前言
本文讲述在 Linux 系统部署 Redis Cluster 实现数据分片的具体步骤。
请参考 Redis 单机部署 下载编译。
Redis Cluster是什么?
Redis Cluster 是官方提供的一种用数据分片来实现横向扩容的解决方案,由一个或多个 Redis 服务组成一个无主集群。
对 Key 使用哈希算法将数据分散倒 16384 个哈希槽,让集群中的节点一起来分摊这些槽位;每个节点都可以进行哈希运算,并且保存了所有节点与槽位的映射关系。
客户端通过直连集群任一节点发送操作指令,当操作经过节点哈希计算得出指令不应由本节点处理时,会向客户端返回 MOVED 错误,并附带正确的节点地址,客户端再访问正确的节点来完成操作。
部署步骤
编辑脚本
可以先看下目录下的 README 文档了解如何使用脚本。
echo "进入集群脚本目录" > /dev/null
cd ~/soft/redis/redis-6.2.5/utils/create-cluster/
echo "编辑脚本" > /dev/null
vim create-cluster
脚本开始部分:PORT=30000 代表创建的集群节点端口号从 30000 开始;NODES=6 代表集群节点总数为 6;REPLICAS=1 代表每个节点包含一个副本/从节点,那就意味着集群由 3 个主节点分摊槽位并提供服务,每个主节点分配一个从节点实现高可用。

创建节点
节点产生的文件都会放在当前所在目录下。
./create-cluster start
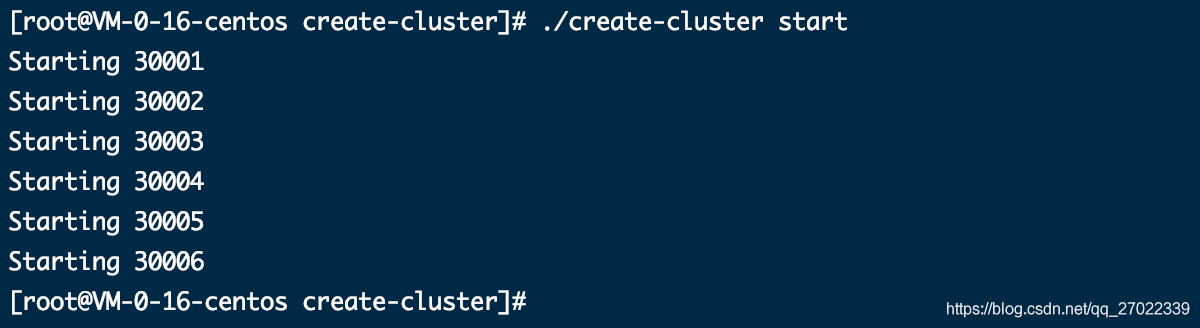
自动分配集群
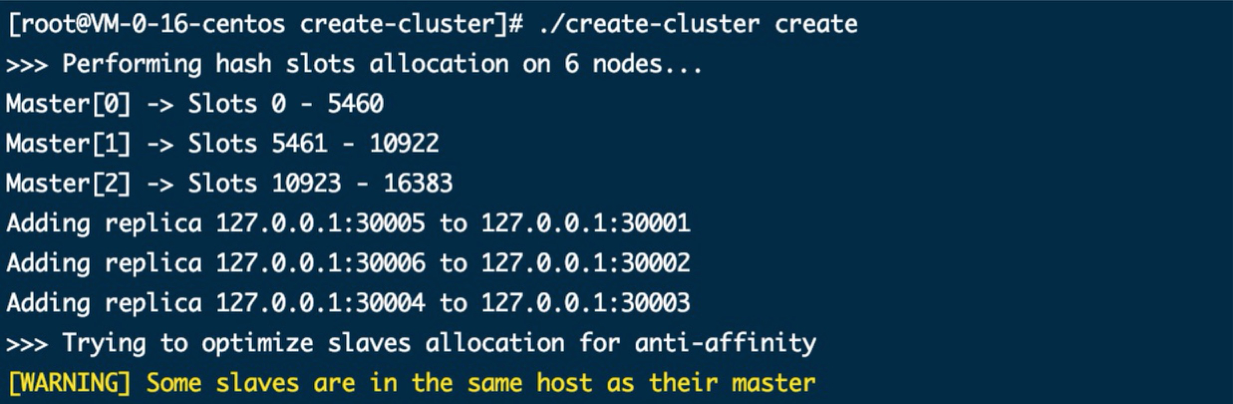
./create-cluster create
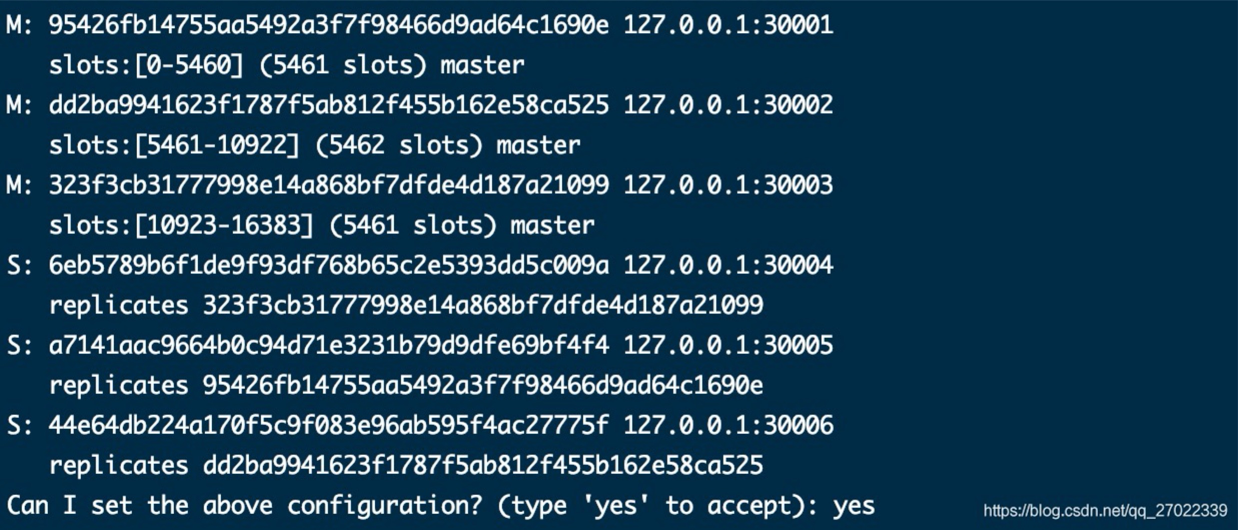
从控制台可以看到将 16384 个槽位分成了 3 份,并分配给了 30001~30003 主节点,30004~30005 分别追随了三个主节点,最后输入 yes 同意这个配置。
黄颜色警告是指从节点和主节点在一台服务器,实际使用肯定需要分开实现高可用。
停止、清除集群
# 停止集群
./create-cluster stop
# 清除日志、数据等相关文件
./create-cluster clean
手动分配集群
其实这种方式跟自动分配最终实现是一样的,只不过自动分配的脚本帮我们拼接了指令然后执行了而已。
# 用脚本创建 6 个节点
./create-cluster start
# 分配,指明节点地址和副本数量
redis-cli --cluster create 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 127.0.0.1:30004 127.0.0.1:30005 127.0.0.1:30006 --cluster-replicas 1
测试
连接节点设置数据,加上 -c 表示操作 Cluster 节点,好处是如果节点经过哈希计算告诉客户端正确的节点地址时,客户端会自动帮你重定向到正确的节点完成操作。
你也可以不加 -c 来连接节点执行操作,只不过客户端工具不会帮你重定向来完成,而是打印 MOVE 错误。
redis-cli -c -p 30001

你可以执行 KEYS * 操作,只不过返回的只有当前节点的所有 key;
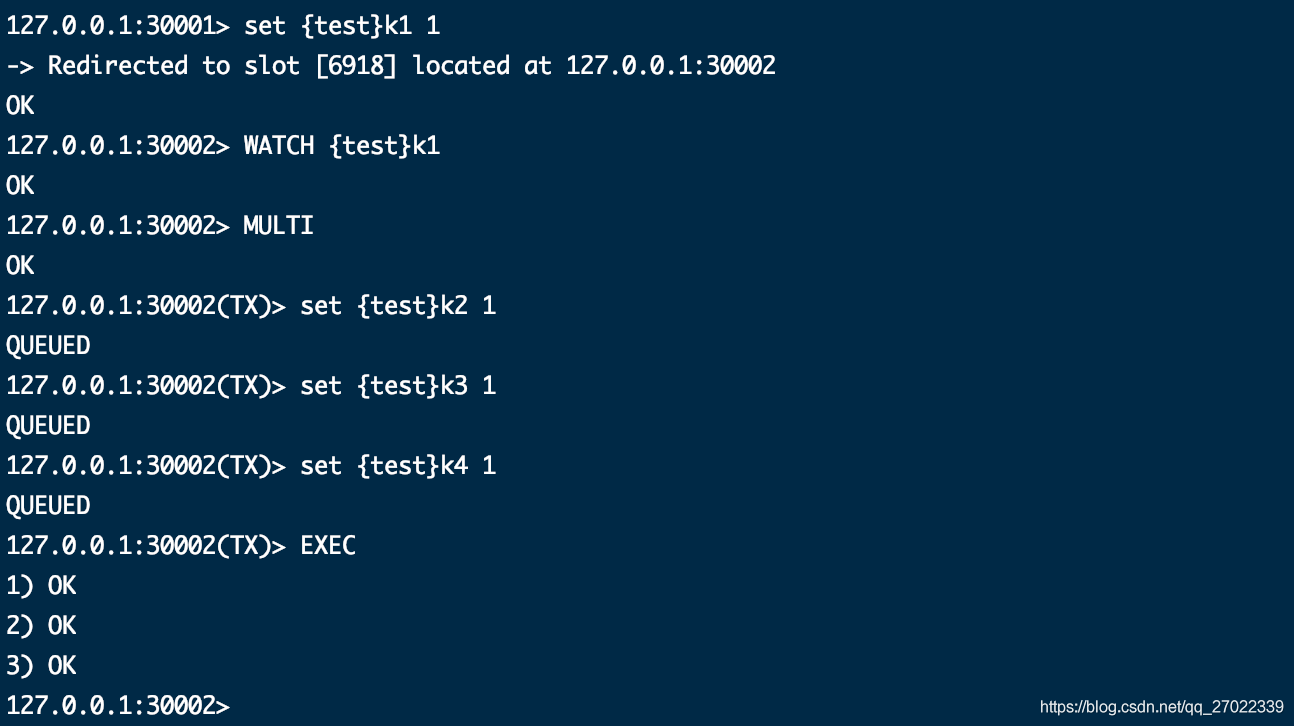
你可以使用 WATCH、MULTI 尝试以事务的方式来设置多个数据,不过最后 EXEC 提交会报错事务超时,因为你多个操作在不同节点之间跳转,提交事务和开启事务不是同一节点,整个混乱了。
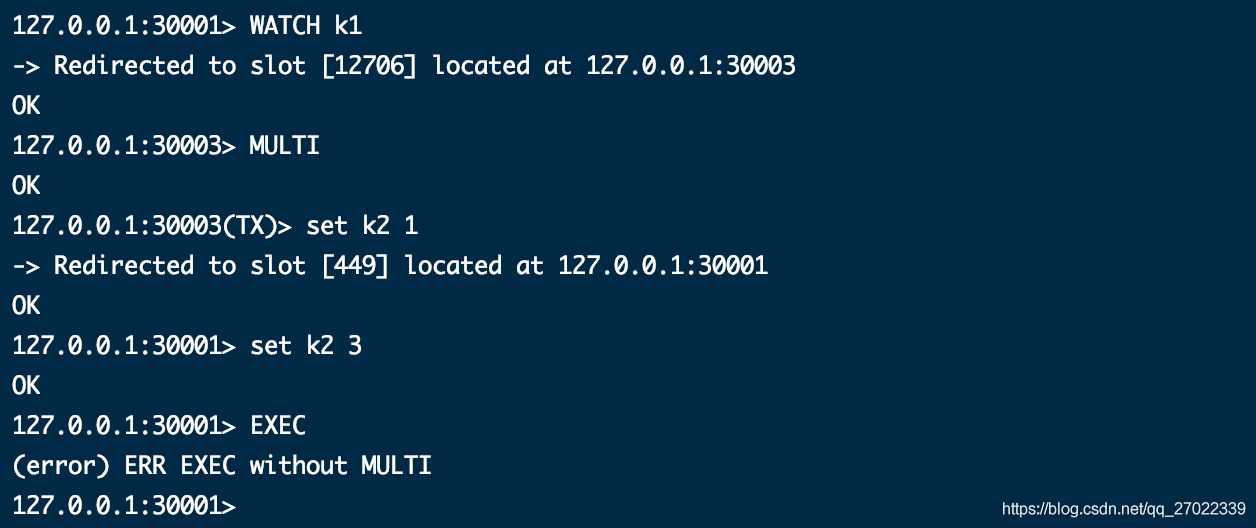
正确实现事务的方式是在多个操作的 key 前加相同的 {tag},哈希算法只会对这个 tag 进行计算,最后落到同一个节点上。
其他问题
多服务器如何配置?
创建节点这一步在每个服务器创建好节点,同样按手动分配集群的方试填写多个服务器对应的 IP 和 端口号就行了。
如何重新分片?
我们可以通过重新分片来解决数据倾斜的问题。
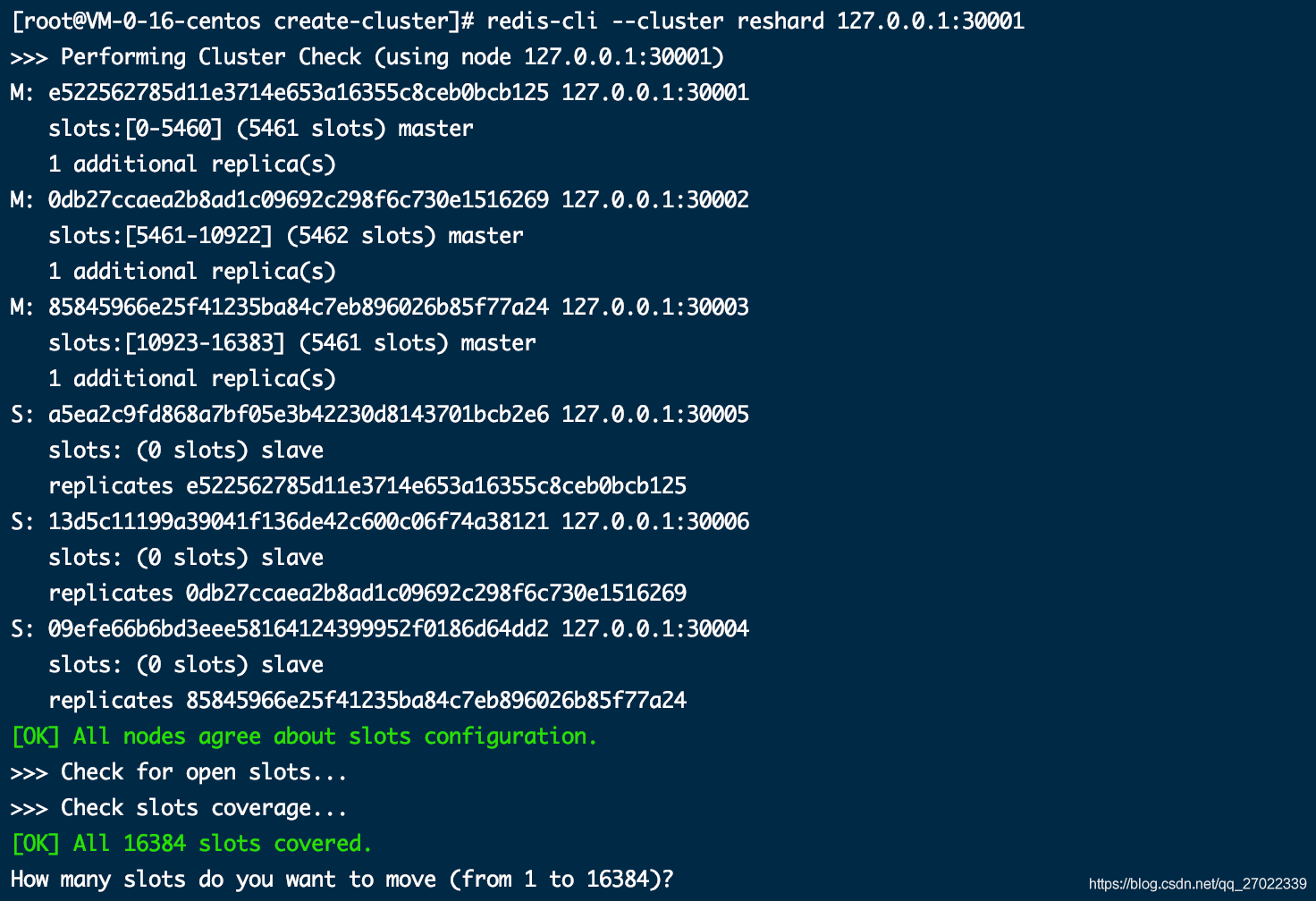
执行下面命令表明连接这个节点进行重新分片操作,同时打印出所有节点信息,然后会询问你要转移走多少个槽位(这里输入了 2000)。
redis-cli --cluster reshard 127.0.0.1:30001
问你接收这些槽位的节点 ID 是多少(这里输入了主节点 30002 的 ID)。
然后要你依次输入多个源节点,就是从哪些节点移走共 2000 个槽位。你可以依次填节点 ID 回车,最后输入 done 完成;也可以直接输入 all 从其他所有节点转移(这里输入了主节点 30001 的 ID)。

最终结果就是从 30001 转移了 2000 个槽位到 30002。经过计算还会询问你是否同意这个分片计划,输入 yes 完成。

如果想再细粒度的控制这个分片过程是做不到的。
其他集群操作指令
# 查看集群指令帮助信息
redis-cli --cluster help
# 这两个指令都可以看到集群相关信息,连任一节点都可以
redis-cli --cluster info 127.0.0.1:30001
redis-cli --cluster check 127.0.0.1:30001