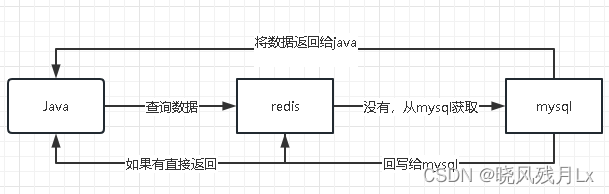
缓存双写一致性
如果redis中有数据
- 需要和数据库中的值相同
如果redis中无数据
-
数据库中的值是最新值,且准备回写redis
-
缓存按照操作分
-
只读缓存
-
读写缓存
-
同步直写策略
- 写数据库后也同步写 redis 缓存,缓存中的数据和数据中的一致
- 对于读写缓存来说,要想保证缓存和数据库中的数据一致
-
异步缓写策略
- 正常业务运行中,mysql数据变动了,但是可以在业务上容许出现一定时间后才作用于redis,比如仓库、物流系统
- 异常情况出现了,不得不讲失败的动作重新修补,有可能需要借助kafka或者RabbitMQ等消息中间件,实现重写重试
-
-
-
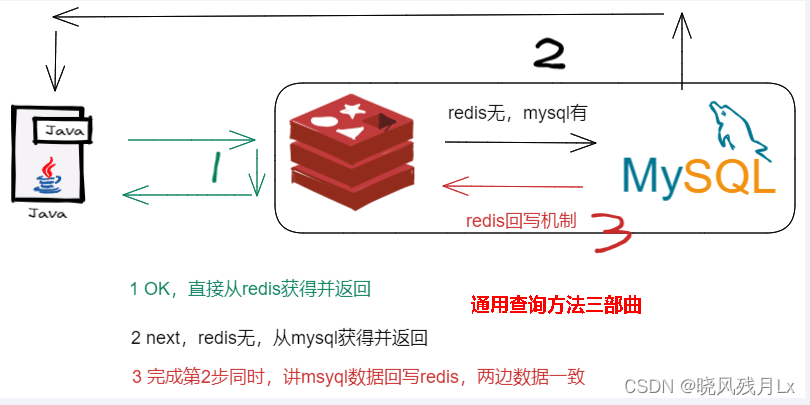
采用双检加锁策略
-
多个线程同时去查询数据库的这条数据,就在第一个查询数据的请求上使用一个互斥锁来锁住他。
-
其他线程获取不到锁就一直等待,等第一个线程查询到了数据,然后做了缓存
-
后面的线程进来发现已经有了缓存,就直接走缓存
package com.lv.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.lv.User;
import com.lv.mapper.UserMapper;
import com.lv.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
/**
* @author 晓风残月Lx
* @date 2023/3/27 12:39
*/
@Slf4j
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById1(Long id){
User user = null;
String key = CACHE_KEY_USER + id;
// 1.先从redis中查询,如果有直接返回结果,没有再去查询 mysql
user = (User) redisTemplate.opsForValue().get(key);
if (user == null){
// 2. redis中没有,查询mysql
user = userMapper.selectById(id);
if (user == null){
// 3.1 redis + mysql 都无数据
// 具体细化,防止多次穿透,业务规定,记录下导致穿透的这个key回写redis
return user;
}else {
// 3.2 mysql有,需要回写到redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况
* @param id
* @return
*/
public User findUserById2(Long id){
User user = null;
String key = CACHE_KEY_USER + id;
// 1.先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
// 第一次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if (user == null){
// 2.对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserServiceImpl.class){
// 第二次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
// 3. 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectById(id);
if (user == null) {
return null;
} else {
// 5. mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key, user, 7L, TimeUnit.DAYS);
}
}
}
}
return user;
}
}
数据库和缓存一致性的几种更新策略
目的
- 达到最终一致性
给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
可以停机的情况
基本上怎么处理都可以
- 挂牌报错
- 凌晨升级
- 服务降级
- 温馨提示
- 最好单线程操作(对于重量级的数据操作)
不可停机的情况
-
先更新数据库, 在更新缓存
- 异常情况1: 线程1先更新数据库, 然后更新缓存出错了, 则会导致后续线程读取到旧数据
- 异常情况2: 高并发情况下, 数据A, 线程1 更新成B, 线程2 更新成C, 有可能更新缓存先更新C, 在更新B, 导致数据库是C, redis是B ,不一致了
-
先更新缓存, 在更新数据库
- 同上同样问题
- 一般数据库的数据为准, 把它做为底库
-
* 先删除缓存, 在更新数据库
-
异常情况: 线程1 先删除了缓存, 然后更新数据库, 可能在这个过程中 有线程2 出现读取到了脏数据 又写回了缓存
-
解决:
-
延时双删
- 线程1 删除了缓存, 然后更新数据库, 可能在这个过程中 有线程2 出现读取到了脏数据 又写回了缓存, 线程1 更新完后再删除一次(保证我是更新完之后在删除)
- 为什么要延迟: 有可能第二次删除, 另一个线程正准备把脏数据给写入, 所以需要延迟一会(延迟的时间是 线程2 读到旧数据并写入的时间)
-
延时双删 又会带来一些问题
-
延时的时间不好把控
- 1、测试业务耗时时间, 加上一个几百毫秒这种
- 2、看门狗机制
-
延时会带来一些性能问题, 降低吞吐量
- 异步去做第二次删除 CompleteFuture
-
-
-
-
** 先更新数据库, 在删除缓存
-
异常情况:
- 1、更新数据库, 删除缓存异常了
- 2、线程1更新数据库, 此时还没删除 线程2进行读取, 读取到的是旧值
-
如何解决呢
- 针对1 如果缓存异常了, 没办法 只能保证最终一致性 放MQ, 让它去保证最终一致性
- 针对2 无法避免, 但是只有少部分线程读取到旧值
-