慢查询
基本原因
访问的数据太多
分析
- 是否检索了过多的数据。
- mysql服务器是否在分析大量超过需要的数据。
注意事项
- 尽量不用select *
- 分页查询(mysql从设计上让连接和断开连接都是很轻量级的。运行多个小查询不是大问题)
- 缓存效率高
- 减少锁竞争
查询的执行基础
查询执行路径(面试考)
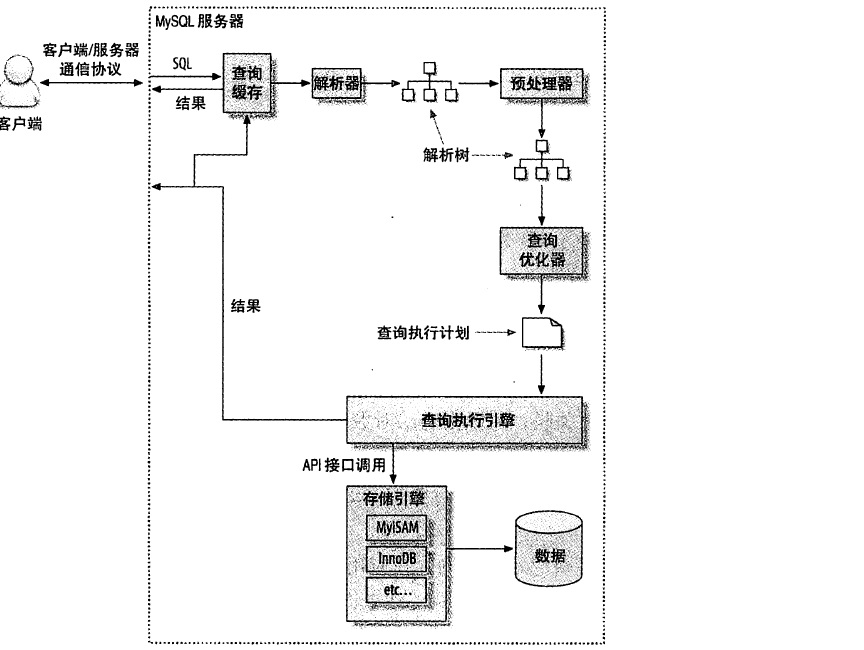
- 客户端发送一条查询给服务器
- 服务器先检查缓存,命中缓存,则返回结果。否则继续往下执行
- 服务器SQL解析、预处理
- 优化器生成执行计划
- 根据执行计划,调用存储引擎来执行查询。
- 返回客户端。
缓存
查询和缓存中的查询要一致,才能命中缓存。
返回前还需再确认一次用户权限。
解析器
判断语法规则,解析查询,判断关键字是否正确。
预处理
根据一些mysql规则,判断解析树是否合法。
优化器
由优化器将查询转为执行计划。选一个最好的执行计划进行执行。
- 关联表的顺序
- 外连接转内连接,可能
- 等价变换 5=5 and a>5 优化成 a>5
- min,max,会从b树两端取值
- 覆盖索引:当索引中的列包含查询需要使用的列,mysql直接使用索引返回需要的数据,无需返回对应的数据行
- 子查询优化
- 提前终止查询
- 等值传播
Explain
开发时优化特定的查询
与特定的版本有关
优化count查询
count()真正的作用:统计某个列值的数量;也可以统计行数。
统计行数的时候直接count(*) 比某个字段效果更好。意义也清晰。
MyISAM中,没有where条件的count(*)才快,因为有变量存。
优化关联查询
- ON或者Using列上有索引
- 索引在第二个表加。例如关联顺序是BA,则在A表加索引。
- 确保group by 和 order by 表达式值涉及到一个表中的列,这样才可能用索引。
优化子查询
尽可能使用关联查询代替。
优化GROUP BY 和 DISTINCT
group by 不能用索引时, 采用临时表 或者 文件排序做分组。
优化Limit分页(面试时考了N次)
limit在偏移量非常大的时候, limit 1000,20 这时查询1020条数据,返回最后的20条。
前面1000条被抛弃。这样代价很高。
优化方法是:
1.尽可能地只用索引覆盖,而不是查询所有列。然后根据需求做一次关联操作,返回需要的列。
例如
select film_id, description FROM sakila.film ORDER BY title LIMIT 50,5。 -- 可以改成 select film.film_id, film.description from sakila.film inner join ( select film_id FROM sakila.film ORDER BY title LIMIT 50,5。 )as lim using(film_id);
2.将limit查询转换为已知位置的查询,让Mysql是通过范围查询获得到对应的结果。
where position BETWEEN 50 and 54 ORDER BY position;
3.加区间
比如主键查询16049到16030的记录。
可以查询where id > 16030 .
这样无论多少页,性能都会很好。
《高性能Mysql》
标签:缓存,查询,索引,Mysql,优化,id,film From: https://www.cnblogs.com/jiangym/p/17596603.html