探索Redis的字符串设计思想
作者:沈自在
1 引言
在Redis中的字符串和我们平时Java中所写的字符串是不一样的,在Java的设计中String是由final修饰的,因此也就成就了他不可变的特性。此外,在C语言的字符标准形式中是以NULL结尾的,但是要通过strlen函数去获取长度的复杂度却是O(n)的,可还记得keys的O(n)有多么吓人。
在Redis的实现中是设计了一个叫做“SDS”的结构(Simple Dynamic String),如下面源码片段所示,他的结构是一个带长度的字节数组。
struct{
T capacity; //数组容量
T len; //数组长度
byte flags; // 标识位
byte[] content; // 数组内容
}
这样的设计就很类似ArrayList了,同时它的追加机制也很类似ArrayList了。
上面的SDS结构体可以看到在长度和容量处采用了 T 范型,之所以不使用int其实是作者对Redis的优化操作,如果当字符串长度很小的时候采用一个int做长度容量的空间的话就显得很浪费了。
2 存储方式
Redis对字符串的存储存在俩种存储方式,在长度特别短时使用embstr ,当长度大于44字节时使用raw存储,这里的设计和Redis的内存分配有莫大的关系。
Redis的每个对象都有一个对象头,他的结构是这样的:
struct RedisObject {
int4 type; // 4bits
int4 encoding; // 4bits
int24 lru; // 24bits
int32 refcount; // 4bytes
void *ptr; // 8bytes,64-bit system
} robj;
不同的对象具有不同的类型 type(4bit),同一个类型的 type 会有不同的存储形式encoding(4bit),为了记录对象的 LRU 信息,使用了 24 个 bit 来记录 LRU 信息。每个对象都有个引用计数,当引用计数为零时,对象就会被销毁,内存被回收。ptr 指针将指向对象内容 (body) 的具体存储位置。这样一个 RedisObject 对象头需要占据 16 字节的存储空间
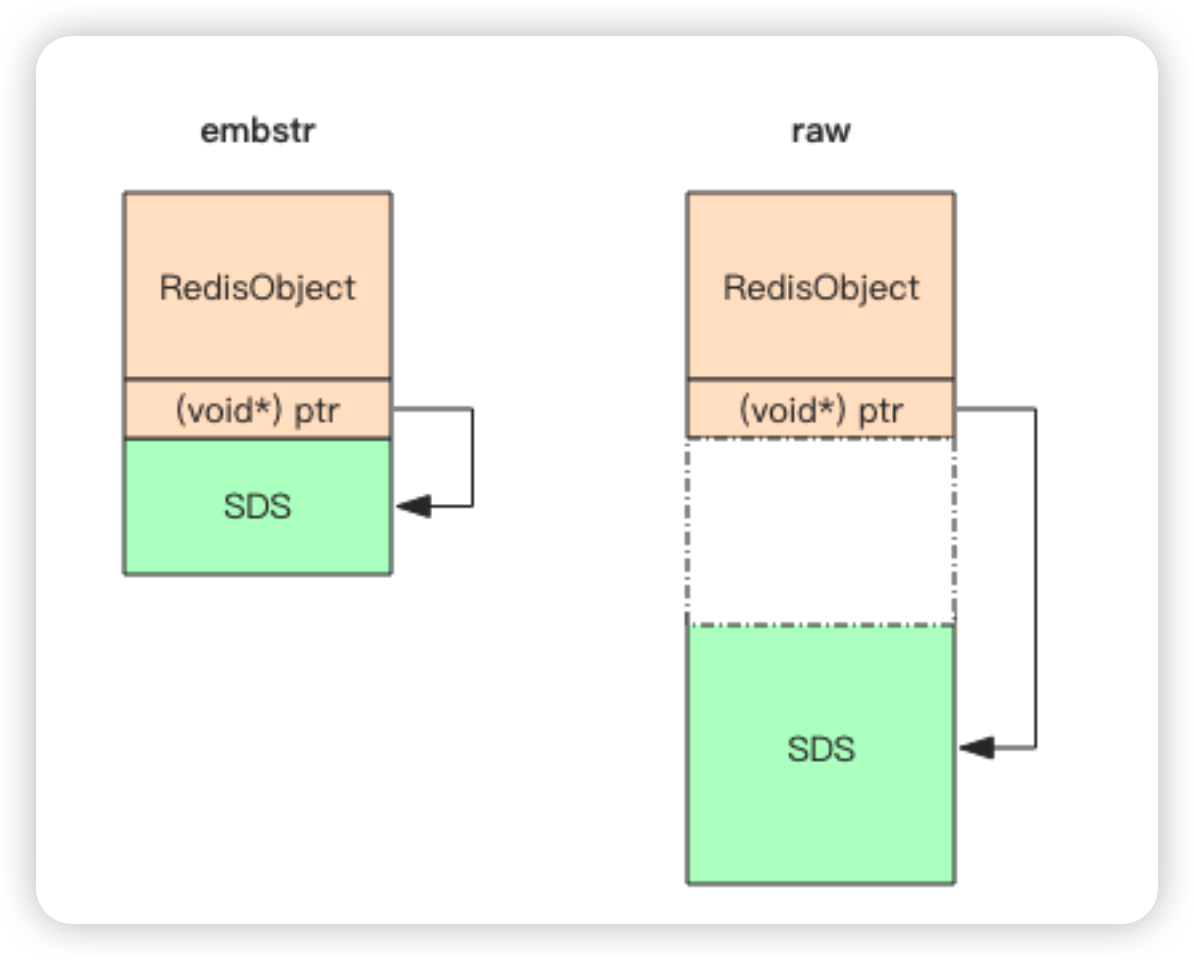
如图所示,embstr 存储形式是这样一种存储形式,它将 RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配。而 raw 存储形式不一样,它需要两次malloc,两个对象头在内存地址上一般是不连续的。而内存分配器 jemalloc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、32、64 等等,为了能容纳一个完整的 embstr 对象,jemalloc 最少会分配 32 字节的空间,如果字符串再稍微长一点,那就是 64 字节的空间。如果总体超出了 64 字节,Redis 认为它是一个大字符串,不再使用 emdstr 形式存储,而该用 raw 形式。
当内存分配器分配了 64 空间时,那这个字符串的长度最大可以是多少呢?这个长度就是 44。那为什么是 44 呢?前面我们提到 SDS 结构体中的 content 中的字符串是以字节\0 结尾的字符串,之所以多出这样一个字节,是为了便于直接使用 glibc 的字符串处理函数,以及为了便于字符串的调试打印输出。
看上面这张图可以算出,留给 content 的长度最多只有 45(64-19) 字节了。字符串又是以\0 结尾,所以 embstr 最大能容纳的字符串长度就是 44。
标签:存储,字节,探索,Redis,64,字符串,长度 From: https://www.cnblogs.com/shenzizai/p/17742464.html