据向上扫描,邻近的一行则是间隙锁的开始范围;
2.LOCK_MODE=X类型,LOCK_DATA是临键锁的尾,从该行向上扫描,邻近的一行则是临键锁的开始范围;如果表中没有临近的数据行,则是无穷小
3.LOCK_DATA=supremum pseudo-record,这个是无穷大的意思
4.非唯一索引记录上加临键锁,会在对应数据行上加记录锁
5.不管是临键锁还是间隙锁,会根据查询条件向上向下延伸,找到不满足条件的临近的行;
下面的情况在分析的时候,结合总结来分析。
场景一:唯一索引等值查询,查询数据不存在
结论:加间隙锁
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where id = 3
查询数据不存在,查询加锁情况:
注意:以下返回值的顺序不代表加锁顺序

我们发现:
1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,GAP,INDEX_NAME=PRIMARY,说明在主键上被加了间隙锁。
间隙锁范围id为(-∞,12)。为什么是(-∞,12)。因为加锁的时候,为了防止幻读,锁住对应的间隙,临界范围会根据查询条件在数据库中找不满足查询条件的相邻的值。如果向上向下找不到不满足条件的值,则是-∞和+∞。
mysql innodb引擎在RR级别下默认加的是临键锁。在当前场景下,临键锁会退化为间隙锁。
3.如果其他事务SessionB想在id < 12的范围内插入数据的话,事务会被阻塞。只有等待SessionA提交后才能执行。

场景二:唯一索引等值查询,查询数据存在
结论:加行锁
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where id = 12
查询数据存在,查看加锁情况:

我们发现:
1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,说明在数据行上被加了记录锁。
记录锁锁定id=12的记录。mysql innodb引擎在RR级别下默认加的是临键锁,在这种场景下,临键锁会退化为记录锁。
这时SessionB立刻插入id=5的数据,是不会被阻塞的。

场景三:唯一索引>=范围查询,等值查询数据存在
结论:加行锁和间隙锁;
SessionA执行以下sql,不提交事务:
update test_user_info set salary = salary + 100 where id >= 59
id=59的数据存在,我们查询加锁情况:

此时加锁情况已经较为复杂,我们发现:
1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,说明在数据行id=59上被加了记录锁。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=supremum pseudo-record,这个是无穷大的意思。说明id范围在(68, +无穷大]的数据上被加了临键锁。
4.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=68。说明在(59, 68]的数据上被加了临键锁。
临键锁遵循左开右闭的原则。当查询数据范围为id>=59的时候,mysql扫描到id=59行的数据,数据存在,加行锁。然后再扫描id > 59的情况,扫描到id=68的数据,所以在(59,68]上加临键锁。然后继续扫描id>68的情况,此时表里面没有数据,所以在(68, +无穷大]的数据上被加了临键锁。
我们讲过,临建锁类似记录锁+间隙锁的组合,所以这时候,如果我们SessionB执行:
update test_user_info set salary = salary + 100 where id = 68,此时68的数据行上有临键锁,事务会被阻塞。
我们想在id >=59的范围内插入数据,也是会被阻塞的。

场景四:唯一索引>=范围查询,等值查询数据不存在,这种就类似于>范围查询
结论:加临键锁
SessionA执行以下sql,不提交事务:
update test_user_info set salary = salary + 100 where id >= 58
id=58的数据不存在,这种类似于>58的查询,查询加锁情况。

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=supremum pseudo-record,这个是无穷大的意思。说明id范围在(68, +无穷大]的数据上被加了临键锁。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=68。说明在(59, 68]的数据上被加了临键锁。
4.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=59。说明在(47, 59]的数据上被加了临键锁。为什么这里是47,因为加锁的时候,为了防止幻读,锁住对应间隙,临界条件会根据查询条件在数据库中找不满足查询条件的相邻的值。我们这里id >= 58, 相邻的不满足条件的值为id=47。
总结就是:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
如果我们SessionB执行:
insert into my_test.test_user_info values (48, 'pengwu', 30, 120)会被阻塞;

但是如果执行的插入数据id=46,则
可以执行,不被阻塞。

场景五:唯一索引<=范围查询,等值查询数据存在
结论:只加临键锁;
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where id <= 35
id=35的数据存在,我们查询加锁情况:

![image-20231114113644445(https://pic.imgdb.cn/item/6556f082c458853aef358304.png)
1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=12。说明id范围在(-∞, 12]的数据上被加了临键锁。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=35。说明在(12, 35]的数据上被加了临键锁。
这里和>=范围查询,等值数据存在场景不一样的是,等值查询id=35的数据不会加行锁。这是因为临键锁左开右闭的原则。(12, 35]的临键锁范围已经包含了数据id=35的行。
如果此时SessionB想在id范围为:id<=35的行上做任何操作,insert,update,delete,哪怕where条件是其他列,但操作的行数据id<=35, 均被阻塞。
SessionB更新:update my_test.test_user_info set salary = salary + 100 where name = 'lisi'
数据id=12,被阻塞。

场景六:唯一索引<=范围查询,等值查询数据不存在,这种就类似于<范围查询
结论:满足条件的范围加临键锁,不满足条件的加间隙锁;
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where id < 35
我们查询加锁情况:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=12。说明id范围在(-∞, 12]的数据上被加了临键锁。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,GAP,INDEX_NAME=PRIMARY,LOCK_DATA=35。说明在(12, 35)的数据上被加了间隙锁。这里为什么变成了间隙锁,因为加锁的时候,为了防止幻读,锁住对应的间隙,临界范围会根据查询条件在数据库中找不满足查询条件的相邻的值。id=35则是向下不满足条件的相邻的值。mysql开始在
id为(12,35]的行上加临键锁。但是id=35的数据在范围外,退化成了间隙锁。为什么这里这么特殊,我想的是,id=35的数据不在范围内,没必要加上行锁,所以这里就退化成间隙锁。保证id=35行的数据可以被操作。这个和>=范围的完全不同。
总结:<=的范围查询,如果查询条件不在临界值,临键范围是会退化成间隙锁的。
SessionB此时是可以操作id=35的行数据的。
场景七:唯一索引>= and <=范围查询
这种基本是场景三,四,五,六的组合,没有什么特殊,即使等值查询数据存在。
SessionA执行以下sql,不提交事务:
update test_user_info set salary = salary + 100 where id >= 12 and id <= 38
我们查询加锁情况:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=12。说明id=12的数据行加了记录锁。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=PRIMARY,LOCK_DATA=35,说明id范围为(12,35]的数据行上加了临键锁。
4.LOCK_TYPE=RECORD,LOCK_MODE=X,GAP,INDEX_NAME=PRIMARY,LOCK_DATA=47,说明id范围为(35,47)的行上加了间隙锁。
场景八:非唯一索引等值查询,查询数据不存在
结论:加间隙锁;
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where age = 15
我们查询加锁情况:


1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,GAP,INDEX_NAME=index_age,LOCK_DATA=25, 68。(25, 68)对应age=25,id=68的索引记录。注意,mysql索引是有序的。
说明在(age,id)范围为:(13,47)到(25,68)的索引数据上加了间隙锁。那么对于age=13或age=25的数据,能不能插入进去呢?
这还要根据id范围确定。实际上,间隙锁是加在了(13,47)和(25,68)的范围。
如果我们此时要插入age=13,id=46的数据,是可以插入的。
但是我们要插入age=13, id=48的数据,就会被阻塞。


场景九:非唯一索引等值查询,查询数据存在
结论:非唯一索引加临键锁,间隙锁;数据行加记录锁
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where age = 13
我们查询加锁情况:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(13,47)。说明
临键锁加在了age和id范围在(12,12)到[13,47]之间。此时如果SessionB插入(age,id)=(12,11)的数据,是不会阻塞的。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=47,说明id=47的数据行上加了记录锁。
4.LOCK_TYPE=RECORD,LOCK_MODE=X,GAP,INDEX_NAME=index_age,LOCK_DATA=(25,68),说明(age,id)范围在(13,47)到(25,68)范围内被加上了间隙锁。
场景十:非唯一索引>=范围查询,等值查询数据存在
结论:非唯一索引记录加临键锁,数据行加行锁。
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where age >= 43
age=43的记录存在,我们查询加锁情况:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(supremum pseudo-record)。说明(age,id)范围在(49,35)到[age无穷大,id无穷大]的索引记录上加了临键锁;SessionB在比(49,35)
范围大的记录上,是无法执行插入操作的。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(49,35)。说明(age,id)范围在(43,59)到[49,35]的索引记录上加了临键锁;
4.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(43,59)。说明(age,id)范围在(25,68)到[43,59]的索引记录上加了临键锁;
5.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=35。说明
id=35的行被加了记录锁;
6.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=59。说明
id=59的行被加了记录锁;
场景十一:非唯一索引>=范围查询,等值查询数据不存在,这种就类似于>范围查询
非常类似场景十
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where age > 43
age=43的记录不存在,我们查询加锁情况:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(supremum pseudo-record)。说明(age,id)范围在(49,35)到[age无穷大,id无穷大]的索引记录上加了临键锁;SessionB在比(49,35)
范围大的记录上,是无法执行插入操作的。
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(49,35)。说明(age,id)范围在(43,59)到[49,35]的索引记录上加了临键锁;
4.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=35。说明
id=35的行被加了记录锁;
场景十二:非唯一索引<=范围查询,等值查询数据存在
结论:非唯一索引加临键锁,数据行加行锁
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where age <= 13
age=13的记录存在,我们查询加锁情况:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(12,12)。说明(age,id)范围在(age无穷小,id无穷小)到[12,12]的索引记录上加了临键锁;
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(13,47)。说明(age,id)范围在(12,12)到[13,47]的索引记录上加了临键锁;
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(25,68]。说明(age,id)范围在(13,47)到[25,68]的索引记录上加了临键锁;
4.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=12。说明
id=12的行被加了记录锁;
5.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=47。说明
id=47的行被加了记录锁;
6.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=68。说明
id=68的行被加了记录锁;((25,68]的索引被加了临键锁,id对应的数据行需要加记录锁)
场景十三:非唯一索引<=范围查询,等值查询数据不存在,这种就类似于<范围查询
结论:非唯一索引加临键锁,数据行加行锁
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where age < 14
age=14不存在,我们查询加锁情况,加锁情况完全同场景十二:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(12,12)。说明(age,id)范围在(age无穷小,id无穷小)到[12,12]的索引记录上加了临键锁;
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(13,47)。说明(age,id)范围在(12,12)到[13,47]的索引记录上加了临键锁;
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(25,68]。说明(age,id)范围在(13,47)到[25,68]的索引记录上加了临键锁;
4.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=12。说明
id=12的行被加了记录锁;
5.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=47。说明
id=47的行被加了记录锁;
6.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=68。说明
id=68的行被加了记录锁;(这个不明白为什么要在id=68的行数据上加记录,可能是bug)
场景十四:非唯一索引>= and <=范围查询
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where age >=13 and age <= 44
查询加锁情况:

1.LOCK_TYPE=TABLE,LOCK_MODE=IX,说明在表上被加了IX意向锁;
2.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(49,35)。说明(age,id)范围在(43,59)到[49,35]的索引记录上加了临键锁;
3.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(13,47)。说明(age,id)范围在(12,12)到[13,47]的索引记录上加了临键锁;
4.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(25,68)。说明(age,id)范围在(13,47)到[25,68]的索引记录上加了临键锁;
5.LOCK_TYPE=RECORD,LOCK_MODE=X,INDEX_NAME=index_age,LOCK_DATA=(43,59)。说明(age,id)范围在(25,68)到[43,59]的索引记录上加了临键锁;
6.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=35。说明
id=35的行被加了记录锁;
7.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=47。说明
id=47的行被加了记录锁;
8.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=68。说明
id=68的行被加了记录锁;
9.LOCK_TYPE=RECORD,LOCK_MODE=X,REC_NOT_GAP,INDEX_NAME=PRIMARY,LOCK_DATA=59。说明
id=59的行被加了记录锁;
场景十五:非索引列查询
SessionA执行以下sql,不提交事务:
update my_test.test_user_info set salary = salary + 100 where salary = 100
查看加锁情况:

全表扫描,所有数据行id间的范围都加上了临键锁。
(-∞,12],(12,35],(35,47],(47,59],(59,68],(68,+∞], 相当于给表加了X锁。任何insert,update,delete操作均会被阻塞。
如果是多条件列,mysql会根据每个条件扫描到到的行,来判断加锁情况。
6.InnoDB死锁
在mysql中,死锁是不会发生在MyISAM引擎中。这是因为主要使用的是表锁,而InnoDB中重点使用的是行锁。
死锁产生的四个条件:
1.互斥条件:一个资源每次只能被一个进程使用;
2.请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
3.不可剥夺条件:进程已获得的资源,在没使用完成之前,不能强行剥夺;
4.循环等待条件:多个进程之间形成了一种相互循环等待资源的关系;
结合mysql,我们如何避免死锁呢?
1.加锁顺序一致,主要打破循环等待条件;
2.尽量基于主键或唯一索引更新数据;
5.1表级死锁产生场景
用户A开启事务,首先使用非索引列更新表t1,由于表t1没有使用索引,导致t1相当于被加上表锁;
用户B开启事务,首先使用非索引列更新表t2,由于表t2没有使用索引,导致t2相当于被加上表锁;
这时用户A去更新表t2,用户B去更新表t1。用户A需要等待用户B释放表t2的表锁,用户B需要用户A
释放表t1的表锁。
这种死锁场景不常见,我们只要在程序中,保证表的更新顺序即可。
5.2行级锁死锁产生场景
mysql因为行级锁产生的死锁情况较多,下面简单列举几种情况。
场景1:id主键
sessionA:
update test_user_info set age =10 where id = 1;(执行时序1)
update test_user_info set age =10 where id = 12;(执行时序3)
sessionB:
update test_user_info set age =20 where id = 12;(执行时序2)
update test_user_info set age =20 where id= 1;(执行时序4)
这种场景容易产生死锁,我们在同一个事务中,要尽可能做到同表的某些数据一次性更新;
按照id进行排序,然后按序处理;
场景2:假设一个表有以下数据:id主键,name索引,age索引
CREATE TABLE `test_user_info` (
`id` bigint(20) NOT NULL COMMENT '主键ID',
`name` varchar(255) DEFAULT NULL COMMENT '用户姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`salary` decimal(15,2) DEFAULT '100.00' COMMENT '奖金',
PRIMARY KEY (`id`),
KEY `index_name` (`name`),
KEY `index_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息表';
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('1','zhangsan','15','100.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('12','lisi','12','100.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('35','wangwu','49','200.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('47','zhangsan','13','100.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('59','qianliu','43','200.00');
insert into `test_user_info` (`id`, `name`, `age`, `salary`) values('68','zhaojiu','25','200.00');
sessionA执行以下sql未提交:update test_user_info set salary=salary+100 where name = 'zhangsan';
主表记录锁加锁顺序按id排序如下:1,47

sessionB执行以下sql未提交:update test_user_info set salary=salary+120 where age > 12 and age < 25;
主表记录锁加锁顺序按id排序如下:47,1

主表记录锁顺序不一致,产生死锁。但这个死锁还有一个极端条件,加锁过程中,sessionA先对id=1的数据行加锁,
sessionB再对id=47的数据加锁;此时不管是sessionA想对id=47的行加锁,或是sessionB想对id=1的数据行加锁,
均会阻塞,并产生死锁。

死锁的关键在于:两个(或以上)的Session加锁的顺序不一致,mysql是逐行加锁的。
解决方案:根据索引回查主键id并排序,根据主键id更新。
查询最近一次死锁日志:SHOW ENGINE INNODB STATUS;
死锁日志如下:
0: len 8; hex 8000000000000001; asc ;;------事务更新的主键索引-----第一个字节是 "80",转换为十进制为 128。后面的 7 个字节 "000000000000002f" 代表一个 64 位的整数,转为十进制为 1
1: len 6; hex 000000000879; asc y;;-----事务id2169
2: len 7; hex 020000016b0151; asc k Q;;---事务回滚指针
3: len 8; hex 7a68616e6773616e; asc zhangsan;;----代表数据值-----十六进制转化后为:zhangsan
4: len 4; hex 8000000f; asc ;;------代表数据值------六进制转化后为:15
5: len 7; hex 8000000000d200; asc ;;------代表数据值salary
- 记录锁(LOCK_REC_NOT_GAP): lock_mode X locks rec but not gap
- 间隙锁(LOCK_GAP): lock_mode X locks gap before rec
- Next-key锁(LOCK_ORNIDARY): lock_mode X / lock mode S
- 插入意向锁(LOCK_INSERT_INTENTION): lock_mode X locks gap before rec insert intention
=====================================
2023-11-15 13:45:36 0x70bc INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 1 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 247 srv_active, 0 srv_shutdown, 95073 srv_idle
srv_master_thread log flush and writes: 0
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 928
OS WAIT ARRAY INFO: signal count 816
RW-shared spins 0, rounds 0, OS waits 0
RW-excl spins 0, rounds 0, OS waits 0
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 0.00 RW-shared, 0.00 RW-excl, 0.00 RW-sx
------------------------
LATEST DETECTED DEADLOCK
------------------------
2023-11-15 13:40:30 0x14de8
*** (1) TRANSACTION:
TRANSACTION 2171, ACTIVE 0 sec fetching rows
mysql tables in use 1, locked 1
LOCK WAIT 4 lock struct(s), heap size 1128, 4 row lock(s), undo log entries 1
MySQL thread id 61, OS thread handle 77680, query id 6470 localhost 127.0.0.1 root updating
UPDATE test_user_info SET salary = salary + 1
WHERE (age > 12 AND age < 25)
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 2 page no 4 n bits 80 index PRIMARY of table `my_test`.`test_user_info` trx id 2171 lock_mode X locks rec but not gap
Record lock, heap no 4 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 8; hex 800000000000002f; asc /;;-----事务更新的主键索引-----第一个字节是 "80",转换为十进制为 128。后面的 7 个字节 "000000000000002f" 代表一个 64 位的整数,转为十进制为 47
1: len 6; hex 00000000087b; asc {;;
2: len 7; hex 01000001720151; asc r Q;;
3: len 8; hex 7a68616e6773616e; asc zhangsan;;
4: len 4; hex 8000000d; asc ;;
5: len 7; hex 8000000000d200; asc ;;
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 2 page no 4 n bits 80 index PRIMARY of table `my_test`.`test_user_info` trx id 2171 lock_mode X locks rec but not gap waiting
Record lock, heap no 7 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;-----事务更新的主键索引------第一个字节是 "80",转换为十进制为 128。后面的 7 个字节 "000000000000002f" 代表一个 64 位的整数,转为十进制为 1
1: len 6; hex 000000000879; asc y;;
2: len 7; hex 020000016b0151; asc k Q;;
3: len 8; hex 7a68616e6773616e; asc zhangsan;;
4: len 4; hex 8000000f; asc ;;
5: len 7; hex 8000000000d200; asc ;;
*** (2) TRANSACTION:
TRANSACTION 2169, ACTIVE 0 sec fetching rows
mysql tables in use 1, locked 1
LOCK WAIT 4 lock struct(s), heap size 1128, 4 row lock(s), undo log entries 1
MySQL thread id 60, OS thread handle 12696, query id 6468 localhost 127.0.0.1 root updating
UPDATE test_user_info SET salary = salary + 1
WHERE (name = 'zhangsan')
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 2 page no 4 n bits 80 index PRIMARY of table `my_test`.`test_user_info` trx id 2169 lock_mode X locks rec but not gap
Record lock, heap no 7 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;------事务更新的主键索引-----第一个字节是 "80",转换为十进制为 128。后面的 7 个字节 "000000000000002f" 代表一个 64 位的整数,转为十进制为 1
1: len 6; hex 000000000879; asc y;;-----事务id2169
2: len 7; hex 020000016b0151; asc k Q;;---事务回滚指针
3: len 8; hex 7a68616e6773616e; asc zhangsan;;----代表数据值-----十六进制转化后为:zhangsan
4: len 4; hex 8000000f; asc ;;------代表数据值------六进制转化后为:15
5: len 7; hex 8000000000d200; asc ;;------代表数据值salary
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 2 page no 4 n bits 80 index PRIMARY of table `my_test`.`test_user_info` trx id 2169 lock_mode X locks rec but not gap waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 8; hex 800000000000002f; asc /;;-------事务更新的主键索引----第一个字节是 "80",转换为十进制为 128。后面的 7 个字节 "000000000000002f" 代表一个 64 位的整数,转为十进制为 47
1: len 6; hex 00000000087b; asc {;;
2: len 7; hex 01000001720151; asc r Q;;
3: len 8; hex 7a68616e6773616e; asc zhangsan;;
4: len 4; hex 8000000d; asc ;;
5: len 7; hex 8000000000d200; asc ;;
*** WE ROLL BACK TRANSACTION (2)
------------
TRANSACTIONS
------------
Trx id counter 2362
Purge done for trx's n:o < 2362 undo n:o < 0 state: running but idle
History list length 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 283442874948104, not started
0 lock struct(s), heap size 1128, 0 row lock(s)
---TRANSACTION 283442874947328, not started
0 lock struct(s), heap size 1128, 0 row lock(s)
---TRANSACTION 283442874946552, not started
0 lock struct(s), heap size 1128, 0 row lock(s)
---TRANSACTION 283442874945776, not started
0 lock struct(s), heap size 1128, 0 row lock(s)
--------
FILE I/O
--------
I/O thread 0 state: wait Windows aio ((null))
I/O thread 1 state: wait Windows aio (insert buffer thread)
I/O thread 2 state: wait Windows aio (read thread)
I/O thread 3 state: wait Windows aio (read thread)
I/O thread 4 state: wait Windows aio (read thread)
I/O thread 5 state: wait Windows aio (read thread)
I/O thread 6 state: wait Windows aio (write thread)
I/O thread 7 state: wait Windows aio (write thread)
I/O thread 8 state: wait Windows aio (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:
Pending flushes (fsync) log: 0; buffer pool: 0
955 OS file reads, 5540 OS file writes, 3533 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 1 buffer(s)
Hash table size 34679, node heap has 2 buffer(s)
Hash table size 34679, node heap has 2 buffer(s)
Hash table size 34679, node heap has 3 buffer(s)
Hash table size 34679, node heap has 2 buffer(s)
Hash table size 34679, node heap has 3 buffer(s)
Hash table size 34679, node heap has 2 buffer(s)
Hash table size 34679, node heap has 2 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 20808942
Log buffer assigned up to 20808942
Log buffer completed up to 20808942
Log written up to 20808942
Log flushed up to 20808942
Added dirty pages up to 20808942
Pages flushed up to 20808942
Last checkpoint at 20808942
Log minimum file id is 6
Log maximum file id is 6
1753 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 0
Dictionary memory allocated 622315
Buffer pool size 8191
Free buffers 6881
Database pages 1293
Old database pages 457
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 816, not young 4439
0.00 youngs/s, 0.00 non-youngs/s
Pages read 933, created 367, written 2566
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 1293, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=81884, Main thread ID=79028 , state=sleeping
Number of rows inserted 50, updated 535, deleted 22, read 1335
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
Number of system rows inserted 470, updated 362, deleted 168, read 21717
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
5.3元数据'锁表'场景(DDL)
MySQL 内部对于 DDL 的 ALGORITHM 有两种选择:INPLACE 和 COPY(8.0 新增了 INSTANT,但是使用范围较小)。
在mysql5.6.71之前,都是使用COPY的方式。
COPY的原理
1、锁表,期间DML不可并行执行
2、生成临时表以及临时表文件(.frm.ibd)
3、拷贝原表数据到临时表
4、重命名临时表以及文件
5、删除原表以及文件
6、提交事务、释放锁
但是在之后的版本,官方开始支持INPLACE的 ALTER TABLE 操作来避免数据拷贝,同时支持了在线上 DDL 的过程中不阻塞 DML 操作,真正意义上的实现了 Online DDL。然而并不是所有的 DDL 操作都支持在线操作。
语句如下:
ALTER TABLE table_name ADD INDEX index_name (column_name), ALGORITHM=INPLACE, LOCK=NONE;
我们常说的 Online DDL,其实是从 DML 操作的角度描述的,如果 DDL 操作不阻塞 DML 操作,那么这个 DDL 就是 Online 的。当前非 Online 的 DDL 其实已经比较少了,主要有:
- 新增全文索引
- 新增空间索引
- 删除主键
- 修改列数据类型
- 指定表字符集
- 修改表字符集
在执行 DDL 操作时,MySQL 内部对于 ALGORITHM 的选择策略是:如果用户显式指定了 ALGORITHM,那么使用用户指定的选项;如果用户未指定,那么如果该操作支持 INPLACE 则优先选择 INPLACE,否则选择 COPY;
- COPY 算法执行的 DDL 肯定不是 Online 的;
- INPLACE 算法执行的 DDL 不一定是 Online 的;
INPLACE 原理
- prepare阶段:尝试获取MDL排他锁,禁止其他线程读写;
- ddl执行阶段:降级成MDL共享锁,允许其他线程读取;
- commit阶段:升级成MDL排他锁,禁止其他线程读写;
- finish阶段:释放MDL锁;
下面演示两种常见的操作,添加索引和添加字段
5.3.1添加索引
下面我们演示添加索引(支持online-ddl)的过程:
SessionA执行:
select * from test_user_info where name = 'lishi'
不提交;
SessionB执行:
alter table test_user_info
add index name_age_index (name, age)
不提交;
SessionC执行:
select * from test_user_info where name = 'lishi'
不提交;

我们发现,SessionC的查询也阻塞了。
这时,我们提交SessionA, 我们发现SessionC可以自动执行了,但是SessionB的添加索引还是阻塞。

现象1: SessionA的查询未提交,阻塞SessionB的执行;SessionB被阻塞后,阻塞SessionC的查询;
分析: SessionA的查询未提交,表加元数据读锁;SessionB执行,获取到表的元数据写锁,因为元数据读写锁互斥,SessionB被阻塞;SessionC执行,获取表的元数据读锁,因为元数据读写锁互斥,SessionC被阻塞。
问题: 原本可以并行执行的操作被阻塞了。
现象2: SessionA提交事务,此时SessionC优先执行,SessionB继续被阻塞;SessionC提交事务后,SessionB才可以执行。
结论:当DDL添加索引因为其他DML操作阻塞时,需要等待其他所有DML操作都提交后才能执行,即使在阻塞后有其他DML操作进来,其他DML操作也优先于DDL添加索引执行。
这会造成什么问题?
假如一个表的并发访问很高,DDL操作可能会超时。如果数据库有慢查询,比如如下查询,查询返回数据需要30秒:
SELECT SLEEP(30) FROM my_test.test_user_info WHERE NAME = 'lisi'
因为DDL执行时,会阻塞其之后执行的DML操作,可能导致之后的DML操作积压,也会造成单个DML操作返回时间过长。可能造成业务系统数据库连接被打满,接口超时,即使不超时也会因为返回时间过长影响用户体验。这种现象看来,就仿佛表被锁住了一样,虽然不是真正意义上的锁表。
所以我们在执行ALTER操作的时候,尽量在业务不繁忙的阶段执行。
5.3.2添加字段
SessionA执行:
SELECT * FROM my_test.test_user_info WHERE NAME = 'lisi'
SessionB执行:
alter table test_user_info
add column hometown varchar(255) default null
SessionC执行:
update test_user_info set salary = salary+1 where age = 12
SessionD执行:
delete from test_user_info where id = 100
均不自动提交事务

现象1: SessionA的查询未提交,阻塞SessionB的执行;SessionB被阻塞后,阻塞SessionC的执行;SessionB被阻塞后,阻塞SessionD的执行;
分析: SessionA的查询未提交,表加元数据读锁;SessionB执行,获取到表的元数据写锁,因为元数据读写锁互斥,SessionB被阻塞;SessionC执行,获取表的元数据读锁,因为元数据读写锁互斥,SessionC被阻塞;SessionD执行,获取表的元数据读锁,因为元数据读写锁互斥,SessionD被阻塞。
现象2: SessionA提交事务,此时SessionB,SessionC,SessionD全部自动执行。
结论:当DDL添加字段因为其他DML操作阻塞时,需要等待其他所有DML操作都提交后才能执行,当阻塞DDL添加字段的DML执行后,DDL添加字段和后续的DML均可同步执行。这点和添加索引完全不同。
5.4.pt-online-schema-change
pt-online-schema-change 是一个用于在线更改 MySQL 表结构的工具,它是 Percona Toolkit 的一部分。它的原理是通过在线复制表数据,同时在新表上应用修改,从而避免了直接修改原始表结构导致的锁表和性能下降问题。
pt-online-schema-change 的原理:
- 创建一张新表,表结构与旧表相同;
- Alter 新表;
- 在原表上创建 insert、update、delete 三种类型的触发器;
- 将旧表的数据拷贝到新表中,同时通过触发器将旧表中的操作映射到新表;
- 如果原表有外键约束,处理外键;
- 原表重命名为 old 表,new 表重命名为原表,整个过程为原子操作;
- 删除 old 表(默认);
pt-online-schema-change 在以下场景中特别有用:
- 修改大型表的结构:对于包含数百万甚至数十亿行的大型表,直接修改表结构可能导致长时间的锁表和性能下降。
pt-online-schema-change通过在线方式避免了这些问题。 - 避免业务中断:在需要修改生产环境数据库表结构时,
pt-online-schema-change可以在不影响业务正常运行的情况下进行表结构更改。 - 兼容各种存储引擎:
pt-online-schema-change支持各种 MySQL 存储引擎,如 InnoDB 和 MyISAM。
7.建议
mysql在非唯一索引上的操作,会加间隙锁或临键锁;根据数据的分散情况,可能产生大量的锁,可能导致大量的行或间隙被锁定。阻塞其他事务的insert,update,delete等操作,有产生死锁的风险,对数据库性能影响较大。对mysql的insert,update,delete或select for update等操作,建议都在唯一索引上进行。实际业务中,我们要根据二级索引更新数据前,可以先将数据的主键查询出来,再根据主键批量操作,这样虽然增加了查询操作,但是只会在唯一索引上加记录锁,锁定行数较少,对其他事务的操作影响较小,提高了数据库的写的性能。
对于表的DDL操作,建议在业务不繁忙的时间段执行,或依赖第三方工具,如pt-online-schema-change来处理。
8.参考文档
MySql8.0官方文档:
https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html#innodb-next-key-locks
MySQL8.0优化 - 锁 - 从数据操作的粒度划分:
https://blog.csdn.net/ChinaYangJu/article/details/127939056
详细剖析MySQL临键锁:
https://blog.csdn.net/Bb15070047748/article/details/131766686
mysql隔离级别RR下的行锁、临键锁、间隙锁详解及运用:
https://blog.csdn.net/qq_35572020/article/details/127629464
pt-online-schema-change
https://blog.csdn.net/weixin_44352521/article/details/108558026
标签:实战,LOCK,age,查询,索引,详细,Mysql,test,id From: https://www.cnblogs.com/wang-meng/p/17838563.html