查询优化(一)
1 关联查询优化
数据准备
CREATE TABLE `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY(`id`)
);
CREATE TABLE `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY(`bookid`)
);
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
左外连接的查询优化
EXPLAIN SELECT * FROM `type` LEFT JOIN book ON `type`.card = book.card;

外连接可以看做是一个嵌套循环,即对于外层的驱动表的一个card内层被驱动表需要检索所有的card来进行连接,时间复杂度为O(N^2),因此使用索引优化需要在被驱动表上添加索引,这样时间复杂度就为O(N * logN)
CREATE INDEX idx_card ON book(card)

内连接优化
首先删除掉上面创建的索引,查看内连接的执行计划,这时type是驱动表而book是被驱动表
DROP INDEX idx_card ON book
DROP INDEX idx_card ON `type`
EXPLAIN SELECT * FROM `type` INNER JOIN book ON `type`.card = book.card;

然后对type创建索引,查看内连接的执行计划,这时book是驱动表而type是被驱动表

对于内连接来说,查询优化器可以选择哪个表作为驱动表哪个表作为被驱动表,并且在两个表的连接条件只有一个索引的情况的会选择有索引的表作为被驱动表
添加两个索引,向type中添加数据,查看内连接的执行计划,这时book是驱动表而type是被驱动表
CREATE INDEX idx_card ON book(card);
CREATE INDEX idx_card ON `type`(card);
EXPLAIN SELECT * FROM `type` INNER JOIN book ON `type`.card = book.card;
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO type(card) VALUES(FLOOR(1 + RAND() * 20));
在两个表的连接条件都存在的情况下,会选择小表作为驱动表,这样被驱动表能够利用索引快速筛选更多的记录

join语句的底层原理
数据准备
CREATE TABLE a (
f1 INT,
f2 INT,
INDEX(f1)
)ENGINE = INNODB;
CREATE TABLE b (
f1 INT,
f2 INT
)ENGINE = INNODB;
INSERT INTO a VALUES(1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6);
INSERT INTO b VALUES(3, 3), (4, 4), (5, 5), (6, 6), (7, 7), (8, 8);
外连接驱动表变化的情况
前面已经说过内连接可能会被优化器优化,导致驱动表和被驱动表重新选择,而外连接其实也可能出现这种情况,下面查看下面两个语句的执行计划
测试一:
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) WHERE (a.f2 = b.f2);
SHOW WARNINGS;
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `atguigudb1`.`a`.`f1` AS `f1`,`atguigudb1`.`a`.`f2` AS `f2`,`atguigudb1`.`b`.`f1` AS `f1`,`atguigudb1`.`b`.`f2` AS `f2` from `atguigudb1`.`a` join `atguigudb1`.`b` where ((`atguigudb1`.`a`.`f1` = `atguigudb1`.`b`.`f1`) and (`atguigudb1`.`a`.`f2` = `atguigudb1`.`b`.`f2`))

这种情况是比较极端的,这个外连接的语义恰巧是一个内连接,因为where条件的存在排除了a有记录而b没有的情况,外连接也就变成了内连接
所以上面的语句没有where的话,show warnings则没有将其转化为内连接
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1)

测试二:
mysql> EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) AND (a.f2 = b.f2);
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| 1 | SIMPLE | a | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | NULL |
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
mysql> show warnings;
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `atguigudb1`.`a`.`f1` AS `f1`,`atguigudb1`.`a`.`f2` AS `f2`,`atguigudb1`.`b`.`f1` AS `f1`,`atguigudb1`.`b`.`f2` AS `f2` from `atguigudb1`.`a` left join `atguigudb1`.`b` on(((`atguigudb1`.`b`.`f2` = `atguigudb1`.`a`.`f2`) and (`atguigudb1`.`b`.`f1` = `atguigudb1`.`a`.`f1`))) where true |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
Simple Nested-Loop Join(简单嵌套循环连接)
MySQL的join连接操作的本质就是循环匹配算法,如下从A中取出一条数据,然后遍历B表再将匹配的数据放到result,以此类推,需要对驱动表的每一条记录和被驱动表的记录进行判断
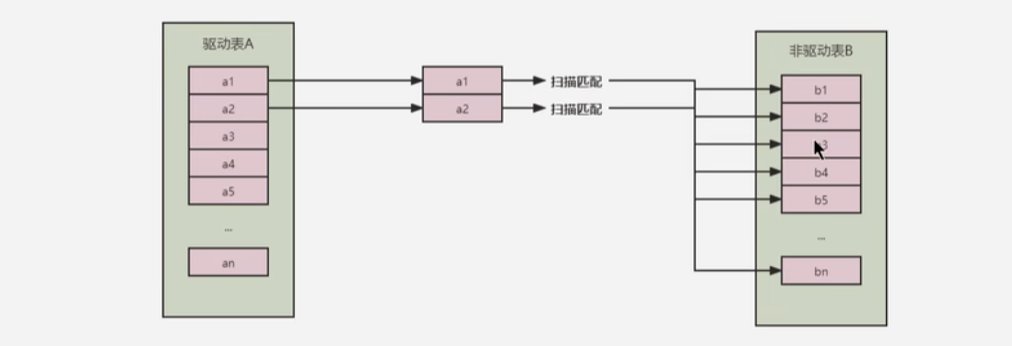
这种方式是非常低效的,假设A表有100条记录,B表有1000条,则A*B=10万次,开销统计如下:
- 内表扫描次数:A
- 外表扫描次数:1
- 读取记录数:A+A*B
- JOIN比较次数:B*A
- 回表读取记录数:0
从读取记录数来看,其实就能明白为什么关联查询要求是小表驱动大表比较好:
A如果是小表的话,A + A * B要比B + A * B要小
Index Nested-Loop Join(索引嵌套循环)
索引嵌套循环主要是为了减少连接时内层表的匹配次数,要求被驱动表必须建立索引。这样外层匹配条件直接和内层索引进行匹配,主键索引就直接得到数据,非主键则还需要进行回表操作,就避免了外层直接和内层的每一条记录进行匹配,极大减少了对内层表的匹配次数。
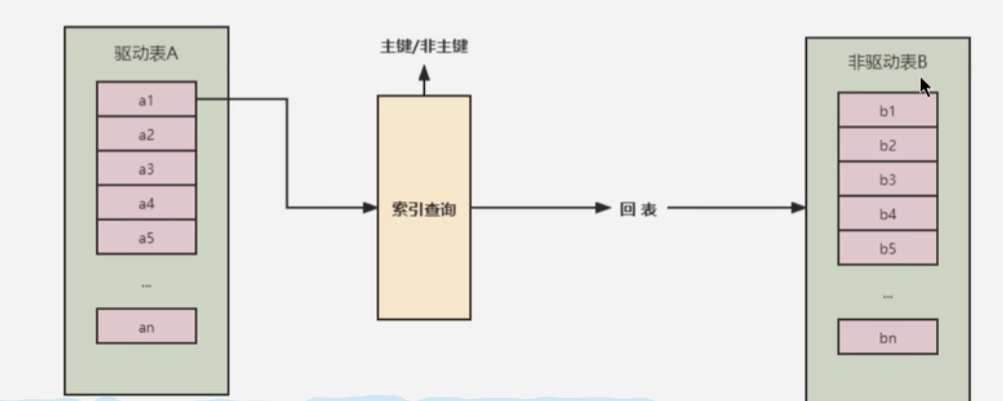
- 内表扫描次数:0(索引查询不会扫描全部内表)
- 外表扫描次数:1
- 读取记录数:A+B(Match)
- JOIN比较次数:A*Index(Height)(数据都在B+树的叶子节点,因此想查看是否含有匹配条件的节点,需要一直比较到叶子节点,比较树高度次数)
- 回表读取记录数:B(Match)(非聚簇索引才需要回表)
对比简单嵌套循环:
- 内表扫描次数:A
- 外表扫描次数:1
- 读取记录数:A+A*B
- JOIN比较次数:B*A
- 回表读取记录数:0
Block Nested-Loop Join(块嵌套循环连接)
如果被驱动表存在索引,则会按照index的方式进行join,但是如果join的列没有索引,则按照简单循环嵌套的方式要扫描的次数太多,即对于每次驱动表的一条记录,被驱动表都需要加载一条记录进行匹配,结束后清除内存。
因此引入了块嵌套循环连接的方式,目的是为了降低被驱动表的读取次数,引入了join buffer缓冲区,会将被驱动表的相关部分数据列(大小受join buffer限制)缓存到join buffer中,将多次简单循环嵌套合并成了一次,降低了被驱动表的访问频率。
为什么缓存驱动表?
缓存驱动表和被驱动表效果是一样的(A*B并不会影响匹配的次数),但是由于驱动表是小表,所以消耗较小
缓存的不只是连接条件的列,select后面的列也会被缓存起来。
在一个有N个join的sql中会分配n-1个join buffer。
在查询的时候应该尽量写入较少的列,以让join buffer能够缓存更多的列。
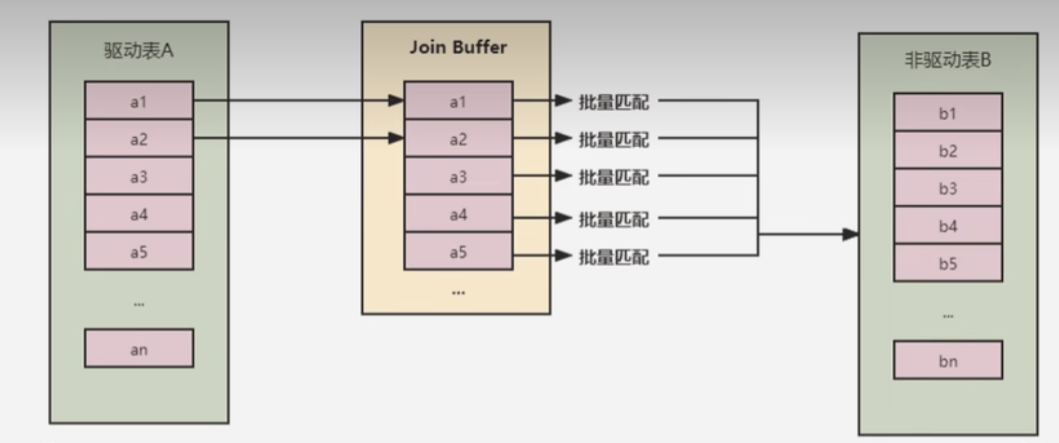
- 和
简单嵌套循环相比只是内表扫描次数变化:A*used_column_size/join_buffer_size表示缓存A个表记录的列需要多少个join buffer,也就是需要读多少次被驱动表了,+1表示向上取整(感觉不是老师说的为了读取一次驱动表) - 然后读取记录的时候,因为是批量匹配,也就是一个驱动表的缓冲池需要读取B个记录进行匹配,相比以前则是每一个驱动表记录都需要读取B个记录,因此是
A + B * A*used_column_size/join_buffer_size
Join小结
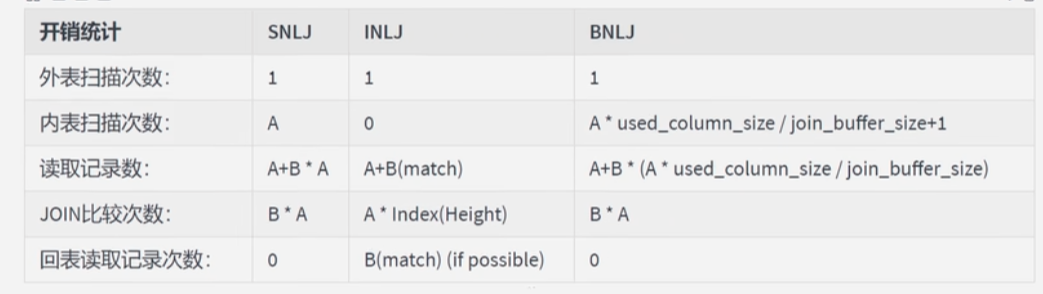
- 整体效率:INLJ > BNLJ > SNLJ
- 永远使用小结果集驱动大结果集(本质是减少
外层循环的数据数量)(小的度量单位指的是 表行数 * 每行大小) - 为
被驱动表匹配的条件添加索引(减少内层表的循环匹配次数) - 增大join buffer的大小
- 减少驱动表不必要的字段的查询
Hash Join
从MySQL 8.0.20版本开始将废弃BNLJ,默认将使用Hash join。Hash Join是做大数据集连接时常用的方式,优化器将使用两个表中较小的表利用Join Key在内存中建立散列表,然后扫描较大的被驱动表并探测散列表,找出与Hash表匹配的行。
2 子查询优化
子查询的效率不高,一般建议都是使用关联查询来代替,因为:
- 执行子查询的时候,会为关联查询建立一个
临时表,然后外层查询语句从临时表中查询记录,查询完毕之后,再撤销这些表,这样会消耗过多的CPU和IO资源,产生大量慢查询 - 产生的无论是内存临时表还是磁盘临时表,都不存在索引,因此查询性能会收到影响
- 对返回结果集比较大的子查询,对查询性能的影响也比较大
测试一:查询班长的学生信息
CREATE INDEX idx_monitor ON class(monitor);
EXPLAIN SELECT * FROM student stu1
WHERE stu1.`stu_no` IN (
SELECT monitor
FROM class
WHERE monitor IS NOT NULL
)

这里正常来说IS NOT NULL是无法使用索引的,但是由于条件select后面只有一个monitor,因此能够进行索引覆盖,因此type为index
MATERIALIZED:物化,即产生的临时表
推荐使用关联查询的方式:
EXPLAIN SELECT stu.*
FROM student stu JOIN class cla
ON stu.`stu_no` = cla.monitor
测试二:查询不为班长的学生信息
EXPLAIN SELECT * FROM student stu1
WHERE stu1.`stu_no` NOT IN (
SELECT monitor
FROM class
WHERE monitor IS NOT NULL
)

推荐使用关联查询的方式:
EXPLAIN SELECT stu.*
FROM student stu LEFT JOIN class cla
ON stu.stu_no = cla.monitor
WHERE cla.monitor IS NULL;
3 排序优化
一般在where条件的字段上添加索引,为什么还要在order by后面的字段添加呢?
在mysql中,有两种排序方式:
- index排序:索引可以保证数据的有序性,不需要再进行排序,效率更高
- file sort文件排序:一般在
内存中进行,需要占用较多的CPU,如果待排的结果较大,会产生临时文件IO到磁盘进行排序的情况,效率较低
优化建议:
- 在where字句和order by条件中使用索引,在where字句中使用可以避免全表扫描,在Order By中使用可以避免file sort文件排序,但是在某些情况下,文件排序的效率要比索引排序的效率要高
- 如果where的字段和orderby的字段相同就使用单列索引,否则使用联合索引
- 无法使用index sort的时候,应该对file sort进行优化
测试
首先删除class 和 student创建的索引
SHOW INDEX FROM class;
SHOW INDEX FROM student;
DROP INDEX idx_name ON student;
DROP INDEX idx_age ON student;
DROP INDEX idx_monitor ON class;
测试一:不使用索引
EXPLAIN SELECT * FROM student ORDER BY age, class_id;
EXPLAIN SELECT * FROM student ORDER BY age, class_id LIMIT 10;
由于没有索引,所以都是file sort文件排序
测试二:使用索引,没有limit索引仍然失效
CREATE INDEX idx_age_cid_name ON student(age, class_id, name);
EXPLAIN SELECT * FROM student ORDER BY age, class_id;

这是因为select的字段是*,这也就意味着进行索引排序后还需要进行一次回表操作,优化器分析成本后认为还不如直接进行一次文件排序的效率高,因此不会使用索引进行排序
测试三:使用索引,limit10变为了索引排序
EXPLAIN SELECT * FROM student ORDER BY age, class_id LIMIT 10;

这是因为数据量较小,索引排序后再回表的成本小于直接文件排序的成本,因此选择索引排序了
测试四:使用索引,没有limit但是只是查询索引字段
EXPLAIN SELECT age,`name` FROM student ORDER BY age, class_id;
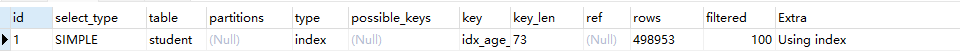
由于索引覆盖,没有回表操作,因此优化器选择进行索引排序
测试五:Order By时顺序错误,索引失效
CREATE INDEX idx_age_cid_sno ON student(age, class_id, stu_no);
下面哪些索引失效?
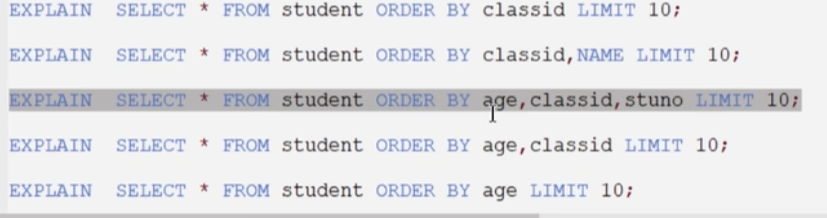
1、2会失效,由于最左前缀原则,联合索引不先使用左边的索引会导致后面无法使用
测试五:Order By时规则不一致,索引失效

1、2、3会失效,4正常
EXPLAIN SELECT * FROM student ORDER BY age DESC, class_id DESC LIMIT 10
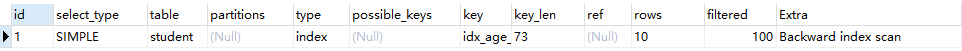
这里是用的mysql8的新特性
倒序索引,正常情况下由于叶子节点之间是双向链表但是节点内部记录之间是单向链表的,无法利用索引进行倒序排序
测试六:无过滤,不索引
EXPLAIN SELECT * FROM student WHERE age = 45 ORDER BY class_id

EXPLAIN SELECT * FROM student WHERE age = 45 ORDER BY class_id, `name`

可以看到上面两种情况的key只使用了where条件中的age字段(key_len = 4 + 1),这是因为索引无法覆盖select,所以还需要回表操作,优化器认为不如直接进行全表扫描
EXPLAIN SELECT * FROM student WHERE class_id = 45 ORDER BY age;

EXPLAIN SELECT * FROM student WHERE class_id = 45 ORDER BY age LIMIT 10;

在数据量较小的情况下,可以使用
索引覆盖进行检索,因此执行计划的type类型为index,这里是符合最左前缀原则的
总结:Order by的字段能够和where后的字段构建联合索引,但是可能需要针对select进行回表,所以需要查询优化器判断是这么做还是直接全表扫描然后文件排序。

注意最后一个,这里失效的原因是a是一个范围查询,会导致后面的索引失效。那么为什么能使用索引的情况的最后一个可以呢?下面我自己试了一下:
EXPLAIN SELECT * FROM student WHERE age = 10 AND class_id > 45 ORDER BY class_id, `name` LIMIT 10;

可以看到key_len的长度是10,表示只用到了联合索引的前两个,并且在补充说明中表名只使用的index条件判断。所以这种应该说是用了但是没完全用。那么再举下最后一个的情况的例子:
但是有一个问题,第二个索引是范围查询,导致后面的索引无序从而无法使用,那么为什么这里没有和下面一样进行文件排序呢?
EXPLAIN SELECT * FROM student WHERE age in (10, 20, 30) ORDER BY class_id, `name` LIMIT 10;

其实这种也用到了联合索引的第一个字段,并且还需要再进行文件排序。
实战
首先删除前面建立的索引
DROP INDEX idx_age_cid_name ON student
DROP INDEX idx_age_cid_sno ON student
然后执行下面,显然是进行的文件排序
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stu_no < 10100 ORDER BY NAME;
为了去掉文件排序,建立一个索引:
CREATE INDEX idx_age_name ON student(age, name)
再次执行上面的语句查看执行计划:发现没有了file sort,并且key_len为5,即只使用了联合索引的第一个字段,这是因为索引天然有序,因此不需要使用第二个字段

file sort一定很糟糕吗?
真不是,比如还是上面的情况,这时候再建立一个索引
CREATE INDEX idx_age_sno_name ON student(age, stu_no, name)
再执行一次查询计划,发现尽管有上面不使用文件排序的索引,优化器还是毫不犹豫地选择了这个可能会出现文件排序的索引,这是因为第二个索引使用的字段(9)要高于第一个(5),结果就是过滤后的行数rows要远远小于第一个的,只对这一点记录进行文件排序显然成本要低。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stu_no < 10100 ORDER BY NAME;

小结:
- 当group by字段和order by字段出现索引二选一的情况的时候,优先观察条件字段过滤数量,如果过滤的数据足够多,而需要排序的数据不多的时候,优先把索引放在范围字段上,反之亦然。
4 Group By优化
- group by即使没有过滤条件使用到索引,也可以直接使用索引
- group by先排序再分组,因此使用索引的时候遵照最左前缀法则
- 当无法使用索引列,增大
max_length_for_sort_data和sort_buffer_size的设置 - where的效率要高于having,能写在where就不要写在having
- 减少使用order by,尽量将排序放到程序端去做,order by、group by、distinct语句都较为耗费cpu
- 包含了order by、group by、distinct语句的sql,where条件过滤出来的数据应尽量低于1000行
5 分页查询优化
一般的分页查询,通过创建覆盖索引就能较好地提高性能,但是下面的这种情况就比较头疼:取200w条数据,此时mysql需要排序分页前2000010条数据,然后仅仅返回后10条,其他的记录都丢弃掉,查询排序的代价非常大。
SELECT * FROM student LIMIT 2000000, 10
优化思路一
该思路只适用于主键自增的表,可以把limit转换成某个位置的查询:
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10
但是一般情况下id不一定是自增的,而且也不一定是自增为1 的
优化思路二
在索引上完成排序分页操作,然后根据主键关联原表进行回表查询其他列的值。
EXPLAIN SELECT *
FROM student stu1, (SELECT id FROM student ORDER BY id LIMIT 2000000, 10) stu2
WHERE stu1.id = stu2.id