SQLAlchemy 是 Python 著名的 ORM 工具包。通过 ORM,开发者可以用面向对象的方式来操作数据库,不再需要编写 SQL 语句。本篇不解释为什么要使用 ORM,主要讲解 SQLAlchemy 的用法。SQLAlchemy 支持多种数据库,除 sqlite 外,其它数据库需要安装第三方驱动。本篇以 sqlite 数据库为例进行说明。
建立与数据库的连接
Engine 对象是使用 sqlalchemy 的起点,根据 sqlalchemy documentation - engine congifugration 中 关于Engine 架构示意图,Engine 包括数据库连接池 (Pool) 和 方言 (Dialect,指不同数据库 sql 语句等的语法差异),两者一起把对数据库的操作,以符合 DBAPI 规范的方式与数据库交互。
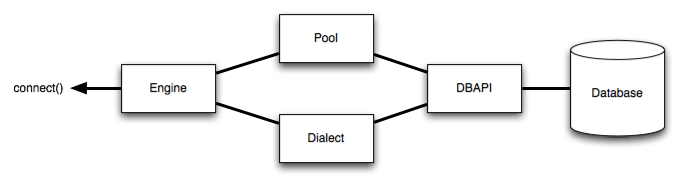
sqlite 连接示例
create_engine() 函数创建 engine 对象,不同的数据库有不同的 database url。比如连接到 sqlite 的 testdb 数据库:
from sqlalchemy import create_engine
engine = create_engine("sqlite:///testdb.db")
典型的 database url 语法规则:
dialect+driver://username:password@host:port/database
mysql 数据库连接示例
# 使用pymysql驱动连接到mysql
engine = create_engine('mysql+pymysql://user:pwd@localhost/testdb')
sql server 数据库连接示例
# 使用pymssql驱动连接到sql server
engine = create_engine('mssql+pymssql://user:pwd@localhost:1433/testdb')
一般情况下,create_engine() 函数只需要指定 database url,根据需要,设置 echo 参数,如果 echo = True,程序运行时反馈执行过程中的关键对象,包括 ORM 构建的 sql 语句。
建立映射关系
数据库与 Python 对象的映射主要在体现三个方面:
- 数据库表 (table)映射为 Python 的类 (class),称为 model
- 表的字段 (field) 映射为 Column
- 表的记录 (record)以类的实例 (instance) 来表示
比如,在数据库中有一个 employees 表,表结构如下:

sqlalchemy 支持两种方式创建映射,最常见的是通过下面的方式,这种方式被称为声明式映射 (Declarative Mapping),声明式映射与命令式映射 (imperative mapping) 相对。
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Employee(Base):
__tablename__ = 'employees'
EMP_ID = Column(SmallInteger, primary_key=True)
FIRST_NAME = Column(String(255))
LAST_NAME = Column(String(255))
GENDER = Column(String(255))
AGE = Column(SmallInteger)
EMAIL = Column(String(255))
PHONE_NR = Column(String(255))
EDUCATION = Column(String(255))
MARITAL_STAT = Column(String(255))
NR_OF_CHILDREN = Column(SmallInteger)
以上代码的作用是:通过 declarative_base() 函数创建 Base 类,Base 类本质上是 一个 registry 对象,Base 作为所有 model 类的父类,将在子类中把声明式映射过程作用于其子类。
在实际编码的时候,常见的方式是先在数据库中建表,然后再用代码操作数据库。上面这种声明式定义映射模型,对 Column 的声明是很枯燥的。如果表的字段很多,这种枯燥的代码编写也是很痛苦的事情。
解决办法有两个,方法一是安装 sqlacodegen 库 (pip 安装方式),然后通过下面的命令,基于数据库中的表自动生成 model 映射的代码。sqlacodegen 用法如下:
# 将数据库中所有表导出为 model
sqlacodegen sqlite:///testdb.db --outfile=models.py
sqlacodegen 使用与 sqlalchemy 相同的 database url。如果只关心部分表的模型导出,使用 tables 参数:
# 指定导出的表导出model
sqlacodegen sqlite:///testdb.db --outfile=models.py -- tables users, addresses
为准备后面单表的 CRUD 操作,我用 sqlacodegen 命令创建 employees 表的 model 映射代码:
sqlacodegen sqlite:///testdb.db --outfile=employee_model.py --tables employees
生成的代码文件 employee_model.py 内容如下:
from sqlalchemy import Column, SmallInteger, Text
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
metadata = Base.metadata
class Employee(Base):
__tablename__ = 'employees'
EMP_ID = Column(SmallInteger, primary_key=True)
FIRST_NAME = Column(Text(255))
LAST_NAME = Column(Text(255))
GENDER = Column(Text(255))
AGE = Column(SmallInteger)
EMAIL = Column(Text(255))
PHONE_NR = Column(Text(255))
EDUCATION = Column(Text(255))
MARITAL_STAT = Column(Text(255))
NR_OF_CHILDREN = Column(SmallInteger)
第二种方法,在构建 model 的时候,使用 autoload = True,sqlalchemy 依据数据库表的字段结构,自动加载 model 的 Column。使用这种方法时,在构建 model 之前,Base 类要与 engine 进行绑定。下面的代码演示了 autoload 模式编写 model 映射的方法:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.sql.schema import Table
engine = create_engine("sqlite:///testdb.db")
Base = declarative_base()
metadata = Base.metadata
metadata.bind = engine
class Employee(Base):
__table__ = Table("employees", metadata, autoload=True)
单表 CRUD
SQLAlchemy 操作数据库,需要引入另外一个对象 Session。Session 建立与数据库的会话 (conversation),可以将其想象成对象的容器,包含的对象叫 identity map 的结构,identity map 的作用就是保证对象的唯一性。另外,Session 对 Python 对象进行状态管理,后面我会说明。
首先,需要构建一个 Session 对象,比较常用的方式是使用 sessionmaker() 函数来创建一个 global 的 Session Factory,进行调用后就生成 Session 对象:
engine = create_engine("sqlite:///testdb.db", echo=False)
Session = sessionmaker(bind=engine)
session = Session()
查询记录
在 CRUD 中,创建记录、修改记录和删除记录都是模式化的代码,查询则比较灵活,我们先介绍查询的方法。单表查询常见的有两种方式,第一种方式是将 model 类作为参数传递给 query() 方法,如下面代码:

Employee 作为参数传给 query() 方法,执行 session.query(Employee) 后,返回值为 sqlalchemy.orm.query.Query 对象实例,调用 all() 方法后,得到包含 Employee 对象实例的 list。我们看到,程序打印的结果如下:

为了能更加友好的输出,可以在 Employee 类中编写 __repr__ 方法,以 dict 类型输出数据表的内容。为了实现通用性,我使用 __dict__ 属性获取 Employee 的字段,将方法放在专门的扩展类中:
import json
class ModelExt(object):
"""
Model extension, implementing `__repr__` method which returns all the class attributes
"""
def __repr__(self):
fields = self.__dict__
if "_sa_instance_state" in fields:
del fields["_sa_instance_state"]
return json.dumps(fields)
再利用 tablib 将数据转换为格式化的输出,方便查看,代码如下:
def to_formatted_table(tab_data):
"""
tab_data is supposed to be of type list(dict)
"""
ds = tablib.Dataset()
return(ds.load(str(tab_data)))
利用 Python 的多重继承机制,将 Model 类增加一个父类 ModelExt:

query() 返回的记录,现在可以格式化输出:
def test_query_all(self):
# 对象作参数,返回值类型为 list[Employee_Object]
employees = session.query(Employee).all()
print(to_formatted_table(employees))
输出界面如下:

如果只需要获取部分字段,将 字段作为 query() 方法的参数:
def test_query_selected_fields(self):
# 返回值类型:list[sqlalchemy.util._collections.result]
employees = session.query(Employee.EMP_ID, Employee.FIRST_NAME, Employee.LAST_NAME).all()
for emp in employees:
print(emp)
此时 employees 的类型是由元组 (tuple) 构成的列表(list),程序输出的界面如下:

为什么 query() 方法,不同的参数类型,能返回不同的结果呢?其实,SQLAlchemy 对 query() 方法,在背后维护了 3 个类,分别是 _MapperEntity, _BundleEntity 和 _ColumnEntity,这三个类都是 _QueryEntity 的子类,在 _QueryEntity 的构造方法中进行了判断,根据传入参数不同,调用了不同的实现。_QueryEntity 的相关代码如下:

用字段作 query 的参数,背后就是用的 _ColumnEntity 对象实例。
查询数据离不开对记录的筛选。Query 对象提供了 filter() 方法和 filter_by() 方法用于数据筛选。filter_by() 适用于简单的基于关键字参数的筛选。 filter() 适用于复杂条件的表达。比如,我们要找出 EMP_ID 为 1001 的雇员信息,filter_by 和 filter 都是可以的:
def test_filtered_query(self):
emp = session.query(Employee).filter_by(EMP_ID='1001').first()
print(emp)
def test_filtered_query2(self):
emp = session.query(Employee).filter(Employee.EMP_ID == '1001').first()
print(emp)
如果我们要找出所有 EMP_ID < 1009 的员工,因为 filter_by 只支持关键字参数,不能实现,需要用 filter() 方法:
def test_filtered_query3(self):
emps = session.query(Employee).filter(Employee.EMP_ID <= '1009').all()
print(to_formatted_table(emps))
下面的代码演示了常见条件的表达,因为比较直观,就不赘述了。
def test_filter_le(self):
emps = session.query(Employee).filter(Employee.EMP_ID <= '1009').all()
print(to_formatted_table(emps))
def test_filter_ne(self):
emps = session.query(Employee).filter(Employee.EMP_ID != '1001').all()
print(to_formatted_table(emps))
def test_filter_like(self):
emps = session.query(Employee).filter(Employee.EMP_ID.like('%9')).all()
print(to_formatted_table(emps))
def test_filter_in(self):
emps = session.query(Employee).filter(Employee.EDUCATION.in_(['Bachelor', 'Master'])).all()
print(to_formatted_table(emps))
def test_filter_notin(self):
emps = session.query(Employee).filter(~Employee.EDUCATION.in_(['Bachelor', 'Master'])).all()
print(to_formatted_table(emps))
def test_filter_isnull(self):
emps = session.query(Employee).filter(Employee.MARITAL_STAT == None).all()
print(to_formatted_table(emps))
def test_filter_isnotnull(self):
emps = session.query(Employee).filter(Employee.MARITAL_STAT != None).all()
print(to_formatted_table(emps))
def test_filter_and(self):
emps = session.query(Employee).filter(Employee.GENDER=='Female', Employee.EDUCATION=='Bachelor').all()
print(to_formatted_table(emps))
def test_filter_and2(self):
emps = session.query(Employee).filter(and_(Employee.GENDER=='Female', Employee.EDUCATION=='Bachelor')).all()
print(to_formatted_table(emps))
def test_filter_or(self):
emps = session.query(Employee).filter(or_(Employee.MARITAL_STAT=='Single', Employee.NR_OF_CHILDREN==0)).all()
print(to_formatted_table(emps))
创建记录
先创建一个 model 对象,Session.add() 方法将 model 提交到 session,session.commit() 将数据提交到数据库:
def test_create_emp(self):
emp = Employee(
EMP_ID = "9002",
FIRST_NAME= "Lauren",
LAST_NAME = "Daigle",
GENDER = "Female",
AGE = 20,
EMAIL = "unknown",
PHONE_NR = "unknown",
EDUCATION = "Bachelor",
MARITAL_STAT = "Single",
NR_OF_CHILDREN = 0
)
session.add(emp)
session.commit()
修改记录
修改记录要需要先定位到该记录,修改字段后进行提交。下面的代码演示了修改的方法。
def test_modify(self):
emp = session.query(Employee).filter_by(EMP_ID='9002').first()
emp.AGE = '21'
session.commit()
删除记录
删除记录也要先定位到该记录,然后进行删除。
def test_delete(self):
emp = session.query(Employee).filter_by(EMP_ID='9002').first()
session.delete(emp)
session.commit()
多表之间的关系
数据库表之间有三种关系:一对一,一对多,多对多,表之间的关系通过外键和参照完整性(级联更新,级联删除等)来表达。这些属于数据库的知识,这里不展开细说。使用 sqlalchemy 来操作多表,我们需要清楚哪些功能是数据库层面实现的,哪些是 sqlalchemy 层面实现的。
假设现在有两个表:users 和 addresses,一个 user 可能有多个地址,所以 users 和 addresses 表之间的关系是一对多。

上面的图示演示了数据库层面将 users 的 id 作为 addresses 表的外键 (foreign key),并且对该约束定义了级联更新和级联删除。如果在 sqlalchemy 代码来生成数据库表并且定义外键和外键的约束,应该是这样的:

为了在 sqlalchemy 中进行多表操作,可以通过下面的方式定义数据表的外键,并且在 sqlalchemy 层面定义表的关系:

relationship() 函数定义两个表之间的关系,(API 请参考:Relationships API)。back_populate 参数的作用是在对象中建立一个相互的参照,比如在 User 类中,通过 addresses 属性参照到的 Address,在 Address 中,通过 user 属性参照到 User。back_populate 需要在两个表中同时维护关系,backref 参数提供了一种简化的方式(在一对多的一方维护就行):

多表 CRUD
多表查询
用上面的代码定义了 User 和 Address 两个 model,如果需要从两个表中查询,方法之一是使用 Query 对象的 join() 方法。代码示例:
def test_query_via_join(self):
result = session.query(User, Address).join(Address).all()
for item in result:
print(item[0].id, item[0].fullname, item[1].email_address)
上面的查询,涉及两个表,其数据类型是包含 tuple 的 list,如果直接打印 result,大致像这样:
[
({"fullname": "admin", "id": 1, "nickname": "adm", "name": "admin"},
{"user_id": 1, "id": 1, "email_address": "[email protected]"}),
({"fullname": "stone", "id": 2, "nickname": "S", "name": "stone"},
{"user_id": 2, "id": 2, "email_address": "[email protected]"}),
({"fullname": "stone", "id": 2, "nickname": "S", "name": "stone"},
{"user_id": 2, "id": 3, "email_address": "[email protected]"})
]
所以可以用 item[0] 获取 User 的数据,用 item[1] 获取 Address 的数据。在 sqlalchemy 维护了两个表 relationship 的情况下,也可以通过下面的方法来获取数据,代码更加直观:
def test_query_via_relation(self):
result = session.query(User).all()
for item in result:
addresses = item.addresses
for addr in addresses:
print(item.id, item.fullname, addr.email_address)
我们也可以从多的一边查询,关联到一的这边:
def test_query_many_to_one(self):
result = session.query(Address).all()
for addr in result:
print(addr.id, addr.email_address, addr.user.fullname)
不管怎样,手工从多个表中获取数据都是可以的:
def test_get_address_manually(self):
"""
不管数据库是否建立关系,sqlalchemy是否建立关系
都可以用下面手工的方式查询和获取
:return:
"""
user = session.query(User).filter_by(id=2).first()
addresses = session.query(Address).filter(Address.user_id == user.id).all()
print(addresses)
多表插入数据
与创建相同,我们总可以以手工的方式,多需要插入的表进行分别操作。比如,要创建一个新的名为 Alice 的 User,同时在 addressses 表中创建 Alice 的两个地址:
def test_create_user_and_addr(self):
"""
手工的方式,没有利用SA的relationship
"""
user = User(id=3, name="Alice", fullname="Alice Brown")
addr = Address(id=4, email_address="[email protected]", user_id=3)
session.add(user)
session.add(addr)
session.commit()
在 SQLAlchemy 维护了关系之后,可以用更加面向对象的方式进行操作。注意下面的方法中,创建 addr 对象没有指定 user_id 字段:
def test_create_user_and_addr2(self):
user = User(id=3, name="Alice", fullname="Alice Brown")
user.addresses = [
Address(id=4, email_address="[email protected]"),
Address(id=5, email_address="[email protected]")
]
session.add(user)
session.commit()
多表删除
根据数据库中是否维护了参照完整性或者 SQLAlchemy 是否定义了级联删除,如果没有维护关系,需要分别删除表中的数据,如果数据表维护了参照完整性,或者 SQLAlchemy 定义了级联删除,删除 One-to-many 中一的一方,many 一方的数据自动删除。
def test_delete_user_and_addr(self):
"""
维护参照完整性,或者SQLAlchemy维护了级联删除
"""
user = session.query(User).filter_by(id=3).first()
session.delete(user)
session.commit()