数据库对象
表
临时表
CREATE GLOBAL TEMPORARY TABLE tab_name
(......
)
ON COMMIT PRESERVE ROWS/ON COMMIT DELETE ROWS;
CREATE GLOBAL TEMPORARY TABLE XX.tab_name ON COMMIT DELETE ROWS/ON COMMIT PRESERVE ROWS AS
SELECT *
FROM tab_name
WHERE rownum < 1;
实体表
-- 修改表名
alter table a rename to b;
-- 修改说明
comment on table CGL.CUX_FA_ACCT_PRE_IMP is '资产费用账户中间表';
-- 权限赋予/撤回
grant select, insert, update, delete ON CUX.CUX_PUB_SELECTED_TMP TO apps;
REVOKE SELECT ON CUX.CUX_PUB_SELECTED_TMP FROM APPS;
列
-- 增加
alter table emp4 add test varchar2(10);
R12.2之后,新增列后需运行:
BEGIN
ad_zd_table.upgrade('CUX', 'CUX_WIP_REQ_DISTRIBUTIONS');
END;
-- 修改列类型、非空
alter table emp4 modify test varchar2(20);
-- 删除
alter table emp4 drop column test;
-- 重命名
alter table emp4 rename column a to b;
-- 添加备注
comment on column CGL.CUX_FA_ACCT_PRE_IMP.IMP_ID is '表ID,主键,供其他表做外键';
索引
-- 普通索引
Create [unique] Index CUX.CUX_TM_SHIPMENT_MAPPINGS_N1 On CUX.CUX_TM_SHIPMENT_MAPPINGS(ORG_ID,DELIVERY_NUM) [TABLESPACE APPS_TS_CUX_IDX];
-- 主键
ALTER TABLE CUX.CUX_WIP_NEW_COMP_TMP
ADD CONSTRAINT CUX_WIP_NEW_COMP_TMP_PK PRIMARY KEY (temp_id)
[USING INDEX TABLESPACE <APPS_TS_CUX_IDX>];
-- or
Create table cux.cux..
(ID NUMBER,
..
CONSTRAINT TB_PK_EXAMPLE_PK PRIMARY KEY(ID) [USING INDEX TABLESPACE <tablespace name>]);
-- 指定值不纳入索引
create index gl.cux_gl_code_combinations_n2 on gl.gl_code_combinations(segment1, segment3, decode(summary_flag, 'N', 'N'));
-- 压缩索引(节省空间,降低IO时间,提高CPU时间)
create index gl.cux_gl_code_combinations_n2 on gl.gl_code_combinations(segment1, segment3, decode(summary_flag, 'N', 'N')) compress 2; -- 2表示压缩两个字段
-- 修改表空间
alter index CUX.CUX_GL_CV_RULE_HEADER_PK rebuild tablespace apps_ts_cux_idx;
-- 删除
DROP Index CUX.CUX_TM_SHIPMENT_MAPPINGS_N1;
alter table HX_AUTH_LOGIN_INFO drop constraint HX_AUTH_LOGIN_INFOPK;
表分析
BEGIN
EXECUTE IMMEDIATE 'analyze table CUX.CUX_ASCP_BOM_ITEM_TEMP estimate statistics sample 100 percent';
--dbms_stats.gather_table_stats('CUX', 'CUX_ASCP_BOM_ITEM_TEMP', cascade => TRUE);
END;
数据闪回
CREATE TABLE cux.cux_xm_auxiliary_contrasts_124 AS
SELECT *
FROM cux.cux_xm_auxiliary_contrasts
AS OF TIMESTAMP to_timestamp('2017-12-04 09:40:00', 'YYYY-MM-DD HH24:MI:SS');
INSERT INTO applsys.fnd_flex_values_tl
SELECT *
FROM applsys.fnd_flex_values_tl AS OF TIMESTAMP SYSDATE - 10 / 24 / 60 -- to_timestamp('2020-03-13 11:25:00', 'YYYY-MM-DD HH24:MI:SS')
WHERE EXISTS (SELECT 1
FROM applsys.fnd_flex_value_sets ffvs
,applsys.fnd_flex_values ffvv
WHERE ffvv.flex_value_set_id = ffvs.flex_value_set_id
AND ffvs.flex_value_set_name = 'XY_COA_PROJ'
AND applsys.fnd_flex_values_tl.flex_value_id =
ffvv.flex_value_id);
物化视图
创建
-- 创建语句规范:
CREATE MATERIALIZED VIEW [view_name]
[ ON PREBUILT TABLE [ { WITH | WITHOUT } REDUCED PRECISION ]
[BUILD { IMMEDIATE | DEFERRED }] ]
[REFRESH [FAST|COMPLETE|FORCE] ]
[ON COMMIT|DEMAND]
[START WITH (start_time) NEXT (next_time) ]
[WITH {PRIMARY KEY | ROWID}]
[ { DISABLE | ENABLE } QUERY REWRITE]
AS subquery
/*
物化视图也是种视图。Oracle的物化视图是包括一个查询结果的数据库对像,它是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。物化视图存储基于远程表的数据,也可以称为快照。
物化视图可以查询表,视图和其它的物化视图。
特点:
(1) 物化视图在某种意义上说就是一个物理表(而且不仅仅是一个物理表),这通过其可以被user_tables查询出来,而得到确认;
(2) 物化视图也是一种段(segment),所以其有自己的物理存储属性;
(3) 物化视图会占用数据库磁盘空间,这点从user_segment的查询结果,可以得到佐证;
创建语句:create materialized view mv_name as select * from table_name
因为物化视图由于是物理真实存在的,故可以创建索引。
ON PREBUILT TABLE
是否使用预建表,即与物化视图的同一schema下,如果有同名的表,可以直接使用它,而不再自动创建表。
此时子查询的列名及数量,与预建表必须一致
WITH/WITHOUT REDUCED PRECISION
使用预建表后,对于字段的精度是否有一致的要求。若使用WITH,则为精确匹配,若为WITHOUT,则精度可不一样,如VARCHAR2(10)与VARCHAR2(20)
创建时生成数据:
分为两种:build immediate 和 build deferred,
build immediate是在创建物化视图的时候就生成数据。
build deferred则在创建时不生成数据,以后根据需要在生成数据。
默认: build immediate。
刷新模式:
有二种刷新模式:on demand/on commit。
on demand 顾名思义,仅在该物化视图“需要”被刷新了,才进行刷新,即更新物化视图,以保证和基表数据的一致性;
on commit 提交触发,一旦基表有了commit,即事务提交,则立刻刷新,立刻更新物化视图,使得数据和基表一致。一般用这种方法在操作基表时速度会比较慢。
默认: on demand
刷新方法:
完全刷新(COMPLETE):会删除表中所有的记录(如果是单表刷新,可能会采用TRUNCATE的方式),然后根据物化视图中查询语句的定义重新生成物化视图。
快速刷新(FAST):采用增量刷新的机制,只将自上次刷新以后对基表进行的所有操作刷新到物化视图中去。FAST必须创建基于主表的视图日志。对于增量刷新选项,如果在子查询中存在分析函数,则物化视图不起作用。
FORCE方式:Oracle会自动判断是否满足快速刷新的条件,如果满足则进行快速刷新,否则进行完全刷新。
默认: FORCE
关于快速刷新:Oracle物化视图的快速刷新机制是通过物化视图日志完成的。Oracle通过一个物化视图日志还可以支持多个物化视图的快速刷新。物化视图日志根据不同物化视图的快速刷新的需要,可以建立为ROWID或PRIMARY KEY类型的。还可以选择是否包括SEQUENCE、INCLUDING NEW VALUES以及指定列的列表。
查询重写(QueryRewrite):
包括 enable query rewrite 和 disable query rewrite 两种。
分别指出创建的物化视图是否支持查询重写。查询重写是指当对物化视图的基表进行查询时,oracle会自动判断能否通过查询物化视图来得到结果,如果可以,则避免了聚集或连接操作,而直接从已经计算好的物化视图中读取数据。
默认为disable query rewrite。
*/
-- 创建物化视图需要的权限:
grant create materialized view to user_name;
-- 在目标数据库上创建MATERIALIZED VIEW:
create materialized view mv_materialized_test
refresh force
on demand
start with sysdate next sysdate + 1 as
select * from user_info; --这个物化视图每天刷新
-- 修改刷新时间:
alter materialized view mv_materialized_test
refresh force
on demand
start with sysdate next trunc(sysdate) + 25/24; -- 每天1点刷新
-- 建立索引:
create index IDX_MMT_IU_TEST
on mv_materialized_test(ID,UNAME)
[tablespace test_space];
-- 删除物化视图:
drop materialized view CUX_GL_MERGE_PROFITS_MV; --删除物化视图
-- 来自 <https://blog.csdn.net/qq_26941173/article/details/78529041>
常用查询
-- 1. 查看物化视图
SELECT *
FROM all_mviews amv
WHERE amv.mview_name LIKE upper('CUX%');
-- 2. 查看物化视图对应的刷新job
SELECT *
FROM user_jobs
WHERE what LIKE '%CUX_GL_MERGE_PROFITS_MV%';
-- 3. 查看物化视图上次刷新时长(单位:s)
SELECT dma.*
FROM dba_mview_analysis dma
WHERE dma.mview_name = 'CUX_GL_MERGE_PROFITS_MV';
-- FULLREFRESHTIM 为完全刷新时间
-- INCREFRESHTIM 为快速刷新时间
-- 4. 手动触发视图刷新
dbms_mview.refresh('APPS.CUX_GL_MERGE_PROFITS_MV', '?');
-- ? : 自动判断刷新模式
-- F : 快速刷新
-- C : 完全刷新
视图日志
语法
-- 创建
CREATE MATERIALIZED VIEW LOG
ON [schema.]table
[ {physical_attributes_clause
| TABLESPACE <tablespace>
| { LOGGING | NOLOGGING }
| { CACHE | NOCACHE }}
...
]
[ { NOPARALLEL | PARALLEL [ integer ] } ]
[ table_partitioning_clauses ]
[ WITH { OBJECT ID
| PRIMARY KEY
| ROWID
| SEQUENCE
| (column [, column ]...)
}...
[ { INCLUDING | EXCLUDING } NEW VALUES ]
] ;
physical_attributes_clause::=
[ { PCTFREE integer
| PCTUSED integer
| INITRANS integer
| storage_clause
}...
]
/*
物化视图日志就是表,名称为MLOG$_<基表名称>,如果表名的长度超过20位,则只取前20位,当截短后出现名称重复时,Oracle会自动在物化视图日志名称后面加上数字作为序号。
任何物化视图都会包括的4列:
SNAPTIME$$:用于表示刷新时间。
DMLTYPE$$:用于表示DML操作类型,I表示INSERT,D表示DELETE,U表示UPDATE。
OLD_NEW$$:用于表示这个值是新值还是旧值。N(EW)表示新值,O(LD)表示旧值,U表示UPDATE操作。
CHANGE_VECTOR$$:表示修改矢量,用来表示被修改的是哪个或哪几个字段。
XID$$:事务ID,11.2开始使用. For the curious, the number is a combination of the elements of the triplet (undo segment number, undo slot, undo sequence); it is simply the binary concatenation of the three numbers shifted by (48, 32, 0) bits respectively (as checked in the script).
The xid$$ column is used by the 11gR2 on-commit fast refresh engine, which can now easily retrieve the changes made by the just-committed transaction by its xid; at the opposite, the on-demand fast refresh one keeps using snaptime$$ as it did in previous versions. I will speak about this in more detail in an upcoming post.
如果WITH后面跟了ROWID,则日志会包含列:M_ROW$$:用来存储发生变化的记录的ROWID。
如果WITH后面跟了PRIMARY KEY,则日志会包含主键列。
如果WITH后面跟了OBJECT ID,则日志会包含列:SYS_NC_OID$:用来记录每个变化对象的对象ID。
如果WITH后面跟了SEQUENCE,则日志会包含列:SEQUENCE$$:给每个操作一个序列号,从而保证刷新时按照顺序进行刷新。
如果WITH后面跟了一个或多个COLUMN名称,则物化视图日志中会包含这些列。
{ INCLUDING | EXCLUDING } NEW VALUES
控制在物化视图日志中是否记录更新语句变化前后的值
*/
-- 删除
drop materialized view log on CUX.CUX_GL_COMBINE_HEADERS; --删除物化视图日志:
示例
-
创建物化视图日志
CREATE MATERIALIZED VIEW LOG ON CUX.CUX_GL_COMBINE_HEADERS PCTFREE 5 PCTUSED 60 INITRANS 2 TABLESPACE CUXX NOLOGGING NOCACHE PARALLEL 2 WITH ROWID,SEQUENCE(header_id, combine_name ) EXCLUDING NEW VALUES; -
创建快速刷新物化视图
CREATE MATERIALIZED VIEW CUX.CUX_GL_COMBINE_HEADERS_MV BUILD DEFERRED REFRESH FAST ON DEMAND WITH ROWID AS select * from CUX.CUX_GL_COMBINE_HEADERS;再创建一个同样定义,不同名的物化视图CUX.CUX_GL_COMBINE_HEADERS_MV1
手动全量刷新视图
-
对基表新增数据,查询日志:

SNAPTIME$$: 默认时间为4000-01-01 -
刷新物化视图CUX_GL_COMBINE_HEADERS_MV,查询日志及视图:
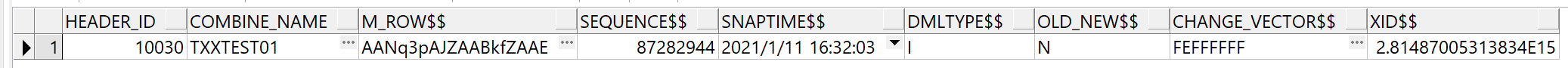
时间变了,为视图刷新时间。
视图中也有了该笔数据:
再刷新视图CUX_GL_COMBINE_HEADERS_MV1,日志中的数据就被删掉了,因为基于该日志的所有物化视图已刷新。
-
如果使用excluding new values时,则物化视图不支持单表使用聚合函数:
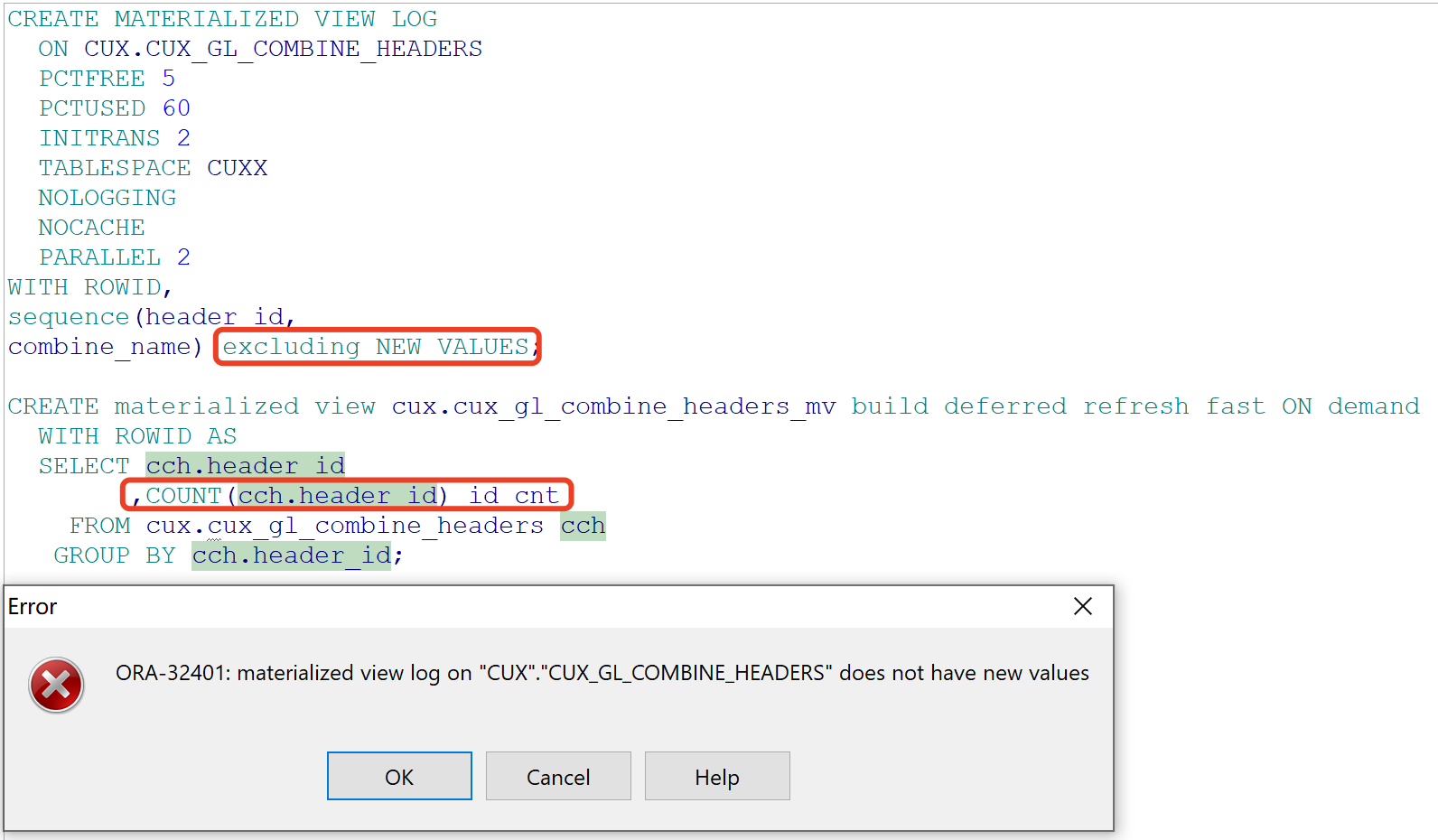
利弊
-
利处显而易见,相对于全量刷新,视图日志可以帮助加快物化视图的刷新速度
-
弊端
-
占用额外的物理空间
-
影响基表的DML性能
下面给一份1W条数据DML时,各场景时间日志大小/处理时间(s) 无视图日志 有视图日志 有同步快速更新视图 插入 1M/0.21 10M/3.73 20M/8.98 更新 4M/0.5 10M/3.88 25M/8.75 删除 1M/0.13 15M/6.94 40M/18.52
-
程序包
权限
-- 执行权限赋予
grant execute on apps.cux_xm_transactions_send_utl to appsquery;
/*
使用pragma restrict_references限制包权限
在看别人的代码的时候,发现了如下的编译指令,
pragma restrict_references(get_attribute_name, wnds);
get_attribute_name是一个pl/sql function, 当我试图在这个函数中往一个log表里面插入log信息的时候,编译都通不过,给出如下信息,
Error(2252,1): PLS-00452: Subprogram 'GET_AMOUNT_NAME' violates its associated pragma
看来就是上面这个pragma搞得鬼。 查了下Oracle 文档, (http://download.oracle.com/docs/cd/B28359_01/appdev.111/b28370/restrictreferences_pragma.htm#LNPLS01339)
才知道这个pragma的作用是保证上面的那个function,不会改变数据库的状态 wnds (Write No Database State), 而我却在这个函数的内部进行了写表操作,难怪编译出错。*/
/*
RESTRICT_REFERENCES pragma的用法如下:
PRAGMA RESTRICT_REFERENCES (subprogram_name, [RNDS, WNDS, RNPS, WNPS, TRUST])
关键字和参数描述:
PRAGMA: 表示这是一个编译指令,在编译的时候执行
subprogram_name: PL/SQL 函数的名字
RNDS: (Read No Database State) 表示该subprogram不会查询(query)数据库中的表。
WNDS: (Write No Database State) 表示该subprogram不会改变数据库中的表的数据。
RNPS: (Read No Package State) 不访问包中的变量
WNPS:(Write No Package State) 不改变包中的变量值
TRUST: 表示信任该subprogram不会违反前面的任何约束,一般用在PL/SQL调用外部函数,比如java代码。
需要注意的是, RESTRICT_REFERENCES pragma只能出现在package specification 或者 object type specification.
下面是一个简单的例子:*/
CREATE PACKAGE loans AS
FUNCTION credit_ok RETURN BOOLEAN;
PRAGMA RESTRICT_REFERENCES (credit_ok, WNDS, RNPS);
END loans;
-- 来自 <https://blog.csdn.net/sunansheng/article/details/46330677>
编译卡住
-- 遇见的情况为取消请求,其进程未关闭,占住了PACKAGE,其后PACKAGE BODY失效,导致其他引用此包的程序卡住,最终报红
-- 1. 查看库缓存(Library cache)
SELECT *
FROM v$access vac
WHERE vac.owner = 'APPS'
AND vac.object = 'DFSCN_ARX_WEBADI_PKG';
-- 2. 查看加锁进程及类型
SELECT vp.spid,
vs.sid,
vs.serial#,
vs.client_identifier,
vs.status,
vs.logon_time,
vs.username,
vs.action,
vs.module,
vs.osuser,
vs.terminal,
vs.program,
dlk.*
FROM dba_ddl_locks dlk,
v$session vs,
v$process vp
WHERE vs.sid = dlk.session_id
--
AND vp.addr = vs.paddr
--
AND dlk.owner = 'APPS'
AND dlk.name = 'DFSCN_ARX_WEBADI_PKG';
-- 杀掉此进程,即可正常编译程序包(如需清掉状态为KILLED的进程,可用ssh, 命令 kill spid)
编译报错
使用pl/sql developer编译时总是报 Ora-03114:未连接数据库
设置PLSQL DEV,取消勾选编译debug:
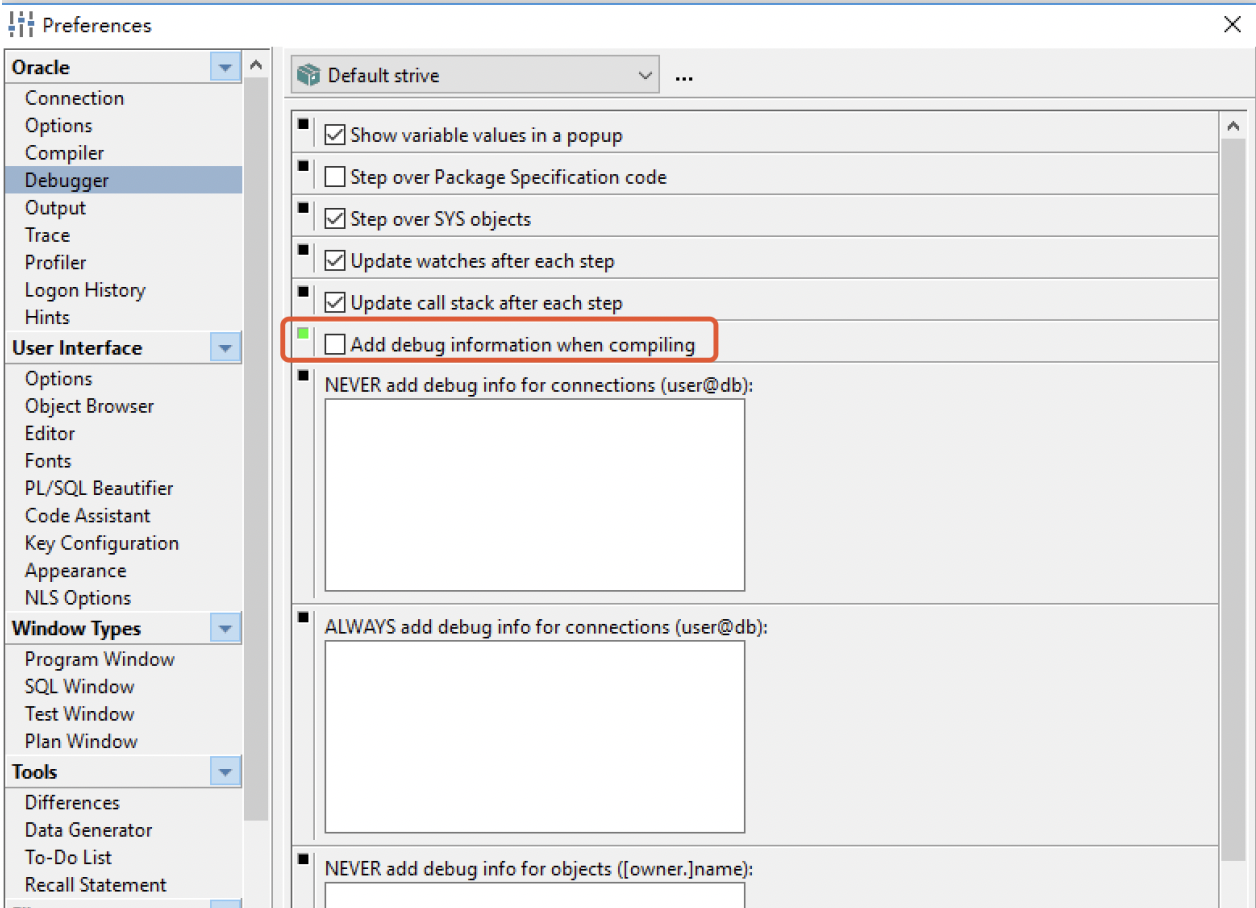
DBLINK
-- 创建
create database link UAT_TEST connect to apps identified by apps
using '(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 172.16.254.51)(PORT = 1531))
)
(CONNECT_DATA =
(SERVICE_NAME =TEST)
)
)';
-- 查看
SELECT owner, object_name FROM dba_objects WHERE object_type = 'DATABASE LINK';
SELECT * FROM dba_db_links;
-- 删除
DROP DATABASE LINK [name]; (DROP DATABASE LINK LCT_MID;)
--或
DROP PUBLIC DATABASE LINK [name]
Trigger
-- 禁用触发器
alter trigger ARP_GL_INTERFACE_ORG disable;
-- 启用触发器
alter trigger CASCADE_DELETE enable;
/*
1. 说明:
禁用并重新启用触发器
可使用 ALTER TABLE 的 DISABLE TRIGGER 选项来禁用触发器,以使正常情况下会违反触发器条件的插入操作得以执行.
然后下例使用 ENABLE TRIGGER 重新启用触发器.
2. 语法:
禁用触发器:ALTER TABLE table_name DISABLE TRIGGER trigger_name启用触发器:ALTER TABLE table_name ENABLE TRIGGER trigger_name
3. 举列说明:*/
-- (1).建表
create table d_ware_q
( id INT,
name VARCHAR(20),
shl int)
-- (2).创建触发器
CREATE [OR REPLACE] TRIGGER trigger_name
{BEFORE | AFTER }
{INSERT | DELETE | UPDATE [OF column [, column …]]}
[OR {INSERT | DELETE | UPDATE [OF column [, column …]]}...]
ON [schema.]table_name | [schema.]view_name
[REFERENCING {OLD [AS] old | NEW [AS] new| PARENT as parent}]
[FOR EACH ROW ]
[WHEN condition]
PL/SQL_BLOCK | CALL procedure_name;
CREATE TRIGGER tr_d_ware_q ON d_ware_q FOR INSERT
as
IF (SELECT COUNT(*) FROM INSERTED WHERE shl> 100) > 0
BEGIN
print '错误提示: 您插入了一个大于 100'
ROLLBACK TRANSACTION
END;
-- (3).禁用触发器测试
alter trigger cux.CUX_PUB_MQ_CONSUMER_IFCE_TRG disable;
ALTER TABLE d_ware_q DISABLE TRIGGER tr_d_ware_q
--插入
insert into d_ware_q values (1,'苹果',101)
--查询
select * from d_ware_q; -- 可以查出
-- (4).启用触发器测试
ALTER TABLE d_ware_q ENABLE TRIGGER tr_d_ware_q
--插入
insert into d_ware_q values (1,'香蕉',102) -- 报错
零散技点
初始化
BEGIN
fnd_global.apps_initialize(1550, 50757, 20023); -- USER_ID/RESP_ID/RESP_APPL_ID
mo_global.init('M'); -- mo_global.init('PO');
-- mo_global.set_policy_context_server('S', 84);
END;
日期
设定会话格式
ALTER SESSION SET NLS_DATE_FORMAT = 'YYYY-MM-DD';
获取第一及最后一天
SELECT last_day(trunc(SYSDATE)) lst_day
,trunc(SYSDATE, 'mm') fst_day
FROM dual;
用户
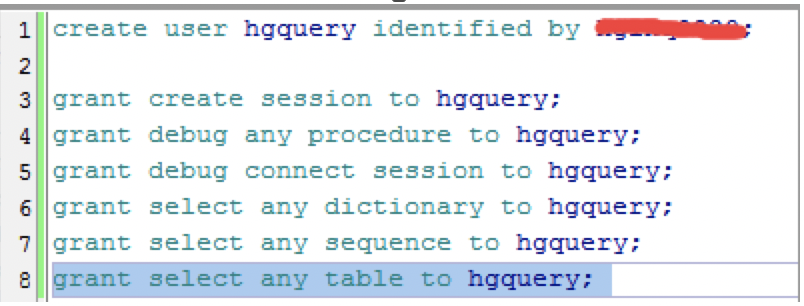
取消请求
UPDATE fnd_concurrent_requests
SET status_code = 'X'
,phase_code = 'C'
WHERE request_id =;
UPDATE fnd_concurrent_requests fcr
SET status_code = 'X',
phase_code = 'C'
WHERE 1 = 1 --request_id = 20309195
AND fcr.phase_code = 'R'
AND fcr.status_code = 'R'
AND fcr.oracle_session_id IS NULL;
COMMIT;
获取功能所属菜单
SELECT m.menu_name
,f.function_name
FROM fnd_menus_vl m
,fnd_menu_entries_vl e
,fnd_form_functions_vl f
WHERE m.menu_id = e.menu_id
AND e.function_id = f.function_id
AND f.function_name = '名称';
MOAC
-- VPD 测试
-- 1. 创建测试数据表
create table cux.cux_vpd_test
(p_employee_number NUMBER,
p_employee_name VARCHAR2(30),
p_age NUMBER);
create synonym apps.cux_vpd_test for cux.cux_vpd_test;
-- 2. 数据插入
INSERT INTO cux.cux_vpd_test VALUES(1, 'TEST01', 1);
INSERT INTO cux.cux_vpd_test VALUES(2, 'TEST01', 2);
INSERT INTO cux.cux_vpd_test VALUES(3, 'TEST01', 3);
-- COMMIT;
SELECT * FROM cux_vpd_test t;
-- 3. 策略函数创建
CREATE OR REPLACE FUNCTION cux_vpd_test_func(p_schema VARCHAR2, p_object VARCHAR2) RETURN VARCHAR2 IS
vc_user VARCHAR2(30);
BEGIN
BEGIN
SELECT sys_context('USERENV', 'SESSION_USER') INTO vc_user FROM dual;
EXCEPTION
WHEN OTHERS THEN
RETURN ' P_EMPLOYEE_NUMBER <= 2 ';
END;
IF TRIM(vc_user) = 'CUX' THEN
RETURN ' 1 = 1 ';
ELSE
RETURN ' P_EMPLOYEE_NUMBER <= 2 ';
END IF;
END;
-- 4. 注册策略函数
BEGIN
dbms_rls.add_policy(object_schema => 'CUX',
object_name => 'CUX_VPD_TEST',
policy_name => 'CUX_VPD_TEST_ALL',
function_schema => 'APPS',
policy_function => 'CUX_VPD_TEST_FUNC',
sec_relevant_cols => 'P_EMPLOYEE_NUMBER',
sec_relevant_cols_opt => dbms_rls.all_rows);
END;
-- 5. 结果校验
SELECT * FROM cux_vpd_test;
-- 6. 删除策略函数
BEGIN
dbms_rls.drop_policy(object_schema => 'CUX',
object_name => 'CUX_VPD_TEST',
policy_name => 'CUX_VPD_TEST_ALL');
END;
会话设置
-- 设置语言
ALTER SESSION SET NLS_LANGUAGE = 'SIMPLIFIED CHINESE';
ALTER SESSION SET NLS_LANGUAGE = AMERICAN;
-- 设置地域
ALTER SESSION SET NLS_TERRITORY = AMERICA;
ALTER SESSION SET NLS_TERRITORY = CHINA;
-- 设置用户
alter session set current_schema = apps;
字符集
-- plsql developer 查出中文乱码
-- 新建或修改环境变量 NLS_LANG,值为:
select * from nls_database_parameters;
-- 查看当前客户端语言环境
select userenv('language') from dual;
事务隔离
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
代码设计
-- 立即影响输出型参数值
PROCEDURE nocopy_parameter(p_number IN OUT NOCOPY NUMBER) IS
BEGIN
p_number := 10000;
RAISE test_exception; --抛出异常,未进行处理
END nocopy_parameter;
-- 对于更新语句,返回更新后的值
RETURNING
DELETE FROM cux_cursor_test
WHERE person_id = 101
RETURNING person_name, age
INTO l_person_name, l_age;
UPDATE cux_cursor_test
SET person_name = 'Abc.' || person_name, age = age + 1
WHERE person_id IN (101, 102)
RETURNING person_name, age
BULK COLLECT INTO l_person_tbl;
-- 调用程序时,使用的权限:程序创建者/调用者
AUTHID DEFINER(默认值为创建者)/AUTHID CURRENT_USER
CREATE OR REPLACE PACKAGE cux_authid_test2_pkg AUTHID CURRENT_USER IS
PROCEDURE insert_row;
END cux_authid_test2_pkg;
行列转换
The LISTAGG function can be used in the following versions of Oracle/PLSQL:
○ Oracle 12c, Oracle 11g Release 2
-- 来自 <https://www.techonthenet.com/oracle/functions/listagg.php
chr(0)
PLSQL中,打印字符串时,不显示CHR(0)之后的内容
程序暂停
dbms_lock.sleep(p_seconds)
清除缓存
ALTER SYSTEM FLUSH SHARED_POOL;
ALTER SYSTEM FLUSH BUFFER_CACHE;
ALTER SYSTEM FLUSH GLOBAL CONTEXT;
ORA错误
定位错误行
在10gR1及之前,只能不去截获exception, 让错误抛出,从错误信息中得到错误发生的位置
从10gR2后,我们可以利用 DBMS_UTILITY.format_error_backtrace 得到发生错误语句的代码对象及行号
ORA-01000
-- step 1: 查看数据库当前的游标数配置
show parameter open_cursors;
-- step 2: 查看游标使用情况:
select o.sid, osuser, machine, count(1) num_curs
from v$open_cursor o, v$session s
where 1 = 1
and o.sid=s.sid
group by o.sid, osuser, machine
order by num_curs desc;
-- step 3: 查看游标执行的sql情况:
select o.sid, q.sql_text
from v$open_cursor o, v$sql q
where q.hash_value = o.hash_value
and o.sid = 123;
-- step 4:
-- 排查游标数超限的程序
-- 提高游标上限(DBA权限)
sql> alter system set open_cursors=1000 scope=both;
ORA-01007
ORA-01007:变量不在选择列表中
游标所取字段数,与fetch into的字段数不一致
BUG
Bug 7306422
DOC ID 813858.1
PL/SQL - Version 11.1.0.6 to 11.1.0.7 [Release 11.1]
Information in this document applies to any platform.
Normally the statement CONTINUE immediately completes the current iteration of a loop and passes control to the next iteration of the loop.
But when it is executed in a CURSOR FOR LOOP and the initialization parameter PLSQL_OPTIMIZE_LEVEL is set to 2 (which is the default setting on 11G), it exits the loop.
Bug 7306422 NEW 11G CONTINUE STATEMENT DOES NOT WORK IN A CURSOR FOR LOOP
The bug is fixed on Oracle 11.2 or later.
Download and apply Patch 7306422 for your 11.1 version and platform.
To work around the problem you can set the initialization parameter PLSQL_OPTIMIZE_LEVEL to 0 or 1 by executing the following statement:
ALTER SESSION SET PLSQL_OPTIMIZE_LEVEL = 1;
or
ALTER SESSION SET PLSQL_OPTIMIZE_LEVEL = 0;
重新编译失效对象
查看失效对象
SELECT owner,
object_type,
object_name,
status
FROM dba_objects
WHERE status = 'INVALID'
ORDER BY owner, object_type, object_name;
手工重编译
直接alter
ALTER PACKAGE my_package COMPILE;
ALTER PACKAGE my_package COMPILE BODY;
ALTER PROCEDURE my_procedure COMPILE;
ALTER FUNCTION my_function COMPILE;
ALTER TRIGGER my_trigger COMPILE;
ALTER VIEW my_view COMPILE;
DBMS_DDL.alter_compile
(不能重新编译view)
EXEC DBMS_DDL.alter_compile('PACKAGE', 'MY_SCHEMA', 'MY_PACKAGE');
EXEC DBMS_DDL.alter_compile('PACKAGE BODY', 'MY_SCHEMA', 'MY_PACKAGE');
EXEC DBMS_DDL.alter_compile('PROCEDURE', 'MY_SCHEMA', 'MY_PROCEDURE');
EXEC DBMS_DDL.alter_compile('FUNCTION', 'MY_SCHEMA', 'MY_FUNCTION');
EXEC DBMS_DDL.alter_compile('TRIGGER', 'MY_SCHEMA', 'MY_TRIGGER');
匿名块
BEGIN
FOR cur_rec IN (SELECT owner,
object_name,
object_type,
DECODE(object_type, 'PACKAGE', 1,
'PACKAGE BODY', 2, 2) AS recompile_order
FROM dba_objects
WHERE object_type IN ('PACKAGE', 'PACKAGE BODY')
AND status != 'VALID'
ORDER BY 4)
LOOP
BEGIN
IF cur_rec.object_type = 'PACKAGE' THEN
EXECUTE IMMEDIATE 'ALTER ' || cur_rec.object_type ||
' "' || cur_rec.owner || '"."' || cur_rec.object_name || '" COMPILE';
ElSE
EXECUTE IMMEDIATE 'ALTER PACKAGE "' || cur_rec.owner ||
'"."' || cur_rec.object_name || '" COMPILE BODY';
END IF;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.put_line(cur_rec.object_type || ' : ' || cur_rec.owner ||
' : ' || cur_rec.object_name);
END;
END LOOP;
END;
UTL_RECOMP
UTL_RECOMP包中包含两个用于重新编译无效对象的过程。
RECOMP_SERIAL过程一次重新编译所有无效对象,
COMP_PARALLEL过程使用指定数量的线程并行执行相同的任务。
定义如下:
PROCEDURE RECOMP_SERIAL(
schema IN VARCHAR2 DEFAULT NULL,
flags IN PLS_INTEGER DEFAULT 0);
PROCEDURE RECOMP_PARALLEL(
threads IN PLS_INTEGER DEFAULT NULL,
schema IN VARCHAR2 DEFAULT NULL,
flags IN PLS_INTEGER DEFAULT 0);
参数的使用说明:
- schema - 要重新编译其无效对象的schema。 如果为NULL,则重新编译数据库中的所有无效对象。
- threads - 并行操作中使用的线程数。 如果为NULL,则使用“job_queue_processes”参数的值。 匹配可用CPU的数量通常是此值的良好起点。
- flags - 仅用于内部诊断和测试。
示例:
-- Schema level.
EXEC UTL_RECOMP.recomp_serial('SCOTT');
EXEC UTL_RECOMP.recomp_parallel(4, 'SCOTT');
-- Database level.
EXEC UTL_RECOMP.recomp_serial();
EXEC UTL_RECOMP.recomp_parallel(4);
-- Using job_queue_processes value.
EXEC UTL_RECOMP.recomp_parallel();
EXEC UTL_RECOMP.recomp_parallel(NULL, 'SCOTT');
使用此软件包有许多限制,包括:
- 使用作业队列执行并行执行。 在操作完成之前,所有现有作业都标记为已禁用。
- 该程序包必须作为SYS用户从SQL * Plus或具有SYSDBA的其他用户运行。
- 该程序包期望STANDARD,DBMS_STANDARD,DBMS_JOB和DBMS_RANDOM存在且有效。
在此程序包的同时运行DDL操作可能会导致死锁。
utlrp.sql/utlprp.sql
Oracle提供了utlrp.sql和utlprp.sql脚本来重新编译数据库中的所有无效对象。
它们通常在主要数据库更改(如升级或修补程序)之后运行。
位于$ORACLE_HOME/rdbms/admin目录中,并在UTL_RECOMP包中提供包装器。
utlrp.sql脚本只是使用命令行参数“0”调用utlprp.sql脚本。
utlprp.sql接受一个整数参数,该参数指示并行度,如下所示。
- 0 - 并行级别基于CPU_COUNT参数派生。
- 1 - 重新编译是串行运行的,一次一个对象。
- N - 重新编译于“N”个线程并行运行。
必须以SYS用户或具有SYSDBA的其他用户身份运行这两个脚本才能正常工作。
DBMS_UTILITY
DBMS_UTILITY包中的COMPILE_SCHEMA过程编译指定模式中的所有过程,函数,包和触发器。 下面的示例显示了如何从SQL * Plus调用它。
EXEC DBMS_UTILITY.compile_schema(schema => 'SCOTT', compile_all => false);
TKPROF
概述
trace文件为Raw Trace形式,不易读取、理解,TKPROF可以把Raw Trace转换为更易读的形式
使用
语法
$ tkprof
Usage: tkprof tracefile outputfile [explain= ] [table= ]
[print= ] [insert= ] [sys= ] [sort= ]
table=schema.tablename Use 'schema.tablename' with 'explain=' option.
explain=user/password Connect to ORACLE and issue EXPLAIN PLAN.
print=integer List only the first 'integer' SQL statements.
aggregate=yes|no
insert=filename List SQL statements and data inside INSERT statements.
sys=no TKPROF does not list SQL statements run as user SYS.
record=filename Record non-recursive statements found in the trace file.
waits=yes|no Record summary for any wait events found in the trace file.
sort=option Set of zero or more of the following sort options:
prscnt number of times parse was called
prscpu cpu time parsing
prsela elapsed time parsing
prsdsk number of disk reads during parse
prsqry number of buffers for consistent read during parse
prscu number of buffers for current read during parse
prsmis number of misses in library cache during parse
execnt number of execute was called
execpu cpu time spent executing
exeela elapsed time executing
exedsk number of disk reads during execute
exeqry number of buffers for consistent read during execute
execu number of buffers for current read during execute
exerow number of rows processed during execute
exemis number of library cache misses during execute
fchcnt number of times fetch was called
fchcpu cpu time spent fetching
fchela elapsed time fetching
fchdsk number of disk reads during fetch
fchqry number of buffers for consistent read during fetch
fchcu number of buffers for current read during fetch
fchrow number of rows fetched
userid userid of user that parsed the cursor
常用格式,按照sql的执行、获取、解析时间排序:
tkprof <src>.trc <tgt>.txt aggregate=yes sys=no waits=yes sort=exeela,fchela,prsela
tkprof PROD_ora_5964876.trc PROD_ora_5964876.txt aggregate=yes sys=yes waits=yes sort=prsela,exeela,fchela
分析
给出一个解析后的trace样例:
头部
/*
头部内容,这里可以看到trace源文件,sort参数等信息
*/
TKPROF: Release 11.2.0.3.0 - Development on Thu Aug 20 15:28:24 2020
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
Trace file: .trc
Sort options: prsela exeela fchela
********************************************************************************
count = number of times OCI procedure was executed
cpu = cpu time in seconds executing
elapsed = elapsed time in seconds executing
disk = number of physical reads of buffers from disk
query = number of buffers gotten for consistent read
current = number of buffers gotten in current mode (usually for update)
rows = number of rows processed by the fetch or execute call
********************************************************************************
执行时间
/*
头部内容下面的部分就是针对每个sql的信息:sql文本,统计信息,解析信息,执行计划,等待事件等。
*/
SQL ID: c8t07u17847mb Plan Hash: 274802493
SELECT FA.ASSET_ID, FA.TAG_NUMBER, FA.ATTRIBUTE7 BU_TAG_NUMBER,
...
/*
count: 这个语句被parse、execute、fetch的次数
cpu: 处理数据花费的cpu时间,单位是秒
elapsed:当前操作花费的总用时,包括cpu时间和等待时间,单位是秒
disk: 执行物理I/O次数,从磁盘上的数据文件中物理读取的块的数量
query: 当前阶段以consistent mode从db buffer中查询的buffer数,通常是select
current:当前阶段以current mode从db buffer中查询的buffer数,通常是insert/update/delete等
语句引起
rows: SQL语句最后处理的行数,对于select,该值产生于fetch阶段;对于dml该值产生于execute阶段
*/
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.55 0.55 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 40.99 43.95 698196 366813 0 797
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 41.55 44.51 698196 366813 0 797
/*
因统计耗费的时间时,最小的计量单位为0.01秒,所以如果得到一个阶段中耗费的时间为0,并不表示这个阶段没有耗费时间,而是极可能说明这个阶段耗费的时间小于0.01秒,小于计量单位,数据库无法计时,只能以0.00表示。
一般来说,elapsed_time = cpu_time + wait_time, 不过对于并行,可能出现cpu_time大于elapsed time的情况。
consistent mode
当查询开始的时候oracle将确立一个时间点,凡是在这个时间点以前提交的数据oracle将能看见,之后提交的数据将不能看见。但查询的时候可能遇上这样的情况,该块中数据已经被修改了,没有提交,或者提交的时间点比查询开始的时间晚,则oracle为了保证 读的一致性,需要去回滚段获取 该块中变化前的数据(before image)。这叫 consistent reads
current mode
当看到当前的block中的内容的时候,是什么就是什么,跟时间点无关,不用去回滚段获取之前的数据。
什么时候会是这样的模式? 除了9i以前版本的FTS对数据字典的获取是current mode外(这是因为关于数据字典的获取必须是当前看见的状态),主要就是发生在DML的时候。
当发生DML的时候,本会话所看见的必须是当前的block状态,不能去回滚段获取数据(否则就乱套了)。假如当前block中数据是被更改过还没有提交,那么数据被锁,其他会话更新会出现等待 (这才是正常的)。(查询去回滚段获取数据,读和更新之间不会出现锁的情况)
*/
-- 1表示shared pool没有命中,这是一次硬分析;软分析为0
Misses in library cache during parse: 1
-- 当前优化模式
Optimizer mode: ALL_ROWS
-- 解析人id,见dba_users (递归深度)
Parsing user id: 63 (recursive depth: 1)
Number of plan statistics captured: 1
执行计划
/*
rows:表示当前操作返回的数据条数
Row Source Operation:行源操作,表示当前数据的访问方式
cr: 一致性方式读取的数据块数,相当于query列上的fetch步骤的值
pr: 物理读的数据块,相当于disk列上的fetch步骤的值
pw: 物理写入磁盘的数据块数
time: 以微秒表示的总的消逝时间
cost: 操作的评估开销(from 11g)
size: 操作返回的预估数据量(字节,from 11g)
card: 操作返回的预估行数(from 11g)
注意:这些值除了card之外,都是累计的,即每一行执行计划的值,都是之前计划的累加
*/
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
...
4917432 4917432 4917432 TABLE ACCESS FULL FA_BOOKS (cr=170471 pr=170437 pw=0 time=1993114 us cost=47042 size=368865000 card=4918200)
...
-- 等待事件、等待次数、等待时长(最大/合计,单位:s)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
Disk file operations I/O 124 0.00 0.00
db file sequential read 59 0.01 0.02
direct path read 14213 0.00 0.61
asynch descriptor resize 7 0.00 0.00
direct path write temp 22349 0.08 5.76
direct path read temp 22349 0.00 0.67
db file scattered read 16 0.00 0.00
********************************************************************************
汇总部分
-- 非递归SQL汇总,表示用户的语句
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 29 0.00 0.00 0 0 0 0
Execute 33 0.36 0.36 4 25 42 20
Fetch 12 0.00 0.00 0 58 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 74 0.36 0.36 4 83 42 30
Misses in library cache during parse: 1
Misses in library cache during execute: 1
-- 等待事件汇总
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 40 0.00 0.00
SQL*Net message from client 40 0.00 0.00
Disk file operations I/O 2 0.00 0.00
db file sequential read 4 0.00 0.00
utl_file I/O 36 0.00 0.00
log file sync 2 0.00 0.00
-- 递归SQL汇总
-- 递归SQL是你的SQL或PL/SQL语句所引起的后台语句执行(如:触发器,数据字典操作,表空间操作语句等等)
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 61 0.55 0.55 0 0 0 0
Execute 6447 0.10 0.36 37 29 80 18
Fetch 6444 41.16 44.22 698667 392086 0 6391
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 12952 41.82 45.15 698704 392115 80 6409
Misses in library cache during parse: 3
Misses in library cache during execute: 2
-- 等待事件汇总
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
Disk file operations I/O 140 0.00 0.00
db file sequential read 445 0.02 0.39
db file scattered read 19 0.00 0.00
direct path read 14213 0.00 0.61
asynch descriptor resize 7 0.00 0.00
direct path write temp 22349 0.08 5.76
direct path read temp 22349 0.00 0.67
utl_file I/O 24 0.00 0.00
59 user SQL statements in session.
9 internal SQL statements in session.
68 SQL statements in session.
********************************************************************************
Trace file: .trc
Trace file compatibility: 11.1.0.7
Sort options: prsela exeela fchela
1 session in tracefile. -- 会话数量
59 user SQL statements in trace file. -- SQL语句数量
9 internal SQL statements in trace file.-- 内部SQL数量
68 SQL statements in trace file. -- 总SQL数量
67 unique SQL statements in trace file. -- 唯一SQL数量
79778 lines in trace file.
45 elapsed seconds in trace file. -- 花费总时间(s)
经验总结
-
Query + Current = Logical Reads (total number of buffers accessed)
(query+current)/rows 平均每行所需的block数,太大的话(超过20)SQL语句效率太低
-
Parse count应尽量接近1,如果太高的话,说明SQL进行了不必要的reparse
-
disk/(query+current)
磁盘IO所占逻辑IO的比例,太大的话有可能是db_buffer_size过小(也跟SQL的具体特性有关)
-
elapsed/cpu 太大表示执行过程中花费了大量的时间等待某种资源
-
cpu Or elapsed 太大表示执行时间过长,或消耗了了大量的CPU时间,应该考虑优化
-
执行计划中的Rows 表示在该处理阶段所访问的行数,要尽量减少
-
DISK是从磁盘上的数据文件中物理读取的块的数量。一般来说更想知道的是正在从缓存中读取的数据而不是从磁盘上读取的数据。
Shell Commands
Using a Java stored procedure it is possible to perform shell commands from PL/SQL.
- [Create the Java Stored Procedure](#Create the Java Stored Procedure)
- [Publish the Java call specification](#Publish the Java call specification)
- [Grant Privileges](#Grant Privileges)
- [Test It](#[Test It]).
- [Known Issues](#[Known Issues]).
This should only be used as a last resort if the functionality you require is not available via other means, like external jobs using the scheduler. As mentioned later, you need to be very careful what file system privileges you grant and/or who you give access to this functionality. If used unwisely, this could allow someone to damage files on the server, or cause a major security breach.
Create the Java Stored Procedure
First we need to create the Java class to perform the shell command.
CREATE OR REPLACE AND COMPILE JAVA SOURCE NAMED "Host" AS
import java.io.*;
public class Host {
public static void executeCommand(String command) {
try {
String[] finalCommand;
if (isWindows()) {
finalCommand = new String[4];
// Use the appropriate path for your windows version.
//finalCommand[0] = "C:\\winnt\\system32\\cmd.exe"; // Windows NT/2000
finalCommand[0] = "C:\\windows\\system32\\cmd.exe"; // Windows XP/2003
//finalCommand[0] = "C:\\windows\\syswow64\\cmd.exe"; // Windows 64-bit
finalCommand[1] = "/y";
finalCommand[2] = "/c";
finalCommand[3] = command;
}
else {
finalCommand = new String[3];
finalCommand[0] = "/bin/sh";
finalCommand[1] = "-c";
finalCommand[2] = command;
}
final Process pr = Runtime.getRuntime().exec(finalCommand);
pr.waitFor();
new Thread(new Runnable(){
public void run() {
BufferedReader br_in = null;
try {
br_in = new BufferedReader(new InputStreamReader(pr.getInputStream()));
String buff = null;
while ((buff = br_in.readLine()) != null) {
System.out.println("Process out :" + buff);
try {Thread.sleep(100); } catch(Exception e) {}
}
br_in.close();
}
catch (IOException ioe) {
System.out.println("Exception caught printing process output.");
ioe.printStackTrace();
}
finally {
try {
br_in.close();
} catch (Exception ex) {}
}
}
}).start();
new Thread(new Runnable(){
public void run() {
BufferedReader br_err = null;
try {
br_err = new BufferedReader(new InputStreamReader(pr.getErrorStream()));
String buff = null;
while ((buff = br_err.readLine()) != null) {
System.out.println("Process err :" + buff);
try {Thread.sleep(100); } catch(Exception e) {}
}
br_err.close();
}
catch (IOException ioe) {
System.out.println("Exception caught printing process error.");
ioe.printStackTrace();
}
finally {
try {
br_err.close();
} catch (Exception ex) {}
}
}
}).start();
}
catch (Exception ex) {
System.out.println(ex.getLocalizedMessage());
}
}
public static boolean isWindows() {
if (System.getProperty("os.name").toLowerCase().indexOf("windows") != -1)
return true;
else
return false;
}
};
/
show errors java source "Host"
Publish the Java call specification
Next we publish the call specification using a PL/SQL "wrapper" PL/SQL procedure.
CREATE OR REPLACE PROCEDURE host_command (p_command IN VARCHAR2)
AS LANGUAGE JAVA
NAME 'Host.executeCommand (java.lang.String)';
Grant Privileges
In this example we are granting access to all directories on the server. That is really dangerous. You need to be more specific about these grants and/or be very careful about who you grant access to this functionality.
The relevant permissions must be granted from SYS for JServer to access the file system. In this case we grant access to all files accessible to the Oracle software owner, but in reality that is a very dangerous thing to do.
CONN / AS SYSDBA
DECLARE
l_schema VARCHAR2(30) := 'TEST'; -- Adjust as required.
BEGIN
DBMS_JAVA.grant_permission(l_schema, 'java.io.FilePermission', '<<ALL FILES>>', 'read ,write, execute, delete');
DBMS_JAVA.grant_permission(l_schema, 'SYS:java.lang.RuntimePermission', 'writeFileDescriptor', '');
DBMS_JAVA.grant_permission(l_schema, 'SYS:java.lang.RuntimePermission', 'readFileDescriptor', '');
END;
/
The affects of the grant will not be noticed until the grantee reconnects. In addition to this, the owner of the Oracle software must have permission to access the file system being referenced.
Test It
Finally we call the PL/SQL procedure with our command text.
SET SERVEROUTPUT ON SIZE 1000000
CALL DBMS_JAVA.SET_OUTPUT(1000000);
BEGIN
--host_command (p_command => 'move C:\test1.txt C:\test2.txt');
host_command (p_command => '/bin/mv /home/oracle/test1.txt /home/oracle/test2.txt');
END;
如示例中所示,linux中的命令要全路径,否则会运行报错。
The same result could be achieved with COM Automation but in my opinion this method is much neater.
The output from the host command can be captured using the DBMS_OUTPUT.get_lines procedure.
CONN test/test
SET SERVEROUTPUT ON SIZE 1000000
CALL DBMS_JAVA.SET_OUTPUT(1000000);
DECLARE
l_output DBMS_OUTPUT.chararr;
l_lines INTEGER := 1000;
BEGIN
DBMS_OUTPUT.enable(1000000);
DBMS_JAVA.set_output(1000000);
--host_command('dir C:\');
host_command('/bin/ls /home/oracle');
DBMS_OUTPUT.get_lines(l_output, l_lines);
FOR i IN 1 .. l_lines LOOP
-- Do something with the line.
-- Data in the collection - l_output(i)
DBMS_OUTPUT.put_line(l_output(i));
END LOOP;
END;
Known Issues
- Depending on the environment, the process may continue running as a zombie after the command has been executed, even if the destroy() method is called manually. If this happens the process is only cleaned up when the session ends. Under normal circumstances this doesn't represent a problem, but when called as part of a job the zombie processes will only die when the Job Queue Coordinator is stopped.
- No profile is run for the OS callout, so no environment variables will be set. As a result you will need to use full paths to any executables ("ls" becomes "/bin/ls") or scripts. Alternatively, write all operations as scripts and set the relevant environment variables inside the scripts.
For more information see:
标签:PLSQL,--,0.00,视图,物化,CUX,name From: https://www.cnblogs.com/star-tong/p/17563647.html