公众号「架构成长指南」,专注于生产实践、云原生、分布式系统、大数据技术分享。
数据库和Redis如何保持强一致性,这篇文章告诉你
目的
Redis和Msql来保持数据同步,并且强一致,以此来提高对应接口的响应速度,刚开始考虑是用mybatis的二级缓存,发现坑不少,于是决定自己搞
要关注的问题点
操作数据必须是唯一索引
如果更新数据不是唯一索引,则数据库更新后的值,与缓存不一致,而查询还会走缓存,而查询的值是脏值。
查询唯一数据,数据值必须是全部字段
假如:B交易查询字段不是全部字段,进行查询放入缓存,A交易进行查询时,从缓存获取,由于A交易需要全部字段,所以就会出现不可预知的问题。
查询缓存数据后,必须要在程序中再次进行条件判断
因为在redis中,存储的的key是唯一索引,所以当查询数据后,只会命中唯一索引的数据,其他附带查询条件不生效。
例如:唯一索引为:user_id ,那么执行
select * from t_user_auth_info where user_id=‘111’ and user_level=‘1’是,条件user_level是不会生效
高并发场景下要注意脏数据的控制
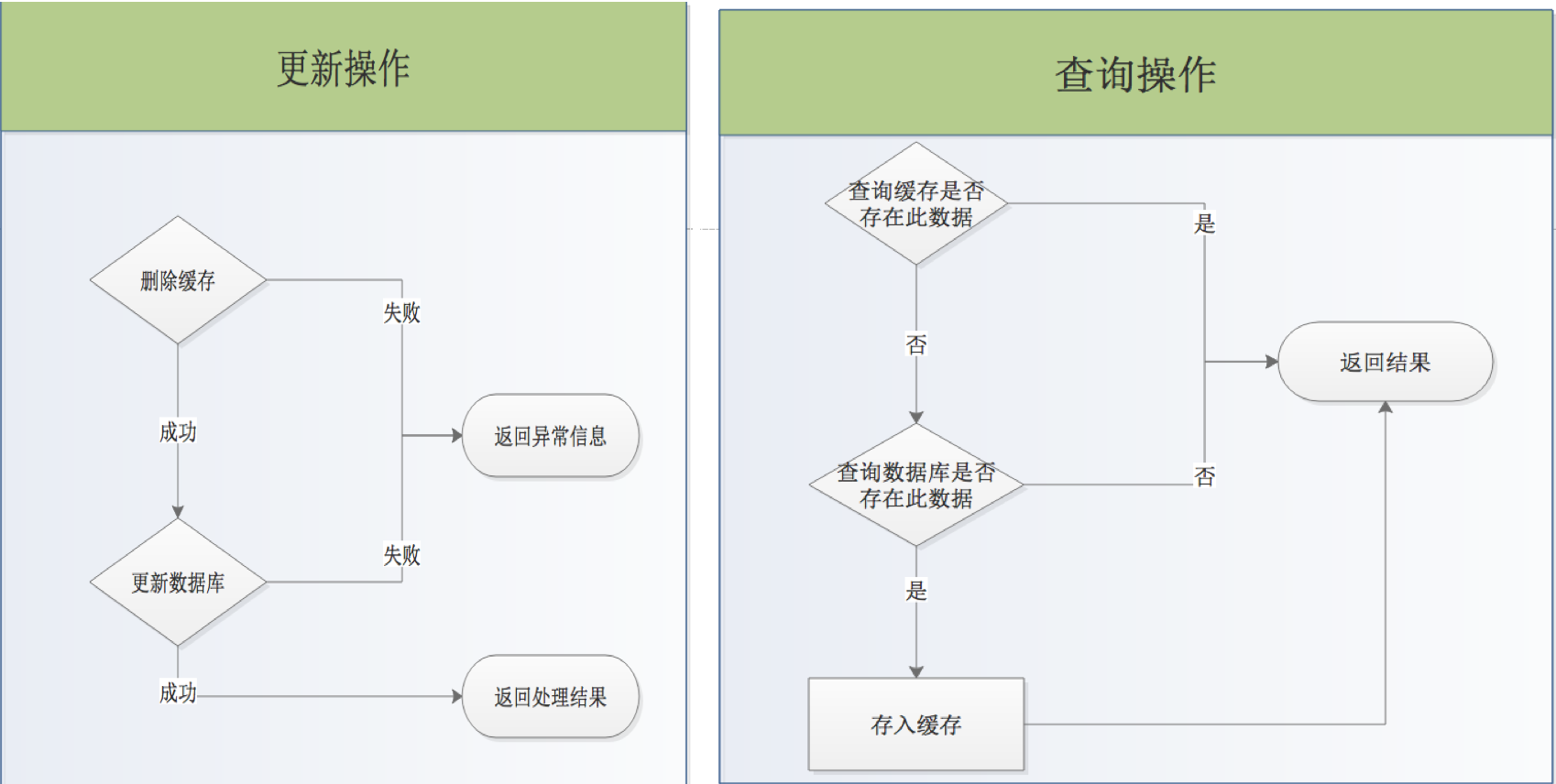
假设是以上流程图,在更新操作,第一步删除缓存后,线程切换到查询线程,查询操作判断缓存中没有数据,就会查询数据库,并把数据存入到缓存中,这时线程在切换到更新线程,进行数据库的更新,这会就会造成,数据库的数据与缓存有不一致性。
最终方案
基于以上问题,我们的最终流程图如下
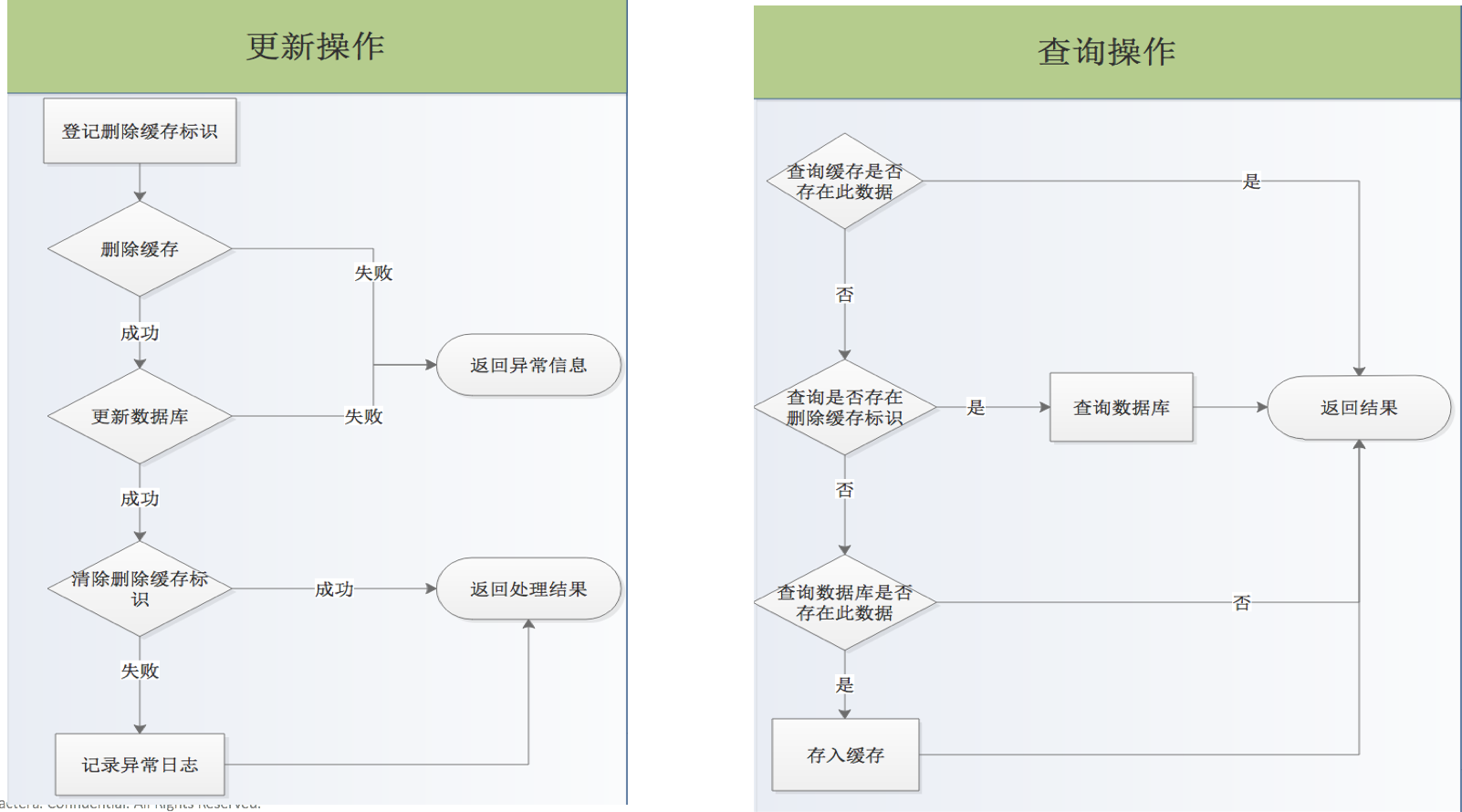
以上流程图在进行更新操作时,增加删除缓存lock,如果这会查询操作判断缓存中有数据,就直接返回数据,如果没有再次判断有没有存在删除缓存lock,如果有则走数据库查询,并返回,不放入缓存,如果没有则查询数据库,并放入缓存,并返回。
注意: 登记缓存标识时,增加缓存lock失效时间,因为有可能删除缓存和数据库更新成功了,而删除缓存lock失败了,那这样后续查询就都走数据库了,这个方案就失去意义了。
代码实现方案
通过aop对db的操作方法,进行拦截,查询方法采用一个切面,删除和更新方法采用一个切面,然后再按照以上流程进行编写,我们这边是使用框架进行封装,最后只需要开发人员配置以下xml即可
<cache-config>
<cache-entity po="com.demo.po.AuthUser" key-prefix="SYSTEM_Person" po-throws="true" key-expire="" key-expire-time-unit="">
<key-properties>userId</key-properties>
</cache-entity>
</cache-config>
如果需要具体实现方案,请联系作者
标签:生产实践,缓存,数据库,Redis,更新,查询,user,Mysql,数据 From: https://www.cnblogs.com/waldron/p/17853511.html