SQL是一种处理数据的编程语言
先看看使用python是如何读入csv数据的
import csv
with open("phonebool.csv","r") as file:
reader = csv.reader(file)
for row in reader:
print(row[1])
需要注意的是row[1]指的是每一行的第二个数据
import csv
with open("phonebool.csv","r") as file:
reader = csv.DictReader(file)
for row in reader:
favorite = row["name"]
print(favorite)
使用DicReader() 可以得到一个字典就可以把列之间调换了
如果定义一个函数只在一个地方使用,我们就可以使用 lambda 函数,例如:
def get_value(language):
return counts[language]
和
lambda language: counts[language]
是等价的
SQL无非就是在做四件事情,创建数据,读取数据,更新数据,删除数据
缩写CRUD,create,read,update,delete
SQL中支持一些命令,包括
AVG
COUNT
DISTINCT
LOWER
MAX
MIN
UPPER
SQL中有一些关键字
WHERE -- adding a Boolean expression to filter our data
LIKE -- filtering responses more loosely
ORDER BY -- ordering responses
LIMIT -- limiting the number of responses
GROUP BY -- grouping responses together
IMDb
- IMDb提供了人物、节目、作家、明星、流派和评级的数据库。这些表格彼此之间的关系如下:

-
在下载
shows.db之后,你可以执行sqlite3 shows.db在你的终端中 -
在执行
.schema时,您不仅可以找到每个表,还可以找到每个字段中的单个字段。 -
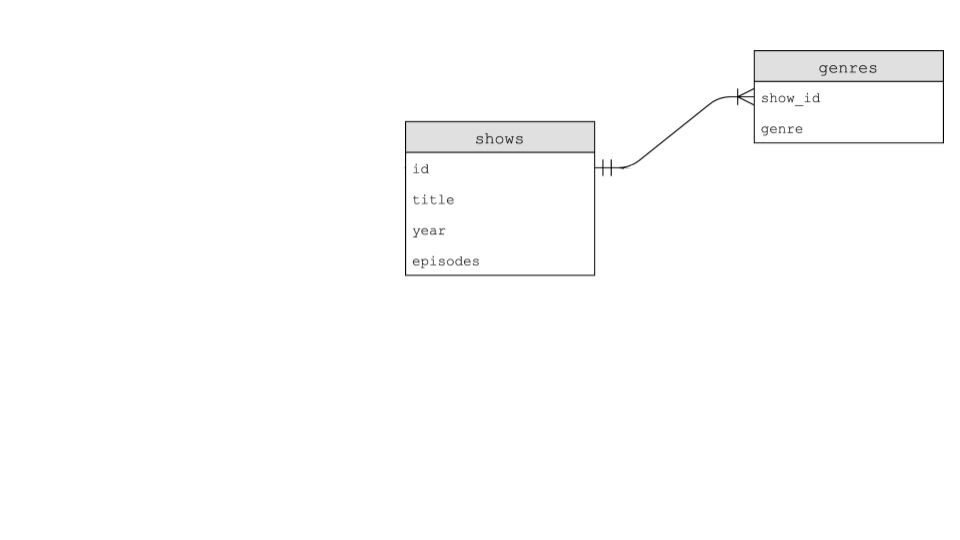
从上图可以看到,
show有一个id字段。genres table有一个show_id字段,其中包含它与shows table之间的公共数据。 -
正如你上面看到的图片一样,
show_id在所有表中都存在。在show table中,它被简单地称为id。所有字段之间的公共字段称为key。主键(Primary key)用于标识表中的唯一记录。外键(Foreign keys)用于通过指向另一个表中的主键来建立表之间的关系。 -
如上所述,通过在关系数据库中存储数据,可以更有效地存储数据。
-
在sqlite中,我们有五种数据类型,包括:
BLOB -- binary large objects that are groups of ones and zeros
INTEGER -- an integer
NUMERIC -- for numbers that are formatted specially like dates
REAL -- like a float
TEXT -- for strings and the like
- 此外,列可以被限制通过添加特殊约束:
NOT NULL
UNIQUE
为了进一步说明这些表之间的关系,我们可以执行以下命令:SELECT * FROM people LIMIT 10;检查输出,我们可以执行SELECT * FROM shows LIMIT 10;此外,我们可以执行SELECT * FROM stars LIMIT 10;我们可以看到,show_id是一个外键(Examining ),因为show_id是shows中的唯一的id字段。Person_id对应于people列中的唯一的id字段。
我们可以进一步利用这些数据来理解这些关系,执行SELECT * FROM genres;,会出现很多流派
我们可以通过执行SELECT * FROM genres WHERE genre = 'Comedy' LIMIT 10;可以看到显示了10个节目。
如果想查明是哪个id为626124的是哪个节目可以通过执行SELECT * FROM shows WHERE id = 626124;
显然,我们不可能一个一个手动去输入,我们可以进一步的提高效率通过执行
SELECT title
FROM shows
WHERE id IN (
SELECT show_id
FROM genres
WHERE genre = 'Comedy'
)
LIMIT 10;
注意到,这里有两个查询嵌套在一起,外部查询使用了内部查询的答案
我们可以通过执行进一步改进
SELECT title
FROM shows
WHERE id IN (
SELECT show_id
FROM genres
WHERE genre = 'Comedy'
)
ORDER BY title LIMIT 10;
这样子就按照字母升序排列了
如果你想找到所有由Steve Carell主演的电视剧呢? 你可以执行SELECT * FROM people WHERE name = 'Steve Carell'; 你可以找到他的个人id。你可以使用这个id去确定他演过的shows。然而,一个接一个的查找是乏味的。我们可以通过执行下面代码来快速实现这一点
SELECT title FROM shows WHERE id IN
(SELECT show_id FROM stars WHERE person_id =
(SELECT * FROM people WHERE name = 'Steve Carell'));
JOIN
考虑以下两张表:
我们怎么临时地结合这两个表,可以使用JOIN命令将表连接在一起。
执行如下命令:
SELECT * FROM shows
JOIN ratings on shows.id = ratings.show_id
WHERE title = 'The Office';
现在你可以看到所有被称为“The Office”的节目。
你可以使用JOIN 对 Steve Carel 的节目进行查询
SELECT title FROM people
JOIN stars ON people.id = stars.person_id
JOIN shows ON stars.show_id = shows.id
WHERE name = `Steve Carell`;
就相当于把三个表融合在了一起,然后查看他的title列
注意到,每一个JOIN 命令能让我们知道,那些列是与其他列匹配的
我们也可以通过下列操作来做到相同的效果
SELECT title FROM people, stars, shows
WHERE people.id = stars.person_id
AND stars.show_id = shows.id
AND name = 'Steve Carell';
有些时候我们不知道全部名字,就可以使用模糊搜索,比如Steve C% 表示Steve C.... 类似的东西,前面的查询需要加上LIKE ,完整的就是SELECT * FROM people WHERE name LIKE 'Steve C%';
Index
我们可以使用index来优化databases,index可以加快查询的速度
我们可以通过再sqlite3 中执行.timer on 来观察执行的时间
先执行 SELECT * FROM shows WHERE title = 'The Office'; 观察时间
然后我们执行命令创造index CREATE INDEX title_index on shows (title);,这句话告诉了sqlite3 去创造一个index,并且执行一些特殊的优化对于title的每一列
我们创造了一个 B Tree ,一种类似与二叉树的数据结构

执行命令 SELECT * FROM shows WHERE title = 'The Office'; 我们可以发现查询的速度快了很多
不幸的是,对所有列建立索引将导致使用更多的存储空间。因此,提高速度是有代价的。
Using SQL in Python
为了帮助在本课程中使用SQL, CS50库可以在您的代码中使用如下:
from cs50 import SQL
与CS50库之前的用法类似,这个库将帮助您完成在Python代码中使用SQL的复杂步骤。
您可以在文档中阅读有关CS50库的SQL功能的更多信息。
回想一下我们上次在favorites.py中讲到的地方。你的代码应该如下所示:
# Favorite problem instead of favorite language
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Counts
counts = {}
# Iterate over CSV file, counting favorites
for row in reader:
favorite = row["problem"]
if favorite in counts:
counts[favorite] += 1
else:
counts[favorite] = 1
# Print count
favorite = input("Favorite: ")
if favorite in counts:
print(f"{favorite}: {counts[favorite]}")
修改代码如下:
# Searches database popularity of a problem
import csv
from cs50 import SQL
# Open database
db = SQL("sqlite:///favorites.db")
# Prompt user for favorite
favorite = input("Favorite: ")
# Search for title
rows = db.execute("SELECT COUNT(*) FROM favorites WHERE problem LIKE ?", "%" + favorite + "%")
# Get first (and only) row
row = rows[0]
# Print popularity
print(row["COUNT(*)"])
注意到 db = SQL("sqlite:///favorites.db") 向Python提供数据库文件的位置。然后,从rows 开始的哪一行,使用 db.exeute 来执行SQL命令,我们可以通过这种语法执行任意的 SQL 命令,并且通过字符串返回到rows中,作为字典的列表。在本例中,只有一个结果,即一行,作为字典返回到行列表。
其中?代表占位符,和printf的用法类似
Race Conditions
使用SQL有时会导致一些问题。
您可以想象这样一种情况:多个用户可以同时访问同一个数据库并执行命令。
这可能会导致代码被其他人的操作打断。这可能导致数据丢失。
内置的SQL特性(如BEGIN TRANSACTION、COMMIT和ROLLBACK)有助于避免其中一些竞争条件问题。
SQL Injection Attacks
在现实生活中,可能出现出现一个问题叫做注入式攻击(injection attack)。注入攻击是指恶意参与者可以输入恶意SQL代码。
例如,考虑如下的界面

如果在我们自己的代码中没有适当的保护,坏人可能会运行恶意代码。考虑以下几点:
rows = db.execute("SELECT COUNT(*) FROM favorites WHERE problem LIKE ?", "%" + favorite + "%")
注意到,因为?的位置,就可以通过验证
永远不要像上面那样在查询中使用格式化字符串,也不要盲目相信用户的输入。
标签:week7,favorite,CS50x,SQL,WHERE,id,SELECT,shows From: https://www.cnblogs.com/martian148/p/17745304.html