Redis(九)五种数据类型的底层结构
1 string
string是redis中最常见的数据类型
-
基本编码方式是
RAW,基于简单动态字符串(SDS)实现,存储上限为512MB,此时的object head和SDS是两个独立的空间,是通过redisObject的buf指针指向的实际存储的SDS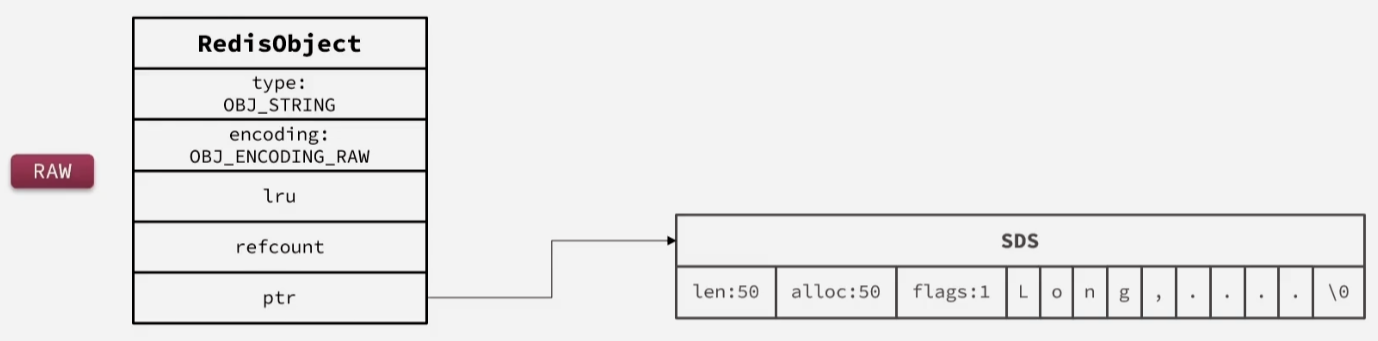
-
如果存储的SDS长度小于44字节,则采用
EMBSTR编码,此时的object head和SDS是一段连续的内存空间,申请空间的时候只需要申请一次内存分配,效率更高。超过44字节,否则会自动变为RAW编码为什么采用小于44字节使用EMB编码?
因为object head总共占用20字节,加上44字节后是64字节,正好是redis内存分配的一个分片大小,这样不容易造成内存碎片,因此使用string的时候,尽量不要超过44字节,否则会自动变为RAW编码

-
INT编码则是将数字转化为二进制直接存储到redisObject的ptr指针部分,占用8字节
2 list
-
在3.2版本之前,redis采用
ZipList和LinkedList来实现的List,当元素个数小于512并且元素大小小于64字节的时候就采用ZiplList编码,超过则采用LinkedList编码 -
在3.2版本之后,redis统一采用
QuickList来实现list,实现原理:- 首先针对list的key和value各建立一个RedisObject,value的RedisObject包含:
type类型为listencoding编码为QuickListlru:最近一次使用时间refcount:引用计数ptr:指向实际存储的QuickList空间
- 然后QuickList的节点通过前后指针连接成双向链表,每个QuickList节点的
zip指针指向存放真实数据的压缩链表
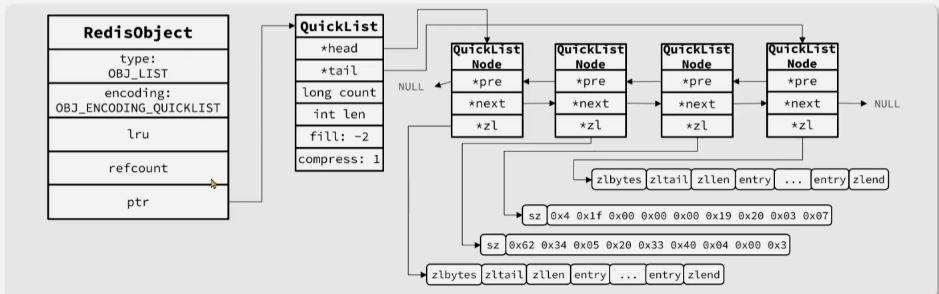
- 首先针对list的key和value各建立一个RedisObject,value的RedisObject包含:
1 为什么redis的list底层采用quickList?
-
为了满足redis的list类型数据可以从首尾操作列表元素的特性,
-
如果采用LinkedList普通链表,可以实现两端访问,但是由于非连续空间需要指针,所以内存占用较高、内存碎片也比较多
-
如果采用ZipList压缩链表,可以实现两端访问并且内存占用较低,但是存储的上限也比较低
-
因此采用QuickList即LinkedList+ZipList的方式,LinkedList的底层节点为一个个的ZipList,既可以实现双端访问,而且内存占用较低,同时包含多个ZIpList存储上限也比较高
3 set
-
set是redis的集合,不保证有序性、但能够保证元素唯一并能够求差集、交集、并集的特性,并且要求查询效率要高
-
当存储的所有数据都是整数,并且元素的个数不超过set-max-intset-entries的时候,set就会采用
INT编码,以节省内存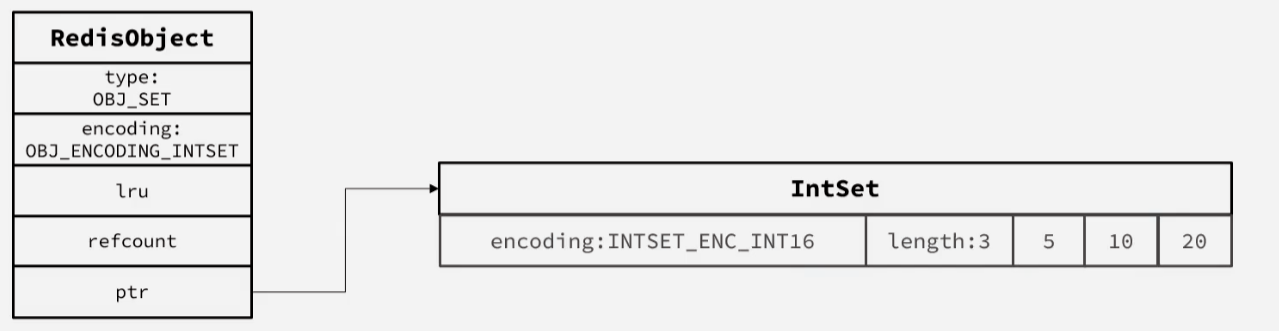
-
当插入一个字符串或者元素个数过多的时候,set就会转化编码为
HASHTABLE,使用Hash Table的key来存储元素,value统一设置为空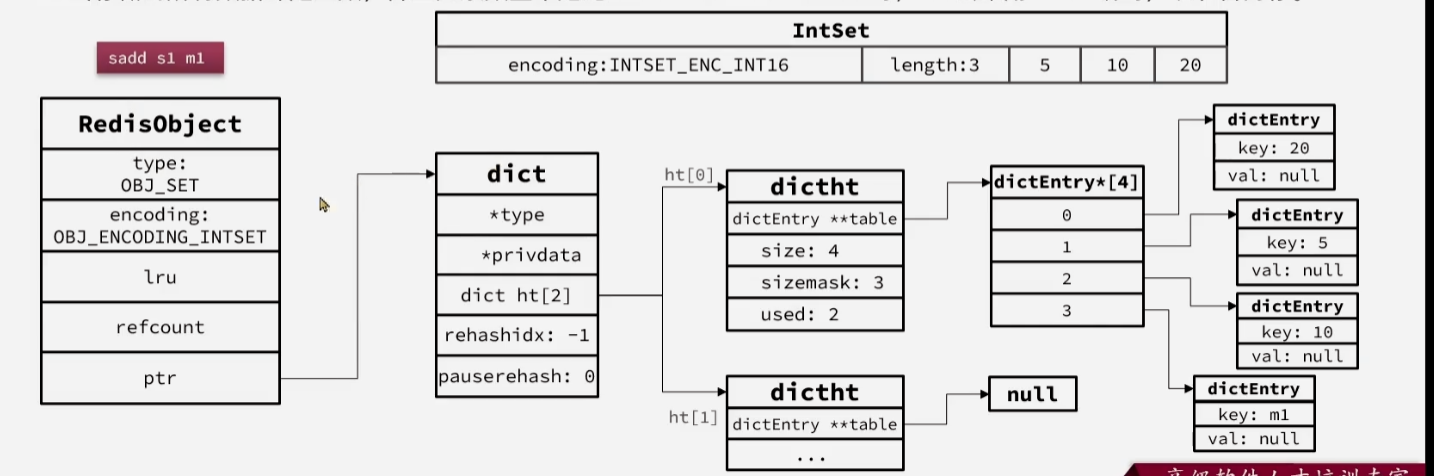
1 为什么redis的set选择哈希表作为存储结构
-
针对set集合不保证有序性、但能够保证元素唯一并能够求差集、交集、并集的特性,并且要求查询效率要高
-
如果采用跳表,跳表需要根据score得分进行排序和快速查找,不满足set集合无序的特点,浪费性能
-
因此采用Hash Table的编码,使用Hash Table的key来存储元素,value统一设置为空
4 Zset
-
Zset也就是SortedSet,每个元素都需要保存一个score值和一个member值,member必须唯一,可以根据score值进行排序,也可以根据member查询score
-
Zset底层编码可以采用
ZipList或者HashTable+SkipList组合的方式 -
当元素个数不多的时候,
HashTable+SkipList的组合发挥不出性能优势但是内存占用较多,因此采用ZipList编码:(个数的界限是:元素数量小于zset_max_ziplist_sntries,默认128且每个元素大小小于zset_max_ziplist_value,默认64字节)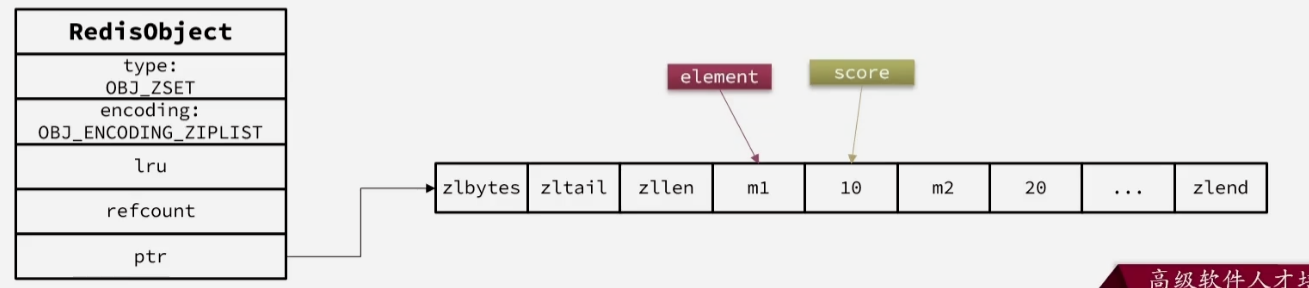
- 由于
ZipList本身既没有键值对,也没有排序的功能,因此需要通过编码实现:- ZipLIst是连续的内存,因此可以让element和score占用两个连续的entry实现键值对的存储
- 通过编码实现排序,每次插入的时候score越小就放到队首,越大就放到队尾
- 查询也是通过遍历的方式
- 因为存储元素数量很少,因此时间消耗不会太多但是内存占用远小于
HashTable+SkipList的组合
- 由于
-
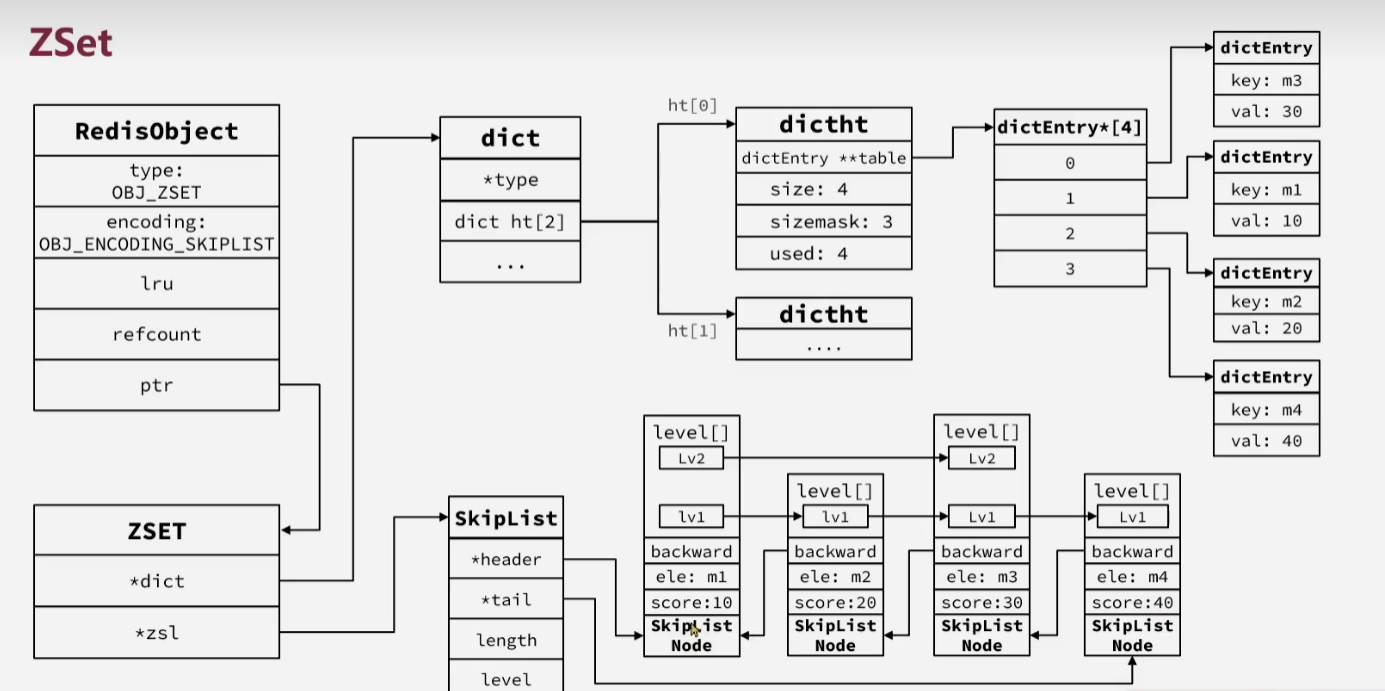
而当元素个数很多的时候,则采用
HashTable+SkipList的组合:- HashTable可以存储键值对,并且能够保证key唯一、实现通过key快速查找value(score),而SkipList能够同时存储element和score(key、value对应element和score),并实现根据score的排序和范围查询
- 而在更新的时候,只需要先通过查询HashTable是否存在key,然后依次更新HashTable和SkipList即可
1 Zset底层结构选取分析
-
为了满足Zset每个元素都需要保存一个score值和一个member值,member必须唯一,可以根据score值进行排序,也可以根据member查询score的特性
-
底层的数据结构中,HashTable能够实现键值对的存储,并且能够保证key唯一、实现通过key快速查找value(score),但是是无序的,不能够对score进行排序
-
SkipList则可以根据score进行排序和范围查询,但是本身不能保证key唯一
-
因此采用
HashTable+SkipList的组合
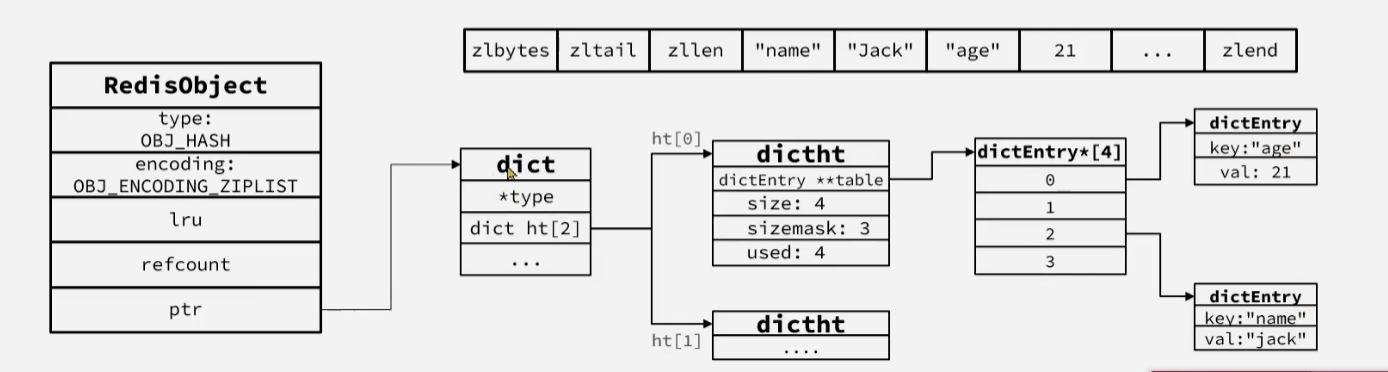
5 Hash
-
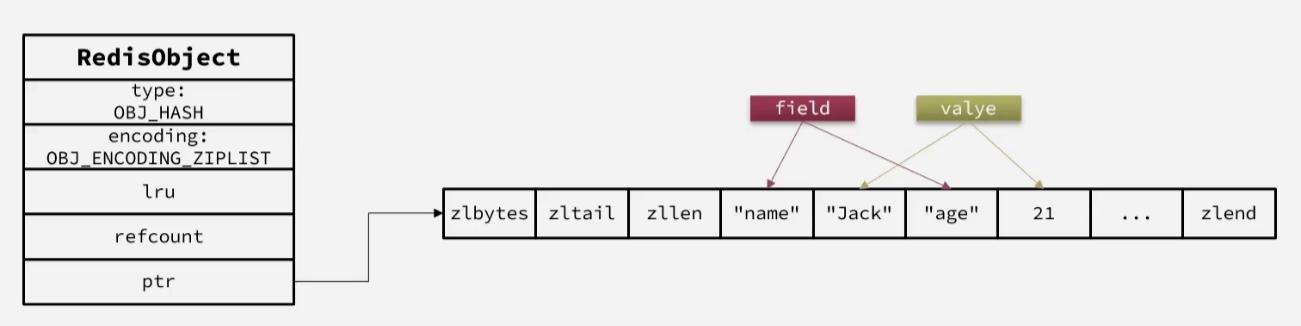
Hash的底层编码和Zset类似,只是去掉了用于score排序的
SkipList,采用的是ZipList或者HashTable编码 -
当数据量较小的时候,采用ZipList编码节省内存,ZipList中两个entry分别保存field和value
数据量大小的判断是:
① 元素数量超过hash_max_ziplist-entries,默认512
② 元素大小超过hash_max_ziplist-value,默认64字节
-
当数据量较大的时候,Hash就转化为了HashTable编码,也就是Dict