目录
- 一、前言
- 二、命令行操作(hbase shell)
- 三、Phoenix插件安装与使用(用来支持标准sql)
- 四、RegionServer拆分实现
- 五、预写日志 (WAL)
- 六、HBase Master高可用实现
- 七、总结
一、前言
HBase的基本概念和环境部署,可以参考我之前的文章:列式存储的分布式数据库——HBase(环境部署)
二、命令行操作(hbase shell)
1)连接HBase
官方文档:https://hbase.apache.org/book.html#shell
# 启动hbase服务,已启动可忽略
start-hbase.sh
# 连接到 HBase
hbase shell
# 查看帮助
hbase:003:0> help
【温馨提示】表名、行、列都必须用引号字符括起来。
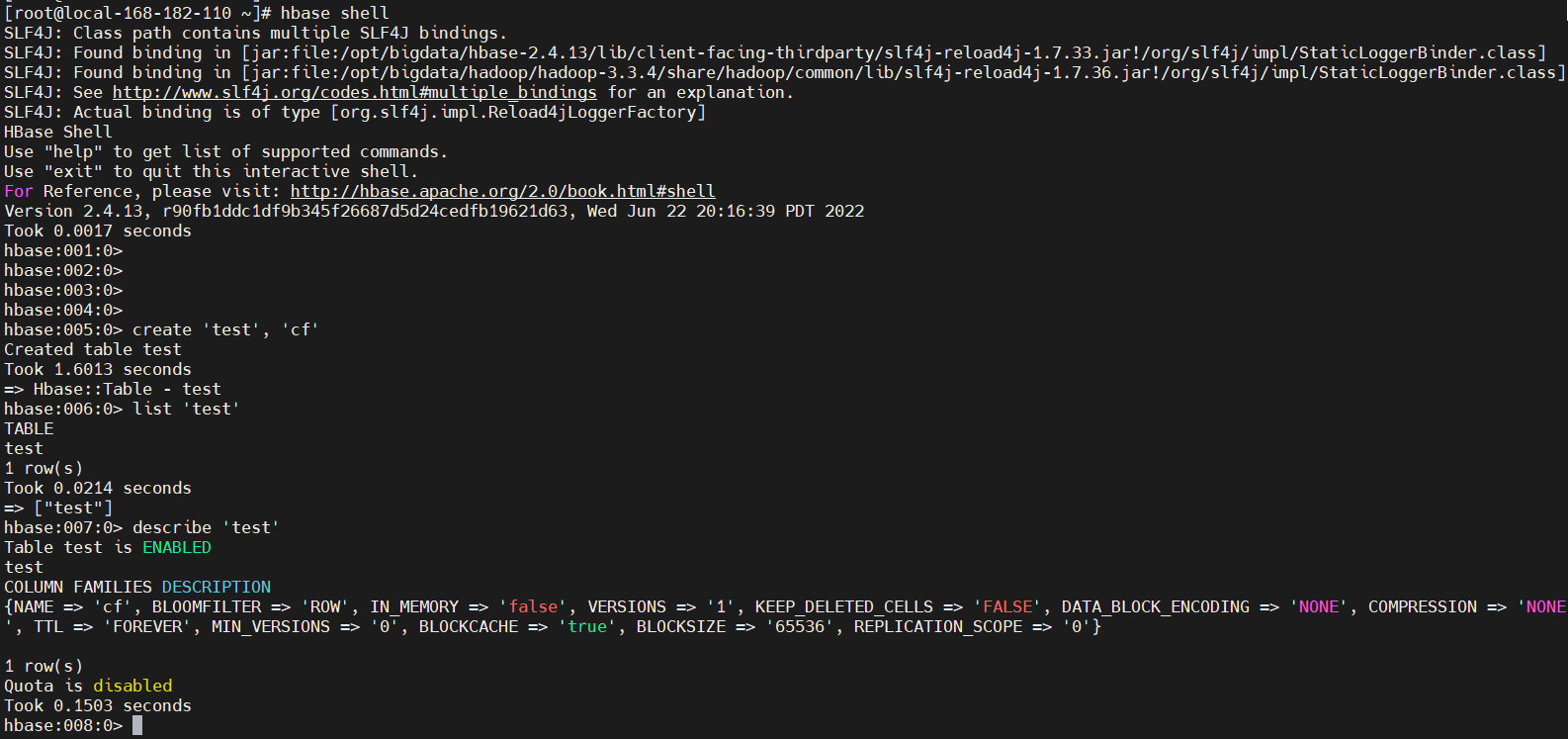
2)创建表(create)
使用create命令创建一个新表。您必须指定表名称和 ColumnFamily 名称。
create 'test', 'cf'
# 使用list命令确认您的表存在
list 'test'
# 现在使用describe命令查看详细信息,包括配置默认值
describe 'test'
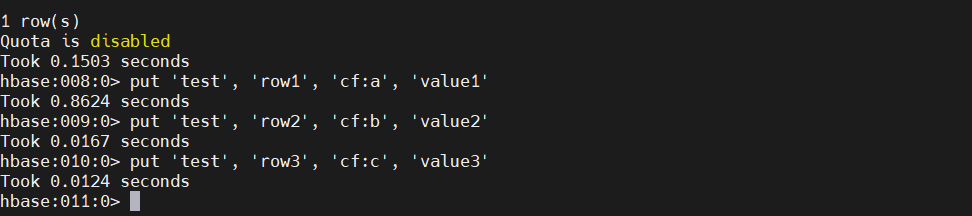
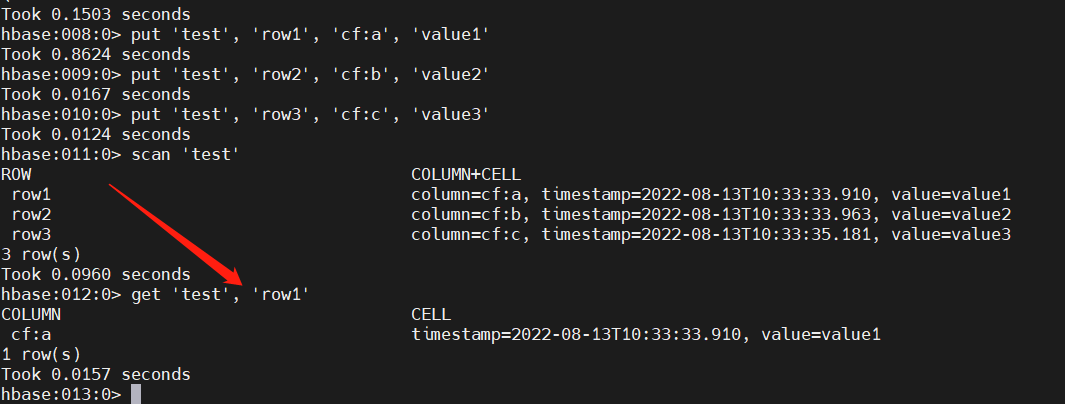
3)添加数据(put)
要将数据放入表中,请使用put命令。在这里,我们一次插入三个值。第一个插入位于row1列cf:a,值为value1。HBase 中的列由列族前缀组成,cf在本例中,后跟冒号,然后是列限定符后缀,a在本例中。
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'
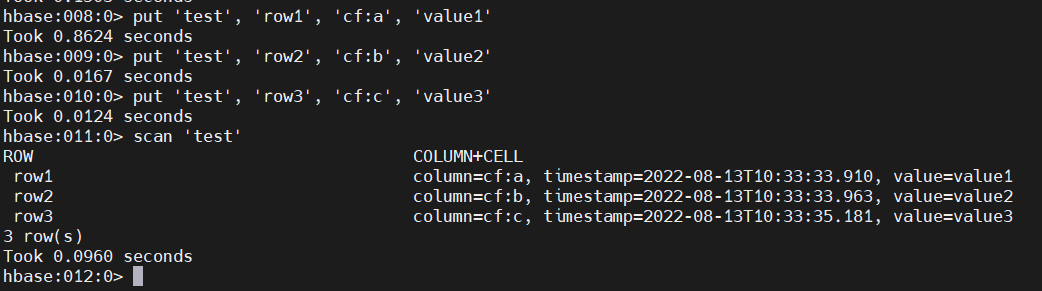
4)查询数据(scan )
从 HBase 获取数据的方法之一是扫描。使用该scan命令扫描表中的数据。您可以限制您的扫描,但目前,所有数据都已获取。
scan 'test'
5)获取单行数据(get)
要一次获取一行数据,请使用该get命令。
get 'test', 'row1'
6)禁用/启用表(disable/enable)
如果要删除表或更改其设置,以及在某些其他情况下,您需要先禁用该表,使用该disable命令。enable您可以使用命令重新启用它。
disable 'test'
enable 'test'
7)清空表(truncate)
truncate 'test'
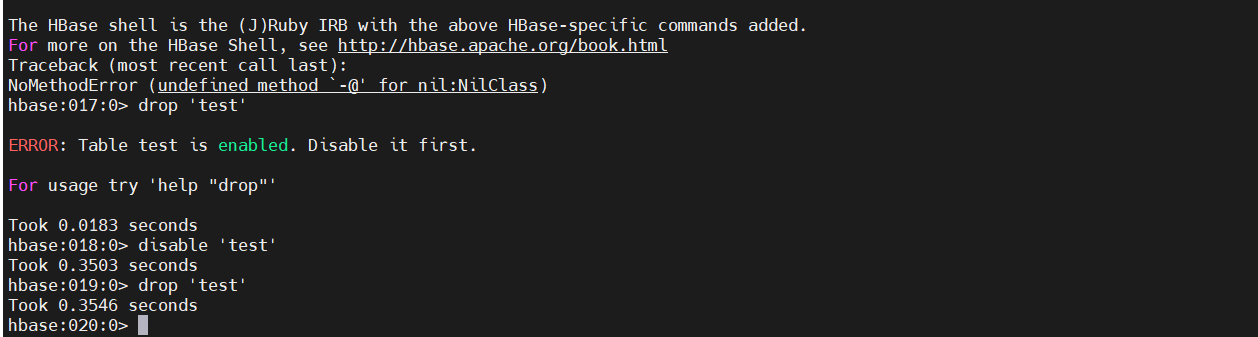
8)删除表(drop)
# Disable it first,删表之前必须先禁用
disable 'test'
drop 'test'
9)开启debug模式(debug)
方式一:
hbase(main):007:0> debug
Debug mode is ON
# 再执行就关闭debug模式了
hbase(main):008:0> debug
Debug mode is OFF
方式二:
./bin/hbase shell -d
10)命名空间(namespace)
# 创建命名空间
create_namespace 'my_ns'
# 查看命名空间详情
describe_namespace 'my_ns'
# 指定命名空间创建表(不指定默认default命名空间)
create 'my_ns:my_table', 'fam'
# 删除命名空间
drop_namespace 'my_ns'
# 修改命名空间
alter_namespace 'my_ns', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
# 查看所有命名空间
list_namespace
# 查看命名空间下的所有表
list_namespace_tables
# 查看命名空间‘ns1’下的所有表
list_namespace_tables 'my_ns'
11)版本操作
-
{row, column, version}元组准确地指定了cellHBase中的a。可能有无限数量的单元格,其中行和列相同,但单元格地址仅在其版本维度上有所不同。
-
虽然行和列键以字节表示,但版本是使用长整数指定的。通常,此 long 包含时间实例,例如由java.util.Date.getTime()or返回的时间实例System.currentTimeMillis(),即:当前时间与 UTC 1970 年 1 月 1 日午夜之间的差异,以毫秒为单位。
-
HBase 版本维度以降序存储,因此在从存储文件中读取时,首先找到最新的值。
cell在 HBase中,版本的语义存在很多混淆。尤其是:
-
如果对一个单元格的多次写入具有相同的版本,则只有最后一次写入是可获取的。
-
可以按不递增的版本顺序写入单元格。
指定要存储的版本数(示例)
# 先创建
create 't1', 'f1'
# 此示例使用 HBase Shell 来保留 column family 中所有列的最多 5 个版本f1。您也可以使用HColumnDescriptor。
alter 't1', NAME => 'f1', VERSIONS => 5
# 修改列族的最小版本数
# 您还可以指定每个列族存储的最小版本数。默认情况下,它设置为 0,这意味着该功能被禁用。以下示例通过 HBase Shell将列族f1中所有列的最小版本数设置为 。
alter 't1', NAME => 'f1', MIN_VERSIONS => 2
【温馨提示】hbase.column.max.version从 HBase 0.98.2 开始,您可以通过在hbase-site.xml中设置,为所有新创建的列保留的最大版本数指定全局默认值。
12)退出 HBase Shell(quit)
要退出 HBase Shell 并断开与集群的连接,请使用该quit命令。HBase 仍在后台运行。
quit
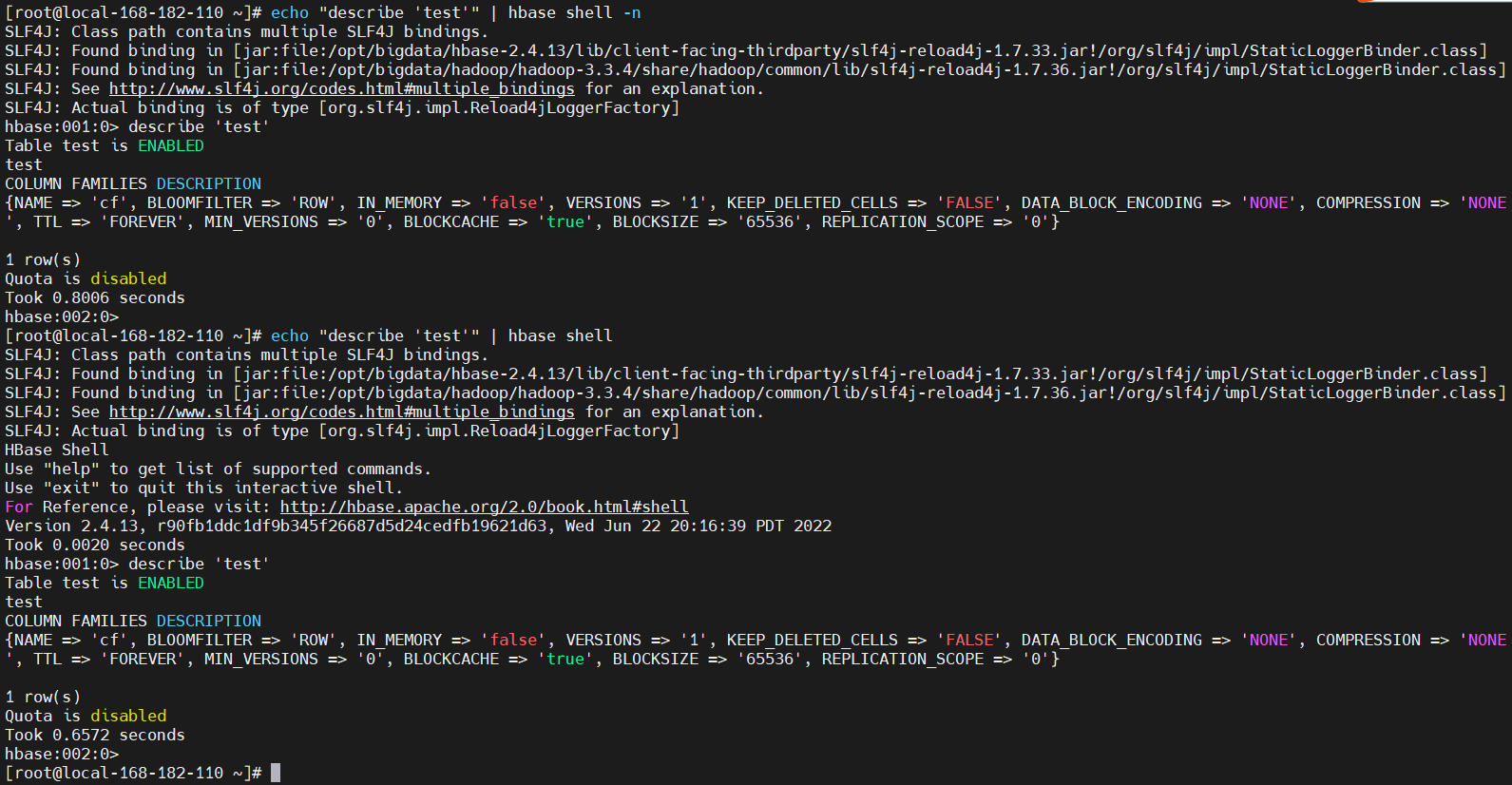
13)非交互式执行(echo)
您可以使用命令和(管道)运算符以非交互模式将命令传递给 HBase Shell。请务必转义 HBase 命令中的字符,否则这些字符会被 shell 解释。从下面的示例中截断了一些调试级别的输出。echo|
echo "describe 'test'" | hbase shell -n
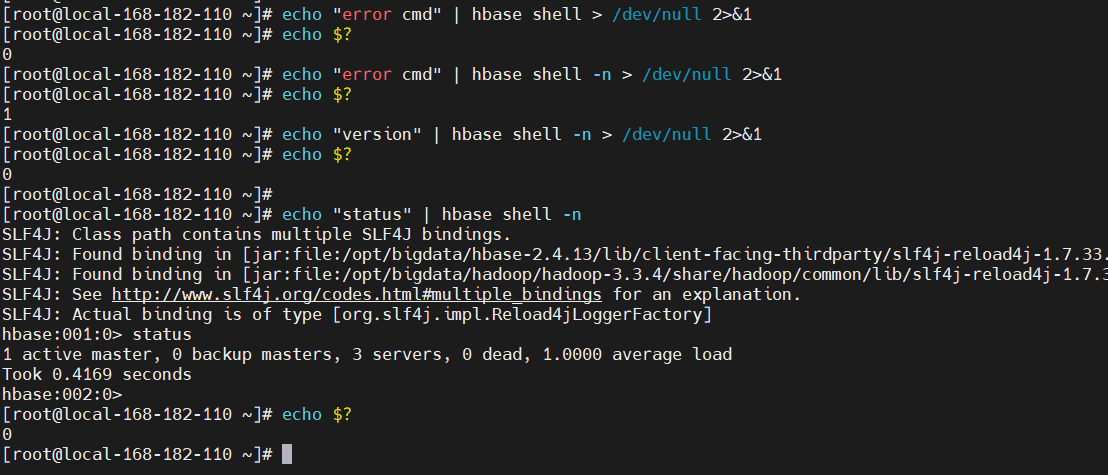
如果我们想要知道HBase Shell命令执行之后是否成功,那一定要使用非交互模式(-n会带出执行状态,不使用-n,$?总是0,无法判断失败和成功)。因为交互模式执行命令后总是返回0。当执行命令失败后,非交互模式将返回非0数值。如下示例:
[root@local-168-182-110 ~]# echo "error cmd" | hbase shell > /dev/null 2>&1
[root@local-168-182-110 ~]# echo $?
0
[root@local-168-182-110 ~]# echo "error cmd" | hbase shell -n > /dev/null 2>&1
[root@local-168-182-110 ~]# echo $?
1
[root@local-168-182-110 ~]# echo "version" | hbase shell -n > /dev/null 2>&1
[root@local-168-182-110 ~]# echo $?
0
[root@local-168-182-110 ~]#
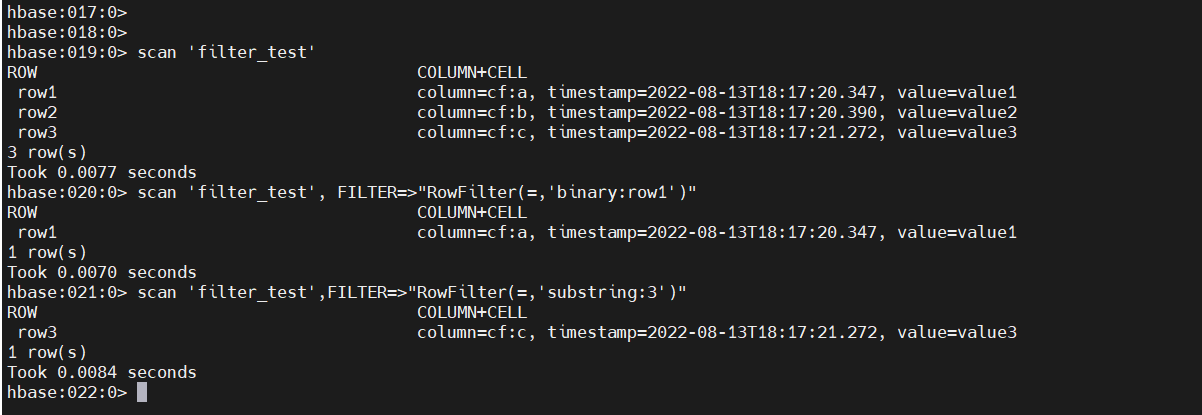
14)过滤器(FILTER )
过滤器包括:行键过滤器、列族与列过滤器、值过滤器、时间过滤器、分页过滤器等。
# 注意: FILTER(大写)
scan ‘表名’, { FILTER => “过滤器(比较运算符, ‘比较器’)” }
简单使用
# 连接
hbase shell
# 创建表
create 'filter_test', 'cf'
put 'filter_test', 'row1', 'cf:a', 'value1'
put 'filter_test', 'row2', 'cf:b', 'value2'
put 'filter_test', 'row3', 'cf:c', 'value3'
# 查看
scan 'filter_test'
# 过滤
scan 'filter_test', FILTER=>"RowFilter(=,'binary:row1')"
# 过滤出行键中包含3的数据
scan 'filter_test',FILTER=>"RowFilter(=,'substring:3')"
三、Phoenix插件安装与使用(用来支持标准sql)
1)Phoenix简介
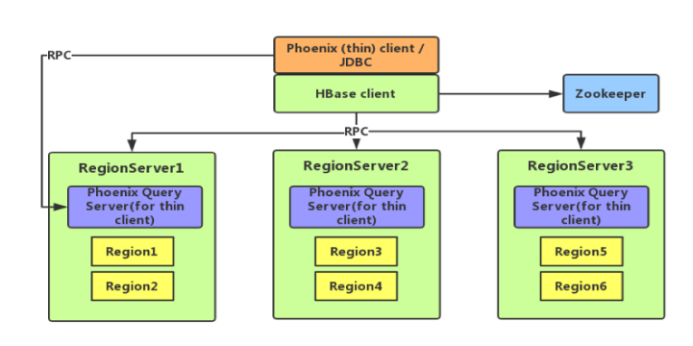
- Phoenix 是一个 Hadoop 上的 OLTP 和业务数据分析引擎,为用户提供操作 HBase 的 SQL 接口,结合了具有完整 ACID 事务功能的标准 SQL 和 JDBC API,以及来自 NoSQL 的后期绑定,具有读取模式灵活的优点。
- phoenix是构建的Hbase之上的,使用标准的SQL操作Hbase,可以做联机事务处理,拥有低延迟的特性。phoenix会把SQL编译成一系列的Hbase的scan操作,然后把scan结果生成标准的JDBC结果集,其底层由于使用了Hbase的API,协处理器,过滤器,处理千万级行的数据也只用毫秒或秒级就搞定。支持有:SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY等操作。
特点如下:
- 容易集成:如Spark,Hive,Pig,Flume和Map Reduce;
- 操作简单:DML命令以及通过DDL命令创建和操作表和版本化增量更改;
- 支持HBase二级索引创建。
2)下载
下载地址:https://phoenix.apache.org/download.html
cd $HBASE_HOME
wget https://dlcdn.apache.org/phoenix/phoenix-5.1.2/phoenix-hbase-2.4-5.1.2-bin.tar.gz --no-check-certificate
tar -xf phoenix-hbase-2.4-5.1.2-bin.tar.gz
3)将phoenix-server-hbase-*.jar文件拷贝到HBase的lib目录下
cp $HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/phoenix-server-hbase-*.jar $HBASE_HOME/lib/
4)将phoenix包同步到其他主机上
scp -r $HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin local-168-182-111:$HBASE_HOME/
scp -r $HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin local-168-182-112:$HBASE_HOME/
scp $HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/phoenix-server-hbase-*.jar local-168-182-111:$HBASE_HOME/lib/
scp $HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/phoenix-server-hbase-*.jar local-168-182-112:$HBASE_HOME/lib/
5)重启HBase
关闭hbase后记得检查所有主机进程是否消失
stop-hbase.sh
start-hbase.sh
6)测试验证
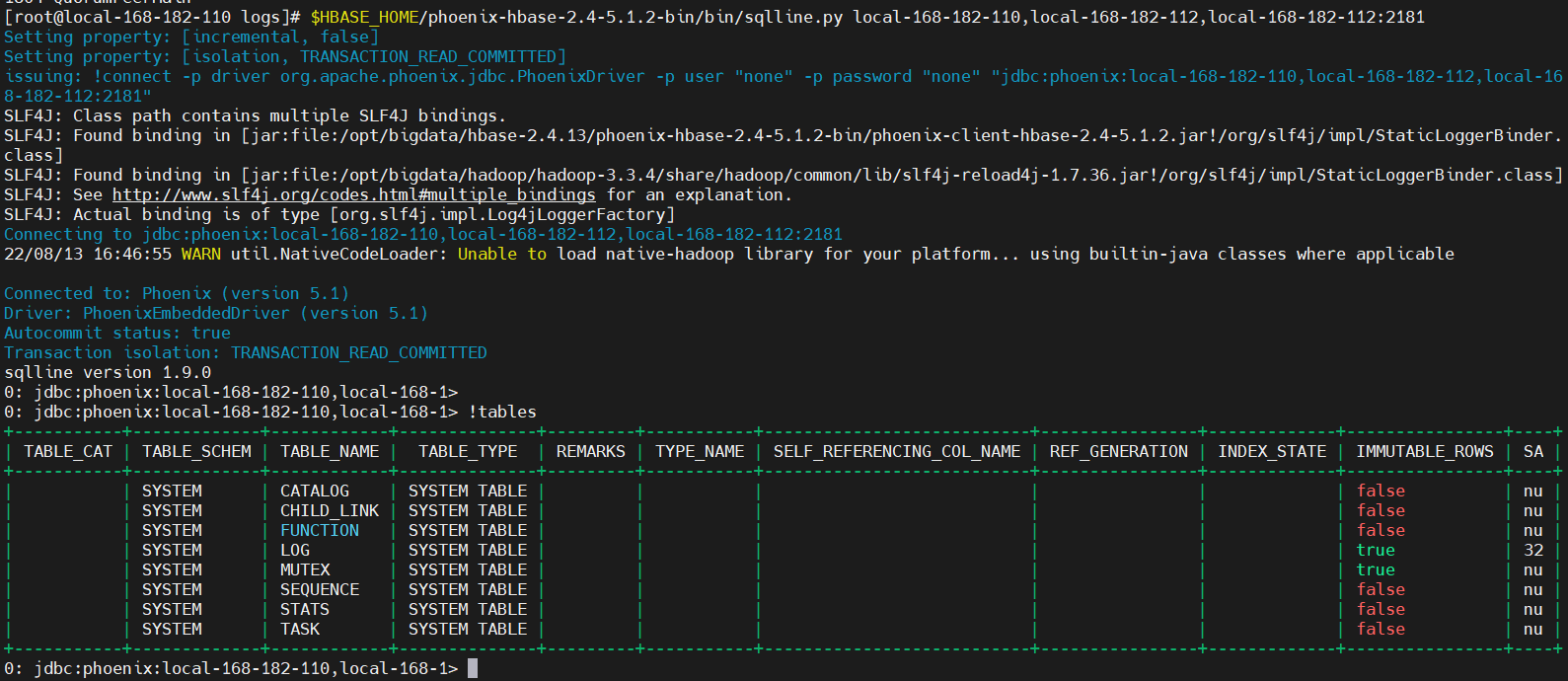
$HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/bin/sqlline.py local-168-182-110,local-168-182-112,local-168-182-112:2181
# 显示所有表
!table
!tables
7)简单使用
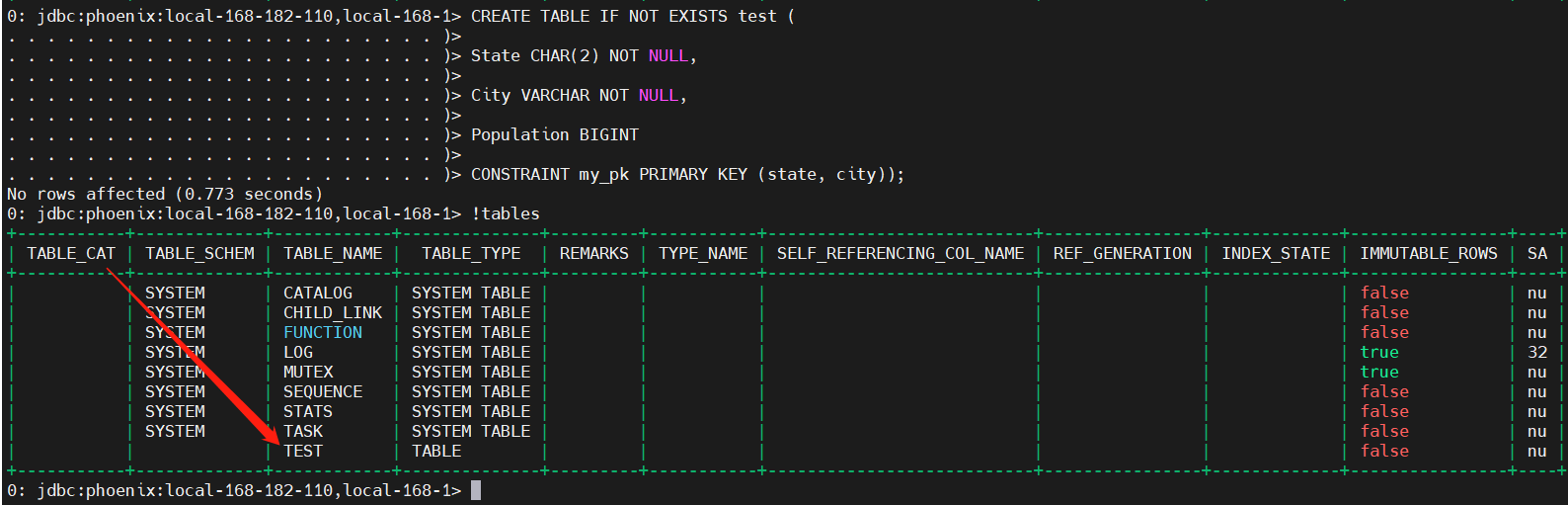
1、创建表
# 建表
CREATE TABLE IF NOT EXISTS test (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
# 在phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"test"。
2、添加数据
upsert into test values('NY','NewYork',123);
3、查询数据
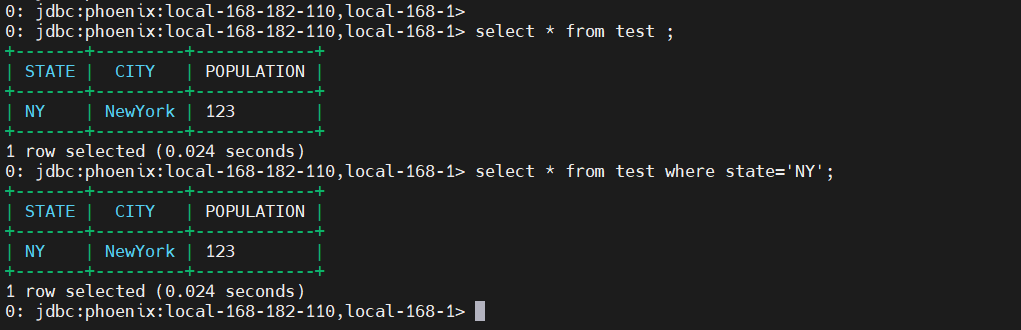
select * from test ;
select * from test where state='NY';
4、删除记录和删除表
delete from test where state='NY';
drop table test ;
5、退出
!quit
!q
6、批量导入数据
us_population.sql
-- 建表
CREATE TABLE example (
my_pk bigint not null,
m.first_name varchar(50),
m.last_name varchar(50)
CONSTRAINT pk PRIMARY KEY (my_pk));
us_population.csv文件内容如下:
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
批量导入
$HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/bin/psql.py local-168-182-110,local-168-182-112,local-168-182-112:2181 us_population.sql us_population.csv
查询
$HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/bin/sqlline.py local-168-182-110,local-168-182-112,local-168-182-112:2181
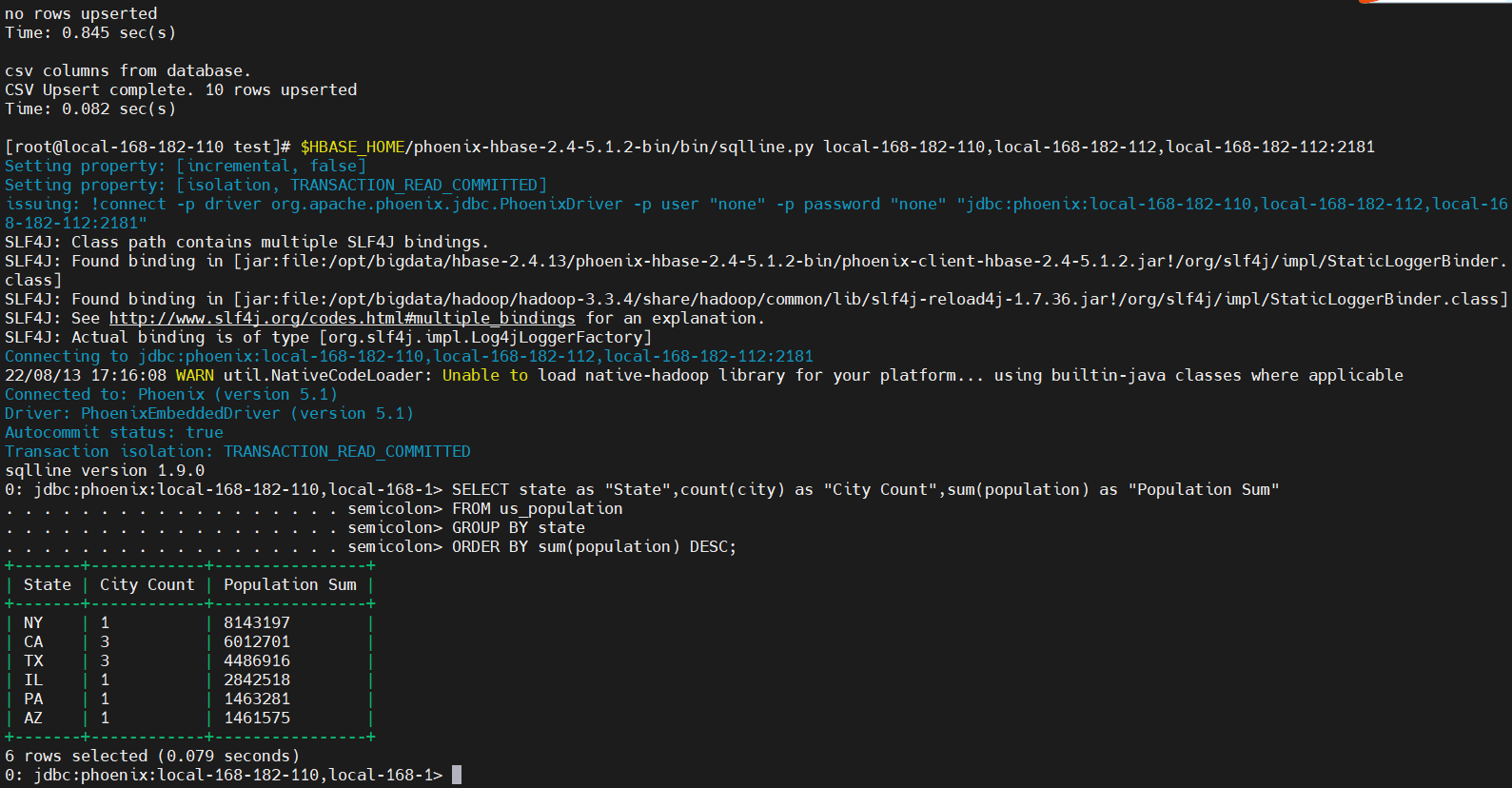
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
7、索引使用
若使用phoenix(对于 Phoenix 4.12 及更高版本)的索引功能,您需要将以下参数添加到每个hbase服务器上的hbase-site.xml :
(详情请参见https://phoenix.apache.org/secondary_indexing.html):
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
上述属性允许写入自定义 WAL 编辑,确保正确写入/重播索引更新。此编解码器支持通常的 WALEdit 选项宿主,最值得注意的是 WALEdit 压缩。
重启HBase
关闭hbase后记得检查所有主机进程是否消失
stop-hbase.sh
start-hbase.sh
example .sql
-- 创建phoenix表(对应的hbase表并不存在)
CREATE TABLE example (
my_pk bigint not null,
m.first_name varchar(50),
m.last_name varchar(50)
CONSTRAINT pk PRIMARY KEY (my_pk));
-- 创建索引
create index example_first_name_index on example(m.first_name);
数据文件example .csv
12345,Joddhn,Dois
67890,Maryddd,Poppssssins
123452,Joddhn,Dois
678902,Maryddd,Poppssssins2
【温馨提示】example .csv名称是表名称,而且只能是csv后缀的名称。
执行批量添加数据
$HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/bin/psql.py local-168-182-110,local-168-182-112,local-168-182-112:2181 example.sql example.csv
查询
$HBASE_HOME/phoenix-hbase-2.4-5.1.2-bin/bin/sqlline.py local-168-182-110,local-168-182-112,local-168-182-112:2181
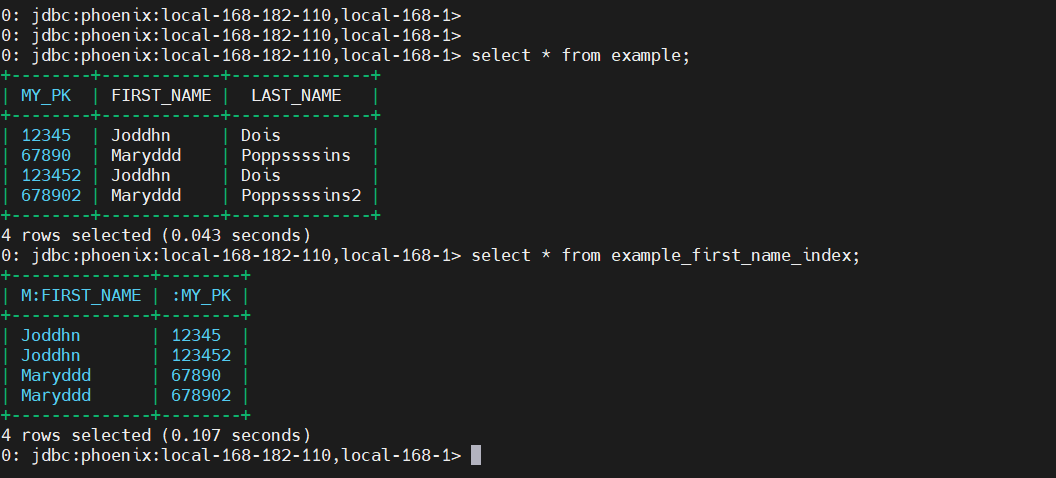
select * from example;
# 通过索引查询
select * from example_first_name_index;
四、RegionServer拆分实现
- 由于写入请求由区域服务器处理,它们会累积在称为memstore的内存存储系统中。
- 一旦 memstore 填满,其内容将作为附加存储文件写入磁盘。
- 此事件称为memstore 刷新。随着存储文件的积累,RegionServer 会将它们压缩成更少、更大的文件。每次刷新或压缩完成后,存储在区域中的数据量发生了变化。
- RegionServer 参考区域拆分策略来确定区域是否已经变得太大或者是否应该出于其他特定于策略的原因进行拆分。如果策略推荐,则将区域拆分请求排入队列。
- 从逻辑上讲,分割区域的过程很简单。我们在区域的关键空间中找到一个合适的点,我们应该将区域分成两半,然后在该点将区域的数据分成两个新区域。
- 然而,该过程的细节并不简单。发生拆分时,新创建的子区域不会立即将所有数据重写到新文件中。相反,它们创建类似于符号链接文件的小文件,命名为参考文件,它根据分割点指向父存储文件的顶部或底部。
- 参考文件的使用与常规数据文件一样,但只考虑了一半的记录。
- 只有在不再引用父区域的不可变数据文件时,才能拆分该区域。
- 这些引用文件通过压缩逐渐清理,因此该区域将停止引用其父文件,并且可以进一步拆分。
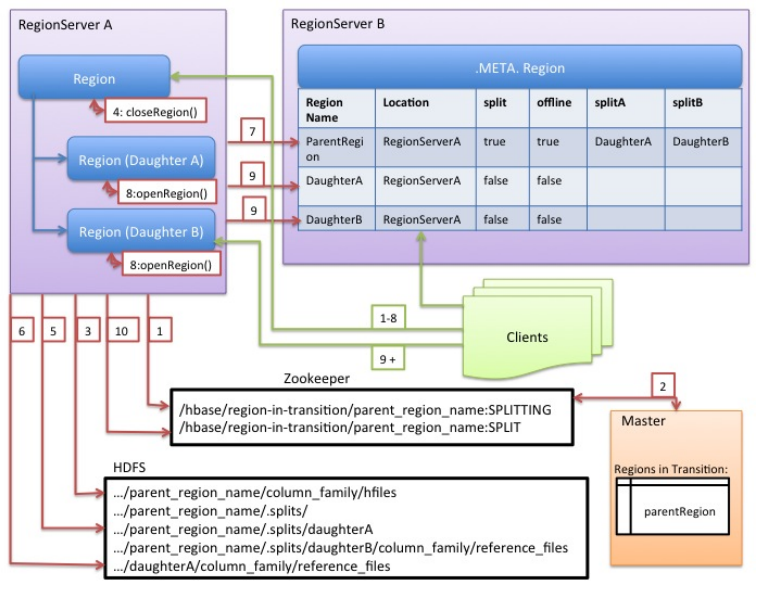
- 虽然分割区域是由 RegionServer 做出的本地决策,但分割过程本身必须与许多参与者协调。
- RegionServer 在拆分前后通知 Master,更新.META.表以便客户端发现新的子区域,并重新排列 HDFS 中的目录结构和数据文件。
- 拆分是一个多任务过程。为了在发生错误时启用回滚,RegionServer 会在内存中保留有关执行状态的日志。
- RegionServer 执行拆分所采取的步骤在RegionServer 拆分过程中进行了说明。
- 每个步骤都标有其步骤编号。来自 RegionServers 或 Master 的操作显示为红色,而来自客户端的操作显示为绿色。
五、预写日志 (WAL)
1)WAL概述
- 预写日志 (WAL)将 HBase 中数据的所有更改记录到基于文件的存储中。在正常操作下,不需要 WAL,因为数据更改从 MemStore 移动到 StoreFiles。但是,如果在刷新 MemStore 之前 RegionServer 崩溃或变得不可用,WAL 会确保可以重放对数据的更改。如果写入 WAL 失败,则整个修改数据的操作都会失败。
- HBase 使用WAL接口的实现。通常,每个 RegionServer 只有一个 WAL 实例。一个例外是携带hbase:meta的 RegionServer ;元表有自己的专用 WAL 。RegionServer 将 Puts 和 Deletes 记录到其 WAL 中,然后将这些 Mutations MemStore记录到受影响的Store中。
2)WAL 提供者
在 HBase 中,有许多 WAL 实现(或“提供者”)。每个都有一个短名称标签(不幸的是,它并不总是描述性的)。您在 hbase-site.xml中设置提供程序,将 WAL 提供程序短名称作为 hbase.wal.provider 属性的值 传递(使用 hbase.wal.meta_provider属性设置hbase:meta的提供程序,否则它使用相同的由hbase.wal.provider配置的提供程序)。
-
syncfs:默认值。自 hbase-2.0.0 (HBASE-15536, HBASE-14790) 以来的新功能。这个AsyncFSWAL提供程序,正如它在 RegionServer 日志中标识的那样,是建立在一个新的非阻塞 dfsclient 实现之上的。它目前驻留在 hbase 代码库中,但目的是将其移回 HDFS 本身。WAL 编辑以并发(“扇出”)方式写入每个 DataNode 上的每个 WAL 块副本,而不是像默认客户端那样在链式管道中。延迟应该更好。有关实施的更多详细信息,请参阅幻灯片 14上的小米 Apache HBase 改进和实践。 -
文件系统:这是 hbase-1.x 版本中的默认设置。它建立在阻塞的DFSClient 之上,并以经典的DFSCLient管道模式写入副本。在日志中,它标识为FSHLog或FSHLogProvider。
-
multiwal:此提供程序由asyncfs或 filesystem的多个实例组成。
3)多线程
-
每个 RegionServer 有一个 WAL,RegionServer 必须串行写入 WAL,因为 HDFS 文件必须是顺序的。这导致 WAL 成为性能瓶颈。
-
HBase 1.0 在HBASE-5699中引入了对
MultiWal的支持。MultiWAL 允许 RegionServer 通过在底层 HDFS 实例中使用多个管道并行写入多个 WAL 流,这增加了写入期间的总吞吐量。这种并行化是通过按区域划分传入编辑来完成的。因此,当前的实现无助于增加单个区域的吞吐量。 -
使用原始 WAL 实现的 RegionServer 和使用 MultiWAL 实现的 RegionServer 可以分别处理任一组 WAL 的恢复,因此可以通过滚动重启实现零停机时间配置更新。
配置 MultiWAL
要为 RegionServer 配置 MultiWAL,请通过粘贴以下 XML 将属性的值设置hbase.wal.provider为multiwal:
<property>
<name>hbase.wal.provider</name>
<value>multiwal</value>
</property>
4)基于procedureV2的WAL拆分
在 HBASE-20610 之后,我们引入了一种通过 procedureV2 框架进行 WAL 拆分协调的新方法。这样可以简化 WAL 拆分的过程,不再需要连接 zookeeper。
1、背景
目前,分裂 WAL 进程由 zookeeper 协调。每个区域服务器都在尝试从 zookeeper 获取任务。并且随着region server数量的增加,负担变得更重。
2、Master 端的实现
在 ServerCrashProcedure 期间,SplitWALManager 将为每个应该拆分的 WAL 文件创建一个 SplitWALProcedure。然后每个 SplitWALProcedure 将产生一个 SplitWalRemoteProcedure 以将请求发送到区域服务器。SplitWALProcedure 是一个 StateMachineProcedure,这里是状态转移图。
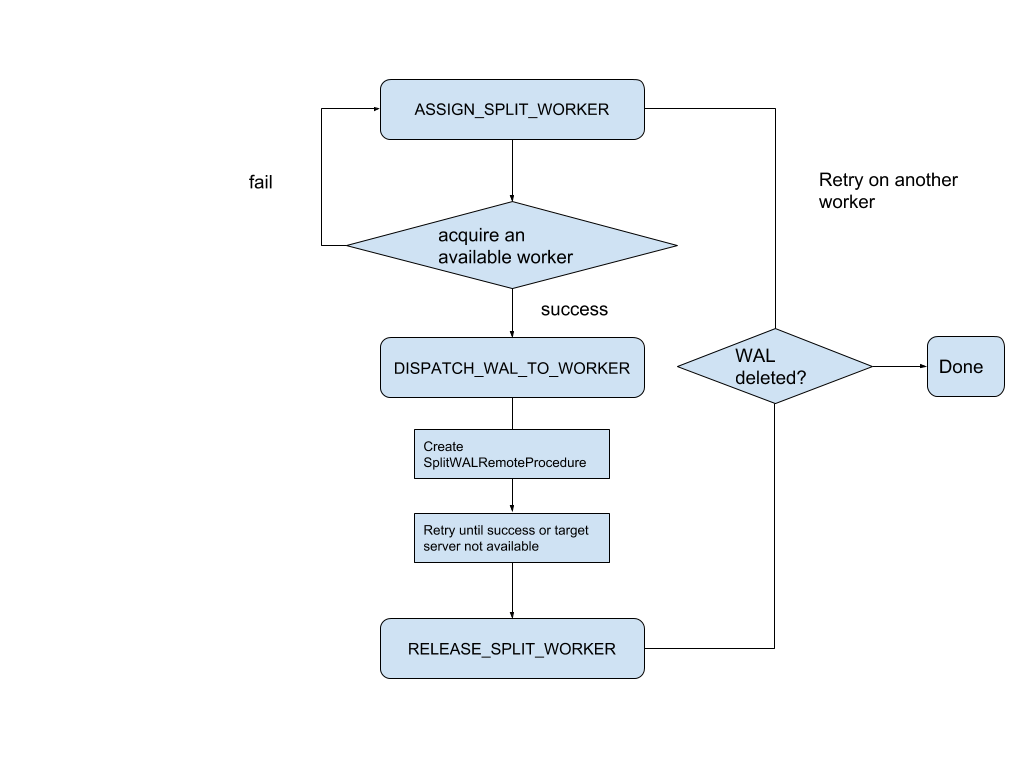
3、Region Server 端的实现
- Region Server 会收到一个 SplitWALCallable 并执行它,这比以前简单多了。如果成功,它将返回 null,如果有任何错误,它将返回异常。
- 根据对具有 5 个区域服务器和 1 个主服务器的集群进行的测试。procedureV2 协调 WAL 分裂在重启整个集群或一个 region server 崩溃时,比 ZK 协调 WAL 分裂 no master 有更好的性能。
- 要启用此功能,首先我们应该确保我们的 HBase 包已经包含这些代码。如果没有,请先升级HBase集群的包,不要做任何配置更改。然后将配置 'hbase.split.wal.zk.coordinated' 更改为 false。使用新配置滚动升级主服务器。现在 WAL 拆分由我们的新实现处理。但是区域服务器仍在尝试从 Zookeeper 中获取任务,我们可以使用新配置滚动升级区域服务器来阻止这种情况。
- 步骤如下:
- 升级整个集群以获得新的实现。
- 使用新配置“hbase.split.wal.zk.coordinated”=false 升级 Master。
- 升级区域服务器以停止从 zookeeper 抓取任务。
关于更多,请查看官方文档:https://hbase.apache.org/book.html#_running_the_shell_in_non_interactive_mode
六、HBase Master高可用实现
- 在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载,如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态。
- 过上述测试,HBase 2.2.4版本中当HMaster角色挂掉后,集群将进入不可用状态,因此在生产环境中我们需要对HBase的Hmaster角色做高可用配置。
1)创建backup-masters文件
echo "local-168-182-111" > $HBASE_HOME/conf/backup-masters
2)将backup-masters文件分发到其它节点
scp $HBASE_HOME/conf/backup-masters local-168-182-111:$HBASE_HOME/conf/
scp $HBASE_HOME/conf/backup-masters local-168-182-112:$HBASE_HOME/conf/
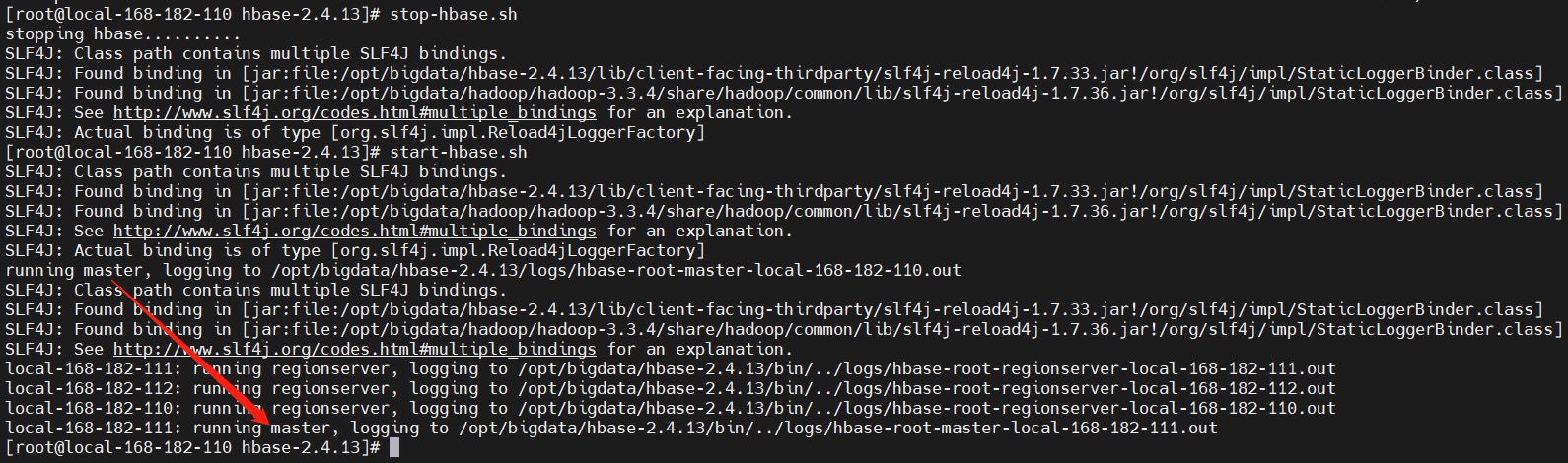
3)重启服务
stop-hbase.sh
start-hbase.sh
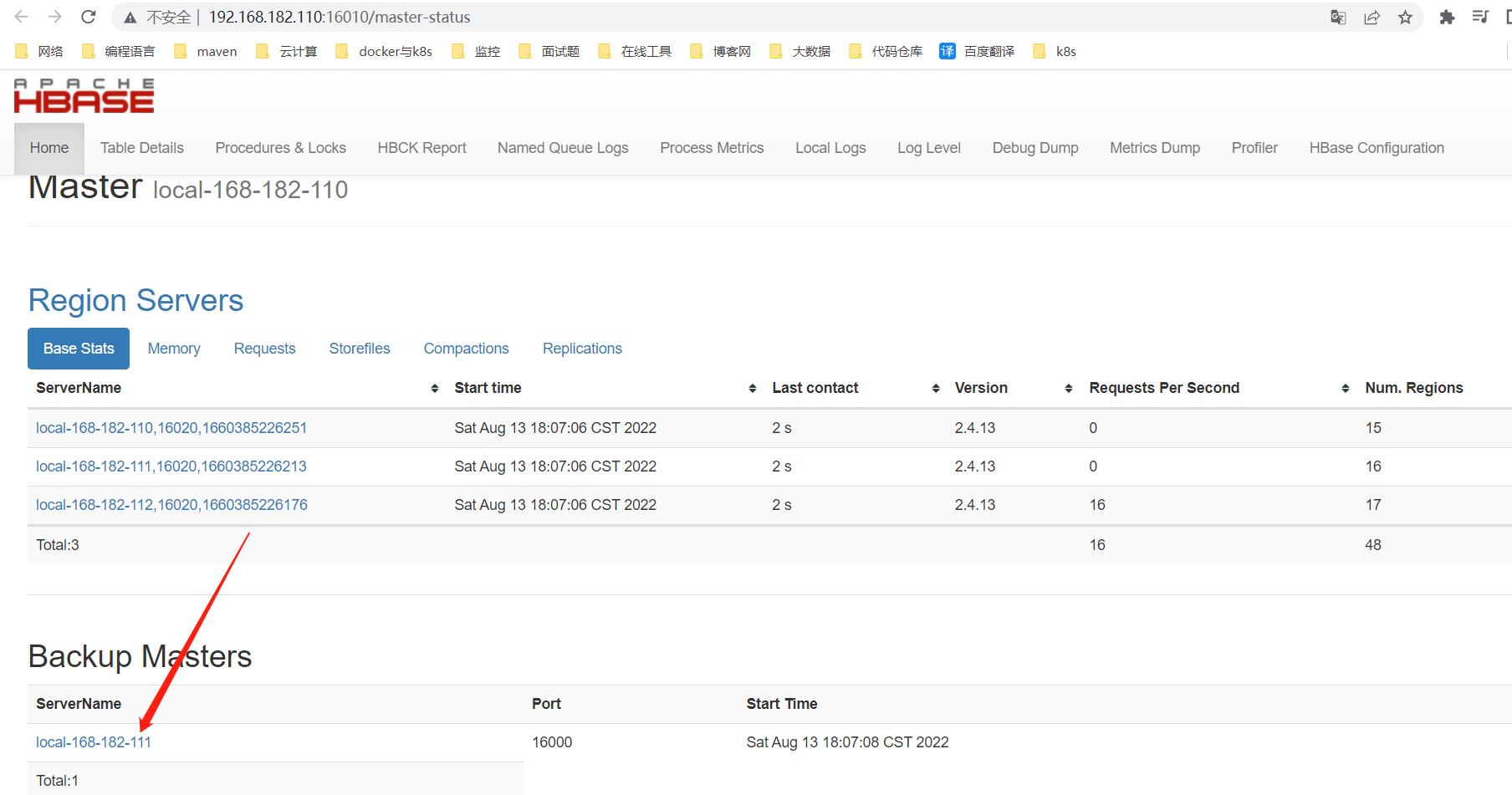
4)检查
web UI界面查看:http://192.168.182.110:16010/master-status
七、总结
其实Hbase主要是基于HDFS,也是为了解决Hadoop的局限性的,Hadoop主要有以下局限性:
- Hadoop主要是实现批量数据的处理,并且通过顺序方式访问数据
- 要查找数据必须搜索整个数据集,如果要进行随机读写,效率很低,所以hive查询HDFS数据效率很低。
HBase主要特点如下:
- HBase就是为了解决上面的局限性,随机读写,读写效率高;
- Hbase 用来存储海量数据,超过百万列,并且常用于实时数据处理中。
HBase应用场景:
- Hbase只要有海量数据存储,而且需要快速的写入以及快速的读取场景,就很适合HBase;
- 可以用来存储爬虫的数据、图片,点赞,转发等数据。
【温馨提示】随机读数据就是想读哪条数据就读哪条数据,例如:mysql查数据一样,可以指定条件读取数据。
HBase的简单使用就先到这里了,后续会持续分享关于大数据相关的文章,请小伙伴耐心等待,有疑问的小伙伴欢迎给我留言哦~
标签:Shell,列式,182,WAL,168,HBase,local,hbase From: https://www.cnblogs.com/liugp/p/16583759.html