参考链接:https://blog.csdn.net/joinplay/article/details/23255941
1、查找oracle错误日志存放目录(sqlplus登录sysdba执行):show parameter background_dump_dest
查看alert.log发现有很多Thread 1 cannot allocate new log, sequence.这样信息
分析觉得应该是dbwr写的太慢,redo切换的太频繁,日志量比较大造成的.
2、查看redo:
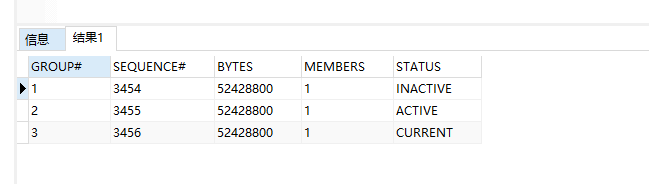
select group#,sequence#,bytes,members,status from v$log; --查看每组日志的状态
3、alter database add logfile group 4 (‘D:\APP\ADMINISTRATOR\ORADATA\ORCL\REDO04.LOG’) size 200M; 增加1组日志组 视情况而定增加日志组的大小。
4、alter system switch logfile; --切换日志组
5、alter database drop logfile group 1; --删除INACTIVE状态的redo文件
6、删除group 1 redo文件后,记录已经删除,但是文件还在,可以执行
select member from v$logfile;标签:group,log,Thread,alert,日志,logfile,redo,alter From: https://www.cnblogs.com/ayu1996/p/17159016.html
查看redo的位置,把redo01文件剪切备份到其他地方。