Redis 是目前最流行的键值对存储数据库,凭借高性能和丰富的数据类型的特性,不仅可以作为缓存,还可以作为一个可持久化的数据库存储。随着业务的发展和版本的迭代,必然会遇到内存不足、集群节点不够和 BUG 等一系列问题。为了防止这些问题导致的系统故障,常常会把对内存、集群节点扩缩容和版本升级等操作作为工作考核的重要一项。这些操作都涉及了数据的迁移,所以,提供高效、安全的不停机数据迁移方案是非常有必要的。
现在,NineData 在支持业务不中断的前提下,实现了配置简单、稳定、高效、安全的数据迁移服务,很好地满足版本升级、扩容、缩容等场景下对数据迁移和同步的需求。经实测,NineData 可在 2 分钟内完成 2000 万个 key(5GB)数据的迁移,平均 迁移速度为 164398 个 key/秒,性能是开源工具的 2 倍多。
1、传统的迁移方案
目前,数据迁移主要的方式有:使用 RDB 迁移,或一些开源工具进行数据迁移。对于这些方式的迁移,会存在一些问题:
-
需要停机,对于拷贝 RDB 文件方式的迁移,不能保障在线业务,并且也不能兼容大版本升级。
-
准确性难保障,不支持数据检测能力,迁移后的数据质量难以保障。
-
可靠性差,对于开源工具,迁移异常后,进程直接退出。
-
运维性差,不能进行暂停、限流、告警等操作。
2、高性能的迁移方案
NineData 提供的数据复制同时包含了数据迁移和数据同步的能力,在不影响业务的前提下,提供了高效、稳定、安全的迁移能力。相较于传统迁移比,NineData 的 Redis 数据迁移能力有如下优势:
▶︎ 简单易用
一分钟即可完成任务配置,并全自动化完成任务迁移。
▶︎ 强劲性能
通过动态攒批、队列优化、流式内存管理等核心技术,迁移性能达到 16 万 key/秒,性能是开源迁移工具的 2 倍,有效保障迁移效率。
▶︎ 高可靠
结合新型断点、异常诊断及丰富的修复手段,对于迁移过程中可能出现软硬件故障,提供完善的容灾能力,大大提高了迁移的成功率。
通过上述优势,保证了 NineData 在 Redis 迁移场景下的领先性。另外,NineData 还提供了对比功能,包含全量、快速和不一致复检的对比方式,并且也支持不同的对比频率。在迁移或复制结束后,通过对比,有效地保障数据的质量。
3、操作使用
NineData 在提供强大迁移能力的同时,也保证了使用的简单性,只需 1 分钟就能完成迁移任务的配置,实现完全自动化的数据迁移过程。下面我们来看下整个任务的配置过程:
3.1 迁移链路的配置
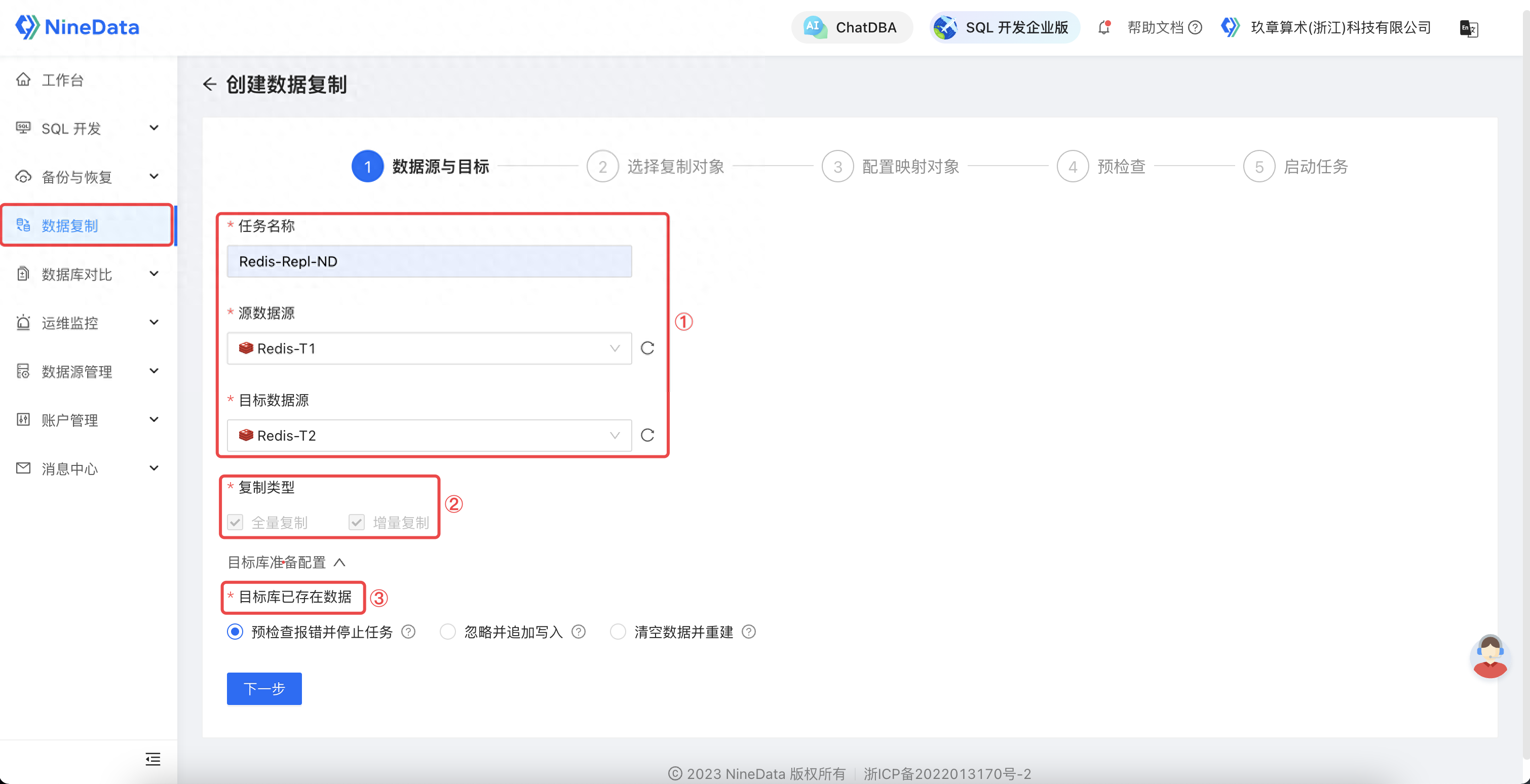 迁移链路的配置
迁移链路的配置
1. 配置任务名称,选择要迁移的源和目标实例。
2. 选择复制类型,数据迁移选择结构和全量复制(数据迁移)。
3. 根据需要,选择合适的冲突处理策略。
3.2 选择迁移对象
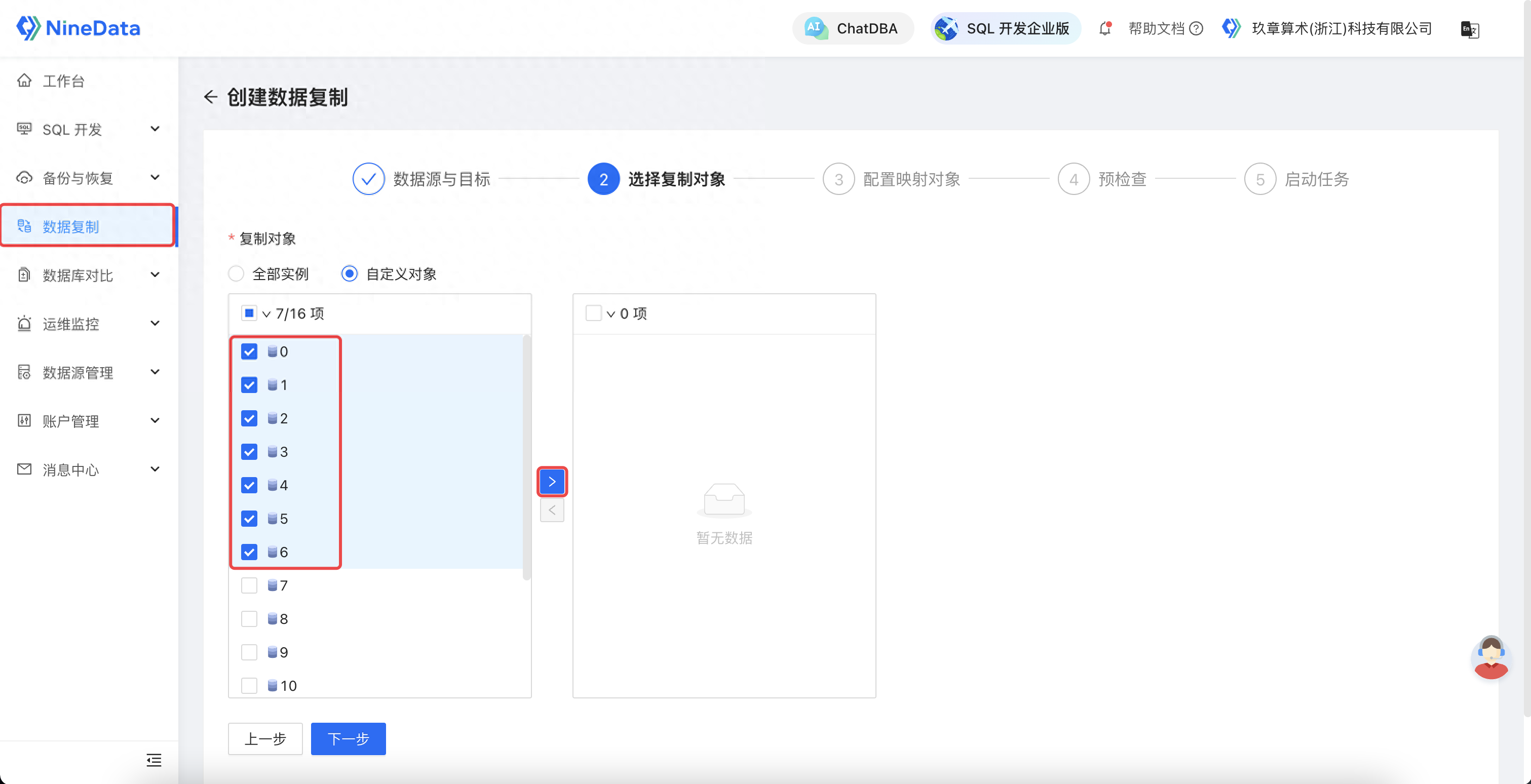 选择迁移对象
选择迁移对象
选择迁移对象:可选择不同 DB 进行迁移。
3.3 配置映射对象
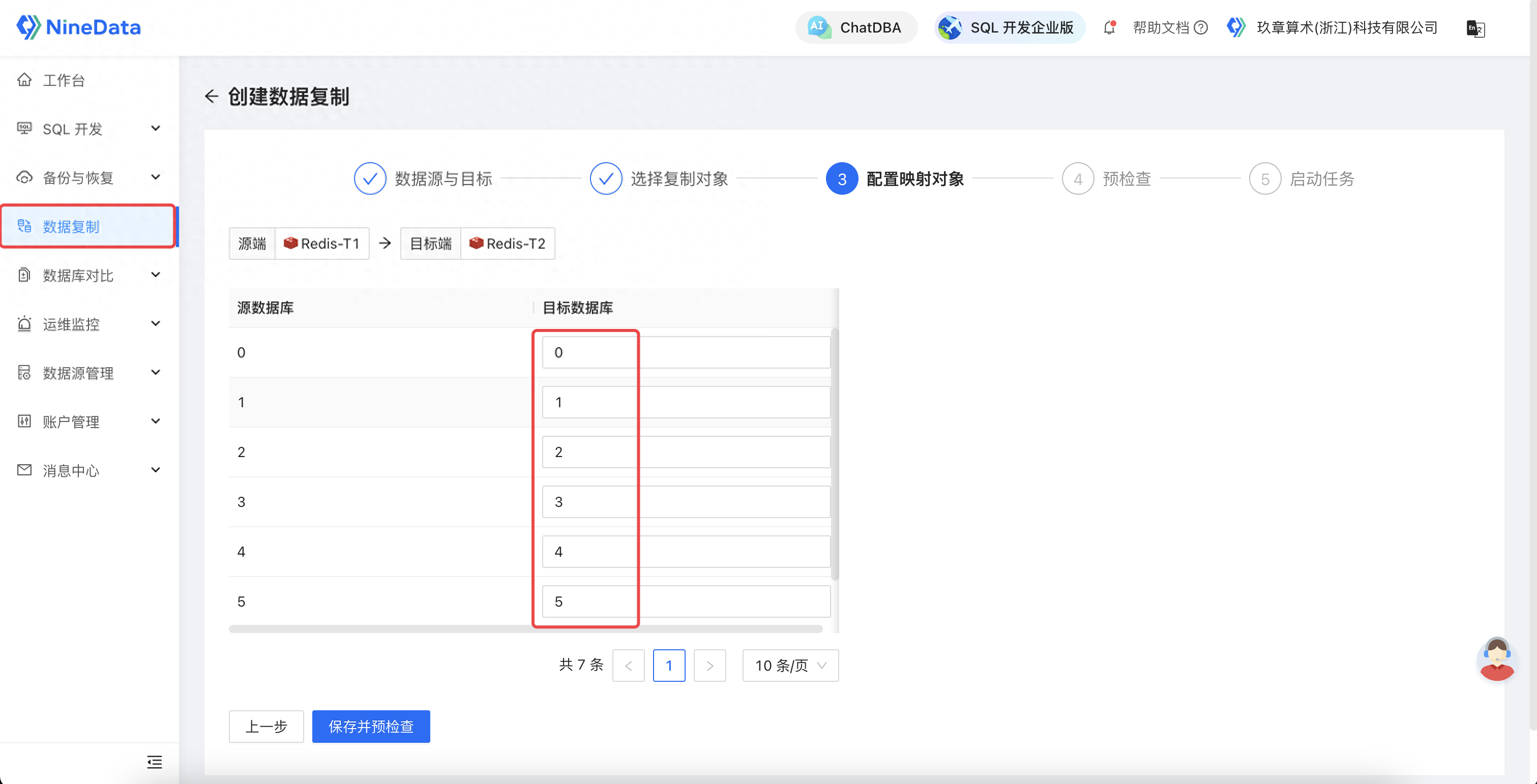 配置映射对象
配置映射对象
配置映射:可以把源实例的多个数据库(0~15)映射到目标实例的指定 1 个或多个数据库,通过该映射能力可以实现类似于 MySQL 多源复制的场景。
3.4 预检查
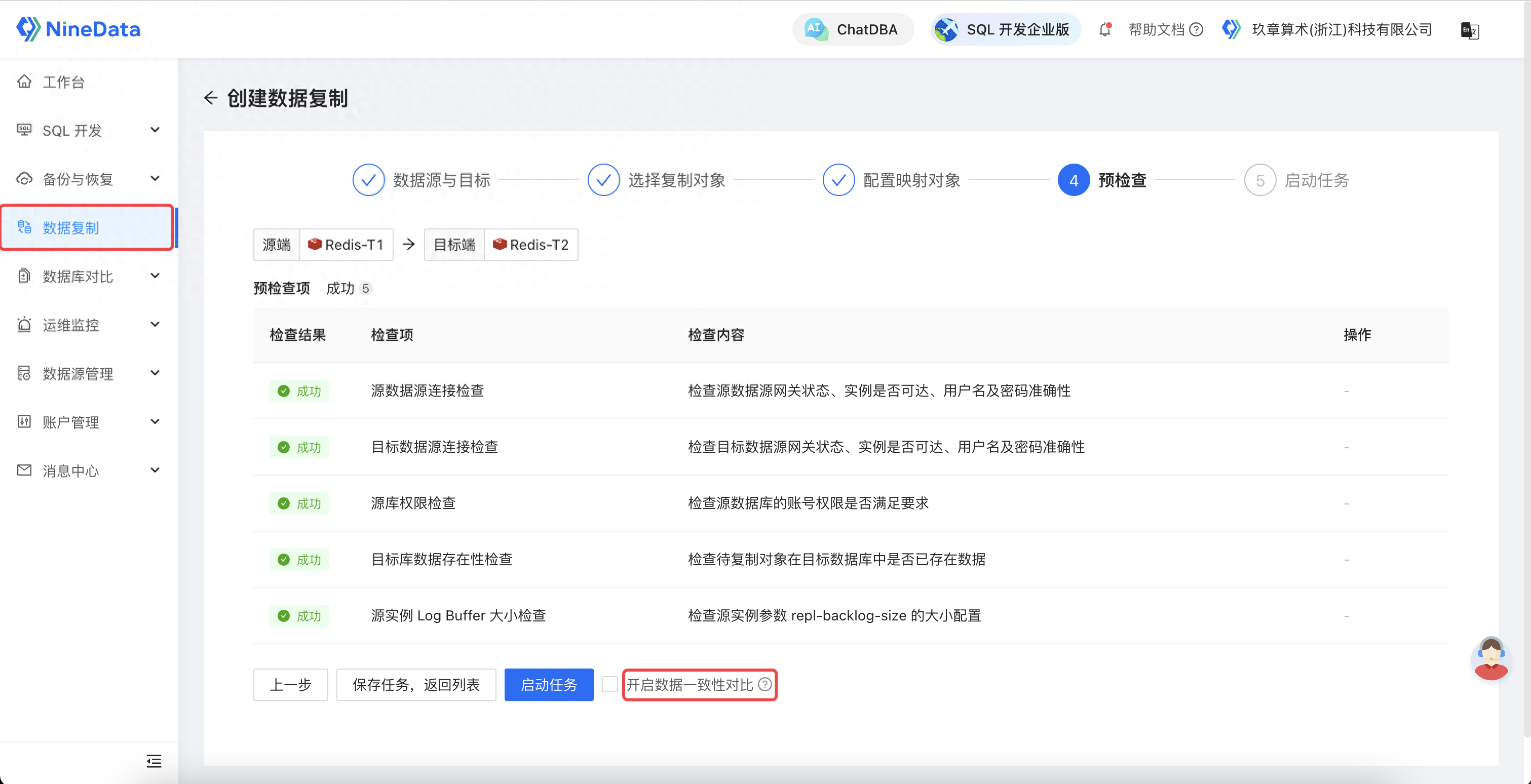 预检查
预检查
通过完善的检查项,保证了迁移任务的稳定性。到此,我们就完成了一个高效、安全的 Redis 迁移任务的配置,当完成配置并启动任务后,NineData 会自动启动全量复制及增量复制过程,实现全自动化的数据迁移。
同时,为了提供更好的迁移体验,NineData 针对迁移过程提供了完善的观测、干预能力。其不但提供对象迁移的详细状态、进展、详情,还通过监控和日志透露后台线程的内部执行情况,帮助用户全方位追踪迁移进展。同时,还针对运行过程中可能出现的异常情况,提供基础诊断和迁移限流能力,让用户能够自主快速地诊断并修复链路,保障迁移稳定性。迁移期间的信息:
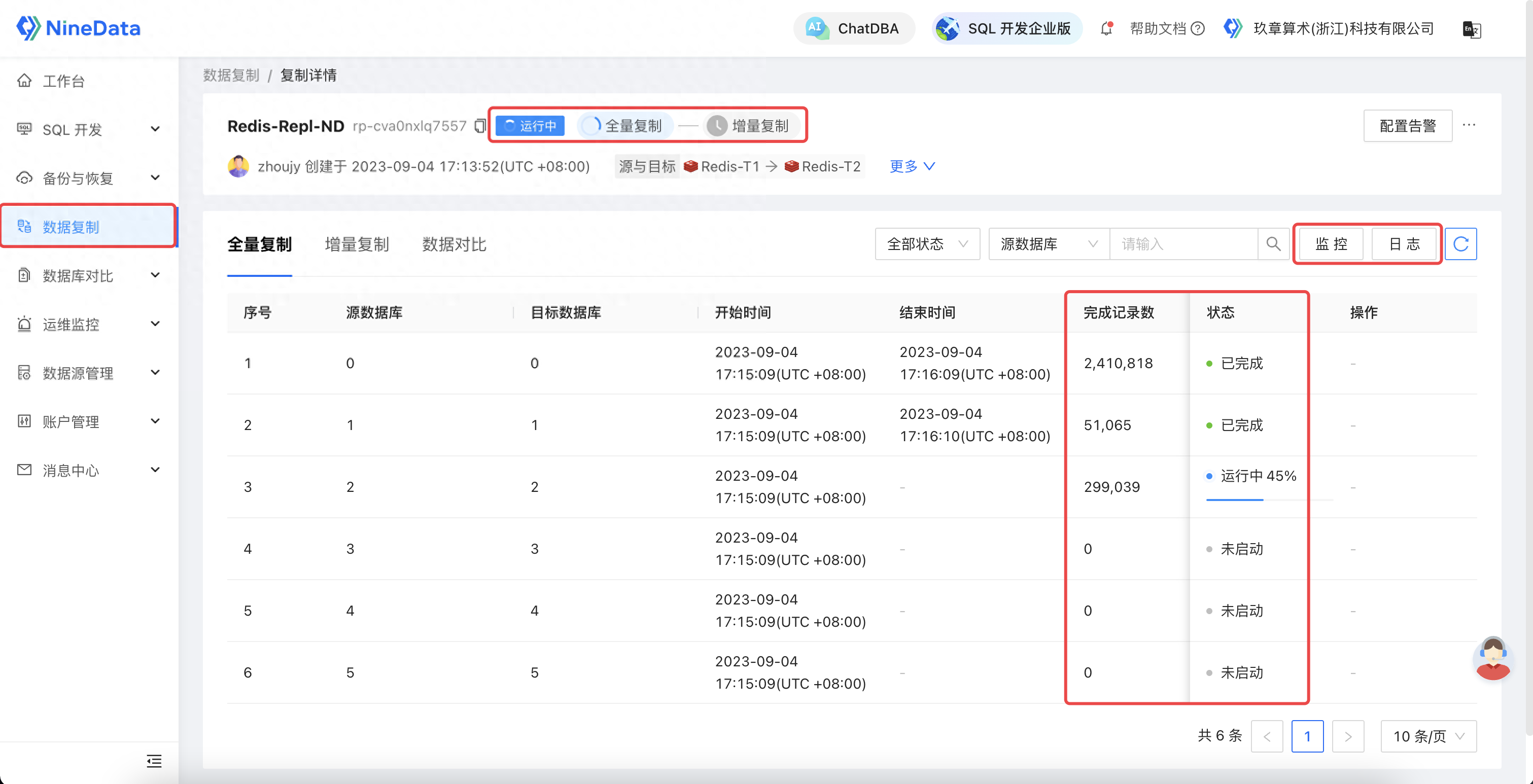 NineData针对迁移过程提供了完善的观测能力
NineData针对迁移过程提供了完善的观测能力
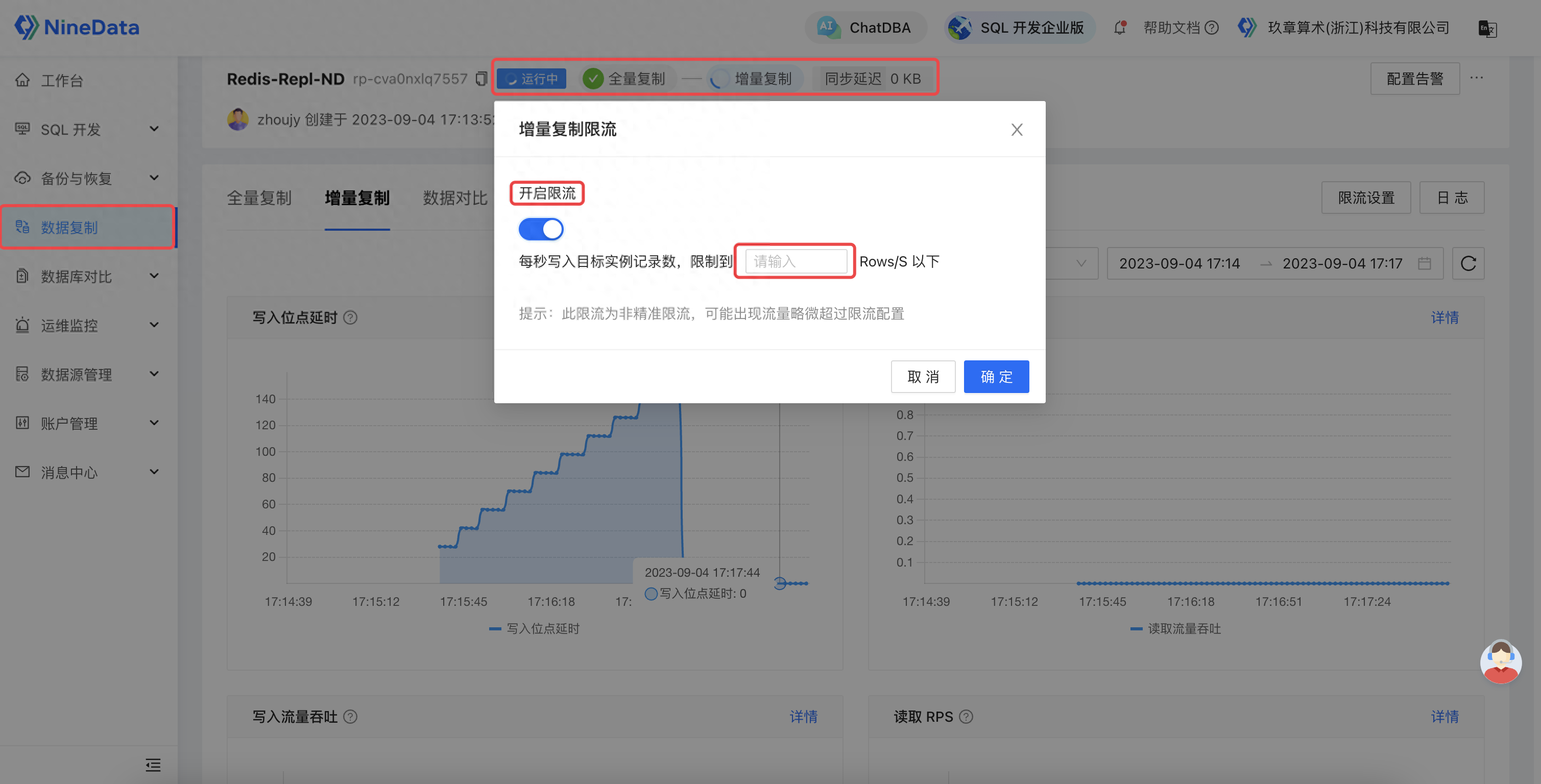 NineData提供完善的可干预能力
NineData提供完善的可干预能力
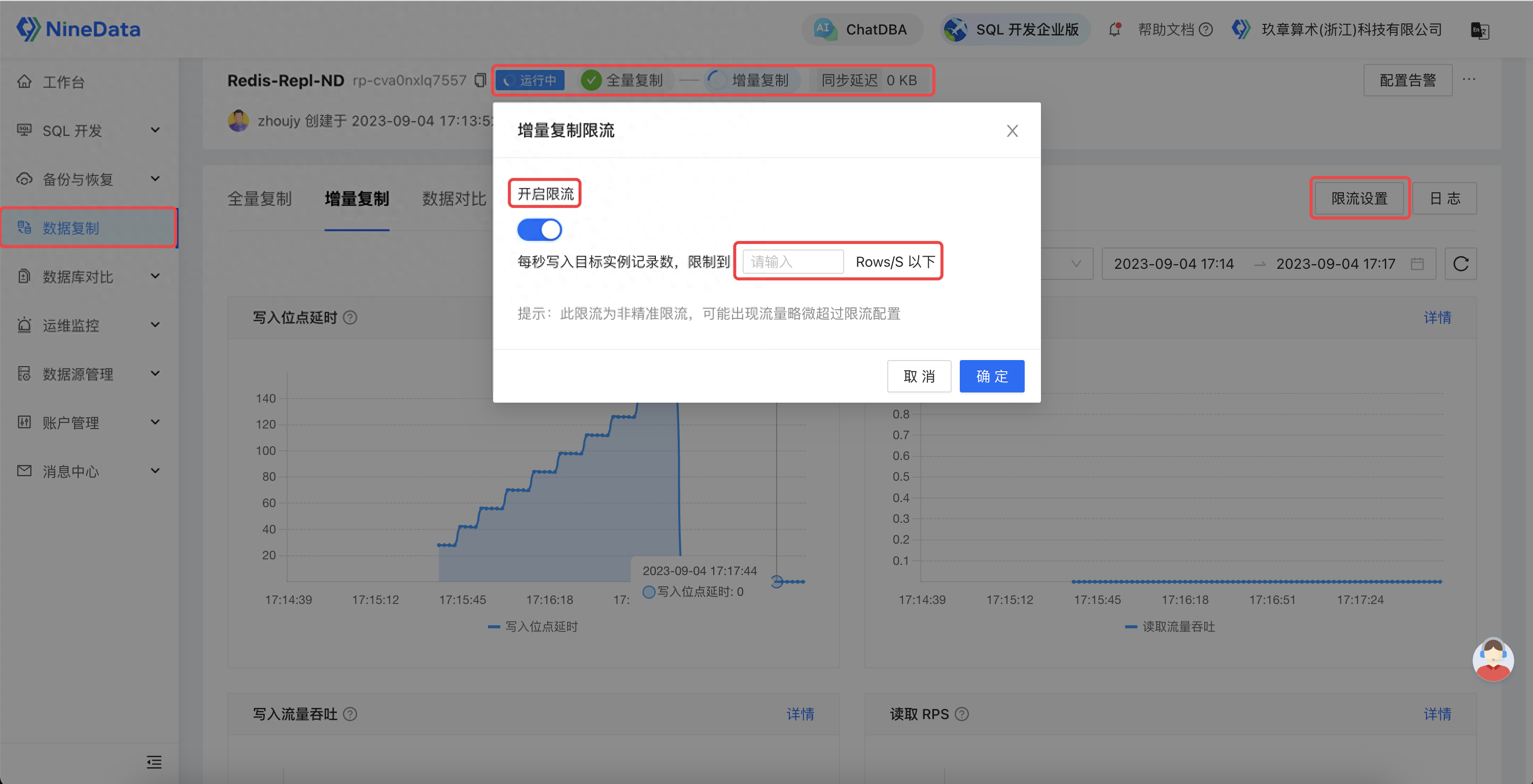 NineData提供基础诊断和迁移限流能力
NineData提供基础诊断和迁移限流能力
4、总结
NineData 基于全量复制、增量日志复制技术,提供了高效、安全可靠的 Redis 不停机迁移方案。当然,除了 Redis,NineData 已经支持数十种常见数据库的迁移复制,实现数据库迁移、数据容灾、数据双活、数据仓库实时集成等业务场景。同时,除了 SAAS 模式外,还提供了企业专属集群模式,满足企业最高的数据安全合规要求。目前,NineData 已在运营商、金融、制造业、地产、电商等多个行业完成大规模应用实践。如果您感兴趣的话,可以登录官网:数据迁移-迁移工具-数据传输-NineData-玖章算术,立即开始使用。
标签:NineData,Redis,配置,停机,复制,迁移,数据 From: https://www.cnblogs.com/ninedata/p/17695778.html