
一、文件系统存储
计算机刚开始出现的时候,那时候没有硬盘,只有内存,数据不会进行存储,一般只用于科技计算,计算完输出结果后,程序就撤出内存了。后来随着技术发展,有了硬盘、文件,在文件的基础上有了文件系统。文件系统可以满足数据存放和查找的需求。
文件系统作为数据库用了一段时间,当数据越来越多、规模越来越大后,数据查找特别麻烦。数据很容易重复(冗余)、占用存储空间多,数据结构化被迫推进。

- 数据库在狭义层面上来说:指的是处理数据的底层程序
- 数据库在广义层面上来说:指的是操作这些底层程序的便捷应用软件
总的来说,数据库顾名思义其实就是存取数据的地方;另外随着时间线的发展产生了不同种类的数据库,但本质技术提升的本质都是为了提升业务性能!


二、关系型数据库存储
关系型数据库也被称为RDBMS,顾名思义就是信息遵循一种利用表或关系的结构化方法,是一种存储和操作历史数据的经典方法。
SQL这个词既是一种语言,也是数据库的类型。SQL代表结构化查询语言,是数据库设计理念的先驱。自80年代中期以来,SQL一直是管理和查询关系数据集的标准;然而,关系模型的早期雏形可以追溯到60年代和70年代,当时出现了区分应用数据和应用代码的迫切需求,使开发人员能够专注于程序开发的其他方面,如访问和操作手头的数据。IBM的IMS是第一个功能齐全的关系型数据库,尽管设计的目的不同,是为了组织阿波罗太空探索计划的数据。关系数据库是各种程度的时间变化的、规范化的关系的集合。可以做出以下直观的对应。
-
关系数据库管理系统 (RDBMS) 支持关系(面向二维表)数据模型,表(table)
- RDBMS 中的数据存储在称为表的数据库对象中
-
表的架构(关系架构)由表名和具有固定数据类型的固定数量的属性/字段定义,列(column)
- 需要预先定义架构,即需要提前知道所有列及其相关联的数据类型,以便于应用将数据写入数据库
- 一个关系就是一个文件,每个文件只包含一种记录类型
-
记录(实体)对应于表中的一行,由每个属性的值组成,行(row)
-
表架构是通过数据建模过程中的规范化生成的
-
可以存储通过键链接多个表的信息,从而创建跨多个表的关系
-
在简单的用例中,键用于检索特定行以便于进行检查或修改
-
结构化查询语言,允许用户访问和操作高度结构化表中的数据
-
记录没有特定的顺序
-
每个字段都是单值的
-
记录有一个唯一的识别字段或复合字段,称为主键字段
特性:ACID
原子性、一致性、隔离性、持久性以保持交易的可靠性。
- 原子性:整体完成交易或完全不完成交易
- 一致性:保证数据库的稳定状态,无论有无变化
- 隔离性:多个事务不会相互干扰
- 持久性:变化对数据库的永久影响
范式设计
一个设计高效数据库的过程

- 1NF:通过分离重复和不重复的属性来分割表。所有的域都是简单的,所有的元素都是原子性的。
- 2NF:移除属性之间的部分依赖关系。任何属性都不应该在功能上依赖于聚合主键的一个部分。
- 3NF:移除表属性之间的传递性依赖。没有首要属性在功能上依赖于非首要属性。
可扩展性
数据库处理不断增长的数据量的能力。垂直扩展有助于增强数据库服务器的现有能力。大多数SQL数据库支持垂直扩展。然而,他们可以扩大规模,而不是缩小规模。
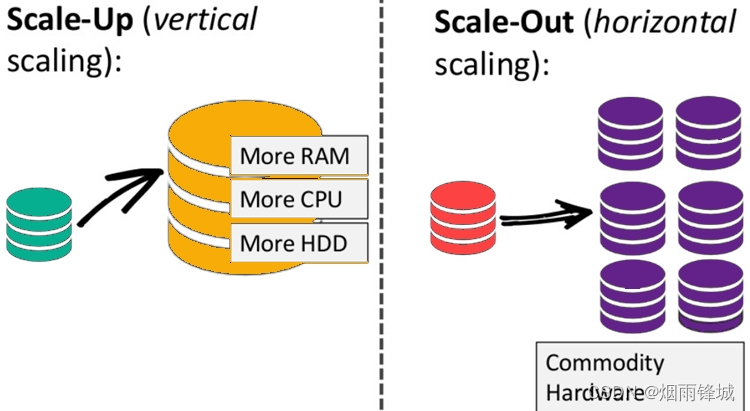
从使用角度来说用户不直接接触数据库,而是通过我们的应用程序与数据库进行交互。
如果用户比较多,发出的请求多了之后,由于我们的数据库是放置在磁盘,而磁盘的性能是比较低的,所以会导致Web应用程序每次到与数据库进行交互之后,用户的响应速度会变慢!

解决方案:池化技术,实现资源的复用(降低资源创建销毁的开销)

以上是Web应用与数据库连接层面的优化,至于在数据库本身我们也可以进行优化,以提升性能。
- 升级服务器硬件
- 数据库索引
- SQL执行计划
- 慢查询
- 减少交互次数
- 减少应用到数据库传输的数据量
- 数据库进行分库分表、读写分离

数据分片,使用分布式集群结构等虽然提高了可扩展性更好了,但也带来了新的麻烦
1、以前在一个库里的数据,现在跨了多个库,应用系统不能自己去多个库中操作,需要使用数据库分片中间件
2、分片中间件做简单的数据操作时还好,但涉及到跨库join、跨库事务时就很头疼了,很多人干脆自己在业务层处理,复杂度较高
关系型数据库劣势
数据建模的僵化
关系型数据库最大的限制之一是将数据组织到表和关系的特定结构中的僵硬性。由于所有的数据都不能方便地装入表格,因此这种方法不能应用于所有的自然数据,也不能以树和图的形式存储,但是,RDBMS通过以父子关系的规范化方式对这些数据进行建模来解决这个限制,这仍然是不够的。
多样性
数据的复杂性也给关系型数据库带来了限制。这些数据库是按共同特征来组织数据的。复杂的数字、图像和多媒体数据很难存储、访问和处理。
空间使用效率低下
当我们定义关系的模式时,我们定义所有属性的大小。不是所有的记录都有使用全部空间的数据。一些有很短的长度。每条记录不一定又适合给定的数据类型,造成了空间浪费。
沉重的变化
一个记录所需的任何改变都需要应用于所有的记录。因此造成了重量级的改变。根据当时存在的记录的大小和数量,这些改变可能是昂贵的,不可行的。因此,改变一个已经存在的数据库的模式是一个挑战。
对大数据来说效率低下
SQL不适合数量大、速度快、种类多的数据,使得它在基于云的应用中效率很低。
总结:随着大数据时代的到来,结构化的方法已经无法满足巨大的信息处理需求,这些信息往往是非结构化的。随着时间的推移,SQL已经经历了许多迭代,以支持大量的数据处理和管道。然而,对于期望快速响应和最高可扩展性的大数据系统来说,它仍然是低效的。
三、非关系型数据库存储
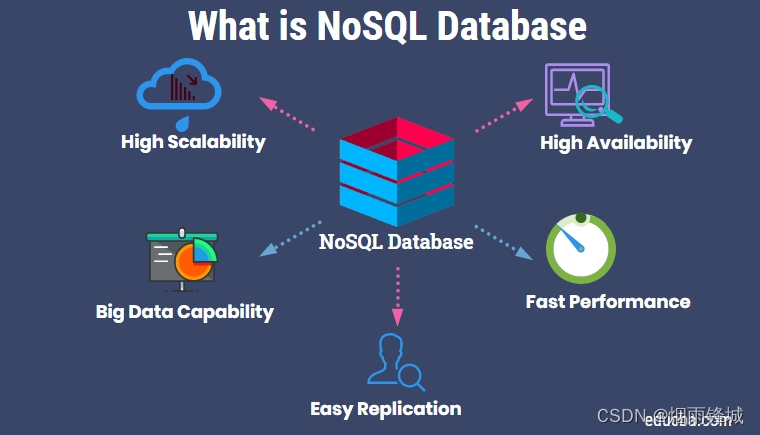
关系数据库近期还是非常广泛使用的模型,它们仍然在许多企业得到了广泛采用。然而,面对当今多样化、高速和海量的数据,有时需要用一个高度不同的数据库来补充关系数据库。这促进了 NoSQL 数据库在某些领域的采用,该数据库也称为“非关系数据库”。由于支持快速横向扩展,因此非关系数据库可以处理高流量,这也使其具有很强的适应性。非关系型数据库也即NoSQL(Not Only SQL),目的总结就是高性能,提升可扩展性!
优势:
- 灵活性:SQL 数据库将数据存储在更加严格的预定义结构中。NoSQL 则以更加自由的方式来存储数据,而无需严格的模式。这种设计可支持创新和快速应用开发。开发人员可以专注于创建系统来改善客户服务,无需担心模式。NoSQL 数据库可以轻松处理任何数据格式,例如单一数据存储中的结构化、半结构化和非结构化数据。
- 可扩展性:NoSQL 数据库可以通过商用硬件来实现横向扩展,而不需要通过添加更多服务器来进行扩展。这可以支持流量增长,从而满足零停机需求。通过横向扩展,NoSQL 数据库可以扩充容量和处理能力,因此成为支持不断变化的数据集的首选方案。
- 高性能:当数据量或流量增长时,NoSQL 数据库的横向扩展架构的优势尤为明显。如下图所示,该架构可实现快速、可预测的个位数毫秒级响应能力。NoSQL 数据库还可以摄取数据并快速可靠地交付数据,因此 NoSQL 数据库可支持应用每天收集 TB 级数据,同时实现高度交互的用户体验。如下图所示,每秒 300 次读取的传入速率(蓝线)的第 95 次延迟在 3-4 毫秒范围内,而每秒 150 次写入的传入速率(绿线)的第 95 次延迟在 4-5 毫秒范围内。

- 可用性:NoSQL 数据库可自动跨多个服务器、数据中心或云资源复制数据。而这又可以大幅减少用户延迟,而不受其地理位置的限制。此特性还有助于减轻数据库管理的负担,从而腾出时间专注于其他优先事项。
- 功能强大:NoSQL 数据库专为具有超高数据存储需求的分布式数据存储而设计。这使得 NoSQL 成为大数据、实时 Web 应用、360 度客户视图、在线购物、在线游戏、物联网、社交网络和在线广告应用的理想方案。
不推荐NoSQL的场景:
- 要求数据规范化:NoSQL 数据库通常依赖于非规范化数据,可支持使用较少表(或容器)的应用类型,并且其数据关系不是使用引用建模,而是作为嵌入式记录(或文档)。财务、会计和企业资源规划中的许多经典后台业务应用均依赖高度规范化的数据来防止数据异常和数据重复。这些应用类型通常不适用于 NoSQL 数据库。
- 查询复杂性:NoSQL 数据库在查询单个表时性能出众。然而,随着查询复杂性的增加,关系数据库则是更好的选择。NoSQL 数据库通常不会在 WHERE 子句中提供复杂的联接、子查询和查询嵌套。
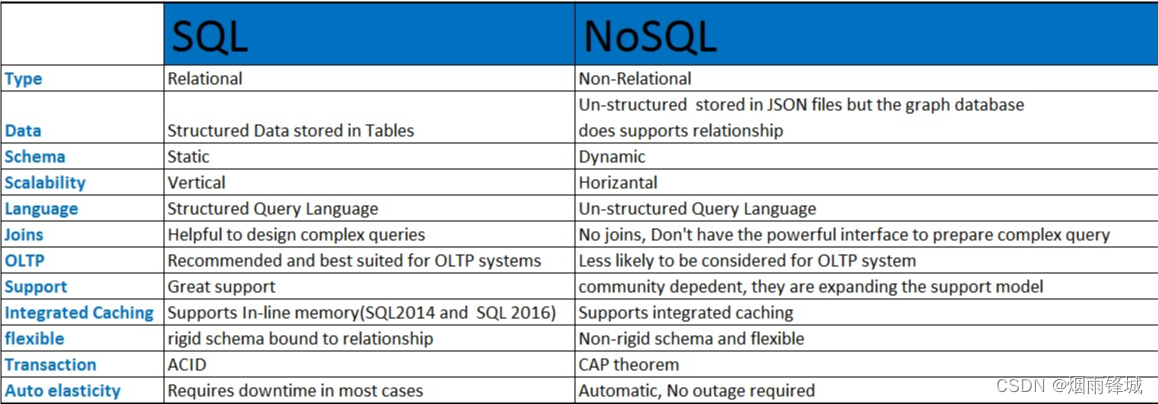
NoSQL VS RDBMS

RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中
- 数据操纵语言,数据定义语言
- 严格的一致性,也称作强一致性
- 严格的事务特性
NoSQL
-
不仅仅是SQL
-
没有声明性查询语言
-
没有预定义的模式
-
键 - 值对存储,列存储,文档存储,图形数据库
-
最终一致性,而非ACID属性
-
非结构化和不可预知的数据
-
CAP定理

-
BASE原则
-
高性能,高可用性和可伸缩性
主要类型
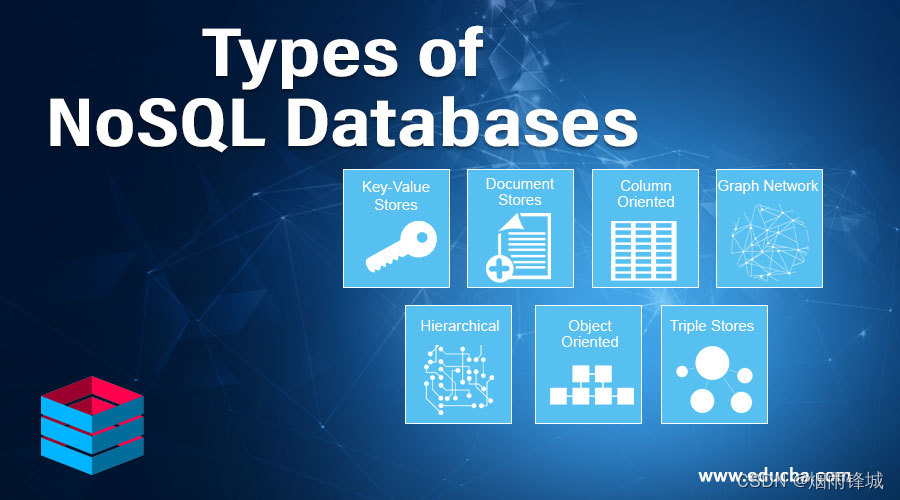


键值存储类型
这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制!
典型代表:MemcacheDB、Redis
特点:
- 通过 Key-Value 键值的方式来存储数据,通过key快速查询到value
- Key 和 Value 可以是简单的对象,也可以是复杂的对象
- 一般作为缓存使用,故我们也称作为故也称作为缓存数据库

文档存储类型
也称为文档存储或面向文档的数据库,这些数据库用于存储、检索和管理半结构化数据。无需指定文档将包含哪些字段。
典型代表:MongoDB、CouchDB
特点:
- 此类数据库可存放并获取文档,可以是XML、JSON等格式
- 在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录
- 文档数据库所存放的文档,就相当于键值数据库所存放的“值”
- 可以对某些字段建立索引,实现关系数据库的某些功能

列式存储类型
这些数据库以表、行和列的形式来存储和管理数据。它们广泛部署于需要用列格式来捕获无模式数据的应用中。
典型代表:Hbase、Cassandra、Hypertable
特点:将数据按照列进行存储,最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有着极大的IO优势

图形存储类型
此数据库将数据组织为节点和关系,这将显示节点之间的连接。这支持更加丰富和完整的数据表示。图形数据库应用于社交网络、预订系统和欺诈检测。
典型代表:Neo4J、FlockDB
特点:
- 利用了图这种数据结构存储了实体(对象)之间的关系
最典型的例子就是社交网络中人与人的关系,数据模型主要是以节点和边(关系)来实现,特点在于能高效地解决复杂的关系问题
- 关系型数据用于存储明确关系的数据,但对于复杂关系的数据存储就有些不方便
如社交网络中人物之间的关系,如果用关系型数据库则非常复杂,用图形数据库将非常简单

总结:


- NoSQL介绍:https://www.guru99.com/nosql-tutorial.html
- MongoDB官网介绍:https://www.mongodb.com/zh-cn/nosql-explained
NoSQL缺点
- NoSQL 不保证强一致性,对于普通应用没问题,但还是有不少像金融一样的企业级应用有强一致性的需求。
- 缺乏标准化,NoSQL 不支持 SQL 语句,没有特定的语言,兼容性是个大问题,不同的NoSQL 数据库都有自己的 API 操作数据,比较复杂
四、NewSQL存储
NewSQL 提供了与 NoSQL 相同的可扩展性,而且仍基于关系模型,还保留了极其成熟的 SQL 作为查询语言,保证了ACID事务特性。简单来讲,NewSQL就是在传统关系型数据库上集成了NoSQL 强大的可扩展性。
传统的SQL架构设计基因中是没有分布式的,而NewSQL 生于云时代,天生就是分布式架构。
NewSQL 的主要特性:
- SQL 支持,支持复杂查询和大数据分析
- 支持 ACID 事务,支持隔离级别
- 弹性伸缩,扩容缩容对于业务层完全透明
- 高可用,自动容灾

总的来说数据库产品演进就是分为三代:
- 第一代数据库架构产品:传统的关系型数据库主导
- 第二代数据库架构产品:传统关系型数据库 + NoSQL多厂家产品配合使用
- 第三代数据库架构产品:NewSQL(关系型+NoSQL+大数据+分布式架构完整解决方案)
主流数据库产品:
RDBMS:Oracle,MySQL,PG,MSSQL,DB2,SQLLite
NoSQL:MongoDB,Redis,ElasticSearch,Cassandra,Neo4j,Solr
NewSQL: Google Spanner,PinCAP TiDB
云数据库:Aliyun RDS,DRDS,PolarDB,腾讯云 TDSQL
参考文章:
- 通俗理解数据库:https://www.daimabiji.com/teatime/933.html
- SQL vs NoSQL vs NewSQL:https://juejin.cn/post/6992416728990875662
- NewSQL系统综述:https://zhuanlan.zhihu.com/p/23866692